Bueno, pues ha pasado otro año. La web de CRySoL (tal como la conocemos hoy) cumple 3 años ya. Se inauguró el 20 de octubre de 2005. Aunque como muchos sabéis había algo parecido a una web cutre desde unos años atrás.
Gracias al inestimable y considerable esfuerzo de lk2, que ha incluido portar parte de algunos módulos y arreglar algún que otro bug en otros, ya tenemos el site de CRySoL migrado a Drupal-6.3. Muchas horas de pruebas y más PHP del que nos gustaría aprender. Como siempre, si encontráis cualquier anomalía en el funcionamiento del portal, o alguna feature perdida, no dudéis en dejar un comentario en este mismo post.
Saludos
Con la reciente actualización del drupal de CRySoL hemos podido hacer el necesario upgrade a PHP5, y eso nos ha permitido instalar un módulo bastante decente para colorear listados de código con GeSHi.
Después de algunos problemillas, hemos migrado el portal a drupal-5.7. Lo sentimos por las molestias que esto te haya podido causar, pero era necesario porque nos habíamos quedado bastante obsoletos. Los problemillas de última hora eran:
Hemos migrado a Drupal 5.1, sin embargo, no todo el trabajo está hecho. Debemos actualizar distintos módulos y herramientas que utilizábamos en la versión 4.6 y adaptar el sitio al nuevo Drupal.
Disculpad por los distintos problemas y carencias que podais observar en estos momentos. En breve las subsanaremos y todo volverá a ser como antes (o mucho mejor).
¡Un saludo!
Ayer fue el aniversario de la inauguración oficial de la web de CRySoL. Sin duda algunos de los que la pusimos en marcha, con más ganas que esperanzas, no creíamos que fuera a ir tan bien.
Uno de los objetivos de CRySoL es la defensa de la libertad del software y otras manifestaciones culturales. Cualquier otra demostracción de defensa de libertades está literalmente fuera de lugar, deberá hacerse en otros foros dedicados a tales asuntos. Por favor: aquél que quiera escribir, que tenga en mente cuál es el objetivo de esta web.
Este comentario no va por la mayor parte de vosotros, ya que existimos desde hace menos de un año y no ha habido ningún altercado digno de mención. Sin embargo, hoy he tenido que "banear" dos artículos y un usuario por su contenido. No importa si me encuentro a favor; no importa si me encuentro en contra. Lo que importa es que dicho contenido no tiene cabida en esta web.
Por favor: Si alguien ve contenido fuera tono/tema, que avise a los administradores para su inmediata eliminación. Recordad que estamos utilizando los servicios de la Universidad, y necesitamos sus favores. No queremos que nos cierren el sitio por un único alborotador.
Muchas gracias.
-- MagMax, uno de los admin.
En primer lugar quiero decir que todos los administradores y editores agradecemos que cada vez más gente empiece a escribir recetas, que son la columna vertebral de este portal.
Bueno, pues parece que la nueva etapa de la web de CRySoL está yendo realmente bien. Desde el día 20 de octubre que pusimos el contador de "webstats4u" (o sea, menos de un mes) hemos recibido más de 10.000 visitas.
Este documento define las normas de estilo que se deben aplicar a las recetas de la web de CRySoL. Se describe la estructura, el formato y típografía a utilizar. Esta receta sigue las normas que en ella se definen y sirve además como introducción a los formatos de entrada necesarios para poder escribir recetas.
Descarga la imagen ISO «net-install» desde https://www.debian.org/CD/netinst/ para tu arquitectura (normalmente amd64). Estas imágenes aparte de poderse grabar en un CD, también son «bootables» desde USB.
El pendrive
Ejecuta el siguiente comando:
$sudo dmesg -w
Ahora busca un pendrive USB que puedas sobreescribir, conéctalo y podrás ver en la consola el nombre del dispositivo que se le ha asignado. Será algo como:
En este caso el pendrive es el dispositivo /dev/sdc. Nos indica que tiene dos particiones sdc1 y sdc2, pero nos da igual porque lo vamos a machacar todo.
Grabar la imagen
PRECAUCIÓN: Si en este comando te equivocas de dispositivo seguramente la vas a liar muy gorda.
El comando dd copia bloques entre 2 dispositivos. En este ejemplo el dispositivo desde el que lee (if) es el fichero ISO y el dispositivo en el que escribe (of) es /dev/sdc, que tendrás que cambiar por el que corresponda según lo que hemos visto en la salida de dmesg. El bs=1M indica que el tamaño de los bloques es 1 mebiqbyte.
Esta receta explica una forma sencilla de hacer una copia de seguridad de una base de datos PostgreSQL completa para poderla restaurar en caso de catástrofe o mudanza.
sudo may be configured to stop requesting passwords for specific commands to specific users or groups. This is very convenient for personal computers where there is only a user (and therefore she’s the administrator).
With next file /etc/sudoers.d/apt, the sudo group members will be allowed to run apt, apt-get and dpkg commands absolutelly with no password.
For other users, the sudo behaviour do not change.
Option ‘timestamp_timeout’ sets the time (in minutes) that the password will remain in cache, so it will not ask for it during that period. The value 0 disables the cache.
This is a new try to start using tmux. I am absolutly convenced about advantages of tmux, but for some strange reason, I am not able to learn its key combos…
I hope this recipe should be a way to have the very basic functions always at a glance.
Panes
horizontal split
C-b %
vertical split
C-b "
move cursor
C-b {arrow}
close
C-b x
maximize/minimize
C-b z
Windows
create
C-b c
change
C-b {n}
Sessions
detach
C-b d
attach
tmux a
list
tmux ls
kill
tmux kill-session -t {n}
Config file
In your ~/.tmux.conf
set -g mouse on
setw -g monitor-activity on
set -g visual-activity on
Enlazo un tutorial del colega Magmax para montar un entorno básico ELK (ElasticSearch + logstash + Kibana) como sistema de monitorización. Probablemente el que llega más lejos con menos rollo, y con screencast y todo.
When vagrant create Virtualbox machines, disks are created with VMDK format. Therefore, the VDI format has some interesting advantages. This recipe shows a setup to create VDI disks instead VMDK.
Virtualbox can use actual partitios for its disks. This task may be simple using the virtual GUI, but in this case, we want automatize the process with Vagrant.
ZeroC provides their own (non-official) Ubuntu packages for the version 3.6. This recipe includes all steps for a successful installation on Debian jessie.
Have a local debian package mirror may be helpful when you frequently perform recurring instalations: virtual machines, continuous integration, isolated integration testing, docker containers and so on. apt-mirror is a program that can make a perfect mirror clon in a very easy way.
According to its manual page “schroot allows the user to run a command or a login shell in a chroot environment”. As many others (chroot, lxc, docker, vserver) it is a OS virtualizer. Often, these “chroot environments” are known as “jails”. A jail is much faster that a full virtualizer as vmware, virtualbox, etc.
In that recipe we explore a interesting feature: jail snapshoting
augeas is a command line generic tool to manage configuration text files. augeas comes with many “lenses”. The lenses are files that specify rules to read and write each kind of file. This is a very good to for scripting or automatic configuration management (like puppet does).
sudo lets a user run commands as she was a different user (usually root). The common configuration of sudo requests your password before run the command. As that is annoying, you may be tempted to write something like this in your /etc/sudoers:
When you have a dual head display one of them is the “primary monitor”. Usually, window manager put special panels or content in that monitor (gnome-shell).
To see which are your connected monitors (and their names) run:
$ xrandr | grep connected
DVI-I-0 disconnected (normal left inverted right x axis y axis)
VGA-0 disconnected (normal left inverted right x axis y axis)
DVI-I-1 connected primary 1920x1200+0+0 (normal left inverted right x axis y axis) 530mm x 300mm
HDMI-0 connected 1920x1200+1920+0 (normal left inverted right x axis y axis) 530mm x 300mm
In this case my primary monitor is DVI-I-1. To change to the other available monitor, run:
Puppet is a powerful software infrastructure manager. That is, a program that enable you to specify what is installed and running in each computer of your network.
Con los últimos cambios en Debian sid gnome-shell no arranca (bug #712919) por una dependencia incorrecta de pulseaudio. Al ejecutarlo vemos el siguiente error:
$ gnome-shell --replace
gnome-shell: error while loading shared libraries:
libpulsecommon-4.0.so: cannot open shared object file: No such file or directory
Para arreglarlo instala una versión anterior del paquete libpulse-mainloop-glib0. Con la versión que hay en jessie (2.0.6) funciona correctamente.
Pruebas de estilo de los distintos tipos de listados de la web. Se muestran etiquetas HTML, soporte de liquid con highlight y gist. Echa un vistado al fuente de este post.
Sometimes you need to test that some procedure is deterministic, that
is, it is done exactly the same way again and again (builder or
factory method patterns are examples of that). The production code does exactly the same invocations for the same
arguments. In these situations were are not checking the “right” behavior but just the invocation sequence does not change.
You may use a doublex Mock to test that. The first execution “trains” the
Mock, the second time verify the same behaviour.
Si tienes Debian sid y has actualizado hace poco probablemente pdflatex ha empezado a fallar:
$pdflatex main.tex
This is pdfTeX, Version 3.1415926-2.4-1.40.13 (TeX Live 2012/Debian)
kpathsea: Running mktexfmt pdflatex.fmt
I can't find the format file `pdflatex.fmt'!
Hay un bug abierto sobre esto: #709164
La solución según este hilo es instalar una versión antigua de libkpathsea6, por ejemplo:
This recipe explain how to build a grid composed by 6 debian virtual machines running IceGrid. Once the setup is done, the whole process may be executed with absolutelly no user interaction. The process takes advantage from libvirt (for virtual machine installation), debian preseds (for unattended installation) and puppet (for configuration management).
The resulting virtual grid is suitable to make tesing and continuous integration for distributed applications (using ZeroC IceGrid in this case).
Generando el .tgz de distribución de un paquete “sample” e instalándolo con pip. Esto puede servir para comprobar que un paquete Python se puede instalar y desinstalar correctamente.
El SDK de android (en concreto adb) requiere algunas librerías para i386. Si tienes una distribución de 64 bits necesitas instalar algunos paquetes adicionales que permiten usar dichas librerías. Simplemente ejecuta:
Algunos altavoces, auriculares u otras cosas, como el Belkin Music Receiver (belkin U15) no funcionan directamente con GNOME (al menos en Debian). La solución es simple, aunque no es fácil de encontrar. Basta con:
Desde que los indices de paquetes en los repositorios incluyen traducciones, las actualizaciones son aún más lentas. Esos ficheros pueden tener tamaños de varios megabytes. Pero como estas traducciones no son muy necesarias que digamos podemos configurar apt para indicarle qué traducciones queremos. Para eso, escribe un fichero /etc/apt/apt.conf.d/99Translations con el siguiente contenido:
Acquire::Languages "none";
Como podrás imaginar, esta configuración hace que apt no descargue ninguna traducción. Verás que un apt-get update, y sobre todo un aptitude update, es bastante más rápido.
Sometimes interaction among your SUT class and their collaborators does not meet a synchronous behavior. That may happen when the SUT perform collaborator invocations in a different thread, or when the invocation pass across a message queue, publish/subscribe service, etc.
Esto es una receta rápida para tener a mano lo comandos para usar pypi (a.k.a. cheeseshop) desde consola. Todo esto y mucho más está por supuesto en el CheeseShopTutorial.
Hace tiempo que quería afinar la configuración del modo tabbar de emacs para poder cambiar entre pestañas usando la típica combinación de teclas alt-<número> cual si fuera navegador o emulador de terminal. Como mis conocimientos de elisp son principalmente anecdóticos, traté de buscar algo parecido de lo que poder sacar factor común, pero nada… hasta ahora.
Tipo de servidor: IMAP
Nombre del servidor: imap.mail.uclm.es
Puerto: 993
Nombre de usuario: Pepito.Grillo
Seguridad de la conexión: SSL/TLS
Método de autenticación: Contraseña normal
Envío
Nombre del servidor: smtp.mail.uclm.es
Puerto: 587
Nombre de usuario: Pepito.Grillo
Método de autenticación: Contraseña normal
Seguridad de la conexión: STARTTLS
Una clase magistral de sistemas operativos modernos y cómo la estrategia comercial de la plataforma puede afectar de forma determinante al rendimiento e incluso a la experiencia de usuario. Me parece muy relevante y bien argumentado cómo un sistema abierto como Android (llamarlo «libre» me parece arriesgado) sufre de limitaciones técnicas precisamente por el hecho de ser portable y abierto.
En las conferencias de la XPWeek, Sebastián Hermida nos explicaba los nueve reglas o (pasos) de Jeff Bay para conseguir mejores diseños orientados a objetos y, en general, código más limpio. Al loro, porque algunas te pueden sorprender:
Si eres un administrador de una máquina debian/ubuntu con un poco de amor propio seguramente no harás configure/make/make install o al menos te lo pensarás dos veces.
Os dejo aquí un script que permite ejecutar comandos predefinidos en un conjunto de máquinas. En realidad es un fabfile, es decir, un script para ejecutar con fabric.
El script que aparece en esta receta lo estoy usando para instalar un mismo paquete (debian) en varios servidores a la vez (lo cual es un latazo hacer una por una). Así que los comandos que tiene definidos son los recurrentes update, install y remove de aptitude. Obviamente se puede utilizar para ejecutar cualquier comando imaginable.
Llevo unos días oyendo a todo tipo de periodistas, tertulianos y «opinadores» profesionales de todo tipo, color y condición hablar sobre el asunto de la detención de la cúpula de la SGAE. E independientemente de la intención que está detrás de su opinión: echar la culpa a determinado tipo de gente, profesión, partido, ministra o presidente, todos coinciden en un argumento que me provoca verdadero estupor:
Seguro que más de uno se ha dado cuenta de que con la llegada de GTK3 no han aparecido los habituales python-gtk3 y compañía. Esto se debe a que ahora se utiliza un sistema de introspección de objetos que proporciona GObject (para que luego digan que no se puede hacer OO en C). Con este sistema se pueden crear «bindings al vuelo» de cualquier librería hecha con GObject con el consiguiente ahorro que implica no tener que hacer y mantener bindings. El sistema de introspección si que necesita bindings claro (PyGI), pero están integrados en python-gobject.
Quizá haya por aquí alguien que quiera escribir su PFC en LaTeX, pero sin liarse demasiado. Si es tu caso, instala la última versión del paquete arco-pfc incluye la clase LaTeX del mismo nombre (es decir, se usa directamente con \documentclass{arco-pfc}). Esta clase sigue el formato específico de la ESI de Ciudad Real, pero es fácil cambiarlo si estudias en otra parte.
En esta receta voy a contar cómo utilizar los «descriptores» de Python para poder crear atributos (variables de instancia) que no puedan cambiar de tipo durante la vida del objeto. Por supuesto, también es una excusa para aprender algo sobre los descriptores en sí.
This recipe shows how to setup a basic synchronization mechanism (similar to DropBox) by means of conventional GNU/Linux tools. This does not require root privileges and no packages (except ssh-server) need to be installed in the server.
Si utilizas Emacs y tienes varios PCs ¿cómo te apañas para que todos se comporten igual? Las mismas fuentes, los mismos colores, las mismas combinaciones de teclas… Realmente todo eso no es un gran problema; basta con tener tu ficherito .emacs en un repositorio personal para que todos los PCs tengan la misma configuración.
Pero ¿y los modulitos (los ficheros .el) que bajas de cualquier parte? Unos los bajas de un blog de alguien, otros de EmacsWiki, etc. etc. No es plan de subirlos también a tu repositorio de configuración, y además, aparecen nuevas versiones, sería un trabajo de chinos tenerlos actualizados. Hasta ahora yo había tomado la determinación de no utilizar ningún módulo de Emacs que no estuviera convenientemente empaquetado para Debian. Hasta ahora…
Donald Knuth, autor de «The art of computing programing» y creador de TeX es uno de los auténticos padres de las ciencias de la computación. Me temo que mucho menos conocido de lo que se merece.
Un Kōan es, en la tradición Zen, una especie de acertijo que el maestro propone a su discípulo para averiguar en qué punto se encuentra en su camino hacia la iluminación. Se trata de un problema cuya solución no puede ser encontrada a través de la razón, si no a través de la intuición…
Ya, ya, esto suena demasiado raro incluso para CRySoL.
Una de las cosas que más chocan al empezar a utilizar un lenguaje dinámico (Python, Ruby, Lua, etc.) es que las variables no se declaran o definen con un tipo concreto. Eso normalmente no es un problema y de hecho resulta bastante cómodo. Pero cuando un programa adquiere cierta envergadura empiezan a surgir problemas.
Poder forzar la interfaz de un método, sobre todo de un constructor es más que conveniente. Permite detectar muchos usos inadecuados cuando el usuario de una clase y su programador son personas distintas (o uno mismo si ha pasado demasiado tiempo). Esto es básico para cosas como el Diseño por contrato y otras metodologías en las que es imprescindible tener comprobación estricta de tipos.
La Escuela Superior de Informática en colaboración con Insula Barataria y CRySoL organizan un curso de introducción al Software Libre y GNU/Linux a partir de este mismo viernes 26 de noviembre.
El curso lo impartirán profesores de la ESI vinculados a los grupos de investigación Arco y Oreto. Son profesionales comprometidos con el uso y desarrollo de Software Libre y su difusión. Se trata de un curso muy orientado a la comunidad, que incide en las cuestiones sociales y filosóficas pero también en las importantes ventajas prácticas y tecnológicas del Software Libre.
Los ingresos de la matrícula de los alumnos se utilizarán para comprar material para los propios alumnos y en donaciones a la Free Software Fundation y otras entidades que promueven el software libre.
Me entero por Fernando Rincón en http://www.technologyreview.com/web/26678/ de PageSpeed, un proyecto bastante interesante de la mano de los chicos de Google. Se trata de un mod para Apache que implementa mejoras para optimizar la velocidad del servidor web.
Si lo pruebas en tu servidor, coméntanos tus impresiones.
La nueva versión del paquete arco-devel (la 0.46-1) incluye una configuración básica para el modo speedbar de emacs. Para usarla, simplemente añade lo siguiente a tu .emacs:
En las últimas versiones los chicos de GNOME han decidido que eliminar los iconos de menús y botones mejora la usabilidad. Si no estás de acuerdo, ésta es tu receta.
Aquí os pongo una lista de libros, documentos y enlaces para meterse en el mundo de los métodos ágiles y en especial en el TDD. La iremos completando. Deja tu comentario si quieres aportar alguno que conozcas.
Me entero por una noticia de barrapunto de un artículo bastante interesante que explica en detalle porqué Python es una buena opción para enseñar programación a novatos.
Después de unas cuantas décadas desde la «crisis del software», las cosas no han mejorado demasiado en las ciencias de la computación. El desarrollo de programas de computadora dista mucho de parecerse al proceso de fabricación típico de cualquier otra ingeniería; razón ésta por la que muchos consideran, no sin falta de razón, que el prefijo «ingeniería» le viene grande a la informática.
El principio KISS es uno de los principios de programación y diseño más conocidos y a la vez más difíciles de seguir. Como supongo que sabéis, KISS dice que «el objetivo principal de todo diseño debe ser la simplicidad».
Esta receta explica cómo incorporar a tus programas la posibilidad de realizar acciones cuando se crean, borran, cambian, etc. ficheros o directorios concretos.
El «centro de cálculo» del proyecto Manhattan (probablemente el primero de la historia) era una sala con un montón de grandes máquinas de IBM. Pero no eran computadores (hablamos del año 1944), eran máquinas completamente mecánicas y procesaban bloques de tarjetas perforadas.
Cómo cambiar rápida y cómodamente entre el fichero de implementación (.c, .cc, .cpp) y el de cabecera (.h, hpp) cuando se trabaja con un proyecto C o C++ (por lo visto también funciona con Ada y VHDL).
El tema es sencillo (o lo parece). Cuando utilizamos un contenedor de la STL (vector por ejemplo) ¿qué pasa con el contenido cuando se destruye el contenedor?
REST es el acrónimo de REpresentational State Transfer. Dicen que es un «estilo arquitectural». Seguramente te has quedado como yo, pero es que no es fácil encontrar material para entender realmente de qué va esto. Aquí os dejo algunos enlaces:
Esta receta es un compendio de pequeños trucos y utilidades para manipular ficheros PostScript con los programas libres habituales en un sistema GNU
En realidad pienso ir apuntando aquí las soluciones que voy encontrando a problemas que me surgen cuando tengo que hacer ciertas «operaciones imprevistas» con ficheros PS. Se admiten sugerencias para ir incorporando a la receta.
Convertir un documento a formato de varias páginas por hoja
Virtualbox permite crear un fichero .vmdk especial que «apunta» a una partición real de un disco duro. De ese modo es posible arrancar un sistema operativo instalado realmente en la máquina pero virtualizado dentro de otro S.O. El comando para lograrlo es:
Cómo interconectar dos redes inaccesibles entre sí ya sea porque ambas están detrás de NAT o por consecuencias de las nuevas e incomprensibles «políticas de seguridad» de la empresa.
GMX es una empresa alemana que ofrece servicio de correo (web, POP e IMAP), jabber y WebDAV de forma gratuita y de gran calidad. No está de más tener una alternativa en un mundo cada vez más dominado por Google.
Pues estaba buscando en CRySoL un enlace que yo mismo puse a una magnifica colección de Citas de Dijkstra. Pero claro, parece ser que todo lo que no esté en CRySoL resulta ser efímero y acaba por desaparecer.
¿Puede la industria del software comercial ofrecer una verdadera calidad en sus productos igual que la NASA o la ESA exige a sus proveedores? ¿Será éste el nacimiento de una auténtica ingeniería informática?
Hace no mucho me enteré por Paco de que el escudo/emblema/anagrama que usamos habitualmente y que usan muchas de las escuelas de informática de España está mal, principalmente porque tiene una rama de trigo y debería ser de olivo. A ver qué hago ahora con el pin tan chulo que me dieron cuando acabé… Se utiliza en documentos oficiales como la guía docente de la ESI (que por cierto el que aparece ahí es obra de Paco Moya y en el documento no se le da crédito por ello).
Permite asignar combinaciones de teclas personalizadas a cualquier opción de un menú solo con pulsarla mientras está seleccionado. Siempre me pareció una gran feature.
Esta receta incluye unas simples pautas para decidir qué referencias son adecuadas a la hora de elaborar cualquier documento técnico. En particular voy a hablar de referencias a documentos electrónicos aunque mucho de lo que digo creo que podría aplicarse también a libros y artículos científicos. Siento que los ejemplos que voy a poner sean tan mono-temáticos pero obviamente no me atrevo a hablar de buenas o malas referencias en campos que no conozco.
Parece que hay algunos problemillas legales en eso de que el gobierno intervenga las comunicaciones de los ciudadanos. A ver si aprenden de España; aquí si aparecen problemas legales para aplicar medidas antipopulares (es decir, en contra del pueblo) pues se cambia la ley, vaya problema!
El fit-PC es un computador basado en el chip Geode con un tamaño realmente pequeño (12×12×4 cm) pero con características muy interesantes. Esta receta explica como instalar Debian para sacarle el máximo rendimiento al pequeño de la casa.
La receta describe cómo preparar un servidor DHCP para instalar Debian (por PXE o Etherboot) en otras máquinas de la misma red (“netboot” lo llaman). Esto es especialmente útil cuando el PC en el que quieres instalar Debian no tiene lector de CD-ROM, como pasa en los netbooks (EeePC, Aspire One, etc) y otras cosas más “raras” como el fit-PC. Si lo pruebas verás que es más sencillo, cómodo y rápido que recurrir al arranque por USB.
Ya lo avisé, la manía (rozando la esquizofrenia) de llamar “Linux” a todo lo que pillas porque “es un nombre muy chulo” acabará siendo el fin del mejor y más importante invento del ser humano: el lenguaje. Cuando todo se llame “Linux” y sea imposible entendernos, la humanidad estará condenada a su propia extinción…
Barrapunto: " La fundación Linux presenta el concurso ‘Soy Linux’ ":http://softlibre.barrapunto.com/articles/09/01/16/1454211.shtml
Esta receta es una lista de programas de análisis de tráfico de red que están disponibles como paquetes Debian oficiales y que pueden resultar muy útiles
Voy a ir publicando como posts partes sueltas -pero con significado autónomo- de los libros Pensar en C++ I y II. La idea es darle un poco de visibilidad al proyecto, y de paso si alguien encuentra algún error o hace algún comentario puede ayudar a la revisión.
He encontrado casi por casualidad la página web de Javier Bezos (el maintainer de babel y algunos paquetes más) y me parecido muy interesante una página en la que explica las decisiones en spanish para babel que han tomado. Muy curiosa la explicación de la controversia tabla/cuadro que sé que preocupa a algunos miembros de CRySoL :-)
Decía Einstein que «hay dos cosas infinitas: el universo y la estupidez humana…». Yo añadiría unas cuantas más: la inmoralidad, la codicia y la ausencia de escrúpulos de la industria del copyright. ¿Hasta dónde serán capaces de llegar? Manipular niños: HECHO. siguiente?…
Por si necesitabas algún motivo más para sentir vergüenza de ser español
El título de este post es el slogan de la campaña Si eres legal, eres legal del Ministerio de Cultura, pero perfectamente podría ser el de cualquier ciudadano que quiera preservar su derecho a acceder libremente a la cultura. Porque mentir a la población diciendo que la ley dice cosas que no dice no debe ser muy legal, no? Al menos parece bastante inmoral.
Cómo instalar nuestra querida Debian en el Acer Aspire ONE. Sé que hay varias buenas recetas sobre lo mismo, pero son efímeras y al final nos quedamos sin receta. CRySoL perdura.
Supongo que sabréis que el Ministerio de Cultura y estamentos privados tan reputados como la SGAE, la industria de los contenidos y las empresas de comunicaciones están preparando un proyecto para acabar con el P2P en España (la semana que viene) y parece que la propuesta va a ser el sistema francés de tres amenazas avisos.
Con todo esto de las atribuciones, las competencias, los títulos, las huelgas, la mala información y la pura y llana desinformación (incluso intencionada) es un auténtico reto enterarse de qué va todo esto y hacia dónde va (si es que va) nuestra amada/odiada, al 50%, carrera de Informática.
Esta receta es una pequeña introducción al soporte de Python para diseño orientado a objetos. Para programadores noveles, se aconseja primero la lectura de nuestra ya veterana receta Mini tutorial de Python.
Los nuevos tiempos del ECTS y el espacio europeo traen nuevos “aires” a la vida universitaria. Esta nueva metodología docente aboga por la evaluación continua y el control del progreso del alumno a lo largo del curso. Eso ya se estilaba en mi cole cuando hice la EGB, tampoco es que sea nada innovador.
Pues nada, se trata de escribir un programilla en el lenguaje que quieras, que tome por línea de comandos un número de cualquier tamaño (menor que un googolplex) y lo represente como en el siguiente ejemplo:
logging es un módulo de la librería estándar de Python para “imprimir” mensajes de log. En esta receta se explica cómo conseguir que cada tipo de mensaje aparezca en consola con un color diferente.
La Forma Canónica Ortodoxa u Orthodox Canonical Form (OCF) es un modismo muy utilizado en C++ y definido por James Coplien en su libro Advanced C++: Programming Styles and Idioms. Este modismo permite que un tipo(clase) definido por el programador se comporte como un «tipo concreto de dato», es decir, tenga las mismas características que un tipo proporcionado por el lenguaje.
Aunque ha salido en todos los medios (excepto A3 y algún despistado más) yo no podía dejar pasar la oportunidad de celebrar el 25º cumpleaños del proyecto GNU, precursor y todavía principal motor del software libre (y por muchos años), a pesar del empeño que muchos ponen en negarlo.
Felicidades también a todos los que usan el sistema operativo GNU (aunque no lo sepan)
Hace tan solo unos días, Phil (el autor de scapy) anunciaba en la lista de correo una nueva (y muy remodelada versión de scapy): la 2.0.0.0. Y como es menester, ya está empaquetada para Debian y disponible en los repos oficiales de Debian con el nombre python-scapy.
Más de una vez (y de dos) he oído hablar sobre extrañas normas no escritas (o eso espero) sobre «buenas prácticas» de programación. De entre todas ellas, me permito destacar:
El break solo se puede usar en los switch (en cada case).
Usar el continue es un pecado capital, al infierno de cabeza.
El return solo puede ir en la última línea de una función o método, y únicamente para retornar algo. De lo contrario sufrirás indecible tormento.
Y la clásica: Usar el goto está penado con sufrimiento eterno.
Con esta paradoja se puede resumir la situación de la seguridad informática últimamente. Empezamos con la clave privada predecible de SSL en Debian (y Ubuntu y derivados, que son muchos), seguramente la cagada más grande en materia de seguridad de su historia.
Como supongo que sabéis, los pobres desgraciados que osan utilizar "continue" van al infierno y arden como teas por toda la eternidad. El castigo por usar "goto" no es muy distinto:
Interesante artículo sobre errores de programación que cometemos todos. Está especialmente orientado a programación orientada a objetos (valga la rebuznancia).
Mercurial es otro sistema de control de versiones distribuido (otro más) que no tiene nada (o poco) que envidiar a git (en lo referente a prestaciones) pero casi tan fácil de usar como subversion. Esta recetilla incluye unas nociones de su uso básico y algunas buenas referencias.
X-Wrt (a.k.a Webif2) es una interfaz web que facilita la administración y configuración de La Fonera y otros routers que usen OpeWrt. Webif2 está disponible como paquete ipkg, así que su instalación resulta tremendamente simple.
Esta receta es un resumen quick & dirty de los pasos necesarios para instalar un sistema OpenWRT estándar en La Fonera. Básicamente es una traducción simplificada de las dos recetas que aparecen en las referencias.
Esta receta explica cómo añadir de una forma muy fácil títulos a tu colección (gestionada con GCStar) mediante un scriptillo hecho en Python + amara. (menudo combo! :-))
El objetivo es borrar ficheros, directorios o incluso particiones de modo que sea imposible recuperar los ficheros originales. Eso se consigue a base de escribir datos aleatorios y normalmente ceros después. La utilidad de esto es, obviamente, que ningún listillo pueda recuperar datos sensibles de tu disco duro, disco externo, etc.
Se trata de un frontend para bittorrent y wget escrito en PHP. torrentflux-b4rt es un fork de torrentflux más flexible, ligero y potente que el original. En esta receta se explica cómo instalarlo sobre lighttpd y sqlite.
Desde el pasado día 8 de febrero, y con la inestimable ayuda de nuestro developer local (Paco Moya), amara ya es paquete Debian oficial. Amara es un toolkit sencillísimo para tratamiento de XML, con soporte de DOM, SAX, XPath, etc y todo de una manera muy “pythonica”. Nunca fue tan fácil tratar documentos XML.
Un “router chupachups” (más conocido como router on a stick) es una máquina que ruta tráfico entre dos o más redes que coexisten en la misma red física. Eso se consigue normalmente por medio de VLANes (aunque éste no es el caso). Es decir, es un router con una única interfaz de red.
Un par de lecturas muy interesantes (tanto para alumnos como para profesores) sobre los estudios en Computer Science. Es la opinión contrastada de dos profesores de la Universidad de Nueva York acerca del gran daño que hacen los nuevos planes de estudios a los titulados de hoy en día. Quizá lo más chocante (aunque no para todos) de sus conclusiones es el daño que, según ellos, causa Java como lenguaje para enseñar programación.
Incluye frases tan demoledoras como:
In short, today’s Java library cobbler is tomorrow’s pizza delivery man.
GNOMEVFS es una librería para realizar todo tipo de operaciones sobre ficheros independientemente del método de acceso necesario para llegar a ellos (FTP, HTTP, WebDAV, SMB, etc). Esta receta muestra ejemplos de lo sencilla y potente que puede llegar a ser esta pequeña maravilla.
Serie de 3 libros electrónicos sobre programación. El propio autor explica:
How do you build skills in programming? By doing a series of programming exercises that are focused on showing language features one at a time. These books build skills without asking you to assimilate too many technical concepts in a single sitting.
Esta receta incluye únicamente una clasificación de patrones a modo de catálogo y una pequeña descripción de cada uno. Desde aquí enlazaré las recetas específicas para cada patrón.
El título de este post es una frase acuñada por David Bravo y de la que cada día vemos más ejemplos. Hoy, otra prueba de que la libertad de expresión es un espejismo.
Desde hace ya algunos meses, nuestro teclado no es el que era. Me refiero a la forma de escribir el carácter virgulilla (también llamado ‘tilde’). ¿Qué ha pasado?
La nueva versión del paquete de scapy ya está en los repositorios de Debian. No es una nueva release, pero corrige un bug bastante tonto aunque importante que impedía utilizar scapy como módulo.
Por si alguien quiere probarlo, os comento que he puesto en el repo de GNESIS una utilidad a la que hace mucho que le tenía ganas. Es un applet para GNOME que indica en pantalla el nombre del escritorio actual (workspace en la jerga gnomera).
Una colección de recetas, tutoriales y enlaces sobre cómo hacer y mantener paquetes Debian. La iré completando con el tiempo. Si encuentras algún otro enlace interesante, por favor, deja un comentario.
Pues eso, enlazo unas cuantas frases atribuidas a Edsger Dijkstra, un gran científico y una de las mentes más sobresalientes de la Ciencia de la Computación.
Llevo un par de tardes mirando qué alternativas hay en GNOME para pintar texto en pantalla, es decir OSD, y he pensado ponerlo aquí en plan receta por si a alguien le resulta de utilidad y sobre todo para tenerlo a mano cuando me haga falta.
Esta receta explica cómo instalar y configurar dicho SAI en un sistema Debian GNU/Linux o derivado para sacarle el máximo partido. Te recomiendo que leas al menos la introducción de Configuración y disfrute de un SAI para que tengas una idea de lo que se puede hacer y lo que necesitas, ya que no lo voy a repetir aquí.
Esta receta incluye la implementación “comentada” de una metaclase Python para conseguir que el constructor de la superclase se invoque automáticamente.
Esta receta es una pequeña introducción a la meta-programación, concretamente voy a contar algunas cosillas sobre uno de los mecanismos más populares y potentes: las metaclases.
Esta receta trata algunas prestaciones interesantes que ofrece el driver intel (para tarjetas nuevas) por medio de la utilidad xrandr. Lo realmente interesante es que puedes activar y desactivar la salida externa y cambiar la resolución de ambos monitores sin tener que reiniciar el servidor X.
Como ya sabrás, los discos duros no son perfectos, y cuando hacen “crash!” no hay mucho que se pueda hacer. ¿o sí? Esta receta explica cómo recuperar datos de un disco duro durante su agonía, o intentarlo al menos.
Si usas con frecuencia ssh, habrás notado que muchas veces tarda muchísimo en conectar incluso aunque utilices autenticación por clave pública. Estos son algunos ajustes de configuración que pueden hacer que la conexión sea mucho más rápida.
Acelerando el login
DNS
Si la máquina a la que quieres conectar tiene IP fija, puedes utilizar tu fichero de configuración de ssh para indicar la IP y así te ahorras resolver la dirección de la máquina cada vez que conectes. Para eso, escribes en ~/.ssh/config:
Host example.com
Hostname 208.77.188.166
User Gil.Puertas
Otra cosa que hace SSH y que puede influir mucho en la duración del «login» es la opción «UseDNS». Según dice el manual:
UseDNS specifies whether sshd should look up the remote host name and check that the resolved host name for the remote IP address maps back to the very same IP address. The default is “yes”.
Y claro, si trata de hacer la resolución inversa de una IP de una conexión ADSL puede tardar bastante (suponiendo que pueda). De modo que una buena forma de ahorrar unos valiosos segundos es poner lo siguiente en el /etc/ssh/ssd_config:
UseDNS no
Recuerda que ésta es una cuestión de seguridad que estás decidiendo no usar. La seguridad tiene un coste, pero no tenerla también, tú decides.
GSSAPI
GSSAPI es un API genérico normalizado para usar mecanismos de seguridad como Kerberos o SASL. Por defecto, al menos en Debian, ssh viene configurado para utilizar autenticación GSSAPI. Si no sabías lo que era, lo más probable es que no lo necesites. Así que lo puedes desactivar comentando la línea correspondiente en /etc/ssh/ssh_config:
# GSSAPIAuthentication yes
Esto supone una diferencia considerable en el tiempo de acceso. En una prueba ejecutando un simple “ssh example ls” en una máquina de la misma LAN, el tiempo necesario pasa de 15.2 a 0.1 segundos.
ControlMaster
Si sueles abrir varias sesiones (login, repos, sftp, etc) hacia el mismo servidor, SSH permite reutilizar una conexión establecida para sesiones adicionales. Eso supone un ahorro de tiempo considerable ya que no necesita establecer una nueva conexión. Para ello, simplemente escribe esto en un ~/.ssh/config
Host *
ControlMaster auto
ControlPath ~/.ssh/master-%r@%h:%p
Acelerando la transferencia
Si utilizas SCP o SFTP para copiar ficheros también hay algunas cosas que puedes hacer para mejorar la velocidad.
Compresión
SSH permite comprimir el flujo de datos, que muchas veces viene desactivado por defecto. Tienes que activarlo tanto en el servidor como en el cliente. Para el servidor edita /etc/ssh/sshd_config y añade una línea tal que:
Compression delayed
Es la opción por defecto si no se especifica. Para el cliente puedes activarlo para todo el mundo editando el /etc/ssh/ssh_config:
Compression yes
O que sólo los usuarios que lo deseen escriban esa línea en su ~/.ssh/config.
Comentarios
Si conoces otras formas de mejorar el rendimiento de SSH, por favor, deja un comentario.
Los responsables de la oficina electoral “nuevos tiempos” nos han invitado a dar una charla sobre software libre. Ellos lo han llamado “conferencia” aunque mi idea es que sea mucho menos formal y mucho más participativo que una “conferencia”, pero vale, intentaremos que lo parezca.
El próximo jueves a las 11:30 será el acto de presentación del cub.net de Ciudad Real en la ESI. No os lo perdáis, seguro que ofrece muchas y fascinantes oportunidades para todos.
Esto es tan chorra que casi me da pena ponerlo, pero bueno, igual a alguien le sirve. Pues eso, se trata de un “script” (una línea de shell) para general un fichero .m3u a partir de los ficheros .mp3 que haya en un directorio, o sea:
Esta receta explica cómo usar las utilidades de comprobación de ortografía «mientras escribe» que trae GNU Emacs en su distribución oficial. Por mucho que insistas, no tienes excusa para escribir mal.
Microsoft nos sorprende una vez más con su innovadora tecnología. En esta ocasión se trata de ReadyBoost. Al parecer se trata de una “feature” que permite al sistema optimizar el acceso a disco usando dispositivos Flash. Aunque he leído que la idea es utilizar ese espacio del pendrive como memoria virtual me resisto a pensar que en verdad sea así.
Recientemente hemos instalado en nuestro drupal el módulo “taxonomy_images”, que permite poner una imagen alusiva a cada término de las taxonomías. En principio sólo vamos a asociar imágenes a los “tipos de nodo”, que son:
¿Estás harto de que las solapas de Iceweasel(Firefox) se cierren cada vez que intentas cortar un trozo de texto pulsando “C-w”? Si te pasa eso es porque eres un honorable usuario de emacs y la extensión Firemacs es la solución a tus problemas.
La que más echaba de menos era el “C-s” y buscar el siguiente con otro “C-s”, qué alivio!
Esto debe tener más años que el sol, pero yo lo vi el otro día. Se trata de material docente de la Stanford CS Education Librar sobre los punteros y la gestión de memoria. Destacan, por lo raro, los vídeos de Binky Pointer Fun Video en los que Binky (un muñeco de plastilina) explica cómo funcionan los punteros en distintos lenguajes: C, C++, Ada, Java, etc. Los punteros nunca fueron tan fáciles.
Saludos
Cómo configurar Apache2 para disponer de un directorio WebDAV, accesible para lectura/escritura desde GNOMEVFS, konqueror, cadaver o como una “web folder” desde el “sistema operativo más rentable de todos los tiempos”.
Esta receta en realidad es una traducción de un artículo de Rob Klein titulado Packet Wizardry: Ruling the Network with Python usando la magnífica herramienta scapy. Igual es un poco largo para receta, pero bueno, no tiene desperdicio.
A través del blog de David Bravo he sabido de un artítulo de El País, que describe de un modo bastante acertado cómo es el mundo en la ‘era de Internet’ (al menos eso me parece a mi).
Se trata de usar subversion para controlar los cambios en un directorio, normalmente ficheros de configuración, para que si metes la pata, puedes saber qué demonios has cambiado.
Cómo usar el servidor subversion para ejecutar automáticamente programas personalizados. Como ejemplo, la receta explica cómo actualizar una página web mantenida en un repositorio.
Esta receta es un “remake” de la que hizo Nacho (con su permiso) sobre el mismo tema. Sólo tiene algunos añadidos y alguna pequeña corrección.
Ingredientes
Módem ADSL Contrend CT-350 USB de Telefónica “el azulito”.
Debian GNU/Linux
Linux >= 2.6.10
subversion
unp
br2684ctl
ppp
pppoe
Módulos
Descarga los fuentes con subversion:
$svn co svn://svn.gna.org/svn/ueagleatm/trunk/ueagle-atm
A ueagle-atm/usbatm.h
A ueagle-atm/ueagle-atm.c
A ueagle-atm/COPYING
A ueagle-atm/usbatm.c
A ueagle-atm/Makefile
Revisión obtenida: 323
Puedes echar un vistazo a /var/log/syslog para comprobar que todo ha ido bien. Debe aparecer algo como:
[ueagle-atm] driver ueagle 1.3 loaded
usb 2-2: [ueagle-atm] ADSL device founded vid (0X1110) pid (0X9021) : Eagle II
usb 2-2: reset full speed USB device using uhci_hcd and address 3
usb 2-2: [ueagle-atm] using iso mode
usb 2-2: [ueagle-atm] (re)booting started
usbcore: registered new driver ueagle-atm
usb 2-2: [ueagle-atm] modem operational
usb 2-2: [ueagle-atm] ATU-R firmware version : 44e2ea17
Bridge RFC-2684
El programa br2684 es un puente para transportar diferentes protocolos sobre una conexión ATM, que es lo que suelen hacer los proveedores de ADSL. Para arrancarlo, ejetucta:
# br2684ctl -c 0 -b -a 8.32
br2684ctl[2508]: Interface "nas0" created sucessfully
br2684ctl[2508]: Communicating over ATM 0.8.32, encapsulation: LLC
br2684ctl[2508]: Interface configured
El 8.32 son el VPI y el VCI de tu ISP. Estos corresponden a Telefónica con IP dinámica. Si tienes otra cosa, tendrás que usar los adecuados.
Usuario/contraseña
Tienes que añadir el nombre de usuario y contraseña al final del fichero /etc/ppp/pap-secrets. Si tienes la ADSL de Telefónica, la línea es:
adslppp@telefonicanetpa * adslppp
Proveedor
También para Telefónica ADSL, escribe un fichero /etc/ppp/peers/adsl:
user "adslppp@telefonicanetpa"
mtu 1412 # IMPORTANTE: imprescindible si vas a compartir la conexión, en caso contrario puedes quitarlo
plugin rp-pppoe.so
nas0
noipdefault
usepeerdns
defaultroute
persist
noauth
Para levantar la interfaz
Y si todo ha ido bien, al ejecutar lo siguiente deberías tener una conexión perfectamente funcional:
# ifconfig nas0 up
# pon adsl
Y para desactivar la conexión
# poff
# killall br2684ctl
Automatizar la conexión:
Añade la siguiente sección al fichero /etc/network/interfaces:
auto ppp0
iface ppp0 inet ppp
pre-up br2684ctl -c 0 -b -a 8.32
pre-up ifconfig nas0 up
provider adsl
Seguro que más de una vez, y de 20, se os ha colgado el firefox (a.k.a iceweasel), lo matas (o se muere solo) y a veces al volverlo a ejecutar sale un mensajito como este:
Cuesta mucho hacer entender a un neófito “de Linux” cuáles son los motivos por los que vale la pena sufrir el software libre. Lo habitual hace un par de años era que sólo los que estaban dispuestos a currárselo se acercaran a este mundillo. Pero todo eso ha cambiado, gracias a (o por culpa de) cosas como Ubuntu o Beryl, una nueva horda ávida de nuevas experiencias (o cansada de las experiencias de su Windows) se lanza de cabeza a probar la última y supermolona live de Ubuntu. ¡La informática chachi (y gratis) ha llegado! pero no borres todavía el XP, que el “Dead or Alive” no tira en Ubuntu.
Cómo usar y aprovechar el soporte de Unicode que Python trae de serie. Si no tienes muy claro de que va esto del Unicode, te recomiendo leer primero la receta Unicode y UTF-8.
Esta receta recoge algunas herramientas que pueden resultar interesantes para trabajar con las cabeceras EXIF de los JPEG. Si lo que buscas es modificar la imagen propiamente dicha, mira la receta titulada Edición de imágenes en consola, con ImageMagick.
Esta receta explica los usos más habituales de iptables. No trata de ser un manual de uso, sólo son unos cuantos comandos que solucionan problemas frecuentes.
Esta receta recoge algunas posibilidades interesantes del programa a2ps. Por cierto, el título es sólo un juego de palabras, no abuses de la impresora que quedan pocos árboles y la tinta está muy cara ;-)
El principal objetivo de este concurso es estimular a los estudiantes universitarios para que se involucren en la participación y creación de proyectos SL. De esta forma se crearán las condiciones idóneas para generar un tejido tecnológico de futuros profesionales que serán capaces de dar soporte de soluciones basadas en SL a empresas y a la administración.
Según parece, el próximo curso se entregará una copia de GNESIS 2.0, en su versión DVD Live, a todos los alumnos en el momento de formalizar su matrícula. El DVD incluye el software necesario para las prácticas de muchas de las asignaturas, además de la Guía Docente del centro. Hablamos de qué es GNESIS no hace tanto.
GNU Emacs puede ser un excelente editor (como no?) también para SGML, XML, o derivados tan populares com XHTML o DocBook. Esta receta concretamente introduce el uso del paquete psgml, aunque hay otros.
La etiqueta de este nodo es “historia” aunque creo que le iría mejor otra como “scifi”. Nada que comentar del tema, podéis verlo y oirlo vosotros mismos… espeluznante…
Me ha llamado la atención esta guía de malas prácticas. Es curioso hasta qué punto muchos de nosotros seguimos o hemos seguido alguna vez estos consejos… ¿tú no? ¿seguro?
Esta receta recoge algunas features interesantes del frontend de consola de gphoto2
Introducción
gphoto2 es una librería que soporta un montón de modelos de cámaras fotográficas digitales. Además dispone de un pequeño frontend que permite usar la mayor parte de sus posibilidades desde consola, algo que puede resultar muy útil para automatizar tareas.
Ingredientes
gphoto2
una cámara digital soportada por gphoto2
Copiar todas las fotos con su fecha y hora
Situados en un directorio creado al efecto simplemente ejecuta:
$gphoto2 -P==--filename"%Y-%m-%d_%H:%M_%n.%C"==
Y gphoto2 descargará y renombrará todas las fotos y vídeos que tengas en la cámara, sin borrarlos de ésta. Dependiendo del modelo de tu cámara quizá tengas que indicar algún parámetro adicional como el puerto o similar; mira la documentación.
Si no te gusta tener tooodas las fotos en el mismo directorio, puedes utilizar este pequeño script Python para clasificar los ficheros en directorios por fecha.
Echa un ojo a la receta de Sacando jugo a EXIF, en consola que tiene algunos trucos útiles para clasificar y organizar fotos.
Esta receta explica cómo utilizar SAMBA para servir ficheros y cómo acceder a ellos desde otro ordenador. Supondremos que en ambos equipos tienes Debian o sucedáneos.
hdparm es una pequeña herramienta que sirve para manipular la configuración de las unidades de disco. El objetivo es optimizar el tiempo de acceso o la velocidad de transferencia.
No creo que sea un problema para muchos de los que andamos por aquí, que dudo que vayamos a poner “el Vista” es nuestro portátil, pero me ha parecido curioso un artículo titulado Vista beta sucks up battery juice por el “precio” que tendrán que pagar muchos por tener un escritorio super-pijo. Cada día más motivos para pasarse a Windows…
Esta receta explica qué hacer para poder reproducir DVD en nuestro sistema operativo favorito. Puede resultar trivial para un iniciado pero como ya me lo han preguntado alguna que otra vez lo dejo aquí para la posteridad :-)
Éste es fácil. Se premiara la claridad y elegancia del código. Pero que quede claro que la programación no es arte :-)
Hacer un programa que cuente las funciones (no prototipos) que hay en un fichero C. Debe imprimir el resultado por salida estándar. Puedes utilizar cualquier lenguaje. No se veta el uso de NINGUNA característica de ningún lenguaje.
Esta receta explica qué hacer para poder utilizar dicha cámara con gphoto2. La cuestión es que esta cámara no es reclamada por ningún driver, a pesar de que está soportada por libgphoto2. De modo que el motivo real de esta receta es explicar lo qué puedes hacer en estos casos, sea con ésta o con cualquier otra cámara en las mismas circunstancias.
Como el año pasado, la asociación “linux Albacete” organiza las Jornadas de Software Libre. Tendrán lugar los días 20, 21 y 22 de abril en la Escuela Politécnica de Albacete.
No te voy a engañar, emacs es complejo pero ¿qué hay que merezca la pena y no lo sea?. Si algo tiene emacs son opciones y comandos, cienes y cienes de ellos. Y claro, cuando necesitas hacer algo, no te acuerdas de cuál era el maldito comando y tienes que ponerte a mirar la documentación, aunque en realidad siempre acabas buscando las mismas cosas. O quizá sólo me pasa a mi. Pues en esta receta voy a poner los comandos que suelo necesitar y que siempre se me olvidan, que son casi todos.
Aunque parece el título de una película de miedo, el «kill ring» es la peculiar manera que tiene emacs de entender el ‘portapapeles’. En lugar de tener un único espacio de almacenamiento donde cortar y pegar, emacs tiene una pila; la verdad es que de entrada sí que acojona un poco… :-P
No, no, tranquilo, el título de la noticia es ficticio, por el momento al menos. Sin embargo, cada día tengo más razones para pensar que no pasará mucho tiempo hasta que se haga realidad y lo veamos en un periódico de tirada nacional y/o televisión.
Esta receta pretende ser una chuleta de pequeños trucos y utilidades para manipular DVD Video, usando los programas libres habituales en un sistema GNU
Copiopego de la entrevista en barrapunto a Ricardo Galli. Me ha parecido curioso que alguien le preguntara esto:
9) Profesores universitarios
por HaCHa
¿Qué opinas de la situación y las condiciones laborales bajo las que ejercen su profesión los profesores asociados de las universidades públicas este país?
Ricardo:
Están fatalmente pagados, salarios de miseria, casi vergonzosos. Al igual que los ayudantes y un poco en menor medida los colaboradores.
No sé si estáis informados sobre los detalles de la nuevaLey de PropiedadIntelectual= que, como era de esperar y conociendo como conocemos a los “entusiastas” del copyright, es aún más restrictiva que la anterior. La ley aún no es definitiva, pero es poco probable que el texto sufra modificaciones importantes. No parece que haya habido mucho debate, todos los partidos han estado bastante de acuerdo desde el principio; sólo se han negociado pequeños detalles. Unanimidad a la hora de hacer una ley que antepone el beneficio económico de una minoría al beneficio cultural de la gran mayoría.
Esta receta es (o será) un compendio de pequeños trucos y utilidades para manipular ficheros AVI usando los programas libres habituales en un sistema GNU.
La primera edición de la Party Quijote se celebró el año pasado en Albacete y fue organizada por la EPSA. Asistieron más de 400 personas que participaron durante 3 días en numerosos talleres, concursos, juegos y actividades de toda índole informática, incluyendo promoción y uso de software libre.
CVS es un sistema de control de versiones concurrente. Era hasta hace poco el más utilizado en proyectos de software libre, está siendo rapidamente reemplazado por subversion por sus evitentes ventajas prácticas. En esta receta se explica cómo realizar las operaciones básicas con un repositorio CVS.
Esta receta explica una forma sencilla de hacer una copia de seguridad de una base de datos MySQL completa para poderla restaurar en caso de catástrofe o mudanza.
Supongo que todos lo habéis visto en Barrapunto, pero lo pongo de todos modos para que quede constancia. Está bien que se vea que en Castilla La-Mancha hay gente que de verdad usa y contribuye al software libre, y no sólo dice que lo usa. Mi enhorabuena desde aquí para Carlos González Morcillo, profesional donde los haya, y también para su equipo. Si todos los profesores hicisemos nuestro trabajo la mitad de bien que Carlos, seríamos la mejor universidad de España, como poco.
Cómo activar el soporte SSL de apache-2 para utilizar HTTPS y navegación segura. Los pasos que se describen son para una Debian o sucedaneos, pero supongo que no será muy distinto a otra distro.
Esta receta trata únicamente de las peculiaridades de este módem a la hora de compartir la conexión. Quizá te interese nuestra receta sobre Compartir la conexión s Internet con GNU/Linux para cuestiones más generales.
Subversion es un sistema de control de versiones concurrente. Su objetivo es muy similar al de CVS aunque tiene grandes ventajas sobre éste, y por eso, cada día muchos proyectos de desarrollo de software cambian a subversion.
Algunas de las miles de distribuciones live que ruedan por ahí tienen una característica muy interesante; consiste en montar tu home desde un disco USB. De ese modo vayas donde vayas puedes tener un sistema decente. Pero a esto le veo varios problemas.
Esta receta explica formas de conocer la IP pública con la que te estás concectando a Internet
Si utilizas un router o algo del estilo que incorpore un servidor DHCP, la dirección asignada a tu ordenador con toda seguridad será una dirección IP privada Pero a veces, es necesario conocer cuál es la IP pública con la que sales a Internet, con el fin de configurar un cliente DNS dinámico u otro tipo de aplicación específica.
Para conocerla puedes usar alguno de estos métodos:
lynx -dump http://checkip.dyndns.org/ | grep IP | awk {'print $4'}
$curl -s checkip.dyndns.org | grep-Eo'[0-9\.]+'
Shell (avisa por mail)
#!/bin/bash
# Requiere los paquetes "mailx" y "lynx"
# Te envía un email cada vez que te cambia la IP pública. Ejecutar en background
while true
do
old_ip="`cat ~/public.ip 2> /dev/null`"
new_ip="`lynx -source http://www.whatismyip.com/ | grep '<TITLE>' | awk '{print $4}'`"
if [ "$old_ip" != "$new_ip" ]; then
echo $new_ip | mail tu@email.com -s "Tu IP ha cambiado"
echo $new_ip > ~/public.ip
fi
sleep 60
done
PHP
<?phpecho"Tu dirección IP externa es: ",$_SERVER['REMOTE_ADDR'];?>
Acabo de ver en la tele la nueva campaña de “concienciación” y en contra de la piratería. El anuncio apela a los sentimientos del cuidadano instándole a preservar nuestra cultura “no pirateando”. Pero la cultura no se protege encerrándola bajo llave. La cultura se preserva sacándola a la luz y haciéndola llegar al mayor número posible de personas, compartiéndola. Las lenguas muertas lo están porque nadie las usa (sus respectivos propietarios deben estar muy contentos :-) )
Yo aún no la he probado, pero la 1.2 estaba muy bien y si ésta está basada en Breezy merece la pena echarle un vistazo. Se puede descargar directamente. Más información en la página de Molinux
devhelp es un brower de documentación técnica. Hay disponibles libros para instalar en devhelp. Un libro es la documentación empaquetada de algún programa o herramienta concreta. Esta receta explica como hacer tus propios libros.
En esta recetilla se explica el uso de alguos programamas de Debian (o distros derivadas) que pueden ayudar a mantener el sistema limpio y no tener más basura de la deseada
Recogiendo las sugerencias que muchos habéis hecho después de la party, creo que una buena opción es hacer algo parecido a lo que apuntaba Tobías. Me explico:
Se trata de reunirnos en un aula o laboratorio (dependiendo de la disponibilidad). Alguien cuenta a los demás el uso de alguna herramienta o cualquier otra cosa curiosa, o que consiedere útil o divertida. Es una especie de receta en vivo, aunque también debería pasar a ser una receta escrita para que quede constancia.
Como usar GNU less para ver ficheros fuente con resalte de sintaxis en consola
Aprovechando lesspipe es sencillo conseguir que less se comporte de modo distinto dependiendo del tipo de fichero que se abre y de ese modo integrarlo con highlight o GNU source-highlight para conseguir resaltado sintáctico en consola.
1. lesspipe
lesspipe es un programa que permite modificar el comportamiento de less de un modo muy sencillo. Primero debes escribir un fichero $HOME/.lessfilter. Este fichero normalmente es un script bash que debe tener permisos de ejecución.
En los próximos apartados se incluyen ejemplos de lessfilter para highlight y souce-highlight que se utilizan para colorear código, aunque en realidad se puede usar less para todo tipo de ficheros, como listado de archivos comprimidos, imágenes, ps, html, etc.
Para que funcione es necesario además incluir lo siguiente en tu fichero $HOME/.bashrc:
Es una utilidad que permite colorear ficheros fuente de varios lenguajes y generar varios formatos de salida, como HTML, LaTeX o secuencias de escape ANSI.
La posibilidad de generar salida para la consola (opción -A) se incorporó en la versión 2.1, así que asegúrate que tienes una versión igual o superior.
Fichero .lessfilter
#!/bin/sh
set -e
file "$1" | grep text > /dev/null
highlight -A "$1"
exit 0
Si usas highlight 2.2-4 o posterior el script es aún más sencillo:
Cómo utilizar module-assistant para instalar el driver propietario para las tarjetas gráficas de nvidia en Debian GNU/Linux, Ubuntu y demás distros derivadas.
Hay varias alternativas para instalar este driver. Esta receta explica la forma más sencilla, que es también la más “Debian compliant”. Consulta las referencias si quieres probar las otras alternativas.
Actualiza tu Linux
Instalar el driver de nvidia es una buena oportunidad para aprovechar y actualizar el núcleo. Se supone que vas a utilizar un Linux precompilado y empaquetado por Debian. Por ejemplo:
#apt-get install linux-image-2.6.22-1-386
También vas a necesitar las cabeceras, que es un paquete con el mismo nombre, cambiando image por headers.
#apt-get install linux-headers-2.6.22-1-386
Si usas grub, no olvides hacer el update-grub correspondiente. Y ahora reinicia para usar el núcleo recién instalado.
Ahora… lo divertido
Esto es tan fácil que casi no tiene gracia. Primero instala module-assistant y nvidia-kernel-common:
Esto crea el /etc/apache2/ssl/apache.pem que contiene el certificado y la clave del servidor. El número de serie debería ser uno más de lo que haya en el certificado anterior.
En /etc/apache2/ssl.crt/ hay sendos enlaces simbólicos (server.key y server.crt) que apuntan al fichero generado.
A veces se necesita ejecutar un programa con interfaz gráfica que reside en una máquina distinta y queremos verlo en la máquina que estamos. Esta receta explica cómo conseguirlo sin tener que abrir una sesión X ni tener que utilizar un “escritorio remoto” como vnc.
Método 1: Exportar display
El método ‘clásico’ cuando queremos ejecutar un programa en una máquina remota y ver su interfaz en nuestro cliente X local es:
user@local:~$xhost remoto
remoto being added to access control list
user@local:~$
Con eso se consigue que el servidor X, que corre en nuestra máquina, acepte conexiones externas de la máquina “remoto”. Pero si queremos que admita conexiones de cualquier máquina hay que poner:
user@local:~$xhost +
access control disabled, clients can connect from any host
user@local:~$
Aunque esto puede suponer un problema de seguridad grave.
Ahora accede a la máquina remota con telnet o algo similar y exporta el ‘display’ para aplicaciones X.
La instrucción export declara una variable de entorno de la shell (no tiene nada que ver con la expresión exportar display).
Con esto, la aplicación X sabrá que debe utilizar el servidor X de la máquina llamada ‘local’ en lugar de usar el de la máquina en la que se ejecuta. Puedes comprobar que funciona con algo como:
user@remoto:~$xeyes
user@remoto:~$
Con lo que deberías ver el clásico programilla de los ojos en la máquina local.
Método 2: ssh
El servidor ssh es capaz de gestionar automáticamente la conexión X siempre que servidor y cliente estén configurados adecuadamente.
Edita el fichero /etc/ssh/sshd_config del servidor y haz la siguiente modificación, que sirve para que el servidor ssh remoto devuelva el tráfico X11.
X11Forwarding = yes
Edita el fichero /etc/ssh/ssh_config del cliente y haz la siguiente modificación, Esto hace que el cliente ssh local solicite el tráfico X11.
ForwardX11 = yes
Como alternativa a esto, el usuario puede solicitarlo por línea de comando al hacer la conexión:
ssh -X <em>remoto</em>
Si lo haces en las dos máquinas, podrás utilizar este mecanismo en ambos sentidos. Sólo queda reiniciar el servidor con:
ATENCIÓN: Aunque los efectos visuales de 3ddesktop pueden seguir resultando interesantes para alguno, XGL deja a este programa bastante obsoleto. Mira la receta de XGL y Beryl en Ubuntu Dapper si de verdad quieres increibles efectos 3D en tu escritorio libre.
Acabo de ver esta noticia en barrapunto de nuestros colegas de Albacete sobre el fenómeno BookCrossing y era algo a lo que hace tiempo que llevaba dándole vueltas. Creo que es un mecanismo sencillo y barato para difusión de cultura libre. ¿Qué te parece? ¿Crees que podría funcionar aquí? ¿Estarías dispuesto a ayudar a poner el tema en marcha?
Esta receta es muy similar a esta otra de SSHfs + FUSE. La diferencia es que aquí se usa un driver específico llamado SHFS. Igualmente se trata de acceder a ficheros de una máquina remota a través de SSH.
Esta receta es un compendio de pequeños trucos y utilidades para manipular ficheros PDF con los programas libres habituales en un sistema GNU
En realidad pienso ir apuntando aquí las soluciones que voy encontrando a problemas que me surgen cuando tengo que hacer ciertas «operaciones imprevistas» con ficheros PDF. Se admiten sugerencias para ir incorporando a la receta.
En realidad se trata de aumentar los márgenes reduciendo el tamaño del área impresa. También con pdfnup:
$pdfnup --nup 1x1 --scale 0.9 original.pdf
Cambiar el formato de página
Si tienes que imprimir un .pdf cuyo formato de página no es A4 probablemente acabarás desperdiciando gran parte de la hoja porque por aquí todas las impresoras domesticas son A4. Con los siguientes comandos puedes convertir el formato de página:
Si has hecho un .pdf con pdflatex lo más probable es que no incluya las fuentes, de modo que el programa pueda renderizar el documento con las fuentes del sistema. Sin embargo, a veces se requiere disponer de un .pdf auto-contenido para garantizar que se verá del mismo modo en cualquier parte. Para lograrlo ejecuta lo sisguiente:
Esta receta explica cómo configurar un ordenador con Debian (también Ubuntu y sucedáneos) para que sirva como router de tu pequeña red doméstica. La idea es que varios equipos puedan salir a Internet por medio de una sola conexión y con una única IP pública. Una vez consigas esto, hay varias cosas más que puedes hacer con él...
Ingredientes
Un ordenador:
Este equipo hará de router. Sirve cualquier cosa mayor de un Pentium. Un K6 o un PII con 64 MB de RAM es más que suficiente para los servicios básicos. Es una buena oportunidad para reciclar tu viejo sobremesa, una vez instalado le sobre el monitor, teclado, ratón, CD-ROM y tarjeta de sonido; la de vídeo déjala puesta por si acaso.
iptables:
Herramienta de administración de filtrado de paquetes IP.
Un Linux "de los nuevos":
Como vas a utilizar iptables necesitas un Linux-2.6 o superior (aunque también serviría un 2.4).
dnsmasq >= 2.46:
Es un servidor DHCP y caché DNS muy versátil y fácil de configurar.
Configuración de las interfaces de Red
Ese ordenador "de desecho" del que hablaba antes lo llamaremos a partir de ahora con el original nombre de Router. Bien, Router debe tener, al menos, dos interfaces de red:
Una conexión a Internet (eth0).
Debe ser algún tipo de conexión a Internet, que puede ser RTC, ADSL, cable-modem, etc. Supondremos para esta receta que usas un modem ADSL con conexión Ethernet.
Conste que podría ser RDSI, ppp o cualquier otro tipo de interfaz de red sin que ello afecte al resto del procecimiento. Supondremos que esta interfaz ya la tienes configurada conforme a las instrucciones de tu ISP.
Una conexión a tu red local (eth1):
Será una tarjeta de red Ethernet 10/100. Esto permitirá que puedas enchufarle un conmutador y conectar "cienes y cienes" de ordenadores si quieres.
Esta interfaz debes configurarla de forma estática, con una dirección IP privada, por ejemplo 192.168.0.1.
Aquí puedes ver un fichero completo /etc/network/interfaces para el caso en que eth0 se configure por DHCP contra tu ISP.
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet dhcp
auto eth1
iface eth1 inet static
address 192.168.0.1
netmask 255.255.255.0
broadcast 192.168.0.255
Activa el forwarding (reenvío)
Normalmente un ordenador conectado a una red TCP/IP descarta todos los paquetes IP que le llegan pero no van dirigidos a él, es decir, aquellos cuya direcci IP no corresponde a ninguna de las interfaces de la máquina. Sin embargo, un router debe tratar paquetes IP que no son para él. Para conseguir esto debes activarlo explícitamente con:
Router:~#echo 1 > /proc/sys/net/ipv4/ip_forward
O mejor aún, como queremos que ocurra la siguiente vez que arranque el equipo, modifica el fichero /etc/sysctl.conf para que quede así:
net.ipv4.ip_forward=1
Activa el NAT
El NAT es una técnica que permite que varios ordenadores puedan acceder a Internet aunque sólo se disponga de una IP pública. El NAT se encarga de "traducir" las direcciones IPs privadas por la única pública al enviar y realiza el proceso inverso al recibir las respuestas. Para activarlo escribe:
Router:~#iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Con esto, los equipos conectados a la interfaz eth1 de Router ya tienen conexión a Intenet, aunque sus IPs habría que configurarlas "a mano" y no son capaces de resolver nombres. Vamos a ver cómo solucionar esas dos cuestiones.
Servidor DHCP y caché DNS
Una vez instalado dnsmasq, haz las siguientes modificaciones en el fichero /etc/dnsmasq.conf:
Este fichero está muy bien documentado con comentarios e incluye ejemplos de todas las posibilidades. Después de realizar las modificaciones reinicia el servicio con:
Router:~#/etc/init.d/dnsmasq restart
Restarting DNS forwarder and DHCP server: dnsmasq.
Simplemente con eso, dnsmasq te da los siguientes servicios:
Si configuras los clientes de tu red local para usar DHCP obtendrán una IP del rango 192.168.0.[2-254]
Se configuran automáticamente para usar tu Router como pasarela y como DNS.
Router cachea todas las peticiones DNS que realicen los clientes y las redirije a los servidores DNS configurados en el /etc/resolv.conf de Router.
Dispone de DNS dinámico local. Si los clientes especifican un nombre al hacer su petición DHCP, el resto de los clientes podrán usar ese nombre para resolver su IP.
Además dnsmasq permite asignar IPs fijas (del rango) y nombres dependiendo de la MAC y otras muchas opciones avanzadas.
Para guardar las reglas activas (las que has ido poniendo hasta ahora) ejecuta:
Router:~#iptables-save > /etc/iptables.up.rules
Y ahora hay que hacer que esa configuración se cargue automáticamente al levantar la interfaz de red principal (la externa). Para ello, edita de nuevo el fichero /etc/network/interfaces para que la entrada de eth0 quede así:
auto eth0
iface eth0 inet dhcp
pre-up iptables-restore < /etc/iptables.up.rules
Esta receta explica cómo instalar y configurar la herramienta NUT para aprovechar al máximo las posibilidades de un SAI en un sistema Debian GNU/Linux. Concretamente, los pasos son para un MGE Pulsar Extreme 1500C
Introducción
Instalar un software de control para un SAI sólo tiene sentido si podemos hablar con él para obtener datos de su estado y funcionamiento. Si el SAI no tiene ningún tipo de conexión de datos (tal como serie o USB) esta receta no te sirve. En cualquier caso, un SAI que no dice nada sobre su estado es de muy poca utilidad. Si estás pensado en comprar un SAI, elige uno con el que puedas hablar. En la página de nut hay una lista de las marcas y modelos compatibles.
Instalación
Si tienes una distro compatible Debian, instalar el paquete nut es así de fácil:
#apt-get install nut
Descripción
Este software tiene una arquitectura cliente/servidor. Esta configuración permite que varios equipos alimentados por un único SAI (y que ejecutan un cliente) puedan hablar, a través de la red, con el equipo que tiene la conexión de datos del SAI (y que ejecuta el servidor). De este modo, ante un corte de corriente, todos los equipos quedan informados y pueden actuar en consecuencia.
Por este motivo, aunque el SAI dé servicio a una sola máquina, será necesario instalar un servidor y un cliente.
Funcionalidad
Lógicamente, la función de un SAI o UPS (mantener la alimentación durante cortes de luz) es insuficiente para un servidor, ya que es muy probable que no haya nadie para apagar el equipo durante el tiempo de duración de las baterías. El software nut ofrece servicios mucho más interesantes:
Fijar un umbral de bateria, por debajo del cual el equipo conectado al SAI se apaga automáticamente.
Desconexión del SAI. De este modo las baterías no se agotan inútilmente, pues ya no hay nada que alimentar.
Fijar umbrales de carga máxima.
Monitorización y configuración remota (por medio de CGI).
Con esa configuración, ante un corte de luz, ocurre lo siguiente:
El SAI pasa a modo batería.
Al bajar el nivel de carga de la batería al umbral fijado, el driver que corre en el servidor lo detecta e informa a todos los clientes.
Los clientes inician el proceso de apagado de cada equipo.
Justo antes de apagarse, el servidor envía al SAI el comando de desconexión.
El SAI recibe el comando, espera un tiempo prefijado y después se apaga.
Al volver la corriente:
El SAI enciende automáticamente.
Cuando la fuente de alimentación del PC detecta voltaje (procedente del SAI) arranca el equipo. Para esto es necesario configurar el BIOS Setup de cada ordenador.
No todos los SAIs pueden hacer todo lo que se índica. Tendrás más o menos posibilidades dependiendo de la gama y precio del SAI.
Configuración
Configuración común
Lo primero, y antes de que se nos olvide, será cambiar los permisos del puerto serie (/dev/ttyS0 o /dev/ttyS1), pues nos debe dejar leer y escribir en él como root. En Debian, los puertos serie suelen pertenecer al grupo dialout, así que la manera más fácil de conseguir permiso es:
#addgrp nut dialout
En /etc/nut/ups.conf habrá que realizar algunos cambios (tanto en cliente como en servidor). Aquí es donde se añade el driver (cada familia de SAIs tiene su propio driver):
[id]
driver = (driver)
port = (port)
(options)
Por ejemplo, para un SAI “MGE Pulsar Extreme” será:
[mge]
driver = mge-utalk
port = /dev/ttyS0
LowBatt = 90
Configuración del servidor
Edita el fichero /etc/default/nut modificando la línea “START_UPSD=no” por “START_UPSD=yes”
En el fichero /etc/nut/upsd.conf tienes que crear la lista de control de acceso (ACL). Para ello incluye (si no existe ya):
ACL all 0.0.0.0/0
ACL localhost 127.0.0.1/32 # host actual
ACL [NombreMáquina] 192.168.0.0/24 # toda la red
ACCESS grant login localhost [password]
ACCESS grant monitor localhost [password]
ACCESS grant login [NombreMaquina] [password]
ACCESS grant monitor [NombreMáquina] [password]
ACCESS deny all all
Por último, edita el fichero /etc/nut/upsd.users para dar acceso a los usuarios. Para ello, añade las líneas:
[monuser]
password = [password]
allowfrom = localhost 192.168.0.0/24 # tu red
Configuración del cliente
Edita el fichero /etc/default/nut modificando la línea “START_UPSMON=no” por “START_UPSMON=yes”
Lo siguiente será /etc/nut/upsmon.conf. Éste es el fichero de configuración del cliente. La línea obligatoria a añadir es la del monitor:
MONITOR [id]@[ip] 1 [password] slave|master
Lo normal para el equipo que tiene la conexión de datos al SAI es que funcione en modo “master”. Eso significa que debe esperar a que los “slaves” apaguen antes de hacerlo él. Así que quedará algo como esto:
MONITOR mge@192.168.0.1 1 [password] master
Ahora debes reniciar el servicio de la forma habitual:
#/etc/init.d/nut restart
Consejos
Lo mejor es que la primera vez se arranque todo a mano, pues el script descrito en la sección anterior redirige todos los errores a /dev/null. Para ello se hará:
#upsdrvctl start
Network UPS Tools - UPS driver controller 1.2.1
Network UPS Tools - MGE UPS SYSTEMS/U-Talk driver 0.51.0 (1.2.1)
##upsd
Network UPS Tools upsd 1.2.1
##upsmon
UPS: mge@192.168.0.1 (slave) (power value 1)
Using power down flag file /etc/killpower
#
Puedes ver que la monitorización funciona adecuadamente con el comando upsc:
Para instalar grub en el arranque del disco debes ejecutar:
#grub-install /dev/hda
siempre que tu disco de arranque sea /dev/hda.
Configuración
Grub puede crear un fichero de configuración por defecto...
#update-grub
Este programa averigua qué kernels tienes instalados y modifica o crea (si no existe) un fichero menu.lst con los datos necesarios. Hazlo también después de instalar un nuevo kernel.
El fichero menu.lst
Su aspecto típico es:
timeout 4
color black/cyan yellow/cyan
default 0
title Debian GNU/Linux [2.4.19-686 precompiled]
root (hd0,4)
kernel /boot/vmlinuz-2.4.19-686 root=/dev/hda5
initrd /boot/initrd.img-2.4.19-686
title Debian single-user (kernel 2.2.18)
root (hd0,4)
kernel /boot/vmlinuz-2.2.18 root=/dev/hda5 ro single
initrd /boot/initrd-2.2.18.gz
title Windows 98
rootnoverify (hd0,0)
makeactive
chainloader +1
Cómo utilizar el gestor de instalación de paquetes GNU stow
Introducción
stow es una pequeña herramienta que sirve para instalar paquetes (normalmente a partir de sus fuentes). Permite que los binarios, ficheros de cabecera y de ayuda del paquete estén accesibles; pero teniendo controlado dónde va a parar cada fichero, de modo que la desistalación elimina TODO lo instalado. En cualquier caso, siempre es preferible utilizar el sistema de paquetes de la distribución (deb, rpm,) pues suele permitir un mejor control del sistema.
Instalación de stow
Suele estar disponible como paquete en las distribuiciones de GNU/Linux más extendidas. En Debian GNU/Linux y distribuciones derivadas (como Ubuntu) es tan fácil como:
#apt-get install stow
Instalación de un paquete usando stow
Supongamos que vas a instalar un paquete a partir de sus fuentes, por ejemplo, gnome-commander-1.1.5.tar.gz. Primero se descomprime:
A continuación "configuramos" el sistema de compilación. Con prefix se indica a configure el directorio en el que se va a instalar el programa. Lo más aconsejable es utilizar un subdirectorio que cuelgue de /usr/local/stow es un buen sitio. Si ese directorio no hay que crearlo. El grupo propietario del directorio stow debería ser staff. Resulte este punto puedes proceder:
Con esto, los binarios quedan instalados en el directorio indicado. Sin embargo, esos directorios no están en el PATH y el programa no se puede invocar a menos que se indique la ruta completa. Aquí es donde entra en juego stow.
Una vez instalado hacemos lo siguiente. Es importante cambiar al directorio /usr/local/stow o de lo contrario habría que indicar las rutas explícitamente.
/usr/local/stow$stow gnome-commander
stow crea enlaces a los ficheros de modo que son accesibles desde /usr/local/bin, /usr/local/lib, etc.
Para poder hacer esto hay que ser root, o mejor, hacer que tu usuario pertenezca al grupo staff (el propietario del directorio).
Des-intalar un paquete gestionado con stow
Si quieres que stow elimine los enlaces que creó para un paquete concreto simplemente ejecuta:
/usr/local/stow$stow -D gnome-commander
Después de esto puedes borrar el directorio /usr/local/stow/gnome-commander sin problema, y todo habrá quedado tan limpito como antes de instalarlo.
Listar los paquetes que contienen cierta cadena en su nombre
$COLUMNS=120 dpkg -l | grep string
Obtener el estado(hold, purge) de un paquete
$dpkg --get-selections nombre_paquete
Eliminar un paquete y sus ficheros de configuración
#dpkg --purge nombre_paquete
Ver las dependencias de un paquete y su descripción
$apt-cache showpkg nombre_paquete
Buscar paquetes relacionados con un término
$apt-cache search string
Posibles problemas
Al instalar un paquete, puede ocurrir que su script de post-instalación falle por alguna razón, lo cual impide que el paquete se instale correctamente. Si eso ocurre puedes editar su script correspondiente en /var/lib/dpkg/info/nombre_paquete.postinst e intentar arreglarlo. Después simplemente ejecuta:
#dpkg --configure-a
Reinstalar todos los paquetes instalados
Útil para limpiar los binarios si el sistema ha sido infectado con un virus o un rootkit. USARCON PRECAUCIÓN.
En determinadas «circunstancias especiales» puede ser necesario que un PC tenga una tarjeta de red con una dirección MAC específica. Esta receta explica cómo conseguirlo con ifconfig, iproute o macchanger
Un minúsculo tutorial para quién necesite o simplemente le apetezca aprender Python.
Introducción
Python es un lenguaje interpretado, interactivo y orientado a objetos. Se le compara con C++. Java o Perl. Tiene variables, clases, objetos, funciones y todo lo que se espera que tenga un lenguaje de programación «convencional». Cualquier programador puede empezar a trabajar con Python con poco esfuerzo. Según muchos estudios, Python es uno de los lenguajes más fáciles de aprender y que permiten al novato ser productivo en tiempo record, lo cual lo hace ideal como primer lenguaje.
Python es perfecto como lenguaje «pegamento» y para prototipado rápido de aplicaciones (aunque finalmente fuera necesario rehacerlas en otros lenguajes), aunque eso no implica que no se puedan ser definitivos. Dispone de librerías para desarrollar aplicaciones multihilo, distribuidas, bases de datos, con interfaz gráfico, juegos, gráficos 3D, cálculo científico, machine learning y una larga lista.
Este pequeño tutorial utiliza la versión actual de Python (3.9) y presupone que el lector tiene nociones básicas de programación con algún lenguaje como C, Java o similar.
Empezamos
Nada como usar algo para aprender a usarlo. El intérprete de Python se puede utilizar como una shell (lo que se llama modo interactivo), algo que viene muy bien para dar nuestros primeros pasos.
$ python3
Python 3.9.1+ (default, Jan 20 2021, 14:49:22)
[GCC 10.2.1 20210110] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Variables y tipos
Las variables no se declaran explícitamente, se pueden usar desde el momento en que se inicializan. Y normalmente no hay que preocuparse por liberar la memoria que ocupan, tiene un «recolector de basura» (como Java).
$ python3
>>> a = "hola"
En el modo interactivo se puede ver el valor de cualquier objeto simplemente escribiendo su nombre:
>>> a
'hola'
Python es un lenguaje de tipado fuerte, pero dinámico. Eso significa que no se puede operar alegremente con tipos diferentes (como se hace en C). Las operaciones están definidas para trabajar con los tipos previstos.
>>> a + 1
Traceback (most recent call last):
File "", line 1, in
TypeError: Can't convert 'int' object to str implicitly
Esa operación ha provocado que se dispare la excepción TypeError. Las excepciones son el mecanismo más común de notificación de errores.
Pero se puede cambiar el tipo de una variable sobre la marcha:
>>> a = 3
En realidad no hemos cambiado el tipo de a, sino que hemos creado una nueva variable que reemplaza la anterior.
Tipos de datos
Valor Nulo
Una variable puede existir sin tener valor ni tipo, para ello se asigna el valor None. Es el valor adecuado cuando se quiere indicar que una variable no se refiere a ningún objeto:
>>> a = None
>>> a
>>>
Booleanos
Lo habitual:
>>> a = True
>>> a
True
>>> not a
False
>>> a and False
False
>>> 3 > 1
True
>>> b = 3 > 1
>>> b
True
Numéricos
Python dispone de tipos enteros de cualquier tamaño que soportan todas las operaciones propias de C, incluidas las de bits. También hay reales como en cualquier otro lenguaje. Ambos tipos se pueden operar entre si sin problema. Incluso tiene soporte para números complejos de forma nativa.
>>> a = 2
>>> b = 3.0
>>> a + b
5.0
>>> b - 4j
(3-4j)
Secuencias
No hay tipo carácter, se utilizan cadenas de tamaño 1. Las cadenas admiten operaciones como la suma y la multiplicación.
El tipo bytes permite manejar secuencias de bytes. Es especialmente útil para serialización de datos. Por ejemplo, podemos convertir una cadena de caracteres UTF-8 a bytes y viceversa:
Las tuplas son una agrupación de valores similar al concepto matemático de tupla. Se pueden empaquetar y desempaquetar varias variables (incluso de tipo diferente).
>>> x = greeting, 'f', 3.0
>>> x
('hola ', 'f', 3.0)
>>> v1, v2, v3 = x
>>> v2
'f'
Las Listas son similares a los vectores o arrays de otros lenguajes, aunque en Python se pueden mezclar tipos.
>>> x = [1, 'f', 3.0]
>>> x[0]
1
Las listas también se pueden sumar y multiplicar:
>>> x = [1, 'f', 3.0]
>>> x + ['adios']
[1, 'f', 3.0, 'adios']
>>> x * 2
[1, 'f', 3.0, 1, 'f', 3.0]
Cualquier secuencia se puede indexar desde el final o mediante «rodajas» (slices):
Python dispone de otros tipos de datos nativos como conjuntos (sets), pilas, colas, listas multidimensionales, etc.
Type checking
Aunque Python es un lenguaje de tipado dinámico, en la versión 3.0 ya se daba la opción de hacer anotaciones sobre las variables y sus tipos, y actualmente (se introdujo con el PEP 484) existe un módulo donde se definen la semántica y convenciones para especificar de forma opcional esas anotaciones o hints.
>>> pi: float = 3.14
Las anotaciones de las variables se almacenan en el atributo __annotations__:
El comportamiento del lenguaje es el mismo, y las variables puede cambiar el tipo de valor que almacenan independientemente de su definición sin producir errores:
>>> pi: float = 3.14
>>> pi = "Tres coma catorce"
Sirve principalmente para facilitar la comprensión del código y poder llevar a cabo comprobaciones de tipos o type checking sobre el código escrito con herramientas como MyPy.
Orientado a objetos
Casi todo en Python está orientado a objetos, incluyendo las variables de tipos básicos, y hasta los literales!
Los módulos son análogos a las 'librerías' o 'paquetes' de otros lenguajes. Para usarlos se utiliza la sentencia import:
>>> import sys
>>> sys.exit(1)
Estructuras de control
Están disponibles las más habituales: for, while, if, if else, break, continue, return, etc. Todas funcionan de la forma habitual excepto for. El for de Python no es un while disfrazado, como ocurre en algunos lenguajes. Este for hace que, en cada iteración, la variable de control tome los valores que contiene una secuencia, es decir, que itere sobre ella. Ejemplo:
>>> for c in "hello":
... print(c)
...
'h'
'e'
'l'
'l'
'o'
Indentación estricta
En muchos lenguajes se aconseja «tabular» de determinada manera para facilitar su lectura. En Python este estilo es obligatorio porque el esquema de indentación define los bloques. Es una importante peculiaridad de este lenguaje. Se aconseja tabulación blanda de 4 espacios. Mira el siguiente fragmento de un programa Python:
El cuerpo del bloque for queda definido por el código que está indentado un nivel debajo de él. Lo mismo ocurre con el if. La sentencia que define el bloque siempre lleva un ':' al final. No se utilizan llaves ni ninguna otra cosa para delimitar los bloques.
Funciones
Nada mejor para explicar su sintaxis que un ejemplo:
deffactorial(n):ifn==0:return1returnn*factorial(n-1)# y su invocación
print(factorial(10))
Python is different
Como cualquier lenguaje, Python tiene sus peculiaridades, y conocerlas puede ayudar a sacarle el máximo potencial. Siempre hay una manera más «pythónica» de hacer las cosas, utilizando por ejemplo las características de programación funcional que incorpora. Como ejemplo, el factorial se puede hacer aún más compacto con algo como:
Lo normal es escribir un programa en un fichero de texto con extensión .py, utilizando algún buen editor (como code). Después ese fichero se puede ejecutar como cualquier otro programa. Para eso, la primera línea del fichero debe tener un «shebang», es decir, algo como:
#!/usr/bin/python3
Y no olvides darle permisos de ejecución al fichero:
Netcat es una de las herramientas más potentes y flexibles que existen en el campo de la programación, depuración, análisis y manipulación de redes y servicios TCP/IP. Es un recurso imprescindible tanto para expertos en seguridad de redes como para hackers. Esta receta incluye varios ejemplos de uso de GNU netcat.
Introducción
Aunque netcat puede hacer muchas cosas, su función principal es muy simple:
Crea un socket con el destino indicado si es cliente, o en el puerto indicado, si es servidor
Una vez conectado, envía por el socket todo lo que llegue en su entrada estándar y envía a su salida estándar todo lo que llegue por el socket
Algo tan simple resulta ser extraordinariamente potente y flexible como vas a ver e continuación. Por simplicidad se utilizan conexiones locales aunque, por supuesto, se pueden utilizar entre máquinas diferentes.
Podemos usar netcat para enviar correo electrónico por medio de un servidor SMTP, utilizando el protocolo directamente:
~$nc mail.servidor.com
220 mail.servidor.com ESMTP Postfix
HELO yo
250 mail.servidor.com
MAIL FROM:guillermito@microchof.com
250 Ok
RCPT TO:manolo@cocaloca.es
250 Ok
DATA
354 End data with <CR><LF>.<CR><LF>
Aviso: su licencia ha caducado. Me deben un pastón.
.
250 Ok: queued as D44314A607
QUIT
221 Bye
HTTP
Es sencillo conseguir un cliente y un servidor HTTP rudimentarios.
Servidor
$nc -l-p http -c"cat index.html"
Al cual podemos conectar con cualquier navegador HTTP, como por ejemplo firefox.
Cliente
$echo"GET /" | nc www.google.com 80 > index.html
Streaming de audio
Un sencillo ejemplo para hacer streaming de un fichero .mp3:
Servidor
$nc -l-p 2000 < fichero.mp3
y para servir todos los .mp3 de un directorio:
$cat*.mp3 | nc -l-p 2000
Cliente
$nc server.example.org 2000 | madplay -
Streaming de video
Servidor
$nc -l-p 2000 < pelicula.avi
Cliente
$nc server.example.org 2000 | mplayer -
Proxy
Sirva para redirigir una conexión a otro puerto u otra máquina:
$nc -l-p 2000 -c"nc example.org 22"
El tráfico recibido en el puerto 2000 de esta máquina se redirige a la máquina example.org:22. Permite incluso que la conexión entrante sea UDP pero la redirección sea TCP o viceversa!
Clonar un disco a través de la red
Esto se debe usar con muchísima precaución. ¡Si no estás 100% seguro, no lo hagas! No digas que no te avisé.
Es este ejemplo voy a copiar un pen drive USB que está conectado al servidor a un fichero en el cliente y después lo voy a montar para acceder al contenido.
Tienes tarifa plana en casa pero tu IP es dinámica. A pesar de eso te gustaría tener un servidor web y tus "cosillas" accesibles desde cualquier sitio. La solución a tus problemas es un servicio de DNS dinámico.
Ingredientes
Una conexión a internet
Debian GNU/Linux o derivados
ddclient
Servidor de DNS dinámico
Lo primero es crearte una cuenta en uno de los muchos sitios que tienen un servicio de DNS dinámico, muchos son gratuitos. Por ejemplo, DynDNS.org.
Hay otros:
Al crear tu cuenta tendrás que indicar cómo se va a llamar tu máquina, por ejemplo, miservidor.dyndns.org.
Instalar ddclient
Simplemente:
#apt-get install ddclient
Configuración
El propio sistema de instalación de paquetes de Debian te preguntará los parámetros de configuración. A continuación se ponen unos valores de ejemplo figurados.
Si metes la pata y te cargas la cuenta de root o simplemente has olvidado la clave, esta receta explica cómo recuperar la cuenta de root sin conocer la clave, siempre que uses GRUB como gestor de arranque.
Cuando aparezca el menu de grub, tras encender la máquina, situate con los cursores en la línea del kernel que quieres usar. Pulsa 'e' para editar la entrada y edita la línea kernel (pulsando 'e' de nuevo). Añade al final de la línea lo siguiente:
init=/bin/bash
Esto hace que el sistema arranque una shell root sin pedir password. Es posible que el teclado esté en inglés y no puedas escribir el '=' y la '/', prueba '¡' y '-'. Pulsa 'b' para comenzar el arranque del kernel.
La partición raíz suele montarse como sólo lectura, asi que si olvidaste la clave de root y quieres cambiarla primero deberás remontarla como lectura/escritura. Para ello:
#mount -o remount,rw /dev/hda3
suponiendo que /dev/hda3 es tu partición raíz. Puedes averiguarlo ejecutando simplemente mount.
Por último, cambia la clave de root ejecutando:
Cómo configurar SSH para poder usar ssh y scp para acceder a otras máquinas autorizadas sin necesidad de indicar la clave de usuario cada vez que se conecta. También muy útil cuando se usan repositorios remotos que se acceden por SSH.
Siempre me ha gustado escribir aplicaciones extensibles, pero picarme todo un sistema de plugins me ha parecido tedioso.
Por eso he intentado buscar librerías que me ayuden a crear plugins, aunque siempre he tenido problemas para la distribución de éstos, como me ha pasado con Yapsy.
La verdad es que me he sentido como un auténtico estúpido al descubrir que Python tiene un sistema para escribir plugins muy sencillo de usar. Vamos a ver cómo.
Puedes encontrar el artículo original en: MagMax Blog.
Atención: Este artículo se ha copiado de la web de MagMax(que es su autor). Es posible que sufra cambios. Podéis encontrar la última versión de este artículo en su ubicación original. Muchas gracias.
Últimamente he estado cotilleando en el mundo ICE con Java, así que aquí os dejo mis conclusiones. Si alguna de ellas es errónea, os agradecería vuestros comentarios.
Por supuesto... Java + IDE (Netbeans o Eclipse)
A menudo he necesitado este script y por fin me he puesto a implementarlo. Consiste en un script-fu que se le puede pasar a gimp para recortar una imagen de forma automática. Contaré los pasos que he seguido y al final hay un resumen para 'ir más rápido'.
Ingredientes
No os lo vais a creer: gimp.
#apt-get install gimp
Seguro que en Mindows es más fácil de instalar.
Mi primer script
Lo primero que necesitado ha sido una manera de ejecutar un script. Para ello, he abierto mi imagencilla con Gimp de la forma habitual:
$gimp tab1.png
Después hay que irse a la ventana principal de Gimp, donde están las herramientas, y acceder a "Exts"->"Script-fu"->"Consola de Script-fu". Se nos abrirá una ventana bastante fea. Antes de avanzar, pulsamos el botón "examinar". Se nos abrirá la ventana de ayuda que podemos tener danzando por ahí mientras nos damos cabezazos contra la pared con nuestro script.
Vamos con mi "hola mundo". En esta ocasión, consistió en seleccionar toda la imagen :-D
(gimp-selection-all 1)
Ahora lo explico: estoy llamando a la función "gimp-selection-all" con el parámetro "1", que es el identificador de la imagen (como la acabamos de abrir, debería ser el 1 :D). Para comprobar el resultado, vamos a la ventana de la imagen y debería estar seleccionado todo.
El Script
Ahora que sabemos usar perfectamente script-fu, vamos con el script que recorta una imagen:
Lo he separado en líneas para que lo veáis bonito :D. La barra invertida: "\" sólo sirve para indicar que va todo en la misma línea.
Ahora explico: "let*" me permite definir variables. Así defino dos: una es "img" y otra "drw". Casi todas las funciones requieren estos parámetros, así que me los guardo "para luego" y así es más fácil todo. Al declarar "img" le asigno el valor devuelto por la función "gimp-file-load", que me ha cargado la imagen, pasándole un "0" ("no interactivo"), la ruta hasta la imagen y "el nombre dado por el usuario", que creo que es el nombre de la imagen sin el path.
Igualmente, a "drw" le asigno el resultado de "gimp-image-get-active-drawable", donde " (car img)" es una llamada a una función que me da el primer elemento del vector "img" (no sé explicarlo mejor. No he conseguido quitarme de encima el "car" ése).
Con eso ya tengo las dos variables locales que, como locales que son, sólo existirán hasta que cierre el "let*" (por eso lo cierro al final).
El primer argumento del resto de funciones siempre es el modo interactivo, el problema es que de homogeneidad nada: unas funciones toman el 0 como "interactivo" y otras como "no-interactivo". En el ejemplo todas están a "no-interactivo".
Por orden, hago: Cargar la imagen (como hemos visto), recortar la imagen, transformar el color blanco a alpha (éste es un bonus track) y guardar la imagen.
No me enrollo más.
Batch mode
Claro, nada de esto tiene gracia si tengo que estar abriendo el gimp para cada una de mis 159 imágenes que quiero procesar... Así que a currarme la línea de órdenes:
A gimp tengo que pasarle la orden "-i" (no interactivo) y "-b" (ejecútame este batch) con la ristra que hemos comentado antes. Tan sólo le he añadido un detallito, que es la orden "gimp-quit" para que no se quede en "modo gimp".
Hay una forma de hacer que me procese todas las imágenes de golpe... Pero eso lo dejaré para otra receta, ya que yo voy a utilizar un precioso Makefile que me va a ir transformando todas las imágenes y me las va a actualizar cuando las modifique (mientras que con gimp tendría que volver a procesar todas), así que lo dejaré en el tintero.
Y fin
No sé si esto resultará útil para alguien, pero puedo asegurar que para mí sí, y como no sabía dónde ponerlo y el script-fu es infernal, lo he plantao aquí, que hacía mucho que no saba señales de vida.
Hasta las narices de que me quieran sajar por un minuto de canción más o menos lo mismo que por una canción completa (con una calidad ridícula), aquí tenéis un manual para reducir el tamaño y la calidad de vuestras canciones favoritas. Eso sí: siempre y cuando tengáis un “título de propiedad” de la canción…
Paso 0: A WAV
Lo primero que hago es obtener el wav. Como lo tengo en CD uso grip (paquetito debian y tal). Si lo tenéis ya en mp3, saltaros este paso.
Paso 1: Recortando
Pues yo uso mhwaveedit. Abre tanto el mp3 como el wav. Recortas, pruebas, recortas, pruebas, pruebas, recortas, pruebas, deshaces, recortas, pruebas… Ale, ya tienes el trocito que te gusta.
Paso 2: Calidad paupérrima
¿Vas a difrutar de la música? La respuesta es: NO. Un montón de investigación para obtener mejor calidad y al final lo que queremos es basura. ¿Qué se le va a hacer? Pero… ¡No hay problema!
$lame -m m -b 56 ficherito.wav ficherito.mp3
Con esto conseguiréis una calidad regulera, pero un tamaño enano. Para un wav de 5Mb he conseguido un mp3 de 200Kb. Podéis jugar con el parámetro de -b hasta encontrar lo que queréis (si ponéis un valor inválido, os avisa de cuáles son los buenos).
Ironic mode: ON
Ale… a difrutar de la música
Ironic mode: OFF
—
20070522 – Añadida opción “-m m” para transformar a Mono. Gracias, Paco; se me había pasado al transcribirlo.
Cualquiera que lea el título puede caer en la desgracia de creérselo. Sin embargo, son afirmaciones que cualquiera que no sepa un poquitín de historia cree. He aquí una pequeña historieta con lo que me ha pasado a mí para descubrir al inventor del ratón.
A menudo, después de liar una buena o bien de instalar sistemas operativos no permisivos y totalitaristas, nos encontraremos que se han cargado GRUB y no podemos volver a iniciar nuestro GNU/*. Siempre olvido alguno de los pasos, así que voy a ponerlos aquí y así a lo mejor le viene bien a alguien.
A menudo necesitamos cambiar de aplicación y lo hacemos rápidamente mediante una combinación de teclas "ALT+TAB". Este cambio, además, muestra una pequeña ventanita que nos indica la aplicación que se va a abrir.
A menudo me ha ocurrido que he tenido que abrir ficheros Makefile. Realmente es un fastidio que tabbar agrupe por extensiones: a mí me gustaría tener disponibles mi Makefile, los .C y los .CPP que utilizo constantemente.
Hoy editaremos a mano, una vez más, nuestro queridísimo .emacs (_emacs para los Windozes). Ahí va un ejemplo de hacer lo que he descrito:
Claro, que suele ser un fastidio tener todas las pestañitas ésas: scratch, Messages, ... Ahí va mi configuración:
(defun tabbar-buffer-groups (buffer)
"Return the list of group names BUFFER belongs to.
Return only one group for each buffer."
(with-current-buffer (get-buffer buffer)
(cond
((member (buffer-name) '("*scratch*")) '("Misc") )
((member (buffer-name) '("*Messages*")) '("Misc") )
((member (buffer-name) '("*Completions*")) '("Misc") )
((member (buffer-name) '("*Ediff Registry*")) '("Misc") )
((eq major-mode 'dired-mode) '("Main") )
((memq major-mode '(c-mode c++-mode makefile-mode)) '("Coding") )
(t '("Main") )
)
)
)
Como podéis ver, tengo 3 grupos principales: Misc, Coding y Main. Por defecto lo mete todo en "Main", salvo los ficheros de c, c++ y Makefiles que son "Coding", y los buffers habituales van a "Misc".
Con esta base y un poco de imaginación, se pueden hacer muchas cosas muy apañadas...
Bueno... Podéis observar que he roto lo habitual de escribir cada semana. A parte de que estoy muy liado, ¡se me están acabando las ideas!.
David ha proporcionado unos cuantos TES y Brue también ha puesto su granito de arena. Si alguien más participa, ¡estupendo! pero, por mi parte, se acaban los TES.
De todas maneras, podéis poner vuestros trucos y marcarlos como "emacs" en la pestaña "Tema". Siempre son bienvenidos ;)
Bogofilter es un filtro antispam que es muy sencillo de combinar con sylpheed y otros clientes de correo. El paquete bogoutils nos permite acceder a las estadísticas y opciones de la base de datos de bogofilter para obtener información adicional. Aquí se muestran algunas de las opciones
Ingredientes
Evidentemente, nos hará falta bogofilter (que ya incluye bogoutil), algún cliente de correo configurado con bogofilter y varias semanas de filtrado de spam.
Notas y cosas
Una nota aclaratoria para todos los ejemplos que se vean en este artículo: He reutilizado la base de datos que tuve hace tiempo, donde no filtré correctamente todos los mailes que me llegaron. Eso ha repercutido en algunas de las estadísticas que mostraré a continuación (como por ejemplo, en la cantidad de mailes que muestran como ham algunas de las palabras, cuando son claramente spam).
Otra cosa: las estadísticas que se muestran aquí sólo son de 3 meses, por lo que no se pueden generalizar (harían falta años para eso).
Ham vs. Spam
Como nota aclaratoria, diré que siempre que me refiera a "Ham" (jamón) me referiré a los mails deseados, mientras que "Spam" (la historia tiene algo que ver con una marca que hacía "Ham" malo) hace referencia a todo mail no deseado.
Cómo funciona
Bogofilter es un filtro bayesiano. Ni idea de qué significa eso, pero por lo que he podido ir observando, utiliza un sistema para puntuar cada palabra, y después calcula algún tipo de media con respecto a las palabras que hay (o algo así). Por ello, cada palabra recibe una puntuación. Este articulillo hará referencia a estas puntuaciones.
Histórico
¿No sentís curiosidad por saber si realmente se puede decidir si un mail es bueno o no por un conjunto de palabras? ¿No encontraremos palabras que son Ham y Spam al mismo tiempo? ¿Será eso lo corriente?
Bueno, pues la manera de saberlo es simple:
Resulta curioso observar que el 61.20% de las palabras que recibo sólo se encuentran en correos Ham, y que el 27.24% sólo están en correos Spam. Así que se puede observar que es cierto que hay palabras que, directamente, deciden cuándo un correo es Spam.
Fijaros que las concentraciones principales están en los extremos y el centro. Es lógico: los conectores (preposiciones, artículos, pronombres, ...) no serán decisorios.
¿Qué probabilidad hay de que "Sexo", "sex", "viagra", "ordenador" estén entre el spam
$bogoutil -p ~/.bogofilter/wordlist.db
spam good Fisher
sexo
sexo 3 3 0.558117
sex
sex 25 0 0.999658
viagra
viagra 2 3 0.457457
ordenador
ordenador 21 48 0.356059
En cuanto introduzcáis la orden arriba citada, el cursor se quedará esperando que tecleéis las palabras a buscar o bien que pulséis CTRL+D para salir.
Observando las estadísticas de arriba se observa que 3 buenos y 3 malos no son un 50%... Bueno, dije que bogofilter hacía "algún tipo de media", no la media aritmética :-D
Despedida
He escrito esto porque me parece curioso, no excesivamente útil. De todas maneras, permite comprobar que nuestro filtro bogofilter está funcionando realmente (y si no lo creéis, probad a mirar las posibilidades de una palabra y después marcad como spam un mail que la contenga).
Espero que a alguien más también le parezca algo en lo que perder un ratejo ;)
A menudo se nos abren muchos Emacs cuando sólo queremos tener uno, y se termina haciendo inusable. Si ya tenemos pestañas con el paquete tabbar, ¿para qué queremos tener varios emacs abiertos?
Ingredientes
Emacs ya trae los ingredientes que nos hacen falta hoy.
Servidor
Vamos a comenzar por la manera fácil: abrimos un Emacs y lanzamos la orden siguiente:
M-x server-start
Ya hemos arrancado un servidor en Emacs. También podemos ponerlo en nuestro .emacs haciendo que se arranque automáticamente mediante:
(server-start)
Cliente
Si tenemos un servidor es porque vamos a tener un cliente, como es lógico. En este caso se llamará emacsclient. En lugar de editar con "emacs", lo haremos con "emacsclient" y arreglado.
Cliente-Servidor todo en uno
Es un rollo eso de tener que decidir si vamos a utilizar emacs o emacsclient... ¡Yo sólo quiero un editor! Además el nombre de "emacsclient" es demasiado largo...
Vamos a probar a hacer lo siguiente: Primero cerramos todos los emacs que tengamos abiertos, y después lanzamos las órdenes siguientes (espero que hayáis puesto el (server-start) en vuestro .emacs):
¡La primera vez se ha abierto un Emacs y la segunda se ha reutilizado! Esto va mejorando, ¿no?
Por cierto.. el -n es equivalente a --no-wait, para que no se quede pillao esperando a que cerréis el buffer y se os devuelva el control.
Más fácil. Más rápido
Ahora nos enfrentamos a una línea de órdenes atroz e insufriblemente larga que no vamos a volver a teclear en la vida. No problem. Siempre podemos hacernos un alias en nuestro .bashrc:
alias emacs=emacsclient -n -a /usr/bin/emacs
Existen otras dos formas que no he probado. La primera es utilizar la variable de entorno ALTERNATE_EDITOR y lanzar emacsclient todas las veces. La segunda está en un fichero que no sé cómo funciona llamado /etc/emacs.bash .
Estaba harto de encontrarme ficheros ~, ## y .semantic por todas partes, y puede llegar a ser muy aburrido borrarlos periódicamente. ¡Tiene que haber alguna manera de optimizar esto! Y, efectivamente...
Ingredientes
Pues el Emacs. No más.
backups
Hoy vamos a tocar a saco el .emacs (recordad que en Windón es _emacs).
Para empezar, veamos los backups, es decir, los ficheros ~. Éstos se crean como medida de recuperación ante fallos. Hay gente a la que le gustaría que no existieran. Hay gente que quiere más backups.
Existe una variable llamada version-control que nos permite crear ficheros loquesea~1~ de tal manera que podamos tener más de 1 backup. Sus valores son t para que se hagan; nil para que no se hagan y t never que es lo mismo pero así, como con más énfasis: ¡que no pongas versiones!. Yo me quedo con una única versión, así que tengo:
(setq version-control t never)
Por si acaso, le digo también que me borre las versiones viejas:
(setq delete-old-versions t)
Situar ficheros
Vale, ahora ya se hacen los backups que yo quiero... Pero sigo teniendo los *~, #*# y *.semantic por todas partes:
La primera instrucción indica dónde quiero que me deje los ~ y la segunda, dónde los .semantic. Es MUY IMPORTANTE que estos directorios existan. Además, hago que comiencen por punto, para que así existan, pero yo no los veo ;)
La segunda de las instrucciones indica dónde debe dejar los .semantic, como es evidente.
Y con esto tengo los directorios limpitos de basura (vamos, con la justa ;D )
A veces es un poco aburrido encontrarse con 20 Emacs diferentes abiertos, sobre todo cuando activamos la opción tabbar. Bien, pues hay una manera de hacer que se reutilice siempre el mismo...
libxml2 es una librería que facilita el manejo de los XMLs. La librería permite el acceso tanto para lectura como para escritura. Si dispones de DTD, también trae funciones para su uso.
A menudo hay cosas que hacen de un editor algo más bonito: iluminar la línea actual, cambiar el color de fondo, algún iconillo... Pues Emacs no iba a ser menos, claro.
Un IDE para unirlos a todos. Muy útil para C, C++, Java, ... Consiste en un conjunto de ventanas que nos permiten acceder directamente a código.
Ingredientes
Emacs, por supuesto, y el paquete ecb.
Activación
Escribiremos una orden Emacs. Para ello podemos pulsar ESC+x o bien M+x (que es, realmente, lo mismo) y después escribir:
M-x ecb-activate
Y veremos las pantallitas nuevas.
Más bonito
Existen distintos tipos de ventanas. Podemos cambiar entre ellos en "Options"->"Customize Emacs"->"Specific Option"->"ecb-layout-name". Si miráis abajo veréis todas las posibilidades. A mí me gusta "top1", aunque podéis ir probando...
Más rápido
A menudo es un rollo tener que estar activándolo y desactivándolo. Por ello me gusta tener accesos de teclado para estos menesteres. Para ello sólo hay que editar nuestro .emacs (al final, por ejemplo):
; Mis atajos de teclado
(global-set-key [f12] 'ecb-toggle-ecb-windows)
(global-set-key [C-f12] 'ecb-activate)
(global-set-key [M-f12] 'ecb-deactivate)
Las teclas que seleccionéis son opcionales. Con éstas podréis:
f12 Me permite mostrar/ocultar las ventanas cuando el modo ecb está activo.
C-f12 Me permite cargar el modo ECB sólo cuando yo quiero (así Emacs es más rápido en general).
M-f12 Sirve para descargar el modo ECB cuando me arrepiento (suelen ser pocas veces).
Con el epígrafe "TES" comenzaré una serie de articulillos sobre emacs. Se corresponden con las siglas "Truco Emacs de la Semana". Procuraré escribirlo todos los lunes, pero no aseguro nada. En esta ocasión, os explicaré cómo activar las pestañas (tabbar).
A menudo es necesario comparar ficheros. Existen numerosos programas; pero me encuentro con que cada uno de ellos tiene un problema que hace que no me solucione la vida en todas las ocasiones. Se me ha ocurrido comentarlo aquí para ver si entre todos podemos aportar ideas.
DIFF
Paquete Debian.
Interfaz: ascii. No es interactivo.
Repositorios: No.
Compara binarios: Sí (-a)
Máximo ficheros: 2
Hexadecimal: No?
Ebcdic: no
Licencia: GPL
Permite edición: No
Automatizable: Sí
Genera patches: Sí
MELD
Paquete Debian.
Interfaz: GTK
Repositorios: CVS/SVN (limitado)
Compara binarios: No
Máximo ficheros: 3
Hexadecimal: no
Ebcdic: no
Licencia: GPL
Permite edición: Sí
Automatizable: No
Genera patches: No?
VBINDIFF
Paquete Debian.
Interfaz: ascii
Repositorios: no.
Compara binarios: Sí
Máximo ficheros: 2
Hexadecimal: Sí
Ebcdic: sí
Licencia:GPL
Permite edición: No
Automatizable: No
Genera patches: No?
Bugs: da problemas con más de 4Gb
Tabla comparativa
.deb
Ifaz
Repos
Bin
Max Fich
Hex
EBCDIC
Licencia
Edit
Auto
Patch
Comentarios
DIFF
sí
ascii
no
sí (-a)
2
no?
no
GPL
no
sí
sí
MELD
sí
GTK
CVS/SVN
no
3
no
no
GPL
sí
no
no
VBINDIFF
sí
ascii
no
si
2
sí
sí
GPL
no
no
no?
Puede dar problemas con más de 4 Gb.
(aquí me falta una leyenda de lo que he puesto en la tablica)
Otras notas
Se agradece vuestra colaboración, aportando nuevos comparadores así como otras características por la que compararlos entre sí (qué paradoja ;)).
Poco a poco los iré añadiendo al artículo. En cuanto pueda haré una tablita comparativa.
Enlace
Hace ya algún tiempo que comencé esta receta... y hoy me encuentro esto en la wikipedia, que no deja de sorprenderme.
Ale, el trabajo ya estaba hecho ;)
¿Se os olvidan los cumpleaños de vuestros amigos? ¿No recordáis cuándo son las fiestas? ¡En 5 minutos podéis solucionarlo!
Material
Necesitaremos instalar el paquete birthday en la máquina que más habitualmente utilicemos:
#apt-get install birthday
Configuración
Editaremos un fichero que no existe aún: ~/.birthdays. Yo recomiendo crear una carpeta (por ejemplo ~/.birthday) donde organizar un poco mejor todos los cumpleaños y eventos. Luego comentaré cómo lo tengo yo configurado.
El formato de este fichero es lo mejor: sencillo. consiste en poner lo que quieras, un igual (=) y la fecha en formato dd/mm, dd/mm/yy o bien dd/mm/yyyy. Ya está. Acordaros de pulsar un intro al final o se os comerá la última de las letras :-D. Ejemplito:
Pepito=15/12/1978
Fulanito=01/09/1977
Cuando hayáis metido 2 ó 3 (que sucendan en las próximas 3 semanas, por favor), probad a ejecutar
$birthday
Os mostrará los eventos de las próximas 3 semanas.
Mi configuración
Dado que el ficherito ~/birthdays te permite incluir ficheros, el mío sólo contiene inclusiones. Las fechas se encuentran en varios ficheros dentro del directorio ~/birthday, donde tengo los ficheros "amigos", "familia" y "fiestas" (éste último os lo podéis bajar más abajo).
¿Y cómo hago para que no sea muy pesado pero me avise antes de que ocurran las cosas? Pues metiéndolo en mi .bashrc. De esa manera, cada vez que abro una consola me aparecen 3 ó 4 líneas con los próximos eventos :-D.
Comentarios
Vaaaale, sí. Ya sé que este truco no os va a salvar la vida y que posiblemente no os importe un carajo, ¿pero cuántos de vosotros conocíais este paquetito?
El caso es que me he picao y ya he comenzado a hacer un programita similar, con idiomas, compatible pero ampliable. En python, por supuesto. Le meteré alguna opción para colorines y esas cosas.
Desde hace algún tiempo (acabo de descubrir que muy posiblemente desde GNOME 2.14), el terminal de GNOME me muestra las tildes, eñes y otros caracteres como caritas. Aunque al principio resulta gracioso, terminas cansándote :-D. Aquí lo arreglaremos de la manera más sencilla.
Arreglarlo
Para arreglarlo basta con editar el fichero ~/.dmrc y añadir al final la línea Language=es_ES.iso88591. Si lo preferís, basta con ejecutar lo siguiente:
$echo"Language=es_ES.iso88591">> .dmrc
¿Qué estaba pasando?
Lo que pasa es que en los GNOMEs anteriores se tomaban las locales del sistema, pero parece que en las últimas no lo hace muy bien. Por ello, al fallar la carga, tomaba las locales por defecto, es decir, ANSI_X3.4-1968 que no tiene tildes y demás.
Yo sabía que se podía cambiar en el menú del gnome-terminal, en "terminal"->"Establecer codificación de caracteres", pero es un rollo tener que hacerlo para cada pestaña del gnome-términal. Así, sólo lo hacía cuando tenía que leer algo un poco grande :-D
Editando el fichero .dmrc le decimos a GDM cuál es el "encoding" que queremos utilizar, puediendo elegir entre los que configuramos con el paquete locales. Para cambiar los "encodings" compilados en "locales", se hace así (los chicos de UBUNTU no sé cómo leches lo hace, pero en Debian se hace así):
#dpkg-reconfigure locales
Y para saber cuáles son los disponibles (qué cadenitas poner en "Language=XXXXXXX"), basta con hacer:
$locale -a
Enlaces
Llevo buscando bastante tiempo, y al final lo encontré en el blog de David Pashley. Este documento es, básicamente, una transcripción de lo que se comenta en el enlace.
Desde hace bastante tiempo estoy tratando de iniciarme en el Proceso de Software Personal. Estuve leyendo un libro bastante pesadete sobre este tema y, aunque me motivó bastante, no conseguí llevarlo a cabo. Parece que he encontrado un nuevo libro que me ha facilitado el paso. Trataré de escribir aquí mis conclusiones y facilidades para seguirlo.
Cuando he abierto mi aptitude en UBUNTU para actualizarme y he visto los paquetes nuevos que han metido en EDGY me he llevado una grata sorpresa al descubrir que el maintainer tenía una dirección @uclm.es.
Tengo un siemens, y me gusta hacer backups periódicos. La perioricidad es variable (cuando me quedo sin memoria para los mensajes), pero me gusta que sea sencillo. Aquí tienes un pequeño script que usa scmxx.
Qué necesitamos
Necesitamos un cable y un móvil soportado por scmxx. También necesitaremos scmxx, por supuesto.
El script
Sin más, ahí va:
#!/bin/bashDIR=`date +"%Y%m%d"`SCMXX_TTY=/dev/ttyUSB0
MEMS="FD SM ON LD MC RC OW SD MS CD BL RD CS VCF"mkdir$DIR
scmxx --get--pbook--sms--slot=all --out=$DIR/sms.p
for i in$MEMS;do
scmxx --get--pbook--mem=$i--out=$DIR/$i.p ;done
Configurar el script
Como podéis ver, el script crea un directorio con la fecha actual, dentro de la que meterá un montón de ficheritos terminados en .p. Éstos tendrán el contenido de cada una de las memorias.
Pero... ¿Cómo sabemos qué memorias debemos consultar? Es fácil: basta con hacer:
$scmxx --info
En caso de que no encuentre nuestro móvil, el problema está en el puerto donde lo conectamos. Por ello, recomiendo que establezcamos la variable de entorno SCMXX_TTY. Como en mi caso está en el USB, el valor de esta variable debe ser /dev/ttyUSB0. Se puede indicar en línea de órdenes, pero me falla bastante.
Poco más que decir. Existe un GUI para scmxx (gscmxx) pero es "más malo" que un dolor de muelas (por el momento).
A menudo nos encontramos con noticias del tipo "hoy se acaba el mundo", debido a diferentes motivos sumamente importantes como que la fecha es el 1999-12-31, un eclipse lunar o a que ayer nos cruzamos con un gato negro. En fin... Que resulta sorprendente que no haya ninguna noticia del fin del mundo para hoy, día 2006-06-06 :-D
Pues eso, chicos, que hoy es día 666.
¡Pasad un buen día!
Recientemente he perdido las fuentes de mi querido Emacs. Estaban ahí, y de repente sólo me aparecían cuadritos de colores (muy monos, eso sí, de colores y todo). Sin embargo, por fin, he encontrado una solución, aunque sea temporal.
Solución provisional
Qué fuentes tienes en el sistema
Lo primero es saber qué fuentes tienes en el sistema. Para ello basta ejecutar:
xlsfonts
Eso sí... preparaos para una salida laaaaarga.
Una fuente para Emacs
Ahora basta con decirle a Emacs la fuente que quieres. A mí me ha gustado una courier (se parecía bastante a la que tenía antes):
Como escribir esa parrafada cada vez es un rollo... pues vamos a hacerle un alias. Para ello editamos el fichero .bashrc y le añadimos la línea siguiente:
alias emacs="emacs -font -adobe-courier-medium-r-normal--14-140-75-75-m-90-iso10646-1"
Y conseguimos que Emacs se abra con esa fuente. No es lo mejor, pero funciona.
Ciertas tareas dependen del tiempo para funcionar (por ejemplo, el salvapantallas, make, cron, …). Es interesante no tener que preocuparse de la hora del sistema, así como que la hora no cambie bruscamente. ¡Y es muy fácil!
Paquetes necesarios
Sólo necesitaremos un paquete: ntpdate. En nuestro sistema basado en Debian es tan sumamente complicado como de costumbre:
#apt-get install ntpdate
Explicación
En el mundo hay una serie de relojes de alta precisión (relojes atómicos) que son los que de verdad llevan la hora del mundo (¿u os pensábais que lo hacía el reloj de la Puerta del Sol? :P). Mediante fibra óptica, están conectados una serie de servidores de acceso restringido. A éstos, se les conectan una serie de servidores de acceso restringido… y así un par de niveles más, hasta que llegan los servidores públicos. Así hay muchos y no los sobrecargamos.
Cada vez que un host intenta sincronizarse lo que se hace es lanzar varias peticiones, calcular el tiempo de retardo existente debido a la red, tomar en cuenta varios factores y estimar la hora real. El error es mínimo (salvo algunas veces que casca todo el sistema y te pone la hora del día anterior, como me ha pasado hace un rato).
Así, groso modo -como mandan las recetas- es como funciona.
Tiempo lineal
Algunos programas pueden tener problemas con los saltos de tiempo misteriosos. Este es el caso del salvapantallas, por ejemplo: si lo tenemos puesto cada 10 minutos y adelantamos el reloj 1 hora, salta. Cron también puede tener problemas: si en nuestro PC de casa tenemos la tarea “salvar_el_mundo” programada para las 13:45 y a las 13:30 cambiamos la hora a las 14:30, la tarea no se ejecutará, con resultados desastrosos.
Por ello conviene que nuestro PC no se salte ni un minuto, ¿no creéis?
Pues hacerlo es tan sencillo como cambiar la configuración de ntpdate, que se encuentra en el fichero /etc/default/ntpdate, y añadirle a la línea “NTPOPTIONS” la opción “-B”. A mí me quedaría así:
# servers to check. (Separate multiple servers with spaces.)
NTPSERVERS="pool.ntp.org"
#
# additional options for ntpdate
#NTPOPTIONS="-v"
NTPOPTIONS="-u -B"
Y, ahora, el mundo está a salvo (aunque en algunos casos nuestro PC puede tardar horas semanas en sincronizarse…) ;D
Lo que ocurre ahora es que los minutos de nuestro PC son más lentos/rápidos que los habituales, pero eso no significa que nos saltemos ni un segundo ;)
¿Usas Evolution y aún tienes Spam? ¿Quieres eliminarlo de una vez por todas? Bien... La verdad es que aún no lo he conseguido, pero estoy tras la pista. A ver si entre todos conseguimos quitarnos de enmedio el molesto spam.
Ante las preguntas realizadas por Oscar sobre el uso de GDB y problemas con el famoso "segmentation fault", me he decidido a hacer un pequeño manual de GDB y otras herramientas útiles para el depurado. Seguramente se me queden muchas cosas en el tintero, pero todos sabemos que las recetas no están cerradas cuando se publican. Se agradecerán todos los comentarios.
gdb
GDB o el GNU DeBugger, es el programa usado para depurar los programas en GNU/Linux. No es el único, pero sí uno de los más potentes, sobre todo para programas escritos en C y C++.
Para poder utilizar todas sus características, será necesario que, durante la compilación, dejemos información de depurado en el ejecutable. Si estamos utilizando gcc o cc, esto se hace mediante la opción -ggdb.
¡Ya tenemos nuestro fichero preparado para ser depurado! Ahora basta utilizar la orden:
$gdb ejecutable
y se nos abrirá la línea de órdenes de gdb (todo en modo texto, claro).
Hay que tener en cuenta una cosa: cuando un programa falla, puede deberse a un error o bien a los efectos colaterales de un error. Me explico con un ejemplo: si tenemos un puntero no inicializado y le asignamos un valor, puede que dé error o puede que no (depende de dónde esté apuntando); por ello puede dar el problema más adelante (esto se conoce como el "Síndrome del puntero loco" entre los coleguitas :-D).
Por ello, es interesante no pensar que gdb te dice "aquí está el problema", sino "el problema está por aquí", que es muy diferente.
Uso de GDB
gdb es bastante complejo, y sólo detallaré aquí los pasos iniciales para debugar el típico "hola mundo".
Primero, cargaremos el ejecutable compilado con las opciones de debug "-ggdb":
gdb ejecutable
Se nos inicia la línea de órdenes gdb. Lo primero, será poner un punto de ruptura ("Breakpoint"). Se puede poner en una línea determinada o bien en una función. Dado que nuestro programa "hola mundo" es pequeñín y no sabemos dónde pusimos el main, plantamos la ruptura en el propio main:
gdb>br main
Y lo siguiente es ejecutar el programa:
gdb>r
Así que se parará en la primera instrucción del main. Ahora podemos utilizar una serie de argumentos que explicaré brevemente:
p "print" imprime el valor de una variable.
d "display" igual que print, pero se muestran cada vez que pulsemos "s" o "n".
n "next" Continúa con la siguiente instrucción de la función actual
s "step" Continúa con la siguiente instrucción de la que se tiene información de depurado (si hay una llamada a función, entrará dentro).
c "continue" continúa la ejecución del programa.
h "help" muestra la ayuda
GNU/Emacs
GDB sólo es muy poco amigable, así que yo prefiero utilizarlo junto con GNU/Emacs. Gano dos cosas, principalmente: ver el código y coloreado del mismo.
Para ello, basta con pulsa ESC+x (o M+x) y escribir la orden "gdb". Emacs nos pedirá el resto de la línea de órdenes, donde pondremos el nombre del ejecutable y del core (si es que existe). Cuando lo tengamos, nos aparecerá una pantalla tipo terminal igual que si hubiéramos iniciado gdb en una consola, pero cuando comencemos a trazar el código se nos dividirá la pantalla en dos, mostrando en el otro lado el código (con una flechita muy molona que nos cuenta por dónde vamos).
ddd
Aunque muchas veces uso Emacs con gdb, debo admitir que mi favorito es ddd. Su instalación es realmente compleja:
#apt-get install ddd
Seguro que los de Windows lo tienen más fácil. Bien. El caso es que la pantalla se divide en tres partes (si no es así mira las opciones del menú "View") en las que tenemos, de arriba abajo: datos, código y terminal gdb. Precioso. Si cargamos un programa con opciones de debug ("-ggdb") podremos ver cómo se mueven los punteritos, cómo cambian las direcciones a las que apuntan, cómo se construyen las estructuras, ... Vamos, muchas cosas que nos cuentan pero no se ven ;)
Y, a parte de los menús TK pseudo-molones, siempre tenemos la parte de abajo con un gdm normal.
NOTA He observado un comportamiento extraño al pulsar con el ratón en la zona de datos o en la de GDB, ya que toma las teclas que pulses como entradas de la pantalla GDB, pero no funcionará el intro. Sin embargo, si pulsas directamente sobre la ventana de código, te funciona todo igual y el intro sí va. No me preguntéis porqué es así, pero ocurre. Seguramente esto sea así porque lo tenéis configurado de esta manera. Para solucionarlo, tenéis que ir a "Edit"->"Preferences", y en la pestaña "Startup" veréis que pone "Keyboard focus a)Point to Type b) Click to Type". Os podéis imaginar: seleccionáis si queréis que el foco se obtenga cuando el puntero del ratón está justo encima (bastante molesto) o os hace falta hacer click para dar el foco (molesto, pero no tanto).
COREs
Una gran ayuda frente a los "segmentation faults" son los archivos COREs. Te preguntarás dónde andan, claro :-D pues no andan por ningún sitio porque los tienes desactivados. Para activarlos, sólo tienes que hacer:
$ulimit-c unlimited
Cuando vuelvas a ejecutar el programa te pondrá "segmentation fault (core dumped)". Genial. Ahora ejecuta gdb de la siguiente manera:
$gdb ejecutable core
y puedes ver dónde cascó exactamente con la orden de gdb "whereis", que te mostrará la pila. Acuérdate de volver a quitar el límite de los cores o te ocuparán espacio en el disco duro (y no poco):
A ver... que estamos muy paradetes...
El problema consiste en hacer un programa C que permita conocer el endian de la máquina en que se ejecuta.
Fácil, fácil, ¿eh?
¿Sabríais hacerlo en otros lenguajes (Java, por ejemplo)?
A menudo se piensa que una aplicación estaría mucho mejor si se encontrara en varios idiomas. Podemos pensar en distintas formas de soportar esto, pero otros ya lo han pensado por nosotros y han creado las fabulosas herramientas gettext. Este documento pretende ser una guía para el uso rápido (rápido de verdad) de estas herramientas.
Ingredientes
gettext
Modificaciones en el código
Lo primero es acordarse de evitar cadenas sin más (al menos las que se muestran) en nuestro código. Ahora importaremos la librería gettext y utilizaremos la función gettext. Se encuentra disponible para numerosos lenguajes, aunque aquí se explicará con ejemplos en python (las diferencias serán mínimas en el resto de lenguajes).
No os asustéis: Las funciones “textdomain” y “bindtextdomain” sirven para decirle a gettext dónde se encuentran las traducciones. Aquí se está poniendo un ejemplo, así que sustituid “programita” por el nombre de vuestro programa, y “./mo” por el directorio donde vamos a meter las traducciones.
A menudo, además, se suele importar la función gettext cambiándole el nombre a algo más sencillo como la barra baja. De esta manera, nos evitamos tener que escribir “gettext.gettext” cada vez. Para hacer esto hay distintas maneras, una de ellas es durante la importación:
fromgettextimportgettextas_
Generación de la plantilla de traducción (.pot)
Podemos obtener la plantilla del código en casi cualquier lenguaje: C, C++, Python, Perl, Glade, Java, … Y se hace así:
$xgettext --language=Python -j programita.py
Las opciones son: —language indicando el lenguaje del código, y -j que indica que, si hay ya un .pot existente, se deben mezclar los mensajes.
Si hemos usado algún cambio y no aparece la función como “gettext”, será necesario usar también la opción —keyword. Por ejemplo:
$xgettext --language=Python -j-k _ programita.py
Ale, ya tenemos el messages.pot.
Generar el fichero de traducciones (*.po)
Ahora se utiliza el messages.pot para generar cada plantilla. Nosotros queremos la traducción al castellano, así que será es.po:
$msginit -i messages.pot -o es.po
Ahora viene la parte en la que editamos el fichero es.po (yo suelo usar gtranslator o kbabel) y demás.
Mezclar el fichero de traducciones (.po) con una nueva plantilla (.pot)
Este sistema sería poco eficiente si tuviéramos que traducirlo todo de nuevo cada vez que se cambie el fuente. Por ello, hay un sistema por el que se mezcla el fichero ya traducido con la plantilla nueva (es decir: volvemos al paso de creación de plantilla y después ejecutamos esto):
$msgmerge -U es.po messages.pot
Y, nuevamente, volvemos a traducir :-D
Creación del fichero de equivalencias (.mo)
Realmente, el ficherito .po no se utiliza en el ejecutable. Es necesario utilizar un ficherito .mo. Aquí crearemos nuestro es.mo, como es lógico:
$msgfmt es.po mo/es/LC_MESSAGES/programita.mo
Como podéis observar, el resultado lo dejamos en mo/es/LC_MESSAGES/. Eso lo hacemos así porque en el código fuente dijimos que las traducciones colgarían del directorio mo, el idioma es Español (las locales son “es”), y porque todos los .mo deben colgar de un directorio LC_MESSAGES dentro de las locales para que sea encontrado correctamente.
Utilización
Ya está. No hay nada más que contar. Si las locales son “es”, escribirá nuestra traducción, y si son “en”, lo escribirá en inglés. Eso es todo.
Ejemplo
Veamos un ejemplo, sugerencia hecha por david.villa:
Editamos el archivo es.po que se nos habrá creado, traduciendo la única cadena. Mi archivo pinta así:
# Spanish translations for PACKAGE package.
# Copyright (C) 2010 THE PACKAGE'S COPYRIGHT HOLDER
# This file is distributed under the same license as the PACKAGE package.
# miguel <miguelangel.garcia@gmail.com>, 2010.
#
msgid""msgstr"""Project-Id-Version:PACKAGEVERSION\n""Report-Msgid-Bugs-To:\n""POT-Creation-Date:2010-05-2507:31+0200\n""PO-Revision-Date:2010-05-2507:32+0200\n""Last-Translator:miguel<miguelangel.garcia@gmail.com>\n""Language-Team:Spanish<>\n""MIME-Version:1.0\n""Content-Type:text/plain; charset=ASCII\n"
"Content-Transfer-Encoding:8bit\n""Plural-Forms:nplurals=2; plural=(n != 1);\n"
#: hello.py:12
msgid "hello, world!"msgstr"hola,mundo!"
Por ahora no nos fijaremos mucho en las cosa que deberíamos cambiar, como el PACKAGE y demás. Sólo nos queda compilar:
A menudo resulta interesante crear un paquete debian de un programa, para su sencilla instalación/desinstalación. Esta receta, inicialmente escrita por Fernando Rincón, explica cómo hacer lo básico en pocos pasos.
Generación de la estructura de directorios
En primer lugar debe crearse un directorio de trabajo (debian), a partir del cual se generará la estructura de directorios del paquete, considerando que el directorio de trabajo es el directorio raíz. A continuación se distribuirán los archivos que forman parte del paquete en los subdirectorios correspondientes.
Si se desea instalar el fichero mi_ejecutable en la ubicación /usr/bin/mi_ejecutable, la estructura del directorio de trabajo debería ser la siguiente:
./debian/usr/bin/mi_ejecutable
Generación de los ficheros de control
Hay varios tipos de ficheros de control. El fichero control propiamente dicho indica las características y dependencias del paquete. Los ficheros preinst, postinst, prerm y postrm son los scripts que se ejecutan durante la instalación, la actualización y el borrado de un paquete, para la configuración/desconfiguración de los programas incluidos en el paquete (Ver sección 6 de [3]).
Los ficheros de control deben almacenarse en la siguiente ubicación:
debian/DEBIAN
El fichero Control
Para la generación del paquete es imprescindible la creación de un fichero de control (también llamado control), en el que se indicará el nombre del paquete, la versión, la sección a la que pertenece, la prioridad de instalación, etc ... La descripción exacta del contenido de cada campo puede encontrarse en la sección 3 de [3].
Por ejemplo:
Package: linuxstatus
Version: 1.1-1
Section: base
Priority: optional
Architecture: all
Depends: bash (>= 2.05a-11), textutils (>= 2.0-12), awk, procps (>= \
1:2.0.7-8), sed (>= 3.02-8), grep (>= 2.4.2-3), coreutils (>= 5.0-5)
Maintainer: Chr. Clemens Lee
Description: Linux system information
This script provides a broad overview of different
system aspects.
Configuración mediante debconf
Debconf proporciona una base de datos con un frontend que facilita el proceso de configuración de un paquete recién instalado o actualizado. Se basa en el uso de una serie de reglas que definen las preguntas a realizar al usuario, y el tipo de valores que
Construcción del paquete
Desde el directorio inmediatamente superior al directorio de trabajo debian debe ejecutarse:
Mirando en la biblioteca de mi padre me he llevado una sorpresa mayúscula al encontrarme un libro sobre las leyes de Murphy. En el prefacio, te explica que han hecho recopilación de todas las que han encontrado (y se ve claramente que han buscado en google). El libro consiste en una lista interminable de frases relacionadas con la ley de Murphy, pero, en la primera página pone eso de "El contenido de este libro no podrá ser reproducido, ni total ni parcialmente, sin el previo permiso del editor". ¿Significa ésto que no puedo utilizar las frases que vienen dentro, aunque éstas no sean del autor del libro?
¿Nunca habéis deseado probar un programa de una distribución más inestable sabiendo que podéis volver atrás? ¿Nunca habéis tenido que recurrir a una versión anterior de ningún paquete? Pues existía una manera más fácil, y aquí os explico cómo.
Asunciones
Asumiremos que tenemos instalada una "unstable", pero queremos tener acceso a algunos paquetes de "experimental" y... bueno, ya que nos ponemos, también de "stable" y "testing", pero con menor prioridad.
Configurar la "release" por defecto
Editáis el fichero (si no existe lo creáis) /etc/apt/apt.conf y añadís la línea:
APT::Default-Release "unstable";
Configurar las otras distros
APT ya sabe cuál es la distro que queremos tener instalada, pero hay que decirle que existe más mundo. Para ello se utiliza el fichero /etc/apt/preferences:
NOTA: No, aún no lo he probado.
Debo advertir que las prioridades son bastante curiosas y hay que tener cuidadín:
< 0: La versión no se instalará jamás.
0 - 100: El paquete no se reemplazará por una versión superior. Los paquetes instalados tienen prioridad 100.
101-500: La versión se instala si es más moderna que la existente y no existe ningún ejemplar en la versión objetivo.
501-1000: La versión se instala aunque no esté en la distro por defecto.
1000: La versión se instalará a toda costa, incluso si es inferior a la actual.
Típicamente se utilizan los valores -1, 100, 500, 900 y 1001.
Lo de bloquear Ubuntu no es por mala leche: a menudo suele dar problemas mezclar paquetes. Cada uno que haga lo que quiera.
Editar sources.list
Claro, nos falta editar el sources.list y añadir todos los repositorios que nos dé la gana. Ya sabemos que no se va a instalar nada "extraño" (siempre que no metáis repositorios "extraños").
Cómo usarlo
Muy fácil: Para los paquetes de la distribución por defecto, como siempre:
apt-get install lo-que-sea
Para el resto, también fácil (donde pongo "experimental" poner el nombre de la distro):
apt-get install -t experimental lo-que-sea
Todos ellos se "updatean" a la vez por el método habitual.
Otras referencias
Me disponía a escribir esta receta basándome en un ejemplo que tenía por algún lado. No he encontrado el ejemplo, pero sí un documento titulado Jugando con APT, que explica cómo hacer lo mismo para Ubuntu.
También están interesantes el Manual de APT y un documentillo que he encontrado titulado Using APT with more than 2 sources, este último en inglés, claro.
Llevo utilizando ordenadores casi toda mi vida, y a veces me parece increíble que aún se sigan cometiendo fallos de usabilidad tan simples. Se me ha ocurrido que puede ser buena idea exponerlos aquí. Por ello, he creado una lista con los primeros que se me han ocurrido; la intención es hacer crecer esta lista con aquéllos que pongáis en los comentarios y con los nuevos que me vaya encontrando.
Las X-Windows de los sistemas Unix tienen una arquitectura cliente-servidor. Aunque lo habitual es que los programas que vemos se ejecuten en nuestra máquina, es perfectamente posible abrir una sesión X en una máquina distinta mediante XDMCP
Configuración
Edita el fichero /etc/gdm/gdm_conf de la máquina que ejecuta el servidor X.
Busca la sección [xdmcp], y activa la opción enable=true.
Es muy recomendable dejar la opción: AllowRemoteRoot=false para evitar problemas de seguridad.
Esto es válido si se usa gdm como gestor de conexión. Si usas kdm o xdm la configuración puede variar.
Ahora busca la sección [server-Standard] y edita la opción command para que NO incluya el argumento -nolisten tcp. Quedará algo como:
command=/usr/X11R6/bin/X -deferglyphs 16 -audit 0
Conexión
Para conectar, bastará con escribir en la consola:
El 0.1 indica el display y el screen. Normalmente variará entre 0.0, 1.0, 2.0 y 3.0, y se podrá acceder, respectivamente, con F7, F8, F9 y F10.
Varias sesiones X en la misma máquina
Puede ser interesante tener una o varias sesiones X adicionales en la máquina local. Por ejemplo, con:
$xinit -- :1
se abre un segundo cliente X (en F8) que ejecuta únicamente un x-terminal, pero sin gestor de ventanas ni de escritorio.
Sesión X anidada
Si en lugar de utilizar el comando X usa Xnest consigue el mismo efecto que en los ejemplos anteriores, pero en lugar de tener un terminal gráfico a pantalla completa obtiene una ventana del tamaño adecuado.
El documento pretende ser un manual "paso a paso" que permita configurar un proyecto Java con Eclipse. Se utilizará Eclipse 3.1 y el proyecto creado será un "tomcat project".
¿Tanto cuesta buscar un portátil?
Pues sí. Sobre todo si lo que buscas es tan específico como lo que busco yo.
¿Qué le pedirías a un portátil? Bien... Pues aquí os dejo lo que YO le pido a un portátil:
Peso. Para mí lo más importante es el peso. No quiero un portátil que pese 3 Kg.
Batería. Esto no consigo verlo en ninguna oferta: ¿Cuál es su tamaño? ¿Y su peso? ¿De qué me sirve un portátil de 1,1 Kg si su batería va a pesar otro 1.1 Kg, o bien es más grande que el propio portátil? También es importante la duración: ¿4 horas? ¿Más?
RAM. Ya que me pongo... 1Gb.
Disco duro. Con 60Gb me conformo.
Precio. En principio, debería ser lo más importante, pero como no hay manera de encontrar todo lo anterior, he decidido bajarlo en el "ranking".
Grabadora de DVD. Hay que amortizar el cánon.
Pantalla. Luego dirán que el tamaño no importa...
Microprocesador. Sí, bueno... Habrá que mirarlo. Sobre todo por la tecnología: los céleron ni en pintura. La velocidad te puede dar una idea del tiempo que llevan en el mercado, pero no creo que sea algo determinante: cualquier portátil hoy día te da potencia de sobra (A no ser que quieras jugar al Doom 3, claro).
Puertos y otras tonterías. Total, hoy en día todos los portátiles te traen 20.000 puertos, wifi, módem, cafetera, altavoces, microondas, refrigerador, ...
¿Se me olvida algo? Supongo que cada uno tiene sus preferencias. Las mías son muy claras: quiero un portátil portable, no un portátil de sobremesa. Quiero algo que pueda mover sin necesitar una carretilla o un coche.
Aun así, ¿Cambiaríais algo?
--
Amortiza el cánon siendo legal: copia música y películas.
Soy el primero que debería aprender lo que voy a poner en este blog. Es importante aprender a escribir correctamente en la web, y donde digo web, quiero decir foros, blogs, mail, ... . No vale todo, como solemos pensar. ¡Intentémoslo!
Porque también hay amantes del software libre a los que les gusta comer bien, igual que puedes escribir recetas informáticas, puedes escribir recetas de cocina (¿o era al revés?). Este documento trata de establecer unas pautas que permitan dos cosas: que no se nos olvide poner nada y que todos tengan un estilo similar.
Apartados
El título va fuera del área de texto. Debe ser claro y conciso: "Macarrones boloñesa de Luis"
Los apartados que debe tener son los siguientes:
Ficha
Tiempo requerido: Aproximado, claro. "45 minutos".
Dificultad: Novato, Experto, etc
Coste: La pela es la pela. Aproximado. "Unos 5 euros".
Comensales: Para cuántas personas está pensada la receta.
Ingredientes: Lista con los ingredientes necesarios.
Preparación: Pasos a realizar indicando tiempos de cocción y cosas por el estilo. Cuanto más precisa mejor. Evitar las generalidades como "un poco", "una pizca". Se trata de hacer recetas para los que no tenemos ni idea. Ejemplo: "un poco de sal, pégale un pellizco al salero y lo que se te quede entre los dedos".
Comentarios: Aquí podéis contar lo que queráis: "con esta receta ligué con mi novia", "ideal para cuando llegas de resaca", "muy útil para quedar bien". También se admiten anécdotas.
Estilo
Como se trata de que sea todo muy sencillito, símplemente poned los apartados como títulos ("h1"), los ingredientes como una lista no ordenada("ul") y los puntos de la preparación como párrafos. Los comentarios quedan completamente a vuestra disposición.
Con esto ya deberías tener funcionando la ATI con un solo monitor. Para comprobar si el 3d te rula, ya sabes:
#glxinfo | grep direct
direct rendering: Yes
Antes de hacer esto, he probado con el instalador de la ATI (bajandolo de su página web) y no rula.
Doble monitor
Para el doble monitor:
#aticonfig --initial=dual-head
Con el xorg.conf que te genera, tienes dos escritorios distintos en cada monitor, puedes cambiar iconos de uno a otro pero no cambiar aplicaciones entre ellos. Si quieres verlo todo como un único monitor debes habilitar la opción Xinerama dentro del ServerLayout del xorg.conf:
Esta receta es una introducción al uso de los programas libres dynamips y dynagen que nos permiten emular Cisco IOS. Las posibilidades son infinitas, aqui damos los pasos para poder empezar a trabajar de una forma básica.
Si alguna vez has querido aprender a configurar redes seguramente te has encontrado con un problema para encontrar entornos reales que te permitan aprender los comandos y configuraciones que se necesitan para echar a andar una red real.
Entre los equipos de mayor calidad nos podemos encontrar la gama de routers Cisco. Tener acceso a routers cisco para prácticar es díficil y caro. Afortunadamente existen dos programas que nos pueden simplificar la vida extraordinariamente. Dynamips y Dynagen son dos programas que te permiten configurar una red medianamente compleja y configurar cada uno de los routers presentes en dicha red mediante un emulador que carga una imagen real del sistema operativo de Cisco IOS, es decir, exactamente el mismo sistema operativo que se ejecuta en los equipos reales.
Las ventajas se ven de forma clara, la imagen que carga el dynamips es exactamente la misma que se ejecuta en un router real por lo que el realismo va mucho mas allá del que puedes conseguir con programas como el PacketTracer. PacketTracer es un programa (la licencia no es libre) que te permite modelar redes y configurarlas.
Instalación
Bueno, al tema, los programas dynamips y dynagen son paquetitos debian, asi que, simplemente, apt-get install dynamips y apt-get install dynagen.
En realidad el programa de emulación es dynamips que puede emular los modelos de routers 7200/3600/3725/3745/2600/1700 mientras que dynagen es un front-end basado en texto que te permite crear redes virtuales y trabajar con ellas.
Estos programas han sido creados para prácticar con la configuración de los routers pensando en las certificaciones CCNA/CCNP/CCIE.
Emulando redes virtuales
Una vez instalados, empezar a trabajar con ellos es sumamente sencillo, arrancas dynamips con las opciones que necesites, por ejemplo, en nuestro caso le indicamos que el puerto va a ser el 7200 :
#dynamips -H 7200
Cisco Router Simulation Platform (version 0.2.8-RC2-x86)
Copyright (c) 2005-2007 Christophe Fillot.
Build date: Oct 17 2007 06:50:15
ILT: loaded table "mips64j" from cache.
ILT: loaded table "mips64e" from cache.
ILT: loaded table "ppc32j" from cache.
ILT: loaded table "ppc32e" from cache.
Hypervisor TCP control server started (port 7200).
A ese puerto se conectará dynagen para pasarle los parámetros de configuración de la simulación.
A continuación arrancamos dynagen indicandole el escenario que queremos crear. El paquete debian tiene unos cuantos ejemplos, veamos uno sencillito creado por nosotros:
La primera sección [ [ 7200 ] ] nos indica la configuración general de los routers, hay muchos parámetros pero el mas importante y que no puede faltar es la imagen, este parámetro determina la imagen del sistema operativo IOS que debe cargar. Aqui hay un problema, el sistema operativo Cisco IOS es privativo por lo que debemos obtener una imagen de algún sitio autorizado. Y aviso a navegantes YO NO PUEDODISTRIBUIRCISCOIOS por lo que tendrás que conseguirla por tus propios medios. (ACTUALIZACIÓN: Parece que hay gente que puede distribuirlas, mira al final de esta receta).
A continuación se definen dos routers [[ROUTER R1]] y [[ROUTER R2]] ambos con
el modelo 7200 (que debe coincidir con la imagen de sistema operativo que cargamos), el atributo model proporciona el modelo de router (7200 en nuestro caso) mientras que tambien debemos especificar las conexiones:
s1/0 = R2 S1/0
Esta sentencia nos indica que la linea serial del router R1 la conectamos a la linea serial S1/0 del router R2.
Si arrancamos el dynagen pasándole como argumento este archivo, que llamaremos simple.net, obtenemos una consola de texto:
La cantidad de opciones y configuraciones posibles son infinitas, lo mas básico para empezar a trabajar es observar los dispositivos que existen en la red con el comando list:
=>list
Name Type State Server Console
R1 7200 stopped localhost:7200 2000
R2 7200 stopped localhost:7200 2001
=>
Arrancar los routers:
=>start /all
Warining: Starting R1 with no idle-pc value
100-VM 'R1' started
Warining: Starting R2 with no idle-pc value
100-VM 'R2' started
y obtener una consola para trabajar con los distintos routers:
=>console /all
=>
Al ejecutar este comando deben aparecer dos consolas, cada una de ellas representa un router y puedes ver como carga la imagen del sistema operativo y podremos empezar a trabajar con comandos reales.
Para terminar varios consejos, dynamips y dynagen consumen muchos recursos, si quieres optimizar y que no consuma tanto mira la opción idle-pc.
Entre las características de dynagen te permite capturar paquetes en distintas interfaces de tu red virtual en el formato .cap que con posterioridad puedes visualizar con programas como wireshark.
Si quieres echarle un vistazo a las posibilidades de estos programas:
Siguiendo el hilo de la receta anterior, vamos a ver cómo podemos clasificar el tráfico que generamos para meterlos en las colas que vamos a crear y así clasificar el tráfico. Para ello, aunque existen multitud de formas de clasificar el tráfico vamos a utilizar el campo TOS (type of service) del protocolo IP.
Clasificando paquetes
Bueno, esta claro que si queremos establecer clases de tráfico podemos hacer dos cosas, una marcar el tráfico de paquetes en el origen y sólo clasificar en el nodo que hace de enlace con, por ejemplo, Internet y otra, no marcar en el origen y filtrarlo (ademas de clasificar) todo en el nodo que hace de enlace.
Si nos imaginamos un nodo con dos interfaces, una conectada a Internet y otra a una red ethernet través de la cual se conectan otros nodos podemos establecer reglas de marcado en esos nodos mientras que en el enlace simplemente clasificamos el tráfico que le llega en el sistema de colas.
El problema de tener que marcar en el origen, es que pueden existir nodos que no marcan sus paquetes o que los marcan mal para obtener el ancho de banda asociado a un tráfico de prioridad mas alta. Vamos a considerar que todos los nodos son buenos y marcan sus paquetes.
Para marcar un paquete debemos usar iptables. Si observamos una regla de iptables para marcar paquetes:
Vemos que lo primero que nos encontramos es el "-t mangle" , que le indica la tabla dónde vamos a operar, por la tabla mangle pasan todos los paquetes por lo que no se nos escapa ninguno, si quieres ver una descripción de las tablas, y su uso mira aquí.
Lo siguiente que viene es "-I POSTROUTING" que nos indica dónde vamos a aplicar la clasificación, como hemos dicho antes, estamos marcando el tráfico que el nodo genera por lo que lo marcamos despues del enrutado de los paquetes. En este punto hay que hacer una pequeña parada, el sitio ideal para marcar el paquete que ha sido originado en un sistema es en OUTPUT, ya que por ahí pasa todo el tráfico generado en un nodo, no obstante a mi me interesa hacerlo en POSTROUTING por que me interesa marcar tráfico que pasa por mi sistema y que no esta marcado (cosas del curro:-)).
El 1 que viene a continuación es el número de la regla que vas a crear, acuerdate de esto si quieres borrarla luego.
A continación vienen las reglas que debe cumplir el paquete para marcarlo, en nuestro caso buscamos todo el tráfico tcp que viene de la dirección 111.11.11.105, "-p tcp -s 111.11.11.105". Y por último especificamos qué queremos hacer con esos paquetes, en nuestro caso vamos a poner el valor 16 en el campo TOS.
Si queremos ver como queda la regla despues de que la ejecutemos en nuestro sistema:
Para borrar todas las reglas de marcado, en el caso de la tabla mangle:
#iptables -F-t mangle
Obviamente podemos especificar el marcado de los paquetes como queramos y atendiendo a multitud de parámetros. Veamos algunos ejemplos:
Especificar que todo el tráfico de salida de un host que sale del puerto 12345 se marque con el valor 4 en el campo TOS:
En general, despues de la opción -p puedes poner cualquier tipo de protocolo (si esta incluido en /etc/protocols), tambien existe la posibilidad de marcar los paquetes que van a un destino específico (con -d), que entraron por un interfaz específico o van a salir etc. existen módulos asociados a protocolos que enriquecen las posibilidades, pero vamos estudiando un poco seguro que puedes marcar y filtrar lo que quieras.
Por ejemplo un paquete muy majo es este que te permite filtrar de forma cómoda por protocolos de la capa de aplicación y habilitar reglas como esta:
Como vimos en la receta anterior, para crear colas, usamos la herramienta tc.
Por ejemplo si queremos establecer cuatro colas, cada una para un tipo de tráfico distinto, y que tengan el mismo ancho de banda, una estructura como esta sería apropiada:
#tc qdisc add dev eth0 root handle 1: htb default 1
#tc class add dev eth0 parent 1: classid 1:1 htb rate 3125kbps
#tc class add dev eth0 parent 1: classid 1:2 htb rate 3125kbps
#tc class add dev eth0 parent 1: classid 1:3 htb rate 3125kbps
#tc class add dev eth0 parent 1: classid 1:4 htb rate 3125kbps
Tal y como hemos creado las estructuras, el ancho de banda es dividido, es necesario resaltar que para que compartieran el ancho de banda deberíamos crear una cola hija de root de la cual "colgar" la clasificación. De esta forma si una clase de tráfico no ocupa su ancho de banda, el que sobra, es repartido en las otras clases de tráfico.
Nuestras colas, quedan, por lo tanto:
Una vez que tenemos el tráfico marcado y las clases de tráfico creado, debemos establecer las reglas para encolar el tráfico en su clase correspondiente, dentro de la clasificación de colas preestablecida.
Para ello, de nuevo utilizamos la herramienta tc:
#tc filter add dev eth0 parent 1:0 protocol ip prio 10 u32 match ip tos 0x10 0xff flowid 1:4
#tc filter add dev eth0 parent 1:0 protocol ip prio 9 u32 match ip tos 0x08 0xff flowid 1:3
#tc filter add dev eth0 parent 1:0 protocol ip prio 8 u32 match ip tos 0x04 0xff flowid 1:2
#tc filter add dev eth0 parent 1:0 protocol ip prio 7 u32 match ip tos 0x02 0xff flowid 1:1
Con estas instruciones le indicamos que vamos a crear un filtro "tc filter" y asociarlo a la interfaz eth0 "add dev eth0" y a la clase root "parent 1:0" (la qdisc que hemos creado antes). Este filtro es sobre el protocolo ip "protocol ip" y le fijamos una prioridad para indicar en que orden se aplican los filtros "prio 10" (mayor número, mayor prioridad). A continuación viene qué condiciones debe cumplir nuestro paquete (con el filtro u32), en nuestro caso, como hemos utilizado el campo TOS, lo especificamos con "match ip tos 0x10 0xff" y por último el flujo al que pertenece si cumple los criterios "flowid 1:4".
Si queremos ver que todo se ha configurado bien:
#tc filter show dev eth0
filter parent 1: protocol ip pref 7 u32
filter parent 1: protocol ip pref 7 u32 fh 803: ht divisor 1
filter parent 1: protocol ip pref 7 u32 fh 803::800 order 2048 key ht 803 bkt 0 flowid 1:1
match 00020000/00ff0000 at 0
filter parent 1: protocol ip pref 8 u32
filter parent 1: protocol ip pref 8 u32 fh 802: ht divisor 1
filter parent 1: protocol ip pref 8 u32 fh 802::800 order 2048 key ht 802 bkt 0 flowid 1:2
match 00040000/00ff0000 at 0
filter parent 1: protocol ip pref 9 u32
filter parent 1: protocol ip pref 9 u32 fh 801: ht divisor 1
filter parent 1: protocol ip pref 9 u32 fh 801::800 order 2048 key ht 801 bkt 0 flowid 1:3
match 00080000/00ff0000 at 0
filter parent 1: protocol ip pref 10 u32
filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1
filter parent 1: protocol ip pref 10 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:4
match 00100000/00ff0000 at 0
#
Comprobando que todo funciona
Vale, y todo esto, ¿cómo comprobamos que funciona?, bueno, hay un script en perl que te permite visualizar las clases de tráfico que hay en tu sistema, el dispositvo y el tráfico que entra por cada clase en tiempo real:
Puedes bajártelo de aquí. El script no está mantenido pero de momento funciona bastante bien. Si observais, en la ejecución del comando sólo va tráfico a la clase 1 que es por defecto, se pueden generar tráfico con una herramienta (tipo scapy) para comprobar qué tráfico va a cada una de las colas.
Vamos a describir en esta receta algunos de los comandos útiles para lo que se ha venido a denominar traffic shaping, en cristiano, control de nuestro ancho de banda. Aviso a navegantes, este tema es un poco lioso y yo no soy ni mucho menos un experto por lo que, primero, espero comentarios, correcciones, mejoras, etc. y segundo, ojo con lo que haces!!
Enviando paquetes a la red
Bueno vamos con algunos comandos y de paso vamos introduciendo algunos conceptos:
# ip link show
1: lo: <LOOPBACK,UP,10000> mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,10000> mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:e0:4c:00:84:bb brd ff:ff:ff:ff:ff:ff
Este comando muestra los “enlaces” presentes en un computador, en esta información va incluida alguna información muy útil, dejando aparte la interfaz loopback, nos centramos en el enlace número dos, es decir la eth0 que es una interfaz ethernet. Despues de la información relativa a la mtu (Maximum transmission unit) que en una ethernet es 1500 tenemos la disciplina de colas (qdisc). Para que nos entendamos, todos los paquetes que se envían son almacenados en un sistema de colas hasta la entrega a la red.
Ahora bien, cómo se gestionan las colas y qué algoritmo se utiliza para decidir qué paquete desencolamos es un mundo un poco complejo que trataremos de introducir en esta receta.
Antes de continuar hay que indicar que, aparte de las colas, están las clases de tráfico y los filtros. Generalmente (esto depende mucho del tipo de colas que estamos usando) se definen clases de tráfico y los filtros clasifican el tráfico en esas clases atendiendo al protocolo, ip, etc..
Tipos de Colas
El algoritmo por defecto es “pfifo_fast”, que es el más sencillo, el primer paquete que llega es el primero que sale y lo más rápido posible, esto no tiene ningún misterio. Con esta política todo el mundo es feliz y todos los paquetes son tratados exactamente igual buscando las máximas prestaciones. No obstante estaremos de acuerdo en que no todas las aplicaciones y ordenadores son de igual importancia por lo que asignar un recurso tan escaso como el ancho de banda, puede ser una buena idea y muy útil.
Hay mas disciplinas de colas, entre las cuales podemos enumerar:
FIFO – simple FIFO (packet (p-FIFO) or byte (b-FIFO) ): la que hemos visto, tambien hay ha nivel de byte.
PRIO – n-band strict priority scheduler: En esta disciplina tenemos un sistemas de encolado basado en clases de tráfico a las cuales se les asigna una prioridad, Las clases de tráfico son desencoladas en funcíon de la prioridad (el 0 es la mayor prioridad y cuanto mayor es el número menor prioridad).
TBF – token bucket filter: Esta es una disciplina para establecer límites en el ratio de entrega de paquetes para las distintas colas. Si quieres limitar el ancho de banda de una interfaz, esto es lo que necesitas.
CBQ – class based queue: Otro sistema basado en colas un poco mas complejo que el PRIO, aquí puedes establecer jerarquías de clases y prioridades. Hay que resaltar que dentro de cada una de las clases hay una qdisc que, por defecto es una pfifo pero que puede ser configurada por lo que la cantidad de combinaciones es enorme.
CSZ – Clark-Scott-Zhang: Para que nos entendamos garantiza el ancho de banda de los servicios garantizados y el resto lo deja para los paquetes que no se clasifican (best-effort traffic), la teoría de esto es compleja.
SFQ – stochastic fair queue: Tienes diferentes colas asociadas a flujos y vas sacando de cada cola un paquete a la vez (round robin) para que todas los flujos tengan el mismo ancho de banda, el tema es que si una aplicación establece muchos flujos obtiene mas ancho de banda.
RED – random early detection: Esto esta diseñado para backbones, el tema es que trata de aprovechar las características de control de flujo del protocolo TCP para ajustar los parámetros de entrega de los paquetes y evitar la congestión antes de que se produzca. Lo que hace es eliminar aleatoriamente paquetes cuando las colas empiezan a llenarse, cuanto mas llena esta la cola, va aumentando la probabilidad de eliminar un paquete de forma aleatoria. TCP cuando pierde paquetes reduce su tasa de envío por lo que reduce la posibilidad de congestiones, hay que ajustar muy bien los valores para que no perdamos mas paquetes de los que perderíamos en congestión (vamos eliminando paquetes por que la red no da mas de si). Esto plantea un problema ya que UDP no implementa un mecanismo similar con lo que los flujos UDP no se ajustan.
GRED – generalized random early detection: El tema es que RED descarta aleatoriamente paquetes cuando hay una posible congestión y de forma aleatoria tratando todos los flujos igual, como en el campo del señor no todos somos iguales, GRED crea una serie de colas virtuales y establece políticas RED distintas (como por ejemplo la probabilidad de eliminar un paquete cuando se empieza a llenar la cola) a cada una de ellas.
ATM – asynchronous transfer mode: Esto es para que emules el comportamiento de una red ATM transmitiendo unidades de información en celdas.
DSMARK – DSCP (Diff-Serv Code Point)marker/remarker: Esto mas que una disciplina es una política de marcado de paquetes en función de reglas específicas.
Hierarchical Token Bucket (HTB): Podemos dividir el ancho de banda especificando el mínimo y el máximo, si alguien no esta usando su ancho de banda, se asigna al resto de clases. Este se considera mas sencillo que el CBQ y bastante flexible por lo que lo usaremos para los ejemplitos.
La herramienta tc: comándos básicos
Vamos con algunos comandos, de aqui en adelante si queremos ver como van nuestras colas:
Este primer comando define una cola que se añade a la raiz (root) con un manejador handle 1: y que
por defecto manda el tráfico a la clase de tráfico 1.
Ahora creamos la clase de tráfico:
$tc class add dev eth0 parent 1: classid 1:1 htb rate 1kbps ceil 5kbps
Para esta clase de tráfico, el padre es la qdisc que acabamos de crear (parent 1:) y cuyo identificador es 1 (classid 1:1). Por último, la parte de comando que delimita el ancho de banda que pueden consumir viene determinado por la parte del comando “rate 1kbps ceil 5 kbps” que le dice al kernel, que, asegure una tasa de 1kbps en caso de congestión y que como mucho esa clase puede llegar a 5 kbps. Si no ponemos la parte ceil, la clase consumirá todo el ancho de banda sobrante que quede (esto es así por que estamos usando HTB).
En teoría ya esta todo, al indicarle al crear la cola que la clase por defecto es la 1, todo el tráfico es dirigido a esa clase que ya esta limitada. Ahora bien, si queremos indicarle explícitamente que mande todo el tráfico ip a esa clase debemos crear un filtro:
$tc filter add dev eth0 protocol ip parent 1: handle 1 fw classid 1:1
De nuevo le indicamos que el parent es la qdisc htb root (parent 1:), el manejador de este filtro es el 1 y la acción es forwardear todo el protocolo ip (protocol ip) a la clase 1:1 (fw classid 1:1).
Varios temas, primero sólo podemos controlar el tráfico que sale por eth0, para controlar el tráfico de entrada hay que trabajar con la cola de entrada (ingress). A menos que estes probando cosas, es recomendable meter tu configuración (lista de comandos) en un script ya que es frecuente cometer errores, y aunque se pueden cambiar las especificaciones, muchas veces puede ser lioso.
Viendo como va nuestra configuración
Si queremos ver como va nuestra configuración de filtros:
#tc filter show dev eth0
filter parent 1: protocol ip pref 49152 fw
filter parent 1: protocol ip pref 49152 fw handle 0x1 classid 1:1
Nuestras clases:
#tc class show dev eth0
class htb 1:1 root prio 0 rate 8000bit ceil 40000bit burst 1603b cburst 1619b
El rate es en bit, le pusimos 1kb es decir 1000*8 bits (lo coge en bytes).
Y las colas:
#tc qdisc show dev eth0
qdisc htb 1: r2q 10 default 1 direct_packets_stat 294
Cada sistema de colas diferentes tiene comandos y parámetros específicos , en algunos casos puedes añadirle a las clases de tráfico qdisc propias que tienen nuevas clases (en forma de árbol) por lo que las combinaciones son múltiples.
Vamos a tratar de describir el proceso de programación de un nodo Mica2 con un ejemplo mínimo. Para ello vamos a usar el equivalente para sistemas empotrados del hola mundo que es la aplicación Blink para el tinyOS. Adicionalmente iremos ampliando este tema con las herramientas que nos proporciona la toolchain.
Hardware
Los equipos adquiridos en el grupo Arco son las micas2 uno de los equipos mas ampliamente usados en Wireless Sensor Networks junto con el tinyOS.
Hay dos tipos de dispositivos, las micas2 (4 nodos) y las micas2dot (4 nodos) ademas de un programador MIB510.
Las micas2 cuentan con un puerto de extensión dónde se le pueden conectar plaquitas con sensores, nuestras micas2 tienen las placas MTS310CA que cuentan con sensor de luz, temperatura, micrófono y un pequeño altavoz ademas
de un acelerómetro y un sensor magnético.
El procesador y la radio de las micas2 cuenta con un MPR400CB que esta basado en el procesador Atmel ATmega128L, para mas datos mirar el datasheet
Las micas2dot son algo mas limitadas como podemos ver en su página web
Programando la Mica2
La instalación del tinyOS y del toolchain ya lo vimos en la receta anterior
Esta aplicación basicamente lo que hace es encender y apagar el led rojo de la mota a una frecuencia de 1Hz. La aplicación se encuentra en el directorio:
/opt/tinyos-1.x/apps/Blink
El compilador que vamos a usar es el de NesC que es el ncc:
ncc --help
Usage: avr-gcc [options] file...
Options:
-pass-exit-codes Exit with highest error code from a phase
--help Display this information
--target-help Display target specific command line options
(Use '-v --help' to display command line options of sub-processes)
-dumpspecs Display all of the built in spec strings
-dumpversion Display the version of the compiler
-dumpmachine Display the compiler's target processor
-print-search-dirs Display the directories in the compiler's search path
-print-libgcc-file-name Display the name of the compiler's companion library
-print-file-name=<lib> Display the full path to library <lib>
-print-prog-name=<prog> Display the full path to compiler component <prog>
-print-multi-directory Display the root directory for versions of libgcc
-print-multi-lib Display the mapping between command line options and
multiple library search directories
-print-multi-os-directory Display the relative path to OS libraries
-Wa,<options> Pass comma-separated <options> on to the assembler
-Wp,<options> Pass comma-separated <options> on to the preprocessor
-Wl,<options> Pass comma-separated <options> on to the linker
-Xlinker <arg> Pass <arg> on to the linker
-save-temps Do not delete intermediate files
-pipe Use pipes rather than intermediate files
-time Time the execution of each subprocess
-specs=<file> Override built-in specs with the contents of <file>
-std=<standard> Assume that the input sources are for <standard>
-B <directory> Add <directory> to the compiler's search paths
-b <machine> Run gcc for target <machine>, if installed
-V <version> Run gcc version number <version>, if installed
-v Display the programs invoked by the compiler
-### Like -v but options quoted and commands not executed
-E Preprocess only; do not compile, assemble or link
-S Compile only; do not assemble or link
-c Compile and assemble, but do not link
-o <file> Place the output into <file>
-x <language> Specify the language of the following input files
Permissible languages include: c c++ assembler none
'none' means revert to the default behavior of
guessing the language based on the file's extension
Options starting with -g, -f, -m, -O, -W, or --param are automatically
passed on to the various sub-processes invoked by avr-gcc. In order to pass
other options on to these processes the -W<letter> options must be used.
For bug reporting instructions, please see:
<URL:http://gcc.gnu.org/bugs.html>.
Si analizamos el proceso de compilación que ya usamos para comprobar que la toolchain estaba correctamente instalada:
$make mica2
mkdir -p build/mica2
compiling Blink to a mica2 binary
ncc -o build/mica2/main.exe -Os -finline-limit=100000 -Wall -Wshadow -DDEF_TOS_AM_GROUP=0x7d -Wnesc-all -target=mica2 -fnesc-cfile=build/mica2/app.c -board=micasb -I%T/lib/Deluge -DIDENT_PROGRAM_NAME=\"Blink\" -DIDENT_USER_ID=\"root\" -DIDENT_HOSTNAME=\"homer\" -DIDENT_USER_HASH=0xbc4a9a92L -DIDENT_UNIX_TIME=0x45b09151L -DIDENT_UID_HASH=0x04c03c51L Blink.nc -lm
compiled Blink to build/mica2/main.exe
1632 bytes in ROM
49 bytes in RAM
avr-objcopy --output-target=srec build/mica2/main.exe build/mica2/main.srec
avr-objcopy --output-target=ihex build/mica2/main.exe build/mica2/main.ihex
writing TOS image
Vemos que lo primero crea un directorio para meter los binarios y que todo lo va a meter en main.exe, las opciones le indican diversos parámetros para la generación del código entre los cuales podemos ver el target, en nuestro caso la mica2, el usuario y el host, y al final nos aparece los bytes generados para la RAM y para la ROM.
Si echamos un vistazo al directorio build/mica2 vemos los siguientes archivos:
donde aparecen diversos archivos como las imágenes generadas por avr-objcopy como són el formato de intel (.ihex) y el de motorola (.srec)
Para instalarlo concectar físicamente el nodo a la interfaz de programación (la placa mib510) y esta al puerto serie mediante un cable RS232, por último ejecutar el siguiente comando:
# make mica2 reinstall mib510,/dev/ttyS0
cp build/mica2/main.srec build/mica2/main.srec.out
installing mica2 binary using mib510
uisp -dprog=mib510 -dserial=/dev/ttyS0 --wr_fuse_h=0xd8 -dpart=ATmega128 --wr_fuse_e=ff --erase --upload if=build/mica2/main.srec.out
Firmware Version: 2.1
Atmel AVR ATmega128 is found.
Uploading: flash
Fuse High Byte set to 0xd8
Fuse Extended Byte set to 0xff
rm -f build/mica2/main.exe.out build/mica2/main.srec.out
installing mica2 bootloader using mib510
uisp -dprog=mib510 -dserial=/dev/ttyS0 --wr_fuse_h=0xd8 -dpart=ATmega128 --wr_fuse_e=ff --upload if=/opt/tinyos-1.x/tos/lib/Deluge/TOSBoot/build/mica2/main.ihex
Firmware Version: 2.1
Atmel AVR ATmega128 is found.
Uploading: flash
Fuse High Byte set to 0xd8
Fuse Extended Byte set to 0xff
Y ya esta, tanto el led rojo de la placa de programación (la MIB510) como el de la mota parpadean a una frecuencia de 1 Hz, a continuación puedes desconectar la mica de la placa de programación y el led continua parpadeando.
No es mucho, pero como ya comentamos es el hello world de las micas y la prueba definitiva de que todo el toolchain funciona correctamente.
Existen dentro del directorio apps bastantes ejemplos que podeis probar y sobre todo, podeis mirar como ejemplos de programación:
Lo siguiente es echarle un vistazo a NesC y ver como desarrollar nuestros propios programas, tambien veremos como usar las herramientas de depuración y el simulador TOSSIM, pero eso para las siguientes entregas.
Enlaces
Los enlaces básicos son los de la receta anterior:
Por que no sólo de GNU/Linux vive el hombre, vamos a describir brevemente la instalación y el uso de un sistema operativo libre denominado TinyOS. Este sistema operativo esta destinado a redes inalámbricas de sensores por lo que necesitaremos para probarlo alguna de las plataformas soportadas por el sistema operativo o el simulador TOSSIM.
Instalación TinyOS 2.0
Vamos a aprender su instalación y dejaremos para más adelante la construcción de un pequeño hello world o incluso la instalación del propio simulador.
Se va a instalar todo en una debian con kernel 2.6.15.7
Instala Java 1.5 JDK. Se necesita para comunicarse con el nodo desde el PC.
Compilador cruzado
Esto va a depender del dispositivo para el cual quieras desarrollar una aplicación y concretamente del procesador con el que estén desarrollados. Por ejemplo, para la familia de las MICAs (dispositivos para redes de sensores) se necesita la toolchain AVR, ya que llevan unos procesadores ATMEL. En la receta supondremos que vamos a trabajar con estas motas, por lo que instalamos todo lo relativo a la citada toolchain. En debian esto implica, instalar los siguientes paquetes:
gcc-avr, el gcc para los atmel
gdb-avr, el gdb para los atmel
binutils-avr, utilidades binarias.
avr-libc, la librería estándar de C
avarice, para utilizar el gdb con JTAG (sistema para depuración típico de sistemas empotrados)
Si peiensas utilizar el apt-get para instalar todo eso será mejor que eches un vistazo a esta página de tinyOS. En resumen dice que no es buena idea, ya que necesitamos versiones muy concretas. Lo mejor es bajarse los rpm y pasar los paquetes a .deb con alien, para luego instalarlos. Un tema importante, primero desinstala todo lo que tengas de avr y no te olvides de bloquear todos los paquetes para que no se actulicen cuando hagas un “upgrade”.
Una vez que tengas los compiladores cruzados (necesarios para compilar el sistema operativo TinyOS) necesitas el compilador de nesC. nesC es el lenguaje en el que está escrito tiniyOS y que se usa también para escribir las aplicaciones. En la página web tienes paquetes rpm para el nesC (que usará los compiladores y para la toolchain de tinyOS por lo que, como esto en una debian tienes que tirar de alien para convertir los paquetes.
#alien tinyos-tools-1.2.2-1.i386.rpm
Warning: Skipping conversion of scripts in package tinyos-tools: postinst prerm
Warning: Use the --scripts parameter to include the scripts.
tinyos-tools_1.2.2-2_i386.deb generated
#dpkg --force-overwrite-i tinyos-tools_1.2.2-2_i386.deb
(Leyendo la base de datos ...
161803 ficheros y directorios instalados actualmente.)
Desempaquetando tinyos-tools (de tinyos-tools_1.2.2-2_i386.deb) ...
dpkg - aviso, no se tendrá en cuenta el problema por estar activa
una opción --force:
intentando sobreescribir `/usr/share/man/man1/uisp.1.gz', que está también en el paquete uisp
dpkg - aviso, no se tendrá en cuenta el problema por estar activa
una opción --force:
intentando sobreescribir `/usr/bin/uisp', que está también en el paquete uisp
Configurando tinyos-tools (1.2.2-2) ...
El sistema operativo
Un paso similar se realiza para instalar el sistema operativo propiamente dicho, es decir el tinyOS. Se coge el paquete .rpm se pasa a .deb con alien y se instala con el dpkg.
Configuración del entorno
Configurar las variables de entorno (mételo en un script para configurarlo de forma automática), por ejemplo en ~/bin/tinyos-setup.sh:
Y ejecuta lo siguiente cuando vayas a compilar para TinyOS:
$. ~/bin/tinyOS.sh
Cambia el propietario del directorio donde esta el tinyOS:
$chown-R felix /opt/tinyos-2.x
y no olvides cambiar los permisos del dispositivo (puerto serie, paralelo, USB) que uses para comunicarte con las motas.
chmod 666 /dev/<devicename>
graphviz
Instalar Graphviz desde su paquete debian correspondiente con
#apt-get install graphviz
Probando
Bueno, enhorabuena, si has hecho todos estos pasos, ya tienes el tinyOS instalado en tu ordenador, ahora necesitas probar todo esto que hemos hecho. No está de más echarle un vistazo a la estructura general del SO para entender como está estructurado y sus posibilidades.
La mejor forma de ver si todo esta correctamente instalado es tratar de compilar y probar algunas de las aplicaciones de ejemplo que vienen con el propio sistema operativo. Como ya habrás notado el sistema operativo se ha instalado por defecto en el directorio /opt/tinyos-2.x
Dentro de este directorio a su vez puedes encontrar los siguientes directorios:
apps: Aplicaciones de ejemplo del tinyOS
support: código fuente del toolchain
tos: el sistema operativo propiamente dicho.
Puedes probar que todo está correcto compilado una aplicación de prueba que viene con el sistema. Copia el directorio apps/Null a algún sitio de tu home. Este directorio es un esqueleto de aplicación para tinyOS, que si bien no hace nada útil, te permite comprobar que has realizado correctamente todos los pasos anteriores.
Dentro de ese directorio, ejecuta el siguiente comando:
$make <plataforma_destino>
donde plataforma_destino puede ser uno de los siguientes:
Vamos a describir una serie de comandos básicos para el uso de gnuplot. Un programa para generar gráficas 2D y 3D a partir de datos "crudos" y funciones matemáticas.
Los usos y aplicaciones de esta herramienta son infinitas y lo más interesante, bastante simple de usar mediante comandos.
Instalación
La instalación no tiene ningún misterio y creo que está empaquetado para todas las distribuciones que generalmente usamos.
No obstante en su página web se encuentra toda la información necesaria para la instalación y algunas gráficas de muestra de lo que se puede realizar con este sistema.
Gráficas a partir de datos
Creo que lo mejor es echarle un vistazo a un ejemplo e ir comentando los detalles. En el siguiente ejemplo sacamos una gráfica con el consumo de energía medio de un nodo a partir de una simulación del ns2.
set terminal postscript eps color
set grid
set xlabel "Node ID"
set xrange [0:50.0]
set ylabel "Energy(Joules)"
set yrange [0:20.0]
set title "Average energy consumed by Node"
plot "average-consume-bynode.data" with boxes
Todos los comandos tienen opciones varias para variar la presentación, tipo de gráfica, límites de la gráfica, etc. Sería imposible verlas todas por lo que os remito al manual :-).
Volvamos con el ejemplo, la primera línea indica cómo queremos que nos saque la gráfica, le decimos que la saque por terminal, en postcript, eps y a todo color.
Con "set grid" le indicamos que nos muestre la regilla en la gráfica.
A continuación vamos con el eje de las X (es una gráfica 2D), primero indicamos con xlabel, la etiqueta que le queremos poner, y a continuación el rango. finalmente establecemos lo mismo con el eje de las Y.
Para terminar de modelar nuestra gráfica le ponemos el titulo con "set title".
Vale, lo último es indicarle dónde estan los datos a representar y cómo queremos que nos lo pinte, en este caso le decimos (última linea del ejemplo) que nos pinte los datos en average-consume-bynode.data con cajas (boxes).
El archivo de los datos tiene esta pinta:
La primera columna son las X y la segunda las Y.
Bueno, pues vamos a pintar, podemos teclear los comandos anteriores aunque os recomiendo que los metais en un archivo (en nuestro caso en el archivo average-consume-bynode.dem), con lo cual si ejecutamos:
$gnuplot average-consume-bynode.dem > grafica.ps
En gráfica.ps tendremos nuestra gráfica:
$gv grafica.ps
con solo cambiar el estilo (palabra a la derecha del with en la última linea) podeis tener diferentes tipos de gráficas para adaptarla a aquellas que mejor representen vuestros datos.
Concretamente se pueden usar:
Otra posible aplicación es obtener datos de funciones matemáticas. Vamos a ver un ejemplo extraido de la demo gallery, dónde hay un montón de ejemplos que os pueden servir como referencia de lo que se puede hacer.
Ahora lo vamos ha realizar desde la línea de comandos ejecutando gnuplot estableciendo la rejilla y utilizando la función splot (usada para funciones 3D y superficies). Esta genera una gráfica con las funciones que le especifiques. Si quieres representar mas de una función no te olvides de separarlas por comas.
Aqui esta el ejemplo tal y como se ejecuta:
felix$gnuplot
G N U P L O T
Version 4.0 patchlevel 0
last modified Thu Apr 15 14:44:22 CEST 2004
System: Linux 2.6.14-2-386
Copyright (C) 1986 - 1993, 1998, 2004
Thomas Williams, Colin Kelley and many others
This is gnuplot version 4.0. Please refer to the documentation
for command syntax changes. The old syntax will be accepted
throughout the 4.0 series, but all save files use the new syntax.
Type `help` to access the on-line reference manual.
The gnuplot FAQ is available from
http://www.gnuplot.info/faq/
Send comments and requests for help to
<gnuplot-info@lists.sourceforge.net> Send bugs, suggestions and mods to
<gnuplot-bugs@lists.sourceforge.net>
Terminal type set to 'x11'
gnuplot>set grid
gnuplot>splot x**2+y**2, x**2-y**2
gnuplot>
Y ya tienes tu primera gráfica en 3D.
La ayuda
Las combinaciones son infinitas para lo cual gnuplot nos da una ayuda por comandos bastante extensa.
generalmente con un help te muestra una ayuda en secciones para que veas las distintas posibilidades.
Como ya he dicho arriba, en mi opinión la mejor fuente de ayuda son los ejemplos, simplemente busca el tipo de gráfico que quieres y fijate en como lo han diseñado.
Una de las aplicaciones más útiles a realizar con los móviles Bluetooth es poder atender una llamada mediante el micrófono y los altavoces del PC o portátil. Lo que vulgarmente se denomina un "manos libres". En esta receta vamos a configurar nuestro GNU/Linux para poder ser utilizado de esta forma.
Compilando el servicio
Lo primero que hay que reconocer es que el servicio está un poco verde y no va a sonar todo lo bien que esperais, con paciencia y buceando en el código supongo que se puede ajustar, pero eso, simplemente supongo..
Bueno, lo primero que hay que hacer es bajarse el servicio handsfree de su página web.
Básicamente hay que seguir las instrucciones de la página web para compilar el servicio y como pre-requisitos :
Tener instalada la pila bluez y las herramientas asociadas. En la anterior receta ya se daban unas nociones básicas de cómo usar estas herramientas.
Tenemos que tener instalado las librerias de desarrollo. En debian el paquete es libbluetooth1-dev.
Otra cosa a tener correctamente configurado es el sistema alsa así como sus librerías de desarrollo (libsound2-dev) para el tema del sonido.
La aplicacion handsfree viene con un Makefile por lo que salvo errores de librerias y rutas con un simple make deberíais tener el servicio compilado.
Ejecutando el servicio
Bueno, ahora viene la parte de ejecución del servicio, lo primero es asociar el móvil con el PC, generalmente te pedirá el pin. Este paso no es necesario y siempre puedes introducir el pin cada vez que uses el servicio, pero vamos, lo más cómodo es asociarlo (bluez-pin es la herramienta para gestionar los PIN desde la parte del PC).
A continuación es necesario añadir dos servicios al registro de servicios del PC, el serial port y el handsfree. Esto se realiza con sdptool, por lo tanto:
felix#:sdptool add SP
felix#:sdptool add HF
A continuación ejecutamos el servicio con:
felix#:./handsfree ADDR 3
ADDR es la dirección de tu móvil y 3 el canal del handsfree.
Para ver cuales son tus parámetros lo mejor es realizar un escaneo:
felix:hcitool scan
Scanning ...
00:15:A0:42:34:8D Nokia 6680
En cuanto al canal, pues mostrar todos los servicios de tu móvil y fijarnos en el canal (Channel) con:
felix:~# sdptool browse 00:15:A0:42:34:8D
Browsing 00:15:A0:42:34:8D ...
...todos los servicios
y ya esta todo, en teoría cuando recibas una llamada descuelgas y se escucha por los altavoces y hablas por el micro. Eso si, como dije al principio y dependiendo de la tarjeta de sonido puede sonar como los teleñecos :-).
Es posible descolgar mediante comandos AT directamente desde el PC y utilizando el propio programa.
Con esto y un poquito de shell puedes tener tu GNU/Linux siempre listo para atender llamadas.
un saludo
Probablemente NS2 es el simulador de redes open source más extendido tanto en investigación como para propósitos docentes, en esta receta vamos a aprender a instalarlo y a simular un escenario para MANET's muy simple.
Su configuración está en /etc/bluetooth/hcid.conf y la base de datos con los pin en /etc/bluetooth/pinDB
Descubrimiento de servicios
El demonio del protocolo de descubrimiento de servicios SDP (Service discovery protocol) es sdpd
Gestión de SDP
#sdptool
sdptool - SDP tool v2.24
Usage:
sdptool [options] <command>[command parameters]
Options:
-h Display help
-i Specify source interface
Commands:
search Search for a service
browse Browse all available services
records Request all records
add Add local service
del Delete local service
get Get local service
setattr Set/Add attribute to a SDP record
setseq Set/Add attribute sequence to a SDP record
Services:
DID SP DUN LAN FAX OPUSH FTP HS HF SAP NAP GN PANU HID CIP CTP
A2SRC A2SNK AVRCT AVRTG SR1 SYNCML ACTIVESYNC HOTSYNC PALMOS
NOKID PCSUITE
Es importante resaltar que para que un servicio sea descubierto, debes añadirlo mediante un sdptool add <servicio>, la lista de abajo del comando anterior nos muestra los servicios disponibles.
Algunos comando útiles
Con hcitool scan obtendrás una lista de los dispositivos presentes a tu alrededor.
$hcitool scan
Scanning ...
00:15:A0:42:34:8D Nokia 6680
Muestra la dirección bluetooth y el nombre, puedes comprobar la dirección bluetooth en los nokia 66** tecleando el código “*#2820#”
Para obtener una lista de los servicios que ofrece cada dispositivo usamos la herramienta sdptool, en nuestro caso, y para ver lo que ofrece el móvil:
#sdptool browse 00:15:A0:42:34:8D
Browsing 00:15:A0:42:34:8D ...
Service Name: Hands-Free Audio Gateway
Service RecHandle: 0x10003
Service Class ID List:
"Handfree Audio Gateway" (0x111f)
"Generic Audio" (0x1203)
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 2
Language Base Attr List:
code_ISO639: 0x454e
encoding: 0x6a
base_offset: 0x100
Profile Descriptor List:
"Handfree Audio Gateway" (0x111f)
Version: 0x0101
Service Name: Headset Audio Gateway
Service RecHandle: 0x10004
Service Class ID List:
"Headset Audio Gateway" (0x1112)
"Generic Audio" (0x1203)
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 3
Language Base Attr List:
code_ISO639: 0x454e
encoding: 0x6a
base_offset: 0x100
Profile Descriptor List:
"Headset" (0x1108)
Version: 0x0100
...todos los servicios
Esto proporciona toda la información que necesitas acerca de todos los servicios presentes en el dispositivo, en este caso el teléfono móvil.
Servicio dial-up networking
Nos vamos a centrar en el servicio dial-up networking, para ello observamos que la salida del comando anterior nos presenta la siguiente información:
Service Name: Dial-Up Networking
Service RecHandle: 0x1000e
Service Class ID List:
"Dialup Networking" (0x1103)
Protocol Descriptor List:
"L2CAP" (0x0100)
"RFCOMM" (0x0003)
Channel: 3
Language Base Attr List:
code_ISO639: 0x454e
encoding: 0x6a
base_offset: 0x100
Profile Descriptor List:
"Dialup Networking" (0x1103)
Version: 0x0100
Para indicarle al ordenador que vamos a usar ese servicio necesitas editar el archivos /etc/bluetooth/rfcomm.conf e insertar una entrada tal que:
donde el device es el identificador del movil y el channel el que nos indica el registro obtenido con sdptool, justo despues de “RFCOMM” (0×0003).
Reinicia para cargar la nueva configuración:
#/etc/init.d/bluez-utils restart
Restarting bluez-utils: hcid sdpd rfcomm.
#rfcomm release 1
#rfcomm connect 1
Connected /dev/rfcomm1 to 00:15:A0:42:34:8D on channel 10
Press CTRL-C for hangup
Ya tienes una conexión lista, con lo cual, por ejemplo, si estas en un portátil en mitad del campo y quieres conectarte a internet con tu
portátil a través de tu móvil tienes que configurar un enlace ppp a través del móvil.
Para eso, tienes comandos muy interesantes:
pand: TCP/IP sobre Bluetooth
—listen para el servidor
—connect para el cliente
/etc/bluetooth/pan/dev-up: pand ejecuta este script al levantar TCP/IP.
dund: Ejecutar PPP sobre Bluetooth RFCOMM
—listen para el servidor
—connect para el cliente
Si no has establecido una “relación de confianza” entre tu móvil y tu
portátil te pedirá en ambos dispositivos el pin.
Protocolo OBEX
Si quieres mandarle un archivo a tu teléfono puedes utilizar el protocolo OBEX. Con gnome-obex-send puedes mandarle un archivo y con gnome-obex-server debe aparecer una opción en nautilus, de forma que, si haces click en el botón derecho sobre un archivo debería aparecer una opcion para enviarlo via bluetooth.
Configurando un Headset
Una interesante aplicación es la de poder usar uno de esos micrófonos y auriculares bluetooth. Estos dispositivos implementan un servicio denominado headset.
Para ello existe un interesante proyecto basado en Alsa, lo puedes encontrar en bluetooth-alsa (no es paquete debian).
Dos errores que surgieron en la configuración son:
felix:#btsco
Error: control open (hw:0): No such device
Error: Can't find device. Bail
Esto indica que no tienes configurados los drivers de alsa y no encuentran los dispositivos. Prueba a instalar y ejecutar el alsaconf para instalar alsa.
Otro problema, despues de instalar los drivers de alsa puede ser:
felix:#btsco
Error: hwdep next device (hw:0): Operation not permitted
Error: control open (hw:1): No such device
Error: Can't find device. Bail
No tienes cargado el modulo del kernel snd-bt-sco, está en el directorio kernel del programa btsco, tienes que ejecutar make; make install en dicho directorio.
Si al hacer modprobe snd-bt-sco, no lo encuentra (y se te ha compilado todo bien) copia el .ko a mano a /lib/modules/2.6.14-2-386/kernel/drivers/ poniendo la versión del kernel que tengas (la mia es una 2.6.14-2-386).
Comentarios
Esta receta se irá ampliando conforme se prueben mas servicios y utilidades.
Si te gusta la tira Ecol, ahora puedes devolverle a su autor, algunas de las carcajadas con un pequeño favor, te necesita para llevarse unas pelas en el concurso de 20minutos por su blog (es tan bueno o mas que la tira).
Esta receta describe cómo configurar una red inalámbrica multisalto (MANET) bajo GNU Linux totalmente funcional.
Introducción
Las redes inalámbricas multisalto no necesitan de infraestructura fija para compartir datos entre distintos PC's, cada uno de los nodos que forman la red hacen las labores de un router de forma que se enrutan datos de unos a otros para formar una infraestructura de red dinámica. Si uno de los nodos tiene una conexión a Internet, los demas nodos pueden utilizar a éste como pasarela.
Requisitos previos
Como paso previo hay que hacer lo siguiente (a modo de precondiciones):
En el kernel tienes que tener compilado el "Netfilters"
Habilitar el Packet Forwarding. En /etc/sysconfig/network añadir una línea:
FORWARD_IPV4=yes
Tener configuradas las tarjetas wireless.
Montar la red ad-hoc
En lo relativo a la configuración de las tarjetas, es muy útil el comando iwconfig que permite la configuración de las tarjetas de forma similar al clásico ifconfig.
En Debian, ese comando está en el paquete wireless-tools.
Bien, tenemos una tarjeta Wireless (en mi caso PC Card WL100) configurada en un portátil con Debian.
El iwconfig nos dice que tenemos:
eth1 IEEE 802.11-DS ESSID:"COMPAQ" Nickname:"Prism I"
Mode:Managed Frequency:2.457GHz Access Point: 00:02:A5:2D:06:35
Bit Rate:11Mb/s Tx-Power=15 dBm Sensitivity:1/242700000
Retry min limit:8 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
Link Quality:49/1 Signal level:-53 dBm Noise level:-144 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:0 Invalid misc:0 Missed beacon:0
Es el momento de observar dos cuestiones importantes, la primero de ellas es el Mode que está en "Managed" (utilizado para asociarse a puntos de acceso) y el segundo es el ESSID.
Hay que señalar que para que esta tarjeta pueda formar parte de una red ad-hoc todas las tarjetas tienen que tener el mismo ESSID y estar puestas en modo ad-hoc.
Para ello, y utilizando el iwconfig ejecutamos:
homer:~# iwconfig eth1 mode ad-hoc
homer:~# iwconfig eth1 essid ARCO
homer:~# iwconfig
eth1 IEEE 802.11-DS ESSID:"ARCO" Nickname:"Prism I"
Mode:Ad-Hoc Frequency:2.457GHz Cell: 02:23:7A:CF:F1:E5
Bit Rate:5.5Mb/s Tx-Power=15 dBm Sensitivity:1/242700000
Retry min limit:8 RTS thr:off Fragment thr:off
Encryption key:off
Power Management:off
Link Quality:0 Signal level:0 Noise level:0
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:0 Invalid misc:0 Missed beacon:0
El segundo ordenador a utilizar en nuestra red es un ordenador de sobremesa con una tarjeta PCI-PCMCIA y con una tarjeta Wireless PC Card WL110. La salida del iwconfig es similar a la anterior, mientras que la salida del lsmod nos muestra el módulo orinoco_plx que es el driver que se ha usado.
Ahora es el momento de configurar las direcciones IP que van a formar parte de nuestra red ad-hoc. Idealmente, un nodo ad-hoc debería ser capaz de autoconfigurarse para formar parte de la red. En principio nosotros vamos a asignar estas direcciones de forma estática.
Edita el archivo /etc/networks/interfaces y añade la configuración de la interfaz eth1, por ejemplo:
Vemos la interfaz configurada con la dirección IP asociada.
Debemos hacer lo mismo tanto en el portátil como el otro PC.(obviamente con direcciones IP distintas).
Bien, en este momento deberíamos poder realizar un simple ping de un ordenador a otro a las direcciones que hayamos puesto, siempre y cuando estemos en el ámbito de cobertura.
Enrutando paquetes
Para tener una verdadera red inalámbrica multisalto debemos hacer que cada nodo enrute paquetes, para ello debemos instalar un algoritmo de enrutado, en nuestro caso vamos a usar el algoritmo AODV cuya implementación (una de ellas) podeis bajar de aodv_kernel
Siguiendo los pasos del archivo README no debe haber ningún problema. Básicamente:
Te bajas el archivo y lo descomprimes.
homer:~#tar xvzf kernel-aodv_v2.2.2.tgz
Ejecutas
homer:~#make
Cambias los ficheros start.sh y start_gateway.sh según los parámetros de la subred
ejecutas start.sh si eres cliente sin acceso a internet
ejecutas start_gateway.sh si vas a funcionar como gateway dentro de la red ad-hoc
En este momento detectará todos los nodos dentro de su alcance y los añadirá a la tabla de enrutado. Para ver la tabla de enrutado:
Muchos de vosotros habréis oido quejarse a la gente diciendo: "Mi equipo no me reconoce 4gb o más ...". Esto puede servir de excusa a gentuza como M$ para venderte que el nuevo SO (vista o 7) si que "reconocen" más de 3 gb.
En esta receta veremos como aprovechar al máximo la RAM de nuestro equipo sin tener que recurrir a versiones de 64 bits.
Pues sí, esas son las conclusiones a las que llega el informe "El Profesional Flexible en la Sociedad del Conocimiento: Nuevas Exigencias en la Educación Superior en Europa".
VideoLAN es un proyecto que permite tanto visualizar como servir vídeos en forma de streaming y bajo demanda. Es una alternativa más completa a Flumotion, ya que soporta protocolos como RTSP y MMS muy útiles para dispositivos móviles como PDAs.
En esta receta no voy a entrar a explicar como funciona el cliente VLC ni nada por el estilo, para eso esta el manual de VideoLAN. Yo solo voy a hacer referencia a como utilizar el core vlm que permite ejecutar VLC como servidor. También he probado VLS como servidor, pero como en las últimas versiones de VideoLAN se ha quedado obsoleto no voy a hacer más referencia a él a no ser que alguien lo pida explícitamente.
Fichero de configuración
Lo primero será crearse el fichero de configuración del servidor. Éste fichero es un simple fichero de texto que puede llamarse de cualquier forma. La nueva sintaxis que han introducido los desarrolladores de VideoLAN es muy coñazo, así que yo creo que mejor explico cada ejemplo por separado.
Ejemplo Unicast
# VLC media player VLM command batch
# http://www.videolan.org/vlc/
### Prueba de Unicast (Cambiar el PC destino)
new prueba1 broadcast enabled loop
setup prueba1 input "/home/.../LOTR-CD3.avi"
setup prueba1 output #duplicate{dst=std{access=udp,mux=ts,dst=EQUIPO_DESTINO:4321}}
control prueba1 play
Lo primero son los comentarios, que como se ve son con la almohadilla. Este ejemplo es de unicast a EQUIPO_DESTINO. Aquí se pone la IP del host cliente al cual se quiere servir el vídeo. En la primera línea se crea un nuevo componente con "new" de nombre "prueba1", lo activamos con "enabled" y hacemos que se ejecute en bucle "loop".
En la segunda linea indicamos el vídeo fuente que se va a servir con "input". En la tercera indicamos que el protocolo que se utilizará sera "udp" utilizando el formato MPEG-TS "ts" y cuyo destino será "EQUIPO_DESTINO" al puerto "4321". Por último activamos el streming en el servidor con "play".
El cliente simplemente ejecutará en su host:
$vlc udp://@:4321
O dentro del GUI "Abrir volcado de Red" en la pestaña UDP/RTP y elegir el puerto.
Ejemplo Broadcast
En el fichero de configuración incluimos lo siguiente:
### Prueba de BROADCAST (Solo PCs)
new prueba2 broadcast enabled loop
setup prueba2 input "/home/..../Matrix_f900.avi"
setup prueba2 output #standard{mux=ts,access=udp,dst=225.0.0.1,sap,name="Matrix Trailer"}
control prueba2 play
Este ejemplo es igual que el anterior, pero en el output indicamos una dirección multicast "225.0.0.1" y además incluimos un anuncio SAP del vídeo con el nombre "Matrix Trailer".
El cliente debe ejecutar:
$vlc udp://@225.0.0.1
VoD
### Prueba de VoD con RTSP
new Test vod enabled
setup Test input "/home/...../prueba.mpg"
Este ejemplo es distinto a los anteriores porque el elemento que aquí se necesita es un "vod" en vez de un "broadcast". Como entrada sólo se necesita el vídeo que demanda el cliente.
El servidor se deberá ejecutar con las siguientes opciones:
### Prueba de HTTP Straming para la PDA
new PDA broadcast enabled loop
setup PDA input "/home/..../dekkers.avi"
setup PDA output #duplicate{dst=std{access=http,mux=ts,dst=EQUIPO_DESTINO:8080}}
control PDA play
Ahora en el output se utiliza el protocolo "http". Es igual que el primer ejemplo pero sobre el protocolo HTTP.
El cliente para visualizarlo:
$vlc http://SERVER_IP:8080
MMSH de M$
### Prueba con MMSH
new procesado5 broadcast enabled loop
setup procesado5 input "/home/..../dekkers.avi"
setup procesado5 output #duplicate{dst=std{access=mmsh,mux=ts,dst=EQUIPO_DESTINO:5000}}
control procesado5 play
Igual que antes pero utilizando el protocolo "mmsh". Este protocolo también nos vale para el cliente ese raro "Media Player", o algo así creo que se llama.
Para cliente GNU/Linux:
$vlc mmsh://SERVER_IP:8080
Para cliente mierdero (M$) desde el "Media Player" acceder a: mms://SERVER_IP:8080.
Post-procesado
Hasta aquí hemos configurado casi todos los protocolos posibles que nos permite utilizar VideoLAN. Pero hay veces que para determinados dispositivos móviles el bit-rate del streaming es demasiado alto y hay que reducirlo para poder verlos. En esta sección vamos a ver un par de ejemplos de como hacerlo.
### Prueba de post-procesado (reduccion del bit-rate) para PDAs
new procesado1 broadcast enabled loop
setup procesado1 input "/home/.../invalid_display_width.mpeg"
setup procesado1 output #transcode{vcodec=mp2v,vb=512,scale=1,acodec=mp2a,ab=192,channels=2}:duplicate{dst=std{access=http,mux=ts,dst=EQUIPO_DESTINO:8081}}
control procesado1 play
Igual que antes configurábamos para HTTP pero aqui antes de hacer el "duplicate" hacemos un "transcode" que consiste en reducir el ratio de video a 512k y el de audio a 192k. Para ello se ha utilizado los codecs mp2v y mp2a para video y audio respectivamente. Para ver que codecs hay disponibles empollate la documentación que hay mucha.
Otro ejemplo:
new procesado4 broadcast enabled loop
setup procesado4 input "/home/.../Matrix_f900.ogg"
setup procesado4 output #transcode{vcodec=theo,vb=128,scale=1,acodec=vorb,ab=64,channels=2}:duplicate{dst=std{access=http,mux=ogg,dst=EQUIPO_DESTINO:8084}}
control procesado4 play
¿ Todo claro ?. Vamos, creo que se explica por sí solo.
Un saludo, Arturo.
Pues sí amiguitos, tal como lo oís. En una entrevista a la hermana Judith Zobelein explica como utiliza Linux pero bajo Mac. No entro en polémica con Unix. La hermana Judith es la responsable del departamento de internet del Vaticano. Lo que más me ha llamado la atención ha sido la frase: No sabemos que sistema operativo utiliza Dios, el Vaticano usa Linux. Hay lo llevas :P
Flumotion es una plataforma de streaming escrito en Python. Es una buena alternativa para hacer streaming live o VoD. La implementación se basa en dos frameworks expectaculares: gstreamer y twisted.
Entre las demás alternativas existentes para streaming, flumotion es una buena alternativa aunque la versión libre no soporta ni RTP ni broadcast streaming. Flumotion es paquete debian, pero la versión que está empaquetada no ofrece los mismos servicios que la versión 0.3.2 que se utiliza en esta receta.
Introducción
Esta plataforma se descompone en tres niveles:
High level: En este nivel hay manager's, atmosphere y flows.
Mid level: demonios de manager's y sorker's
Low level: componentes
Sólo existe una atmósfera en la que existe un manager dentro del "planeta" y luego hay flujos que contienen semillas y demás movidas.
Esto no lo entiendo ni yo, pero es la paranoia del desarrollador, así que habrá que tenerlo en cuenta.
En fin, que este tipo de diseño permite una instalación distribuida ya que el manager puede ejecutarse en un host y luego tener uno
o varios workers que se encarguen de diferentes flujos y así conseguir un sistema distribuido "acojonante". Si queréis ver mas sobre
esto leed el manual, aunque no esperéis gran cosa.
Ingredientes
Lo primero es conseguir los fuentes de la versión
0.3.2 de flumotion. También se pueden conseguir en el repo subversion:
$svn co https://core.fluendo.com/svn/flumotion/trunk flumotion
Instalación
Ahora toca compilar e instalar:
$./configure && make &&sudo make install
En /usr/local/bin/ tendremos todos los ejecutables de la plataforma. Como Flumotion utiliza conexiones SSL para poder
administrar es necesario crearse un certificado con openssl o utilizar el de prueba que esta en conf/default.pem.
Por defecto el certificado debe estar en /usr/local/etc/flumotion/. Sino hay que indicar su ubicación por línea de comandos.
$flumotion-worker -d 3 -u user -ptest> log/worker.log &
Para ver las demás opciones consultar el manual. Aunque
no esperéis gran cosa.
Ahora lanzémos la interfaz de administración. Hay dos: una con gtk y otra con ncurses. Yo utilizo la de gtk:
$flumotion-admin -v
Como se muestra en el manual la conexión con el manager se
puede hacer con o sin conexión SSL. Ya que nos ponemos, utilizamos SSL que por defecto se conecta por el puerto 7531. Si la conexión
no existe la creamos para futuros accesos. Lo primero que aparecerá en la interfaz de administración ser el wizard. Dentro de
el podremos configurar varios flujos, productores, consumidores, etc. Si le damos a todo "Siguiente" al final se crearan los jobs
necesarios para hacer nuestra primera prueba. Una vez arrancados todos los procesos es hora de probar el streaming. Por defecto podremos
acceder a el en la url http://localhost:8800/. Podremos acceder mediante un browser o con xine, mplayer, etc; en definitiva con el
reproductor multimedia que ms os guste. En este punto podremos observar la carta de ajuste de gstreamer.
La interfaz de administración en modo texto se llama: flumotion-admin-text y funciona de una forma similar a la anterior.
Configuración básica
Como alguien se habrá podido imaginar, los ficheros de configuración están en el directorio con/. Estos ficheros de configuración son
XML, lo cual facilita bastante el trabajo con la plataforma. El primer fichero a tener en cuenta es planet.xml:
Como mínimo es necesario un manager y luego se pueden utilizar tantos componentes como se necesiten. En este caso se utiliza
un "htpasswdcrypt-bouncer" para hacer la autenticación del administrador. En el worker hay que indicar el usuario/password
necesario para acceder a la interfaz de administración.
Otro fichero a tener en cuenta es el de los flujos. En principio se puede poner cualquier nombre a este fichero, pero habrá
que meterlo dentro de un directorio con el mismo nombre. Por ejemplo, dentro del directorio default/flows habrá que
añadir nuestros flujos. Por defecto, esta el fichero ogg-test-theora.xml para hacer pruebas. Su contenido es el
siguiente:
Como puede verse, solo tenemos un flujo que se llama "default". Y luego hay cuatro componentes:
video-source: que es de tipo videotest y se le asocia al worker localhost.
video-encoder: que es de tipo theora-encoder.
muxer-video: de tipo ogg-muxer. Este componente es el contenedor del stream.
http-video: de tipo http-streamer, que "saca" el stream por http ap puerto 8800.
El componente video-source es un productor, que genera la carta de ajuste de gstreamer en formato YUV con un ratio de 5
y un tamao de 320x240. El siguiente, video-encoder toma como entrada el stream de video-source y lo codifica en
formato ogg con un bitrate de 400, para posteriormente ser "mezclado" por ogg-muxer. Y finalmente. http-video hace
el streaming final sobre http.
Para probar otras configuraciones podemos utilizar el wizard. Con el wizard podemos tomar streaming a partir de webcams, cmaras
digitales, capturadores de TV, etc. Segn para lo que queramos nuestro servidor seleccionamos uno u otro. Tambin podemos elegir
audio o video, o los dos con overlay incluido; para finalmente pasarlo por http por nuestro puerto preferido. Todo esto configurable
fcilmente mediante la interfaz grfica.
Configuracin intermedia
En el apartado anterior solo hemos visto ejemplos bsicos (y lo que queda por llegar). Ahora es hora de ver todos los componentes
disponibles en la versin 0.3.2. Para ver los componentes disponibles hay que utilizar el comando:
$flumotion-inspect
El cual nos mostrar los componentes y plugs disponibles en nuestra versin. Si utilizais un versin antiga vereis como disponeis
de menos componentes, como es el caso de la versin empaquetada para debian. Para obtener ms informacin sobre un componente
concreto hacer:
$flumotion-inspect http-server
por ejemplo. Veremos las propiedades del componente http-server, que es el que voy a utilizar para el próximo ejemplo de
configuración. Este componente te permite tomar como fuente un fichero multimedia (usa ogg/vorbis por dios) y el solito se
encarga de hacer el streaming sobre la url que le especifiquemos. El fichero de flujo nuevo quedará así:
Accediendo a la URL: http://fulanito:8800 veremos nuestro video en HTTP streaming.
Configuración avanzada
Ya lo haré.
Visualizar el streaming
Anteriormente he comentado como se podría ver el video en streaming, bien mediante un browser o bien mediante nuestro reproductor
multimedia favorito. Pero cuando se pretende que el acceso a estos contenidos multimedia sean portables (todo el mundo me entiende)
es necesario buscar otro tipo de alternativas. La mejor sin duda es utilizar un browser y en esto ya han pensado los desarrolladores
de flumotion. Para ello han desarrollado cortado. Cortado es un applet que permite una
fácil visualización de los streams. Utilizarlo es muy sencillo, tan solo hay que añadirlo a nuestra web:
Esta receta explica cómo ejecutar comandos del sistema con los permisos de otro usuario.
Introducción
El principal objetivo de sudo es reemplazar al comando su. En algunas situaciones puede reemplazar al SUID. La principal ventaja de utilizar sudo es que no es necesario conocer la password de otro usuario para ejecutar comandos con permisos “especiales”.
Configuración
Lo primero será editar el fichero /etc/sudoers. Existe un comando llamado visudo que directamente edita el fichero con vi. Pero si alguno no sabe utilizar vi, puede utilizar cualquier otro editor. El fichero tiene el formato siguiente:
# Host alias specification
# User alias specification
# Cmnd alias specification
# User privilege specification
root ALL=(ALL) ALL
fulanito ALL=(ALL) ALL
En el podemos ver como el usuario root tiene permiso de todo al igual que el usuario fulanito. Muchos administradores opinan que hacer esto es “peligroso” si los usuarios son noveles, pero ese no es mi caso :-P.
El fichero se divide en tres secciones:
Definiciones de alias
Ajuste de opciones por defecto
Reglas de acceso
La sección más importante son las reglas de acceso, que tienen esta forma:
usuario host = (usuario_privilegiado) comando
En el ejemplo de antes se ha utilizado un alias especial ALL que engloba a todos los comandos, usuarios y demás historias. Para hacer una configuración más afinada lo mejor es que cada uno se cree sus propios alias y configuraciones. El nombre de usuario privilegiado que se pone entre paréntesis es opcional, si no se pone es root por defecto.
Otro punto a comentar es que cuando se ejecuta cualquier comando con sudo, al usuario se le pide su propia password. Esto impide que si un usuario deja una consola abierta otra persona puede realizar operaciones privilegiadas utilizando su sesión. Puedes evitar la comprobación de clave si escribes la palabra NOPASSWD antes del comando.
Por ejemplo, la siguiente línea permite al usuario webmaster parar y reiniciar el servidor web sin tener que poner su clave:
Hola a todos:
Hace tiempo que llevo buscando la manera de bajarme los videos de YouTube pero al fin he encontrado una forma de hacerlo. No sé si será la mejor, pero yo la explico por si le puede ayudar a alguien. Lo primero es tener instalado firefox (creo que todo el mundo lo utiliza ;-)), y sino mal asunto.
Si tenemos instalado nuestro flamante GNU/Linux y por alguna extraña circunstancia instalamos Windows, al reiniciar habremos perdido nuestro gestor de arranque (lilo, grub, etc). Esta receta resume cómo se puede recuperar dicho gestor de arranque para poder cargar nuestro GNU/Linux.
Procedimiento a seguir
Lo primero será arrancar nuestro PC con cualquier live-cd, no importa la distro. Cuando el entorno gráfico se haya cargado, se lanza un terminal de superusuario. La mayoria de los live-cd montan las particiones en modo de sólo lectura. Necesitamos remontar la partición de GNU/Linux con permisos de lectura-escritura.
Así que primero la desmontamos:
#umount /mnt/hda3
Y ahora la volvemos a montar partición con permisos de lectura-escritura. Suponemos que el disco es /dev/hda3, y se monta en el directorio /mnt/hda3.
#mount -t ext3 -o rw /dev/hda3 /mnt/hda3
Ahora montamos /proc:
#mount -t proc /mnt/hda3/proc
Ahora hacemos un poco de "magia":
#chroot /mnt/hda3/
Y ahora mismo estarás dentro del GNU/Linux que tienes en el disco duro. Has cambiado y ahora lo que verás como directorio "/" será el antiguo /mnt/hda3. Ahora falta volver a instalar nuestro gestor de arranque, en nuestro caso grub:
#grub-install /dev/hda
Y ahora reinicia el PC y saca el live-cd. Podrás comprobar como vuelves a ver tu querido grub.
Esta receta trata de como empezar desde cero en la instalación de una debian SARGE y de como configurar correctamente el hardware de nuestro equipo.
1. Instalar Debian SARGE vía DVD
Lo primero es conseguir los dos dvd's. Yo los compré de una revista (no voy a hacer propaganda poruqe no me pagan), pero se pueden conseguir en debian.
Se arranca el pc con el dvd y nos saldrá un pantallazo que pone "Press F1 for help or ENTER to boot: ", pulsamos enter y seguimos las instrucciones. Para instalar un kernel 2.6 donde dice "Press F2 through F10 for details, or ENTER to boot: " ponemos linux26.
En el paso de las particiones es donde hay que tener mas cuidado. Una vez instalado el sistema base, el equipo se reinicia, y nos da la posibilidad de instalar las aplicaciones via dvd, http, ftp o disco local. Elegimos la que mejor se adapte a nuestras necesidades. Después de esto, nos saldrá un pantallazo que nos da la posibilidad de seleccionar los programas que se pueden instalar. Luego se configura el grub y marchando ... ;-)
Tarjeta Ethernet: VIA Technologies, Inc. VT6105 [Rhine-III]
Network controller: Intel Corp. PRO/Wireless LAN 2100 3B Mini PCI Adapter
Modem: Smart Link 56K AC'97
Tarjeta de sonido: Intel 810 + Realtek AC'97 Audio
FireWire (IEEE 1394): VIA Technologies, Inc. IEEE 1394
Infrarrojos: Puerto infrarrojos SMC IrCC - Fast Infrared
FLASH memory: ENE Technology Inc CB710 Memory Card Reader
Vamos paso a paso configurando cada uno de los componentes.
Controlar la velocidad de la CPU automáticamente
APM está muerto. El futuro es ACPI, y una de las aplicaciones prácticas de ACPI es "Speedstep" (pero solo en los centrino).
Para ello necesitamos un kernel 2.6.X para poder aprovechar los estados "throttling". Se pueden utilizar los demonios powernow o cpudyn. Personalmente he probado los dos y me quedo con el primero.
¿ Que necesitamos ? Lo primero será instalar el demonio encargado de controlar la velocidad del centrino, este es powernowd. Para controlar si realmente funciona el invento, instalamos el applet CPU Frequency Scaling Monitor.
Una vez instalado esto, debemos comprobar si se han cargado los siguientes módulos:
Si es así, debemos fijarnos en el applet y ver si pasamos de 600 MHz (Userspace) a 1400 Mhz (Performance) cuando le damos un poco de caña al procesador.
Configurar la tarjeta gráfica
En mi caso dispongo de una tarjeta integrada Intel Corp. 82852/855GM. A partir del kernel 2.6.10 está disponible el driver "i810" y "drm". Lo único que hay que hacer es cargarlo con la orden modprobe i810. Este driver funciona bajo xfree-86. Si se quiere utilizar Xorg en vez de xfree, lo único que hay que hacer es desinstalar xfree e instalar Xorg. Al hacer esto se cargará el modulo "i915" en vez del "i810", con una mejora bastante sustancial.
Gestión de energía: APM, ACPI, APIC
Como se comentaba anteriormente APM está muerto. ACPI es el futuro. Para tener soporte con ACPI hay que instalar "acpi" y "acpid". Luego, para comprobar que funciona podemos comprobar que esté corriendo el demonio "acpid" o instalar un monitor de carga de bateria.
Otra cosa a tener en cuenta es la de hacer "hibernar" al pc. Esto se consigue compilando el kernel con esta opción y teniendo una swap más del doble que nuestra RAM. Una vez hecho esto se hace:
$echo 3 > /proc/acpi/sleep
Y el pc hibernará guardando el estado actual. Lo de la swap es importante.
Puertos USB
La instalación por defecto instala "hotplug" y "udev". Si no se han instalado, pues ya sabes "apt-get install ....".
Aqui voy a explicar como configurar un lápiz usb. Editamos el fichero /etc/fstab y añadimos la siguiente línea:
/dev/sda /mnt/sda vfat user,noauto 0 0
Ahora necesitamos crear el direcorio /mnt/sda con los permisos necesarios. Comprobamos que esté el módulo "usb-storage" cargado y nada, se pincha el lápiz y se monta.
Tarjetas PCMCIA
Lo mejor es comprar tarjetas que soporten el driver "orinoco". Sino probar cargando el modulo "yenta-socket".
Tarjeta Ethernet
EL modulo que soporta mi tarjeta es "via_rhine". Aunque con "8139too" y "8139cp" funciona también.
Esta interfaz es la que se suele utilizar cuando se transporta el pc de un sitio a otro, y a lo largo del camino tendremos distintas configuraciones en distintos lugares. En unos tendremos DHCP, mientras en otros habrá una IP fija. Para facilitar el trabajo de cambio de IP's existe "laptop-net".
Con esto podemos crearnos distintos "esquemas" y allí donde se vaya cargar uno u otro dependiendo de las configuraciones. Una vez instalado, se edita el fichero /etc/laptop-net/scheme y se añaden los esquemas. Un ejemplo es:
case "${SCHEME}" in
offline)
# Setting nothing means to leave the network interface disabled.
;;
down)
# El link esta abajo
;;
casa)
DHCP="no"
ADDRESS="1.2.3.4"
NETMASK="255.255.255.0"
BROADCAST="1.2.0.255"
NETWORK="1.2.0.0"
GATEWAY="1.2.3.1"
NAMESERVERS="62.42.230.24 62.42.63.52"
;;
*)
# Set to "yes" to use DHCP
DHCP="yes"
;;
esac
Yo tengo un esquema para DHCP (por defecto) y otro para mi casa. Para cambiar de esquema se hace:
$/etc/init.d/laptop-net scheme casa
Changing scheme from down to casa
PRO/Wireless LAN 2100
Para configurarlo utilizo el driver ipw2100. Si tienes instalado "module-assistant" te lo bajas, lo compilas y lo instalas. Una vez echo esto te bajas el firmware de "Sourceforge" firmware y lo descomprimes en /usr/lib/hotplug/firmware/. Cargas el módulo ipw2100 y compruebas con "dmesg" que todo se ha configurado correctamente.
Sino te queda claro mira este documento centrino.
Modem: Smart Link 56K AC'97
Con "module-assistant" te bajas slmodem-source, lo compilas y lo instalas y cargas el modulo "slamr". Una vez echo esto comprueba que este corriendo el demonio en /etc/init.d/sl-modem-daemon.
Tarjeta de sonido: Intel 810 + Realtek AC'97 Audio
$dmesg | grep 1394
ieee1394: Initialized config rom entry `ip1394'
ohci1394: $Rev: 1250 $ Ben Collins <bcollins@debian.org>
ohci1394: fw-host0: OHCI-1394 1.0 (PCI): IRQ=[11] MMIO=[fedff800-fedfffff] Max Packet=[2048]
ieee1394: Host added: ID:BUS[0-00:1023] GUID[0040d0010013f9e6]
eth1394: $Rev: 1247 $ Ben Collins <bcollins@debian.org>
eth1394: eth1: IEEE-1394 IPv4 over 1394 Ethernet (fw-host0)
En mi caso lo tengo configurado en la interfaz de red eth1:
eth1 Link encap:UNSPEC HWaddr 44-44-44-44-44-44-44-44
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Infrarrojos
Lo suyo es instalar "irda-utils" y "ircp" junto con "ircp-tray". Para lo único que utilizo el infrarrojo es para pasar ficheros al móvil, aunque se puede utilizar para controlar los mandos a distancia y demás historias.
Comprueba esto:
irda0 Link encap:IrLAP HWaddr 00:00:00:00
UP RUNNING NOARP MTU:2048 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:8
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
FLASH Memory
He visto en el kernel 2.6.12 que ya hay soporte para tarjetas de memoria SD y MMC. Pero todavía no lo he probado. Espero contar algo más en sucesivas actualizaciones.
En esta receta explico como compartir ficheros entre dos o más máquinas mediante NFS (Network File System). Una de las máquinas tiene que hacer de servidor y la otra de cliente.
Ingredientes
Hay que tener instalados los paquetes:
nfs-kernel-server
nfs-common
portmap
portmap permitirá realizar conexiones RPC al servidor y es el encargado de permitir o no el acceso al servidor a equipos concretos. Para saber si tienes portmap instalado bastará con hacer:
Fijate en las líneas marcadas con una flecha. Si el portmap no ofrece los servicios de NFS, es porque no se tiene instalado el servidor NFS.
Directorios compartidos
Una vez hecho esto, tienes que decidir lo que quieres compartir. Para ello edita el fichero /etc/exports; y añade el directorio que quieras dejar accesible, los permisos y el equipo o equipos que van a acceder a él.
Con esto indicas que vas exportar /home/arturo y /usr/local permitiendo acceso a tu rango de direcciones locales en modo de lectura/escritura.
En el caso del primero se accede sólo desde el equipo 192.168.0.4 en modo lectura-escritura, y en segundo toda la red local puede acceder a /usr/local.
Para tener un poco más de seguridad es necesario editar el fichero /etc/hosts.deny y añadir:
Con esto la seguridad es suficiente, aunque siempre se puede configurar de una forma más individualizada.
Si has cambiado el fichero /etc/exports después de iniciar el servicio NFS debes indicar al sistema que vuelva a leer el fichero y active los cambios. Esto lo puedes hacer reiniciando el demonio:
#/etc/init.d/nfs-kernel-server restart
O bien:
#exportfs -ra
Configurando el cliente
Ahora que ya tienes el servidor funcionando, prueba el acceso al directorio compartido desde la máquina cliente. Por ejemplo:
#mount 192.168.0.1:/home/arturo /mnt/nfs
Esto montaría el directorio /home/arturo del servidor en /mnt/nfs del cliente. Hay que tener en cuenta que el directorio /mnt/nfs debe tener los permisos pertinentes.
Sino se monta, debes revisar los ficheros de configuración del servidor y comprobar que son correctos.
Montando desde /etc/fstab
Si quieres que el sistema de ficheros NFS se monte al arrancar debes añadir una entrada en el fichero /etc/fstab:
En esta receta explico como instalar eDonkey2000. La idea es instalar el core en un PC y el cliente ed2k-gui en otro PC distinto.
Instalar el core
Después de bajar el core desde ed2k, lo siguiente es instalarlo:
#dpkg -i el_core_que_sea.deb
Y después configurarlo:
$ edonkeyclc
[--- Storing settings in '/XXXXX/XXXX/.eDonkey2000' ---]
Welcome to eDonkey2000 command line client 1.3.0
Enter commands at any time (type '?' for help)
>
Ahora se nos abre el shell del core. Lo primero será crearnos un usuario del core:
>name fulanito
Ahora vamos a establecer la velocidad máxima de bajada (20 KB/sec) y de subida (7 KB/sec), por ejemplo:
>dumax 20 7
Lo siguiente será crear un usuario y una contraseña para poder conectar desde los clientes gráficos a nuestro core (o cliente en modo texto):
>pass usuario passwd
Ten en cuenta que el passwd no se cifra ni nada por el estilo, por eso es aconsejable usarlo bajo una red segura.
Veamos lo que hemos creado:
> vo
Name: fulanito
Max Download Speed: 20.00
Max Upload Speed: 7.00
Line Speed Down: 0.00
TCP Port: 0
UDP Port: 3620
Admin Port: 4663
Admin Name: usuario
Admin Pass: passwd
Verbose: 0
SaveCorrupted: 1
MaxConnections: 45
ScreenLines: 24
Allow Private Messages: 0
Allow Viewing of Files: 0
Una vez configurado el core, salimos guardando la configuración introducida.
>q
Are you sure wanna quit (Y/n)?
y
Y ahora lo que hacemos es volver a lanzar el mismo programa pero indicandole que espere conexiones del cliente gráfico:
$edonkeyclc -g
Instalar el gui
En el otro PC nos tendremos que bajar el GUI ed2k-gui.
Al igual que antes, lo instalamos como root con:
#dpkg -i paquetito_gui.deb
Ahora lo lanzamos mediante el comando "ed2k_gui" o en el menú Aplicaciones -> Internet -> Controlador central eDonkey2000 GTK+.
Al iniciar el gui saldrá un ventana "Connect to...", pues bien, elegimos la segunda opción "Connect to a core running on another computer". Ahora hay que rellenar los siguientes datos:
Pulsamos aceptar y si todo ha ido bien deberiamos acceder al gui sin ningún problema. Una vez dentro hay que cambiar una opción importante para que el core siga corriendo en la otra máquina aunque cerremos el gui. Esta opción se encuentra en la pestaña "Opciones" -> "GUI1". Hay que desmarcar la opción que pone "apagar el núcleo al salir". Las demás opciones a gusto del cosumidor :-).
Script de inicio
Este es el script que he incluido en /etc/init.d/ para que cuando se encienda la máquina el core se ejecute,
yo lo he llamado "core-ed2k":
Tcpstat es un programa que nos da distintas estadísticas sobre la red. Estas estadísticas las puede obtener monitorizando una interfaz de red, o leyéndolas de una captura previa desde un fichero.
Introducción
Tcpstat hace uso de la librería pcap, utilizada para capturar paquetes, al igual que otros programas como tcpdump, wireshark, dsniff o snort. Por lo tanto con Tcpstat podremos analizar ficheros de captura creados con cualquier otro programa compatible con el formato pcap.
Instalación
En Debian tan sencillo como:
#apt-get install tcpstat
Ejecución
Pcap accede directamente al interfaz de red para poder hacer las mediciones oportunas (capturando los paquetes que pasen por esa interfaz). Por este motivo, tiene que ejecutarse como root si vamos a capturar paquetes de la interfaz de red. No es necesario si los paquetes los lees desde un fichero pcap.
Un pequeño ejemplo puedes ejecutarlo tecleando:
#tcpstat -i eth0
Con esto obtendrás las estadísticas cada 5 segundos, incluyendo la tasa de bps, la media de bytes por paquete y la desviación típica de bytes por paquete.
Opciones
A continuación explico las opciones más importantes:
-F Hace un flush a la salida estándar, útil cuando se utiliza con tuberías o se redirige su salida a algún fichero.
-f “filtro” Aplica un filtro a las estadísticas. Este filtro tiene la misma sintaxis que un filtro de pcap (ver manual de tcpdump)
-o “cadena” Cadena de formato de salida. En el siguiente apartado veremos en qué consiste.
-s segundos Se ejecuta sólo durante el número de segundos especificado, y luego sale. Por defecto se ejecuta hasta que se pulse Control-C.
-p No pone el interfaz en modo promiscuo (por defecto lo pone en modo promiscuo)
-r fichero.pcap Lee del fichero pcap indicado en lugar de una interfaz de red.
-e Elimina los intervalos sin estadísticas.
-l Incluye la capa de enlace en el cálculo del tamaño de paquete.
También puedes especificar un intervalo de actualización, tras el cual se actualicen las estadísticas. Para especificar un intervalo de actualización de 1 segundo, ejecutarías:
A continuación pongo algunos ejemplos sencillos que te pueden resultar útiles.
Para medir estadísticas de transferencia HTTP
#tcpstat -f"tcp port http"-i eth0 1
Para medir el bitrate de un stream RTP que nos llega al puerto 1234
#tcpstat -f"udp port 1234"-i eth0 -o"bps=%b\n" 1
Para ver el uso de un servidor FTP en modo activo (puerto 21 control y 20 datos)
#tcpstat -f"port 20 or port 21"-i eth0 1
Para ver la tasa de transferencia y carga de la red de un servidor gnump3d
#tcpstat -f"port 8888"-i eth0 -o"Tasa de transferencia:%b\tCarga de la red:%l\n" 1
Para leer las estadísticas de un fichero capturado previamente con Wireshark
$tcpstat -r captura.pcap 0.5
Con imaginación puedes darle muchos más usos, según lo que necesites monitorizar. Para mayor información sobre los filtros, consulta el manual de tcpdump.
Conclusión
Tcpstat puede ser una buena herramienta para administradores de redes y de servidores para obtener diversa información sobre el uso de la red.
Veremos como podemos hacer streaming utilizando el protocolo RTP (Real Time Protocol), usando tuberías GStreamer. Transmitiremos tanto audio como vídeo a través de las tuberías.
Introducción
Necesitas tener instalados los paquetes gstreamer0.10-tools y los plugins necesarios: gstreamer0.10-plugins-base, gstreamer0.10-farsight, gstreamer0.10-plugins-good, gstreamer0.10-plugins-ugly, gstreamer0.10-alsa, gstreamer0.10-ffmpeg y gstreamer0.10-x.
El soporte de RTP en GStreamer actualmente es parcial, aún así, ya es posible ejecutar algunas tuberías que nos transmiten vídeo y audio utilizando RTP encima de UDP.
RTP se compone de dos protocolos: RTP y RTCP. RTP es el encargado de transmitir los datos del flujo multimedia, y RTCP se encarga del control de flujo. En los elementos udpsrc y udpsink de la tubería es necesario especificar un puerto par, que será usado por RTP. RTCP usará justo el siguiente, un puerto impar. También puede especificarse un host opcional para especificar la interfaz por donde mandaremos los paquetes.
Vídeo MPEG4
Ejecuta la siguiente tubería (emisor) con la opción verbose:
Presta atención a las Capabilities (caps) de udpsink, es el tipo de datos que se transmitirán por la red. Copia los caps del elemento udpsink. Los caps cambian cada vez que se ejecuta el emisor.
A continuación, lanza el receptor, especificando los caps en el udpsrc
En el receptor, la opción "sync=false" en los sink finales (xvimagesink, alsasink, etc) es importante, puesto que aún no hay implementado un gestor de la sesión RTP que controle la sincronización en la tubería.
Puedes especificar en el udpsrc una URI del tipo "udp://host:puerto" de donde debe coger los datos.
Audio Vorbis
La forma de proceder es la misma. Primero ejecuta el emisor:
Todo esto teóricamente se podría utilizar para transmitir en directo el escritorio de nuestro equipo a numerosos equipos mediante multicast, útil por ejemplo, para que los alumnos vean la pantalla del profesor en su ordenador.
También hay soporte para transmitir vídeo Theora y vídeo H.263, pero no está suficientemente probado.
Vamos a ver como podemos crear reproductores GStreamer para los distintos códecs de audio y vídeo existentes, usando gst-launch y construyendo las distintas tuberías usando los distintos plugins de GStreamer.
Ingredientes
Necesitas tener instalados los paquetes gstreamer0.10-tools y los plugins necesarios: gstreamer0.10-plugins-base, gstreamer0.10-farsight, gstreamer0.10-plugins-good, gstreamer0.10-plugins-ugly, gstreamer0.10-alsa, gstreamer0.10-ffmpeg y gstreamer0.10-x. Veremos como podemos crear reproductores genéricos, de audio y de vídeo. Según el códec del fichero que quieras reproducir, tienes que ejecutar en una consola la tubería GStreamer oportuna.
Si quieres saber los plugins GStreamer instalados en el sistema, puedes usar gst-inspect-0.10.
Son bienvenidas las tuberías para reproducir otros tipos de ficheros.
Buenas!Hace un par de días, en uno de mis ratos libres se me ocurrió buscar información sobre cómo crear tu propio sistema de ficheros para Linux (si, el kernel). En los nomerosos foros comentaban que era algo muy díficil y que requería mucho tiempo y esfuerzo. Bien, esto es verdad... pero también es verdad que no tenemos porqué enfrentarnos al problema en todo su esplendor. Existe un modulito para los Linux 2.4 y 2.6 que permite montar sistemas de ficheros en espacio de usuario. Esta receta explicará como crearnos nuestro propio filesystem para montarse mediante fuse y para ello nada mejor que crearnos nuestro propio FS.
Qué es FUSE
Inicialmente FUSE era un componente de AFS. Finalmente se desarrolló como componente independiente y AFS se convirtió en un módulo de AFS.
FUSE se compone de un módulo que se carga en el kernel y una biblioteca que facilita el acceso al mismo. Además, para desarrollar módulos en un determinado lenguaje debe existir un wrapper para dicho lenguaje. Afortunadamente para nosotros existe uno para python, en Debian y similares:
$sudo aptitude install python-fuse
A la hora de utilizar un FS determinado FUSE se encargará de realizar todas las tareas comunes y cuando haya que realizar algo específico de nuestro FS se invocará a alguno de los métodos escritos por nosotros.
FUSE está diseñado para ofrecer soporte absoluto a FS's que cumplan todas las normas Posix. Evidentemente no es necesario para el funcionamiento de cualquier FS que se implementen todas esas funciones (como veremos más adelante), así que si alguna acción no la hemos implementado FUSE se las arreglará con lo que tenga. Si finalmente no se puede realizar la acción se eleva un error que nos mostrará el sistema operativo (por ejemplo: sistema de ficheros de sólo lectura).
Nuestro sistema de ficheros
Nosotros vamos a crear un sistema de ficheros con las siguientes características:
NO es persistente, es decir: cuando desmontemos volarán todos los datos.
NO soportará gestión de permisos.
NO soportará fechas (ni de creación, modificación, etc.)
NO permitirá enlaces simbólicos.
Vaya guarrería de sistema de ficheros... ¡pues claro! la primera versión está escrita en unas horas de tiempo libre además pretende ser muy simple para que sirva de ejemplo. Nosotros implementaremos lo siguiente:
Creación/eliminación de directorios
Creación/eliminación de ficheros
Modificación de ficheros
Mover/renombrar ficheros y directorios
Nivel de anidamiento ilimitado (teórico, claro)
¿Cómo implementaremos nuestro FS? pues de una forma muy simple: un directorio será un diccionario en python, la clave será el nombre (del fichero o directorio) y el valor será:
Una cadena si se trata de un fichero
Otro diccionario si se trata de un subdirectorio
Cómo escribir un módulo para FUSE
Bueno, nuestros módulos van a ser ejecutables que aceptarán opciones similares a mount y mediante los cuales podremos montar directamente nuestro FS en la estructura de directorios de nuestro sistema.
A la hora de depurar nuestro FS debéis saber que los print no se van a mostrar por pantalla (se acabó la depuración por chivatos) y que las excepciones no capturadas se las comerá FUSE y como mucho obtendremos por consola un "imposible hacer XXX: argumento no válido". Así que puede ser una buena tarea estudiar un poquito el módulo logging de python ;).
A la hora de implementar los métodos a los que invocará FUSE tenemos tres opciones:
No escribir el método: se elevará una excepción que capturará FUSE y obtendremos un mesaje similar a "imposible hacer XXX: no implementado".
Escribir un método hueco que devuelva error: obtendremos el mensaje de antes, sin embargo nos resultará útil para saber qué acciones en el FS ocasionan llamadas a unos métodos u otros (cosa que supongo podríamos ver estudiando código y documentación).
Implementar el método y que devuelva un valor correcto o error en caso de fallo: cuantos más de estos tengamos, mejor será nuestro FS :D.
La clase principal, la que utilizará FUSE deberá heredar de la clase Fuse y cuando creemos una instacia de nuestro FS le pasaremos unos parámetros que indicarán a FUSE la clase de FS que va a manejar, si el módulo permite acceso concurrente, cómo debe tratar el carácter de separación de directorios, etc.
Así de buenas a primeras el esqueleto de aplicación FUSE podría ser como sigue:
#!/usr/bin/env python
importfusefromfuseimportFuseifnothasattr(fuse,'__version__'):raiseRuntimeError, \
"python-fuse doesn't know of fuse.__version__, probably it's too old."fuse.fuse_python_api=(0,2)# My FS, only stored in memory :P
#
classDictFS(Fuse):"""
"""def__init__(self,*args,**kw):Fuse.__init__(self,*args,**kw)# Root dir
self.root={}defmain():usage="""
Userspace filesystem example
"""+Fuse.fusagefs=DictFS(version='%prog'+fuse.__version__,usage=usage,dash_s_do='setsingle')fs.parse(errex=1)fs.main()if__name__=='__main__':main()
Como véis en el constructor nos hemos creado el directorio raíz de nuestro FS. Si no hubiésemos necesitado nada, podríamos habernos ahorrado el método completo.
Entradas de directorio y atributos
Como ya sabéis, una entrada de directorio en nuestro FS será un fichero o un directorio. Cada vez que FUSE entre en un directorio o vaya a leer un fichero, preguntará primero por sus atributos. Para ello invocará al método getstats(path) de nuestra clase y le pasará la ruta ruta completa dentro de nuestro FS. El raíz de nuestro FS será '/' que no tiene porqué coincidir con el '/' de nuestro sistema. Este método es básico en nuestro FS y debe retornar un objeto de tipo fuse.stats.
Podemos crearnos nosotros nuestra propia clase de atributos:
Vamos a hacer esto porque en nuestro ejemplo siempre vamos a devolver un objeto de estos, pero modificando algunos atributos según sea el caso.
Atributos de directorio
Cambiaremos los siguientes valores:
st_mode = stat.S_IFDIR | 0755 (recordad que deben ser ejecutables)
st_nlink = 2 (numero de enlaces al fichero, debe ser distinto de 0, en directorios se usa 2)
El resto de parámetros podemos dejarlos intactos, ya hemos dicho que no trataremos al dueño del fichero ni las fechas de modificacion, acceso, etc. Además, para los directorios se asumen que tienen tamaño 0.
Atributos de archivo
Ahora los valores serán:
st_mode = stat.S_IFREG | 0666 (así impedimos ejecución de ficheros en nuestro FS)
st_link = 1 (en nuestro FS siempre será 1, 0 indicaría archivo borrado)
st_size = longitud del fichero (de la cadena en nuestro caso)
Nuestas funciones auxiliares
Bueno, lo suyo es que si nos hacemos un FS nos hagamos una clase a parte que implemente nuestro FS y el modulito de FUSE sirva de wrapper entre nuestra clase y el FUSE. Pero bueno, voy a pasar y como queremos un ejemplo simple lo metemos todo en la misma clase. Un ejemplo de esto serán las funciones auxiliares que nos vamos a crear.
La principal es __get_dir(path) que, siendo path una lista de elementos (nombres de directorio), caminará desde el diccionario root hasta llegar al último elemento de la lista (directorio hoja) y nos lo devolverá.
Los métodos __join_path(path) y __path_list(path) convierten una lista de elementos en una cadena del tipo "/elemento1/elemento2" y viceversa (si, conozco os.path.join() y tal pero preferí escribirlos yo).
Por último está __navigate(path). Este método nos resultará muy útil porque cada vez que FUSE se refiere a un elemento de nuestro FS lo hace utilizando la ruta completa dentro de nuestro FS. Así, si nos indicase "/dir1/dir2/elemento1", este método nos devolvería el directorio dir2 y el nombre de elemento1. Como veréis más adelante, esto nos hará todo el trabajo.
El código de las funciones es el siguiente, no hay mucho más que comentar sobre ellas:
# Return string path as list of path elements
def__path_list(self,path):raw_path=path.split('/')path=[]forentryinraw_path:ifentry!='':path.append(entry)returnpath# Return list of path elements as string
def__join_path(self,path):joined_path='/'forelementinpath:joined_path+=(element+'/')returnjoined_path[:-1]# Return dict of a given path
def__get_dir(self,path):level=self.rootpath=self.__path_list(path)forentryinpath:iflevel.has_key(entry):iftype(level[entry])isdict:level=level[entry]else:# Walk over files?
return{}else:# Walk over non-existent dirs?
return{}returnlevel# Return dict of a given path plus last name of path
def__navigate(self,path):path=self.__path_list(path)entry=path.pop()# Get level
level=self.__get_dir(self.__join_path(path))returnlevel,entry
Los métodos propios de nuestro FS
Bien, ya tenemos todos los ingredientes, pero si ahora intentásemos montar un directorio con nuestro módulo nos daría error porque FUSE no sería capaz de leer el directorio raíz de nuestro FS. La primera llamada que intenta FUSE es: getattr('/') así pues, lo primero que tenemos que implementar es ese método:
defgetattr(self,path):st=MyStat()# Ask for root dir
ifpath=='/':#return self.root.stats
st.st_mode=stat.S_IFDIR|0755st.st_nlink=2returnstlevel,entry=self.__navigate(path)iflevel.has_key(entry):# Entry found
# is a directory?
iftype(level[entry])isdict:st.st_mode=stat.S_IFDIR|0755st.st_nlink=2returnst# is a file?
iftype(level[entry])isstr:st.st_mode=stat.S_IFREG|0666st.st_nlink=1st.st_size=len(level[entry])returnst# File not found
return-errno.ENOENT
Este método creo que es un poco spaguetti porque el caso especial del root realmente no existiría. A parte de esto el funcionamiento es simple: creamos un objeto stats. Cuando nos preguntan por un elemento, si existe y es un directorio (un diccionario) ponemos unos valores a los atributos y lo retornamos. Si era un archivo (una cadena) pues ponemos otros valores y lo retornamos. Si la función no retorna nada obtendremos un parámetro inválido y la operación sobre nuestro FS fallará. Si retornamos -errno.ENOENT obtendremos un fichero no encontrado.
Operaciones con directorios
Ahora mismo ya podríamos montar nuestro FS, pero un simple ls sobre él nos daría error. Ahora hay que implementar tres operaciones para poder listar, crear y borrar directorios: readdir(path, offset), mkdir(path, mode) y rmdir(path) respectivamente.
defreaddir(self,path,offset):file_entries=['.','..']# Get filelist
level=self.__get_dir(path)iflen(level.keys())>0:file_entries+=level.keys()file_entries=file_entries[offset:]forfilenameinfile_entries:yieldfuse.Direntry(filename)
Este método recibe el path sobre el que obtener el contenido y un offset que indica cual es el primer elemento de la lista a devolver (en todas mis pruebas siempre valía 0). Como véis hay que añadir a pelo los directorios "," (por eso en directorios st_nlink = 2) y el enlace al padre (esto es: ".."). En vez de retornar una lista pasamos directamente el iterador. Usamos un método de python-fuse que construye una entrada de directorio a partir del nombre.
Con este método podremos hacer ahora ls en nuestro FS que no dará error... pero claro, tampoco mostrará nada porque nuestro FS está vacío... Vamos a permitir la creación de directorios, para ello implementamos el siguiente método:
defmkdir(self,path,mode):level,entry=self.__navigate(path)# Make new dir
level[entry]={}
Es tan fácil que no hay nada que explicar... ;) Si ahora montamos nuestro FS (al final tenéis un ejemplo de cómo) veréis que podemos crear directorios, ir a ellos y listarlos... ¡todo un avance! Si intentamos borrarlos... ¡fail! así que añadimos esa posibilidad:
Ahora también podremos hacer rmdir o rm sobre un directorio... pero cuidado que si un directorio no está vacío, se eliminará también (aquí no comprobamos que no lo esté). No es demasiado grave puesto que python tiene garbage collector y no se nos quedarán por ahí directorios sin enlazar ocupando memoria...
Operaciones con ficheros
Bien, ya podemos trabajar con directorios como con cualquier otro FS... pero... ¿y los ficheros? estos son bastante más chicha...
Si montáis nuestro FS y hacéis un touch os dará un unimplemented error, nos hacen falta dos métodos (además del getstat()) para poder realizarlo: mknod(path, mode, dev) y open(path, flags). El primero creará el enlace y el segundo intentará abrirlo (aunque luego no realice operaciones sobre él). Estas dos operaciones no deben devolver error (o elevar una excepción) para que touch funcione. La primera es bastante sencilla:
defmknod(self,path,mode,dev):level,filename=self.__navigate(path)# Make empty file
level[filename]=''
Nuestro método no retornará nada (ni elevará ninguna excepción) lo cual indicará a FUSE que todo ha ido bien. Del modo de creación pasamos completamente (ya que no mantenemos un objeto stats por cada elemento del FS). El parámetro dev es un identificador interno del kernel que representa al manejador de dispositivo asociado al FS... también pasaremos de él :).
El segundo método tampoco es complicado:
Símplemente verificamos que exista o no el fichero. Daos cuenta que en un FS real esto es más complicado puesto que deberíamos comprobar los flags con los permisos del fichero. También mantendríamos una lista de ficheros abiertos si quisiéramos controlar la concurrencia, etc.
En este momento el touch crearía ficheros vacíos... pero después daría un error extraño. ¡Pues claro! porque hemos implementado el open() pero no el close()... que en este caso se llama release(path):
Todo lo dicho para el open() es válido ahora para release() así que poco más que comentar.
En este punto ya podemos trabajar con directorios en nuestro FS y crear archivos vacíos con touch... pero si creamos un fichero con emacs por ejemplo y le damos a guardar... ¡error! pues claro... para leer y escribir de un fichero necesitamos dos métodos nuevos: read(path, length, offset) y write(path, buf, offset).
La función read() debe retornar un buffer (una cadena, en python) de como mucholength bytes, leídos del elemento path a partir del byte offset. O dicho en pythonés:
defread(self,path,length,offset):level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENT# Check ranges
file_size=len(level[filename])ifoffset<file_size:# Fix size
ifoffset+length>file_size:length=file_size-offsetbuf=level[filename][offset:offset+length]else:# Invalid range returns no data, instead error!
buf=''returnbuf
El método es bastante simple, pero hay que tener cuidado con los rangos y demás. Con el método write() tenemos menos problemas:
defwrite(self,path,buf,offset):level,filename=self.__navigate(path)# Write data into file
ifoffset>len(level[filename]):offset=(offset%len(level[filename]))# This operation could be truncate the file!!
level[filename]=level[filename][:offset]+str(buf)# Return written bytes
returnlen(buf)
¡Y listo! ya podemos leer y escribir dentro de los ficheros de nuestro FS... ahora abrimos un fichero existente, le añadimos algunos bytes, le damos a aguardar y... ¡¡error!! ¿y esto? pues... ¿qué va a ser? esa operación también hay que implementarla y se llama truncate(path, size): permite modificar el tamaño de un fichero existente. El método es sencillo: truncar la cadena o concatenarla según sea necesario...
deftruncate(self,path,size):level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENTiflen(level[filename])>size:# Truncate file to specified size
level[filename]=level[filename][:size]else:# Add more bytes
level[filename]+=' '*(size-len(level[filename]))
Y ahora sí... montad el FS y perrear con él... veréis que casi todo funciona. ¿Todo? pues si intentáis mover/renombrar un fichero o directorio... ¡¡FAIL!!... aún nos queda un método más: rename(oldPath, newPath). Implementar el movimiento/renombrado de ficheros en nuestro FS tampoco es muy difícil :P. A ver qué os parece:
defrename(self,oldPath,newPath):oldLevel,oldFilename=self.__navigate(oldPath)# Can't use __navigate() because newPath-filename not exists
newPath=self.__path_list(newPath)newFilename=newPath.pop()newLevel=self.__get_dir(self.__join_path(newPath))# Make new link
newLevel[newFilename]=oldLevel[oldFilename]# Remove old
self.unlink(oldPath)
Tampoco hay mucho que comentar así que ya os dejo de dar la lata... ¡ahora a probarlo!
Probando el invento
Supongamos que habéis creado el archivo dictfs.py con permisos de ejecución y toda la pesca. Si estáis en el grupo de FUSE o sois sudoers:
$mkdir mymnt
$sudo ./dictfs.py mymnt/
Y ya está... ¡montadito! (hombres de poca fé, tecleen mount para verificarlo!). Para desmontar pues el umount de toda la vida ;)
El código completo
Bueno, tengo el ejemplo en mi github pero aquí os voy a copiar la versión inicial (supongo que si actualizo, también lo haré aquí):
#!/usr/bin/env python
#
# Released under GPLv3 license
# Read full text at: gnu.org/licenses/gpl-3.0.html
#
importosimportstatimporterrnoimportfusefromfuseimportFuseifnothasattr(fuse,'__version__'):raiseRuntimeError, \
"python-fuse doesn't know of fuse.__version__, probably it's too old."fuse.fuse_python_api=(0,2)importloggingLOG_FILENAME='dictfs.log'logging.basicConfig(filename=LOG_FILENAME,level=logging.DEBUG)# Only make one of this whe getstat() is called. Real FS has one per entry (file
# or directory).
#
classMyStat(fuse.Stat):def__init__(self):self.st_mode=0self.st_ino=0self.st_dev=0self.st_nlink=0self.st_uid=0self.st_gid=0self.st_size=0self.st_atime=0self.st_mtime=0self.st_ctime=0# My FS, only stored in memory :P
#
classDictFS(Fuse):"""
"""def__init__(self,*args,**kw):Fuse.__init__(self,*args,**kw)# Root dir
self.root={}# Return string path as list of path elements
def__path_list(self,path):raw_path=path.split('/')path=[]forentryinraw_path:ifentry!='':path.append(entry)returnpath# Return list of path elements as string
def__join_path(self,path):joined_path='/'forelementinpath:joined_path+=(element+'/')returnjoined_path[:-1]# Return dict of a given path
def__get_dir(self,path):level=self.rootpath=self.__path_list(path)forentryinpath:iflevel.has_key(entry):iftype(level[entry])isdict:level=level[entry]else:# Walk over files?
return{}else:# Walk over non-existent dirs?
return{}returnlevel# Return dict of a given path plus last name of path
def__navigate(self,path):# Path analysis
path=self.__path_list(path)entry=path.pop()# Get level
level=self.__get_dir(self.__join_path(path))returnlevel,entry### FILESYSTEM FUNCTIONS ###
defgetattr(self,path):st=MyStat()logging.debug('*** getattr(%s)',path)# Ask for root dir
ifpath=='/':#return self.root.stats
st.st_mode=stat.S_IFDIR|0755st.st_nlink=2returnstlevel,entry=self.__navigate(path)iflevel.has_key(entry):# Entry found
# is a directory?
iftype(level[entry])isdict:st.st_mode=stat.S_IFDIR|0755# rwx r-x r-x
st.st_nlink=2logging.debug('*** getattr_dir_found: %s',entry)returnst# is a file?
iftype(level[entry])isstr:st.st_mode=stat.S_IFREG|0666# rw- rw- rw-
st.st_nlink=1st.st_size=len(level[entry])logging.debug('*** getattr_file_found: %s',entry)returnst# File not found
logging.debug('*** getattr_entry_not_found')return-errno.ENOENTdefreaddir(self,path,offset):logging.debug('*** readdir(%s, %d)',path,offset)file_entries=['.','..']# Get filelist
level=self.__get_dir(path)# Get all directory entries
iflen(level.keys())>0:file_entries+=level.keys()file_entries=file_entries[offset:]forfilenameinfile_entries:yieldfuse.Direntry(filename)defmkdir(self,path,mode):logging.debug('*** mkdir(%s, %d)',path,mode)level,entry=self.__navigate(path)# Make new dir
level[entry]={}defmknod(self,path,mode,dev):logging.debug('*** mknod(%s, %d, %d)',path,mode,dev)level,filename=self.__navigate(path)# Make empty file
level[filename]=''# This method could maintain opened (or locked) file list and,
# of course, it could check file permissions.
# For now, only check if file exists...
defopen(self,path,flags):logging.debug('*** open(%s, %d)',path,flags)level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENT# No exception or no error means OK
# In this example this method is the same as open(). This method
# is called by close() syscall, it's means that if open() maintain
# an opened-file list, or lock files, or something... this method
# must do reverse operation (refresh opened-file list, unlock files...
defrelease(self,path,flags):logging.debug('*** release(%s, %d)',path,flags)level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENTdefread(self,path,length,offset):logging.debug('*** read(%s, %d, %d)',path,length,offset)level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENT# Check ranges
file_size=len(level[filename])ifoffset<file_size:# Fix size
ifoffset+length>file_size:length=file_size-offsetbuf=level[filename][offset:offset+length]else:# Invalid range returns no data, instead error!
buf=''returnbufdefrmdir(self,path):logging.debug('*** rmdir(%s)',path)level,entry=self.__navigate(path)# File exists?
ifnotlevel.has_key(entry):return-errno.ENOENT# Delete entry
del(level[entry])deftruncate(self,path,size):logging.debug('*** truncate(%s, %d)',path,size)level,filename=self.__navigate(path)# File exists?
ifnotlevel.has_key(filename):return-errno.ENOENTiflen(level[filename])>size:# Truncate file to specified size
level[filename]=level[filename][:size]else:# Add more bytes
level[filename]+=' '*(size-len(level[filename]))defunlink(self,path):logging.debug('*** unlink(%s)',path)level,entry=self.__navigate(path)# File exists?
ifnotlevel.has_key(entry):return-errno.ENOENT# Remove entry
del(level[entry])defwrite(self,path,buf,offset):logging.debug('*** write(%s, %s, %d)',path,str(buf),offset)level,filename=self.__navigate(path)# Write data into file
ifoffset>len(level[filename]):offset=(offset%len(level[filename]))level[filename]=level[filename][:offset]+str(buf)# Return written bytes
returnlen(buf)defrename(self,oldPath,newPath):logging.debug('*** rename(%s, %s)',oldPath,newPath)oldLevel,oldFilename=self.__navigate(oldPath)# Can't use __navigate() because newPath-filename not exists
newPath=self.__path_list(newPath)newFilename=newPath.pop()newLevel=self.__get_dir(self.__join_path(newPath))# Make new link
newLevel[newFilename]=oldLevel[oldFilename]# Remove old
self.unlink(oldPath)defmain():usage="""
Userspace filesystem example
"""+Fuse.fusagefs=DictFS(version='%prog'+fuse.__version__,usage=usage,dash_s_do='setsingle')fs.parse(errex=1)fs.main()if__name__=='__main__':main()
Va con comentarios del director y logging, muy útil... ;)
Seguramente alguna vez habréis tenido que explicar a alguien (via pidgin o teléfono) cómo hacer tal o pascual en su terminal, pegando los comandillos para que los ejecute y tal... bueno pues, como siempre, hay una forma más fácil y divertida de hacerlo.
Buenas, os traigo algo calentito y en fase de pruebas. Es una utilidad que acabo de portar y que es capaz de cifrar los elf que compilamos para que cualquier PSP los tome por archivos "oficiales". A partir de ahora podremos crear nuestros propios programas con herramientas libres y ejecutarlos en consolas con firmware oficiales o customizados. También deberían funcionar en cualquier modelo de consola. En fin, ya no necesitamos a Sony ;) .
Para firmar un EBOOT.PBP simplemente debemos hacer:
$ebootsign EBOOT.PBP EBOOT_signed.PBP
Y voilá, ahora podemos llevarnos el EBOOT_signed.PBP a cualquier PSP para probarlo.
Makefiles
Podemos añadir el siguiente target en nuestros makefiles para generar directamente los archivos firmados:
EBOOT_signed.PBP: EBOOT.PBP
ebootsign $^ $@
Y bueno, eso es todo... la aplicación está en pruebas y el código es bastante feo puesto que tiene partes de aquí y de allá. Además principalmente es un port de otra aplicación de PSP. En fin, agradecería testers, parches, críticas, etc. ;)
Hola buenas, hoy voy a hablaros sobre un tema que vengo siguiendo desde hace tiempo relativo a la libertad de los usuarios sobre los cacharros que se compran. Por poner un nombre os hablaré de Sony y de la PS3.
Imaginemos que tenemos un sistema con 20 procesadores. Nuestro linux (si, el kernel) tiene un planificador (o scheduler) muy majo que reparte todos los procesos entre los procesadores de forma que todos se queden más o menos equiparados en cuanto a carga. Ahora supongamos que algunos procesos consumen de vez en cuando mucha CPU y no queremos que esta sobrecarga afecte a algunas CPU's (vale, es un escenario muy específico, pero os aseguro que se da ;)). ¿Cómo podemos alterar esta planificación para algunos casos? pues fácil, con esta receta :).
La herramienta taskset
Este programilla en Debian lo podemos encontrar en util-linux:
#aptitude install util-linux
Y es el que nos permitirá jugar con el affinity flag
En algunos sistemas esta herramienta se encuentra en el paquete schedutils.
El affinity flag
El AF es una máscara de bits que se crea para cada nuevo proceso e indica al planificador qué procesadores pueden ejecutar dicho proceso. En esta máscara cada bit representa a un procesador, siendo el procesador #0 el bit menos significativo.
Cuando un proceso se crea, por defecto su AF es 0xFFFFFFFF. Esto significa que cuando el proceso sea desalojado de un procesador, cualquier otro procesador podrá seguir con su ejecución.
Por defecto esta solución permite al planificador del kernel seleccionar cada vez cualquier CPU para cualquier proceso.
Cualquier usuario puede obtener el AF de un proceso de una forma fácil, imaginemos que el proceso tiene como PID el 12345:
$taskset -p 12345
pid 1611's current affinity mask: 3
¡Vaya! ¡os he engañado! esto me ha dicho <3> en lugar del numerajo que os había dicho... Pues muy sencillo, en el caso del ejemplo resulta que el sistema tiene sólo 2 procesadores: esto es, los dos bits menos significativos a 1 o lo que es lo mismo, 3 en decimal. ¿Qué quiere decir esto? pues que por defecto el FA tiene a 1 todos los CPU's de nuestro sistema.
Modificar el AF
Ya sabemos como funciona por defecto el AF, ahora bien, hemos dicho que un determinado proceso no queremos que nos ocupe una determinada CPU. Lo único que debemos hacer es alterar su AF: si no queremos que pueda entrar en la CPU #0 entonces su AF debe ser 0xFFFFFFFE. Ahora supongamos que el PID de dicho proceso es 12345:
#taskset -p 0xFFFFFFFE 12345
Esta solución es válida si el proceso ya estaba en ejecución, pero si queremos lanzar uno nuevo especificando su AF:
#taskset 0xFFFFFFFE /etc/init.d/lapd start
Y si somos unos vaguetes y no queremos andar con máscaras, podemos indicar también una lista de CPU's donde puede correr nuestro proceso:
#taskset -p-c 1,2,5-8 12345
Esto hace que el proceso cuyo PID es 12345 pueda ser procesado por las CPU's #1, #2, #5, #6, #7 y #8. Si queremos lanzar un proces nuevo:
#taskset -c 0 ls
Esto hace que el comando ls sea ejecutado únicamente por la CPU #0.
Un apunte más: sólo el señor root puede establecer un FA. También lo pueden hacer usuarios con CAP_SYS_NICE activo (pero eso es harina de otro gran costal).
Hola amigüitos! si sois alegres poseedores de una PS3 con FW3.50 o anterior y tenéis a vuestra disposición algún dispositivo jailbreaker sabréis que la ejecución de programas caseros o homebrew está en vuestras manos. Pero claro, eso para está web no es nada... a nosotros nos gusta más desarrollar esos programas caseros. Existen por internet varios SDK's oficiales filtrados, pero que no debéis usar (ni, por tanto, publicar aplicaciones compiladas con esos kits). Es ilegal que los uséis porque no tenéis la licencia, así que si encontráis alguno, como material didáctico están muy bien, pero hasta ahí su utilidad práctica. En esta receta explicaremos cómo compilarnos nuestro propio kit de desarrollo legal para hacer nuestras aplicaciones caseras legales que correrán en cosolas jailbreakadas.
Qué necesitamos
Bueno, nuestra distro tiene que contar con los siguientes paquetes:
Lamentablemente puede que se me olvide alguno, si es así rogaría que me lo comentaseis.
Ahora necesitamos un sitio donde meterlo todo, es decir, /usr/local/. Ahí crearemos un directorio y le daremos permisos de escritura al grupo staff (al que perteneceremos) para no tener que hacer las cosas como root:
Vale y ahora ajustaremos las variables de entorno para que todo quede bien organizadito (estas lineas, además de ejecutarlas, añadirlas en vuestro ~/.bashrc o similar) (esto hacedlo ya como vuestro usuario):
Bien, con esto podremos compilarnos e instalar la toolchain, pero nos hará falta el SDK para poder crear nuestros ejecutables para la PS3. Le haremos sitio al SDK de la siguiente manera:
$ cd $PS3DEV
$ mkdir psl1ght
Y de la misma manera que antes, creamos la variable de entorno (meted esto también en vuestro ~/.bashrc):
$ export PSL1GHT=$PS3DEV/psl1ght
Vale, ya lo tenemos todo listo... ahora a descargar y compilar...
Compilar e instalar la toolchain
Bueno, yo tengo mi directorio ~/repos donde guardo todas estas cosas, vosotros podéis meterlo donde os plazca... si lo hacéis como yo:
Cuando esto termine: a compilar, parchear e instalar, es decir:
$ cd ps3toolchain
$ ./toolchain.sh
Y esto tardará la vidaaaa... (bueno, según vuestros sistemas...) el caso es que tiene que crear dos toolchains una para el PowerPC (conocido como PPU) y otra para los Synergistic Processors (conocidos como SPU's).
Atención: debido a que algunas URL's que utiliza el script pueden estar offline, habría que realizar los siguientes cambios en estos scripts: scripts/002-gcc-4.5.1-PPU-stage1.sh, scripts/004-gcc-4.5.1-PPU-stage2.sh, scripts/007-gcc-4.5.1-SPU-stage1.sh y scripts/009-gcc-4.5.1-SPU-stage2.sh
La línea:
$ ppu-gcc --version
ppu-gcc (GCC) 4.5.1
Copyright (C) 2010 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ spu-gcc --version
spu-gcc (GCC) 4.5.1
Copyright (C) 2010 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Compilar e instalar el SDK: PSL1GHT
Bueno, como antes, si tenéis vuestros repos en ~/repos haced lo siguiente y si no, hacedlo donde queráis:
Cuando esto termine: a compilar, parchear e instalar, es decir:
$ cd PSL1GHT
$ make
$ make install
Como su nombre indica... es ligerito así que no tardará mucho... después de esto ya estaréis en condiciones de crear vuestros programas para la PS3... peero...
Algunas librerías útiles
Si queremos instalarnos algunas librerías portadas a la PS3 como zlib, libpng, libjpeg, freetype, pixman, libogg, libvorbis, libzip o incluso cairo, haremos lo siguiente:
Ya tenemos bastantes cositas para empezar a programar un hola mundo y algo más... pero como ya os dije antes, hay muchas librerías útiles por ahí que podemos ir instalando según nuestra necesidad.
vpcomp: compilador de programas de vértices
Primero: ¿qué demonios es esto? pues más o menos lo siguiente: resulta que para mover vértices y todo ese rollo, los señores de NVIDIA han creado una especie de "máquina virtual", la cual interpreta una serie de opcodes para trabajar con datos escalares y vectoriales. En la PS3 esta máquina virtual puede interpretarse mediante una SPU, pero claro, alguien debe compilar esos programas de vértices en estos opcodes para la SPU, esto es: vpcomp
Requisitos no muy libres
Bueno, esto necesita el NVidia Cg Toolkit que es un compilador/intérprete de una especie de lenguaje ensamblador para OpenGL, podemos descargarnos gratis del NVIDIA Cg website. Descargaros el tgz de vuestra arquitectura (x86 o x86/64).
Ahora viene una cutrez: no vamos a instalar este paquete en nuestro sistema (bueno, si vosotros queréis dadle caña, lo tenéis también como paquete Debian). Como sólo necesitamos una biblioteca, vamos descomprimir el tgz y a copiar sólo lo que necesitamos en /usr/local (suponemos que estamos en el directorio donde descargamos el fichero):
La última línea refresca la caché de bibliotecas, para asegurarnos que la tenemos "disponible".
Compilar e instalar
Bien, ya podemos volver al repositorio de PSL1GHT para compilarnos el compilador...
$ cd PSL1GHT/psl1ght/tools/vpcomp
$ make
Se siente, el Makefile no tiene el target install, así que a manímetro:
$ cp vpcomp $PSL1GHT/bin/
Y ya tenemos listo nuestro compilador de vértices... ;)
Tiny3D: algo parecido al OpenGL en la PS3
Si, el RSX devora OpenGL que da gusto... pero para explotar eso (por ahora) tendríamos que echar mano del SDK oficial así que por ahora nos contentaremos con el magnífico Tiny3D de Hermes.
Requisitos
Todos los pasos anteriores, incluído el vpcomp.
Compilación e instalación
Pues nada, en nuestro directorio de repositorios:
$ git clone https://github.com/hermesEOL/tiny3d.git
$ cd tiny3d
$ make all
Si no hay ningún error, estaremos listos para usar la biblioteca. En tiny3d/docs tenéis un documentillo sobre la biblioteca y el RSX de la PS3.
ps3soundlib: audio fácil para nuestros programas
También gracias a Hermes tenemos esta biblioteca que nos permite utilizar samples de 8 y 16 bits en mono y stereo. Reproducir los samples en loop, una vez , o incluso llamando a un callback al finalizar. En fin... más cositas útiles.
Requisitos
Los pasos para obtener la toolchain y el PSL1GHT, con eso es suficiente...
Compilar e instalar
Desde nuestro directorio de repositorios:
$ git clone https://github.com/hermesEOL/ps3soundlib.git
$ cd ps3soundlib
$ make
$ make install
Al igual que antes, si no obtuvimos ningún error, ya tendremos la biblioteca lista para usar en nuestros homebrews.
Guinda: la librería SDL
Antes de que alguien se lleve a equívocos, hace tiempo que SDL fue oficialmente portado a PS3, entonces: ¿para qué todo esto?. Pues fácil, el port en realidad es para el OtherOS, es decir, algún GNU/Linux que tengáis corriendo en aquellas PS3 con un FW que disponga de esa opción. Y os permitiría crear aplicaciones para esa distribución. En cambio este port os permitirá crear aplicaciones que utilicen SDL de forma nativa en la PS3. Es decir, sin necesidad de OtherOs ni nada por el estilo: compiláis, obtenéis un PKG que podréis instalar y a funcionar... ;)
Requisitos
Los pasos para obtener la toolchain, el PSL1GHT y las ps3libraries (ya sabéis: Algunas librerías útiles).
Compilación e instalación
Como siempre, desde nuestro directorio de repositorios:
$ git clone https://github.com/cebash/SDL_PSL1GHT.git
$ cd SDL_PSL1GHT
$ ./script.sh
$ make
$ make install
Y si no tuvimos ningún error tendremos libSDL listo para usar en nuestras aplicaciones homebrew.
Y ya está... creo que con esto podremos empezar a hacer nuestras aplicaciones caseras. De todas formas existen más librerías y utilidades por ahí que según vaya probando iré añadiendo en la receta, ok?
Para terminar: Makefile
Os pongo un Makefile típico para que os cree los targets automáticos para generar los archivos PKG que contienen nuestras aplicaciones y que podremos instalar en la consola para ejecutar/distribuír nuestras creaciones.
Bueno, aquí podréis encontrar un proyecto propio en fase ultrabeta quick & dity pero que instala (probado) el toolchain, el psl1ght, las ps3libraries y la sdl_psl1ght configurando las variables de entorno y todo ese rollo. ¡Cuidado porque no comprueba que tengáis los paquetes necesarios comentados en la receta!.
Ps3sdk-Builder at github.com
Disfruten! :D
Como todos sabéis, Ana María Méndez (la dueña de Traxtore que desafió a la SGAE) ha conseguido llevar el canon y a las cinco asociaciones pro-derechos de autor a un tribunal europeo. Por ahora la cosa pinta bien ya que la abogada de dicho tribunal ha dado la razón a Ana considerando el canon incompatible con la actual normativa europea... esta afirmación no es vinculante pero suele coincidir en un 90% con el dictamen definitivo del tribunal.
Buenas... pues para aquellos que necesiten hacer un programita que mande notificaciones a alguien, puede usar alguno de los cientos de programas que existen por ahí... o puede hacer su propio notificador vía e-mail. En python es ultra sencillo y hay varios métodos, que yo conozca: conectar a un servidor SMTP, autenticarse y mandar el mensaje; o ser uno mismo el servidor y conectarse con un relay que te autorice (también soportado en python). En esta receta explicamos la primera, que es más simple (aunque también requiere tener la contraseña por algún lado, en el ejemplo la pediremos al usuario y listo...).
A cerca de Gmail
Bueno, este servidor, al igual que otros muchos por ahí, utiliza conexiones cifradas, por lo que mandar un correo nos obligará a establecer una conexión segura antes de autenticarnos (lo cual está muy requetebién y es muy sencillo).
Supongo que esta receta funcionará igual para todos aquellos servidores que requieran TLS puesto que cumple con la RFC 821 y la RFC 1869 (que alguien ponga los enlaces si quiere, yo voy con prisas :P).
Componer el mensaje
En python un mail es básicamente un diccionario cuyas keys son los nombres de los campos: Subject, Reply-To, etc... pero que además nos ofrece un par de métodos interesantes que nos permiten attach-ear imágenes y codificar todo el mensaje como mensaje MIME:
Mensaje de texto corriente y moliente
fromemail.MIMETextimportMIMETextmsg=MIMEText("Hello World,\no algo parecido...")msg['Subject']='Esto es una prueba'msg['From']="Juancar I"msg['Reply-to']="La casa ficticia"msg['To']="La Sofi"
Como dijimos antes, los campos se tratan igual que en un diccionario. Hay que tener en cuenta que no son obligatorios y que podemos falsear el origen y el destino del mismo, aunque para enviar el correo SI es necesario origen y destino reales, pero los datos que aparecerán en el correo al destinatario serán los que pongamos aquí. Tened cuidado con poner cosas demasiado "raras" o no rellenar suficientes campos porque entonces vuestro mail será considerado Spam casi con toda seguridad...
Mensaje con texto y fotos
Esto está sacado de la documentación de python y no lo he probado, pero en teoría funciona, si alguien me lo confirma pues mejor que mejor. Como dije antes, voy con prisa! :P
Aquí tenéis cómo enviar un mensaje con imágenes, podéis attachear cuantas imágenes queráis de la misma manera. Si queréis envíar sonidos o algún otro tipo de fichero, consultad la documentación de python porque se pueden componer cosas bastante chulas de forma similar (básicamente cambiar la clase MIMEImage por una más adecuada).
Conectar con el servidor SMTP
Asumimos aquí que tienes un objeto msg construído como anteriormente explicamos, pues bien, la cosa queda más o menos tal que así:
Y así de fácil es!
En este punto sabed que el origen y el destino deben ser auténticos, en caso contrario, el servidor de gmail nos dirá que hasta luego (y en el error nos da un bonito enlace con ayuda sobre su SMTP). Otra cosa más, si nuestro servidor utiliza algún tipo de certificado especial, se puede especificar en la función starttls().
Hace mucho tiempo los usuarios de madwifi contábamos con un driver maravilloso que nos permitía hacer casi cualquier cosa con nuestra tarjeta WiFi. El driver pasó al mainstream de Linux y de repente, en una aciaga versión 2.6.18 (o por ahí) el driver dejó de inyectar. Muchos pensábamos que sería cuestión de tiempo que reparasen este bug... versión tras versión no hemos podido volver a inyectar y en los foros sobre el driver nadie parece haberse dado cuenta... y eso es porque el driver internamentenunca dejó de inyectar. Esta receta explica cómo hacer que el driver funcione como antaño, cuando todos éramos felices inyectando.
El problema
Bueno, como decíamos en la introducción, el driver nunca dejó de inyectar, sin embargo, las aplicaciones que hacen uso de esta feature no funcionan o dicen que el chipset no es capaz de inyectar. ¿Cómo es esto posible?. Para responder a esta pregunta quizás primero debamos saber qué características tiene el driver y el tráfico wifi.
Estructura del driver
El driver tiene dos partes bien diferenciadas: capa MAC80211 o interfaz con el sistema operativo y capa ATH_HAL o interfaz con el hardware. Ambas capas tienen colas de envío y recepción. Los frames o paquetes recibidos por ATH_HAL son procesados y pasados a las colas de la capa MAC80211 si es necesario. Los paquetes envíados a la capa MAC80211 son tratados y depositados en las colas de la capa ATH_HAL para ser envíados por el hardware.
La inyección es tratada por la capa MAC80211, sin embargo, ATH_HAL no marca ese tráfico como lo hacía antiguamente. Éste es el motivo por el que ahora parece que no inyectamos tráfico.
Tráfico normal vs. Tráfico inyectado
Bueno, cuando nuestro driver trabaja con tráfico normal, la cola de envío en la capa MAC80211 no realiza un marcaje especial de los frames, lo que implica que todos los paquetes envíados esperarán su correspondiente ACK. La capa MAC puede configurar su cola de envío de forma que marque los frames para que no esperen respuesta. Éste método es el que se debe usar cuando la cola de envío esté en modo inyección. Y ésto es lo que actualmente se ha eliminado del driver: cuando la cola de envío está en modo inyección, los paquetes en ATH_HAL son tratados como tráfico corriente, cuando en realidad deberían marcarse como NO_ACK.
Actualmente lo que sucede es que los paquetes inyectados esperan ACK, pero jamás lo recibirán puesto que son inyectados. Por este motivo son descartados por el propio ATH_HAL. Para que sean procesados y enviados por ATH_HAL sin importar si llegan o no los ACK hay que marcar el tráfico como NO_ACK.
Dónde se marca el tráfico
Bueno, aquí depende del módulo que use nuestro chipset:
ath5k: echamos un vistazo a base.c del código fuente:
La función ath5k_txbuf_setup() configura la cola de envío (como su propio nombre indica) y, efectivamente, vemos que si la cola se configura como IEEE80211_TX_CTL_NO_ACK, añade AR5K_TXDESC_NOACK a los flags de envío. Sin embargo, no hace ningún cambio si la cola está en modo INJECTED.
ath9k: veamos el fichero xmit.c (nueva versión del ath5k con un código bastante más limpio):
staticintsetup_tx_flags(structath_softc*sc,structsk_buff*skb,structath_txq*txq){structieee80211_tx_info*tx_info=IEEE80211_SKB_CB(skb);intflags=0;flags|=ATH9K_TXDESC_CLRDMASK;/* needed for crypto errors */flags|=ATH9K_TXDESC_INTREQ;if(tx_info->flags&IEEE80211_TX_CTL_NO_ACK)flags|=ATH9K_TXDESC_NOACK;returnflags;}
Efectivamente, la función aquí es setup_tx_flags(), que retorna los flags que usará la capa ATH_HAL en su cola de envío. Al igual que antes, no hace nada especial si la cola de la capa MAC80211 se configuró como INJECTED.
Aplicar el parche (sin recompilar el Linux entero)
Ahora explicaremos como parchear el módulo en cuatro fáciles pasos, es un poco artesanal pero también más genérico (no voy a hacer parches para cada posible versión del driver :P).
Descarga del código fuente y preparación
Como ya dijeramos, los drivers madwifi pertenecen al mainstream de linux por lo que obtener los fuentes de forma separa puede no ser tan fácil como parece. En nuestro caso tenemos suerte y podemos descargar el paquete compat-wireless de Linux Wireless. Nos bajamos aquel cuya versión sea la más cercana a la de nuestro núcleo, en mi caso la 2.6.32:
Con esto habremos instalado los programas y paquetes necesarios para compilar módulos para nuestro núcleo.
Parcheado
ATENCIÓN: estas modificaciones parecen ser motivos de cuelgues en núcleos con versiones 2.6.27 y similares.
Antes disponíamos de parches oficiales de madwifi pero ahora no hay (o no los encuentro) así que a manita... según el módulo que use nuestro chipset (con lsmod podemos ver cuál es):
ath5k Modificamos la siguiente línea del fichero drivers/net/wireless/ath/ath5k/base.c:
Como véis, lo único que hacemos es añadir una condición más al if para marcar el tráfico como NO_ACK, y es que la cola esté configurada como INJECTED.
Compilación
Si todo lo anterio lo hicimos correctamente, la compilación es lo más sencillo:
ath5k:
$./scripts/driver-select ath5k
$make
ath9k:
$./scripts/driver-select ath9k
$make
Instalación
Bueno, el Makefile tiene el target install con lo que:
$sudo make install
debería funcionar a la perfección, sin embargo, yo he hecho la instalación manual que consiste básicamente (esto es para ath9k, para el módulo ath5k se hará igual... solo cambia un fichero...):
Descargar los modulos ath9k, ath, mac80211 y cfg80211 de memoria:
Terminados algunos de los juicios anti-monopolio de la innombrable (la antigua, no la nueva esa de la manzana) se han revelado algunos e-mails internos (de directivos y tal) donde Bilipuertas pide explicitamente cosas como:
Permitir que los documentos de Office se visualicen bien por los navegadores de otros es una de las cosas más destructivas que podemos hacer a la compañía. Debemos dejar de poner cualquier esfuerzo en esto y asegurarnos de que los documentos de Office dependan profundamente en las capacidades propietarias de Internet Explorer.
Cuando nos enfrentamos a un proyecto nuevo siempre debemos crear un sistema automático para compilar nuestra "obra". Este paso puede ser más o menos complejo dependiendo del tamaño de nuestro proyecto y de otros factores tales como su portabilidad, etc. Unas herramientas muy apañadas que facilitan en gran medida esto (cuando las conoces, si no se pueden volver un tanto "engorrosas") son las autotools. Y de eso va esta receta... a petición del pueblo, el tonto'las'autotools hará un pequeño programilla que será compilado con estas herramientas.
Qué son las autotools
Bueno, como dijimos en la introducción, las autotools son un conjunto de herramientas de GNU que facilitan la compilación de proyectos software en plataformas tipo Unix, MacOS-X, Cygwin e incluso Windows. Las herramientas concretamente son:
Autoconf: genera el "famoso" script configure a partir de unas macros en lenguaje M4.
Automake: a partir de unas sencillas reglas descritas en Makefile.am, genera un complejo Makefile.in con el que configure creará los Makefiles finales.
Autoheader: crea el archivo config.h.in con el que configure generará un archivo config.h que contendrá una serie de macros dependientes de la arquitectura que podremos usar en nuestro proyecto.
Libtool: si nuestro proyecto no es programa, sino una librería, estas herramientas nos facilitarán en gran medida su compilación e instalación.
Cómo trabajar con las autotools
Una vez tenemos las herramientas (los paquetes Debian/Ubuntu tienen el mismo nombre...) tenemos que usarlas, para ello primero explicaré cómo se debe hacer (o cómo lo hago yo) y luego haremos un pequeño ejemplo.
Las Autotools trabajan con una importante cantidad de scripts, macros y archivos de definiciones... sin embargo (y aquí viene lo bueno) nosotros sólo debemos crear DOS archivos. Además una herramienta nos generará automágicamente una versión inicial de uno de esos dos ficheros. Los ficheros en concreto son:
configure.ac: contiene información relativa al proyecto en general.
Makefile.am: contiene instrucciones simples sobre los componentes que forman el proyecto.
Una herramienta, llamada autoscan nos generará una versión inicial de configure.ac muy fácil de modificar y adaptar a nuestras necesidades.
La secuencia de trabajo (cuando tenga tiempo subiré un impresionante diagrama PNG) será la siguiente:
Ejecutar autoscan para obtener el configure.ac incial.
Modificar configure.ac para adaptarlo a nuestras necesidades.
Crear Makefile.am según las necesidades de nuestro proyecto.
Y ya está! a partir de ahora todos los pasos son automáticos:
Ejecutar aclocal para generar las macros M4 utilizadas en los scripts para nuestro proyecto.
Lanzar autoheader para generar el archivo config.h.in basado en nuestro configure.ac.
Ejecutar automake para generar los ficheros Makefile.in utilizados por configure para crear los Makefiles.
Finalmente lanzamos autoconf para generar el script configure.
Después de todo esto, cualquier usuario que obtenga nuestro proyecto con todos esos ficheros generados, podrá compilar e instalar nuestro proyecto simplemente haciendo:
$./configure
$make
$sudo make install
Opcionalmente (y muy recomendado) se suele incluir un script llamado autogen.sh que realiza todos los pasos automáticos hasta obtener el configure. Ese archivo puede tener el siguiente aspecto:
Sin embargo hay por ahí muchos autogen.sh mejores que hacen cosas como limpiar todos los archivos generados, etc. Algunos paquetes fuente de Debian tienen estos scripts que podéis probar.
Nuestro ejemplo
Vamos a suponer que nuestro proyecto consta de un programa fuente, llamado mir_kernel.c. Lo primero es hacer un poco de limpieza, si tenemos el directorio ~/mir con dicho fuente, crearemos el subdirectorio src y dejaremos ahí el fichero (el nombre es un simple convenio):
Tenemos dos ficheros: autoscan.log que podemos ir borrando (o cotilleando) y el configure.scan, que tiene el siguiente aspecto:
# -*- Autoconf -*-
# Process this file with autoconf to produce a configure script.
AC_PREREQ([2.64])
AC_INIT([FULL-PACKAGE-NAME], [VERSION], [BUG-REPORT-ADDRESS])
AC_CONFIG_SRCDIR([src/mir_kernel.c])
AC_CONFIG_HEADERS([config.h])
# Checks for programs.
AC_PROG_CC
# Checks for libraries.
# Checks for header files.
# Checks for typedefs, structures, and compiler characteristics.
# Checks for library functions.
AC_OUTPUT
Todo eso que vemos ahí son macros M4, en los enlaces del final podéis ver de qué va eso (aunque para usar autotools no es necesario). La primera macro obliga a que la versión de autotools necesaria para ejecutar estos scripts sea la 2.64, podemos bajarla un poco si no queremos ser demasiado restrictivos, puesto que no todo el mundo tiene porqué usar Debian Unstable :P.
La siguiente macro establece el nombre del proyecto, su versión y una dirección de e-mail a la que envíar bugs. Rellenemos los campos con la información apropiada.
Las dos macros siguientes establecen el directorio de nuestro código y cómo se debe llamar el archivo de macros C por si queremos usarlo en nuestro proyecto (por ejemplo, crea una macro con la versión que indiquemos arriba para poder usarlo en nuestro código).
El resto de macros sirve para dar instrucciones sobre dependencias exernas, por ejemplo: AC_PROG_CC indica que nuestro proyecto requiere un compilador de C. Existen muchas macros más, por ejemplo: AC_PROG_INSTALL comprueba que exista un programa que nos permita instalar nuestro proyecto en el sistema.
Además, existen otras macros útiles, por ejemplo:
AM_INIT_AUTOMAKE: indica que, como salida, autotool debe generar un Makefile. Esto será necesario en nuestro caso.
AC_CONFIG_AUX_DIR(directorio): por defecto, todos los ficheros generados por las Autotools estarán en la raíz del proyecto, con esta macro especificamos otro directorio.
AC_CONFIG_MACRO_DIR(directorio): los archivos con las descripciones de las macros M4 los alojará en este directorio.
AC_CONFIG_FILES([Makefile src/Makefile]): indica los archivos de salida que creará Autotools.
Existen más macros muy útiles, echad un vistazo al manual si queréis más información. Nosotros modificaremos nuestro configure.scan de la siguiente manera:
# -*- Autoconf -*-
# Process this file with autoconf to produce a configure script.
AC_PREREQ([2.64])
AC_INIT([MIR Kernel], [2.0], [billgates@vigilando.org])
AC_CONFIG_AUX_DIR([config])
AC_CONFIG_MACRO_DIR([m4])
AM_INIT_AUTOMAKE
AC_CONFIG_SRCDIR([src/mir_kernel.c])
AC_CONFIG_HEADERS([config.h])
# Checks for programs.
AC_PROG_CC
AC_PROG_INSTALL
# Checks for libraries.
AC_CHECK_LIB([bluetooth])
# Checks for header files.
# Checks for typedefs, structures, and compiler characteristics.
# Checks for library functions.
AC_CONFIG_FILES([Makefile src/Makefile])
AC_OUTPUT
Y este archivo será nuestro configure.ac:
tobias@nasa:~/mir$mv configure.scan configure.ac
Nótese que en el archivo añadimos una linea:
AC_CHECK_LIB([bluetooth])
Ahí podemos indicar una serie de librerías con que debe contar nuestro sistema para poder compilar y ejecutar nuestro proyecto.
Ahora escribimos nuestro Makefile.am, uno por cada subdirectorio de nuestro proyecto. Primero el del directorio padre:
SUBDIRS=src
Sólo tenemos que indicar dónde hay subdirectorios con otros Makefile.am. Ahora el del del directorio hijo:
Directorio donde el programa mir se instalará. El nombre de la variable es importante, si definimos la variable pruebaprgdir, automake buscará la variable pruebaprg_PROGRAMS.
De qué programas consta el proyecto. La siguiente variable establece una lista de ejecutables que hay que crear en el proyecto. Por cada programa que especifiquemos, automake buscará una variable con nombre programa_SOURCES.
Qué archivos fuentes son necesarios para compilar un programa. La última variable contendrá una lista de archivos fuente necesarios para crear nuestro ejecutable.
Opcionalmente podemos especificar librerías externas que necesite nuestro programa (en nuestro configure.ac deberíamos haber comprobado que existan) :
mir_LIBADD=-lbluetooth
También podremos indicar opciones de linkado y compilación adicionales para cada programa mediante las variables mir_LDFLAGS y mir_CFLAGS.
En este punto, si trabajamos con repositorios, podemos subir todos los archivos que tenemos en ~/mir puesto que son los mínimos, a partir de los cuales se generarán los demás (y que por tanto no son necesarios en el repositorio). Ahora, para preparar nuestro proyecto para distribuir, ejecutamos lo siguiente:
tobias@nasa:~/mir$mkdir config
tobias@nasa:~/mir$aclocal
tobias@nasa:~/mir$autoheader
tobias@nasa:~/mir$automake -acconfigure.ac:8: installing `config/install-sh'
configure.ac:8: installing `config/missing'
src/Makefile.am: installing `config/depcomp'
Makefile.am: installing `./INSTALL'
Makefile.am: required file `./NEWS' not found
Makefile.am: required file `./README' not found
Makefile.am: required file `./AUTHORS' not found
Makefile.am: required file `./ChangeLog' not found
Makefile.am: installing `./COPYING' using GNU General Public License v3 file
Makefile.am: Consider adding the COPYING file to the version control system
Makefile.am: for your code, to avoid questions about which license your project uses.
¡Hemos obtenido un error! ¿Qué ha pasado? :O
Pues fácil, existen una serie de ficheros de texto, en plan README que deberían acompañar todos los proyectos, estos archivos tendremos que crearlos "a mano", podéis echar un vistazo a algunos de los que incluyen los paquetes fuente de Debian para que os hagáis una idea del formato y contenido. Podéis crear archivos vacíos si queréis aunque es aconsejable seguir las mismas pautas que todo el mundo sigue... Además, automake tiene una serie de plantillas para algunos de ellos, como por ejemplo para COPYING usa la GPLv3 por defecto. Una vez que los hayáis creado:
Y ese directorio, tal cual, está listo para ser distribuído por Internet, todo el mundo podrá compilar e instalar tu proyecto con las instrucciones de siempre:
tobias@nasa:~/mir$./configure
tobias@nasa:~/mir$make
tobias@nasa:~/mir$sudo make install
Conclusiones
Quizás os haya podido parecer un poco enrevesado, pero haced vosotros el ejemplo, veréis que todo esto se resume en modificar el fichero configure.ac y crear los archivos Makefile.am que son muy simples. Acto seguido ejecutamos las Autotools (buscad un autogen.sh que están más chulos) y listo. Muy sencillo. :P
Supongamos que quisierais ver a vista de pájaro todos vuestros ficheros. Navegar, copiar, renombrar y borrar ficheros tan sólo con volar entre ellos... ¿no me explico bien?... bueno, una imagen vale más que mil palabras así que no os perdáis el vídeo y si os gusta, seguid leyendo...
Para los que pasamos muchas horas delante del ordenador, puede ser interesante que éste se comporte como nuestro teléfono móvil sin necesidad de apartar nuestra atención del equipo. Para ello tenemos que hacer que nuestro dispositivo bluetooth implemente el HFP Profile. De eso va esta receta.
Ingredientes
Primero instalamos los paquetes necesarios para que nos funcione el invento (apt-get o aptitude al gusto):
$svn co https://nohands.svn.sourceforge.net/svnroot/nohands/trunk nohands
Compilación e instalación
Primero compilamos todo...
$cd nohands
$./autogen.sh
$./configure && make
$sudo make install
Pseudo BUG:Si tenemos libbluetooth1-dev, dará un error de compilación en el archivo nohands/libhfp/bf.cpp. Esto se debe a que la línea 81 dice lo siguiente:
attr2 = SDP_ATTR_SUPPORTED_FEATURES;
Y habría que poner lo siguiente:
attr2 = SDP_SUPPORTED_FEATURES;
Podéis cambiarlo y ya os compilará sin problemas... de todas formas es mejor usar libbluetooth2-dev (o lo que es lo mismo, libbluetooth-dev)
Probando... 1, 2, 3...
Algo que faltaría en Ingredientes es algo evidente: tarjeta de sonido funcionando y opcionalmente un micrófono y un altavoz. Conectamos todo eso al equipo, con la mezcladora ajustamos los valores de captura de micrófono y reproducción PCM y lanzamos el programa:
$hfconsole
Nos aparecerá lo siguiente:
Imagen increíblemente realista de cómo se vería la aplicación recién instaladita.
Para buscar nuestro teléfono pulsamos en "Search for Device...", entonces aparecerá lo siguiente:
Otra imagen realmente impresionante de la aplicación buscando dispositivos bluetooth.
No os preocupéis si no sabéis la dirección mac de vuestro teléfono porque se irán resolviendo los nombres poco a poco. Cuando lo tengáis, lo marcáis y pulsáis "Añadir". Si tenéis varios los podéis añadir también, pero recordad que una limitación de Bluetooth es que sólo se puede mantener una conexión SCO a la vez, esto quiere decir que aunque el programa atienda a varios móviles, únicamente uno podrá hacer streaming del audio a la vez. Cuando hayamos cerrado la ventana de búsqueda de dispositivos, el programa se conectará con el móvil y tomará este aspecto:
La última imagen, y no por ello menos impresionante, de la aplicación haciendo uso del móvil que hayamos elegido...
...¡y ya tenéis control sobre el móvil!
Un único detalle más: por defecto se usa la tarjeta de sonido seleccionada como default en ALSA, podéis elegir la tarjeta de entrada y de salida en las preferencias del programa, en el recuadro "Device / Options" podéis escribir lo siguiente, por ejemplo:
in=hw:2,1&out=hw:3,0
Esto haría que se capturase del canal 1 de la tarjeta de sonido 2, enviando ese audio al móvil y que el canal 0 de la tarjeta 3 reprodujese lo que el móvil esté recibiendo.
Llevaba ya mucho tiempo sin escribir por aquí algo... y para desengrasarme un poco voy con una recetilla muy simple pero que puede ser de mucha utilidad: supongamos que entras en una página que reproduce audio mediante streaming y que quieres capturar ese audio. Si abres un programa de captura comprobarás que no se captura ese sonido... necesitamos algún tipo de tarjeta "virtual" que nos permita capturar lo que reproduce, esto es: audio loopback.
Instalando (quick'n'dirty)
Los señores de ALSA crearon hace tiempo un modulito que permitía justamente esto, el aloop, pero lamentáblemente no se compila por defecto, esto hace que distribuciones como Debian no lo traigan de serie, por tanto, nuestro primer paso es compilar el modulito.
Empezamos descargándonos el archivo alsa-drivers de ALSA FTP (el link es FTP pero el drupal lo cambia a HTTP porque es muy listo). Lo suyo sería que fuese el de la misma versión que tengamos en nuestro sistema. Si no sabéis qué versión usáis, ejecutad lo siguiente:
$cat /proc/asound/version
Advanced Linux Sound Architecture Driver Version 1.0.16.
De todas formas, yo tengo la versión 1.0.16 y me he instalado el módulo en su versión 1.0.17 (porque era la que tenía a mano) y no he tenido warnings ni nada por el estilo...
Una vez descargado, descomprimimos y compilamos:
Ahora podríamos hacer un make install pero yo no lo hago por una sencilla razón: instala más módulos de los estrictamente necesarios. Para no "tocar" más de lo necesario hago lo siguiente (como root):
Ahora configuramos la tarjeta (realmente este paso no es necesario para ciertas aplicaciones: las que usen alsa-lib, pero nunca está de más), para ello debemos saber qué tarjetas tenemos funcionando (esto ya lo podemos hacer como usuario):
$cat /proc/asound/cards
0 [A5451 ]: ALI5451 - ALI 5451
ALI 5451 at 0x8400, irq 9
1 [pcsp ]: PC-Speaker - pcsp
Internal PC-Speaker at port 0x61
2 [Loopback ]: Loopback - Loopback
Loopback 1
Como podemos ver, la tarjeta virtual Loopback es la 2, esto nos permite escribir lo siguiente en el archivo ~/.asoundrc (si no existe lo creáis) y añadimos lo siguiente:
pcm.aloop {
type hw
card 2
}
ctl.aloop {
type hw
card 2
}
Con esto ya tenemos listos dos canales PCM, que en este caso serían (en nomenclatura ALSA): hw2,0 y hw2,1. Lo que reproduzcamos por uno de ellos, lo podremos capturar por el otro, lo único que hay que tener en cuenta es que el formato de captura debe coincidir con el del audio que se está reproduciendo.
Si queréis un ejemplo podéis hacer lo siguiente: capturamos uno de los extremos del loopback:
$arecord -D hw:2,1 -c 2 test.wav
Y ahora podemos reproducir cualquier archivo (en estéreo, puesto que estamos capturando 2 canales), seleccionando dispositivo de reproducción hw:2,0:
$aplay -D hw:2,0 music.wav
Y ya está.... así de fácil! :)
Rizando el rizo: múltiples tarjetas loopbacks
Bien, ya sabemos crear una tarjeta virtual con sus 8 subcanales PCM listos (si, no lo he comentado antes, pero mezcla hasta 8 canales), pero... ¿qué pasa si queremos más de una tarjeta loopback?. La solución es fácil: al cargar el módulo podemos especificar cuántas tarjetas virtuales queremos (hasta un máximo de ocho):
En el ejemplo anterior primero descargamos el módulo y después lo volvemos a cargar de la siguiente manera:
index: índices de las nuevas tarjetas a crear, esto es: las tarjetas loopback serán hw:2.x y hw:3.x.
enable: tarjetas virtuales a habilitar. Un 0 la deja deshabilitada y un 1 la activa (realmente no se para que sirve esto ya que no entiendo porqué alguien va a crear una tarjeta virtual que no pueda usar. Simplemente poned tantos unos como tarjetas vayáis a añadir).
pcm_substreams: número de subcanales que tendrá cada tarjeta virtual. En este caso serán 4 subcanales por tarjeta.
Enlaces
Aunque está un poco anticuada... la página de aloop module puede ser útil...
Resulta que ahora en veranito muchos de vosotros habréis viajado a algún sitio y puede que (como frikis/hackers que somos) llevéis vuestra Debian en la mochila. Si esto es así y habéis cambiado de uso horario, tendréis que cambiar la hora de vuestro equipo... ¿es necesario esto?... pues claro que no!
El problema
Cuando instalamos nuestro sistema, en uno de los primeros pasos, elegimos nuestro país, en ese paso se configura nuestro timezone, que es un servicio que permite compensar la hora de nuestro sistema con la hora local donde se ubica el mismo. No se si soy muy torpe o no he mirado bien o qué, el caso es que no he encontrado ninguna utilidad que permita cambiarlo así pues vamos a explicar como cambiarlo, es muy sencillo.
Configuración del timezone
La configuración de esto se encuentra en un extraño archivo ubicado en /etc/localtime (digo extraño porque no es texto plano). Así pues lo que tenemos que hacer es cambiar ese archivo por otro...
#mv /etc/localtime /etc/localtime.old
Y ahora... ¿qué ponemos en su lugar? pues fácil... en /usr/share/zoneinfo tenemos un montón de archivos, sólo hay que elegir uno...
Hola majetes! quizá alguna vez hayáis intentado descargar una página completa con wget -r y sin ningún motivo aparente se ha negado a llevar a cabo tal tarea... quizás podáis con este cutre truco
Hola buenas! Pues nada, esta receta formará parte (espero) de una mayor que explicará como instalar una red VPN entre oficinas a través de Internet. Para llevar a cabo esto hay que empezar pasito a pasito, el primer paso será el siguiente: configurar la red local de cada oficina.
Hola! supongo que ya os habréis enterado del DSA-1571 (aviso de seguridad de Debian), que viene a ser esto: el generador de números aleatorios de openssl que se emplea para generar las claves privadas y públicas de SSH es predecible, lo cual es un grave problema porque ahora, conocida una cable pública, se puede obtener su clave privada. Esto hace que desde el 17 de septiembre de 2006 las claves generadas con Debian (y similares) sean inseguras. Así que ya sabéis: revocad vuestras antiguas claves y generaros unas nuevas!.
Aquí tenéis el material para el taller de videojuegos, aunque el material está disponible en repositorio con sus distintas trunks, para facilitar el uso y la comprensión, se han creado el “juego final” en 16 pasos.
Pues nada, esta receta en verdad no sirve para mucho, pero como últimamente no hago otra cosa y siempre me equivoco en algo al montar… pues lo escribo para no confundirme nunca más… :P
Consejos
Para poder desmontar la consola hará falta un juego de destornilladores de precisión, sobre todo de estrella (alguno plano vendrá muy bien). También puede ser útil contar con unos alicates de punta fina y una gamuza (como las de las gafas).
Aunque todo esto es alta tecnología y se supone que es muy delicado y tal y pascual… en verdad es muy sencillo, y con un poquito de cuidado y paciencia no tendremos problemas.
¡Ah! una cosa más… con esto se pierde la garantía porque hay que romper la pegatina que hay debajo de la batería…
Desmontar
Pues para montar primero habrá que desmontar… vamos con ello… quitamos la batería, la memory stick y el umd si lo tuviera.
Carcasa frontal
Con la consola apagada, le damos la vuelta y quitamos los siguientes tornillos (círculos rojos):
Una vez retirados los tornillos (en algún lugar seguro) damos la vuelta a la consola y retiramos la carcasa frontal:
TFT
Ahora vamos a quitar el TFT, para ello nos vendrá bien el destornillador plano, ya que la pantalla no va montada con tornillos, sino que va encajada con cuatro pestañas a un soporte metálico. Primero quitamos la barra de botones frontal (que va con otras pestañas). La forma de desencajar estas piezas es haciendo palanca suavemente con el destornillador plano, encajándole entre el soporte y la pieza móvil. Una vez desencajas las pestañas la cosa quedará parecido a:
Para retirar la barra de botones completamente habrá que levantar la pequeña pestaña del conector (otra vez el destornillador plano) y retirar la faja (chistes a parte). Para retirar la pantalla completamente (cuidado con plantar los dedos) retiraremos las dos fajas: la de alimentación (la delgada) y la de datos (la ancha). Lo haremos de la misma forma que lo hiciéramos para los botones frontales. En la imagen se marcan los conectores así como los tornillos que retiraremos para quitar el soporte del TFT (siguiente paso):
Una vez quitados los tornillos del soporte, debemos abrir la tapa del lector de umd para poder retirarlo, ya que la mecánica de cierre está en el mismo soporte. Cuando retiréis el soporte debéis tener cuidado con el resto del proceso puesto que la óptica de la lente del umd queda expuesta… ¡no la toquéis con los dedos ni la arañéis ni nada!.
Placa base
Una vez retirado el soporte del TFT tendremos lo siguiente:
Vamos a retirar los pulsadores de la cruceta y los controles. La cruceta tiene un tornillo (marcado con el círculo) y la placa de los controles dos pestañas (también marcadas), haciendo palanca con el destornillador plano saldrá fácilmente. Para retirar las dos piezas, levantamos las pestañas de los conectores de las dos fajas y las desconectamos. Una vez sacadas las piezas tendremos esto:
Debemos desconectar los últimos cables que van a la placa. En la parte inferior tenemos los cables de los altavoces, el izquierdo tiene una pequeña tira adhesiva que debemos despegar primero (con levantar un lado para soltar el cable es suficiente, así podremos volver a cerrarlo). En la parte inferior también está la faja que controla el motor del umd, que también debemos retirar. En la parte superior derecha tenemos el conector de voltaje (el blanco) que también hay que desconectar. El cable del conector está sujeto con otra tira adhesiva al plástico que forma la antena wifi, hay que soltarlo para poder desencajar la antena, ya que el cable que va desde la tarjeta wifi hasta la antena está atrapando la placa entera; ese mismo cable está fijado con otra tira a la placa, hay que soltarlo también. Por último soltamos el cable de la lente del umd y tendremos la máquina así:
Ahora sólo tenemos que desatornillar el tornillo marcado y ya podremos extraer la placa. A la hora de extraerla tened cuidado porque en la parte izquierda hay un conector vertical por la parte trasera de la placa, por tanto estará un poco más duro. Yo suelo hacer palanca suavemente para extraer la placa de ese lado.
Wifi y Memory Stick
Extrayendo la placa ya sólo nos quedará lo siguiente:
Extrayendo los tornillos marcados podremos retirar una pieza de plástico que afianza la placa metálica que protege la placa wifi:
Extrayendo el tornillo marcado podremos retirar la placa metálica:
Ahora ya podemos retirar la placa wifi. Dicha placa está fijada con unas guías de plástico de la carcasa (marcadas en rojo). La placa wifi tiene además el zócalo para la memory stick (como se ve en la figura). Retirando la placa hija nos quedaremos con lo siguiente:
Que es la carcasa inferior y el lector de umd, si queremos retirar el lector debemos quitar los tornillos marcados. La cabeza de estos tornillos está por el otro lado, para acceder a ellos hay que desencajar la tapa trasera. Aquí debéis tener cuidado porque es fácil romper alguna pestaña.
Montar
Pues si esperábais que hiciese la gracia de decir: leed la receta al revés, habéis acertado… mirad las fotos de abajo arriba y ya está. Si alguno tiene dudas, que lo diga y lo completo… :P
Sólo diré una cosa: una vez puesta la pantalla, antes de poner la carcasa frontal, limpiad con una gamuza la superficie de la misma porque seguro que habrá cogido polvo. De la misma forma limpiad la parte interna de la carcasa frontal. Si no lo hacéis, cuando encendáis la consola, seguramente tendréis molestas motas de polvo y partículas dentro de la consola y es como tener píxeles muertos.
Enlaces
La verdad que esto no lo he buscado en ningún sitio… pero en youtube tendréis vídeos sobre como desmontar y montar la consola… también pueden serviros de ayuda.
Ahora a ver si alguien con una NDS nos enseña a destriparla… :P
Tengo el gusto de informaros de la celebración de la próxima Install Party de CRySoL que se celebrará en la Escuela Superior de Informática los días 22 y 23 (viernes y sábado).
Dado que la PSP evoluciona, lo hace también la scene (normalmente más rápido :P), lo que provoca cambios en el pspsdk que debemos adoptar lo antes posible para no quedarnos obsoletos. En este caso vamos a hacer compatibles nuestros programas al modelo slim de PSP y a las PSP clásicas con firmwares actuales (versiones 3.XX y posteriores). Es indispensable leer y entender la receta “Aplicaciones portables entre PSP y GNU/Linux con SDL”.
Introducción
Hasta ahora, cuando desarrollábamos software para nuestras portátiles, no teníamos ningún tipo de limitación: toda la máquina era para nosotros. Esto era debido a que las aplicaciones se podían ejecutar como kernel thread, es decir: con todos los privilegios. A partir del firmware 2.71 esto no es posible, y si nuestros ejecutables se configuran como kernel thread, obtendremos un bonito “No se pudo iniciar el juego” cuando intentemos ejecutarlo. Igualmente obtendremos un error si, aún siendo user thread, hacemos llamadas a objetos del espacio del kernel.
Configurar el programa como user thread
Como ya explicamos en anteriores recetas, el modo del hilo viene configurado por:
PSP_MODULE_INFO(“module_name”, 0, 1, 1);
Aquí viene el primer cambio, a partir de ahora lo configuraremos como:
PSP_MODULE_INFO(“module_name”, 0, 1, 0);
Ahora tenemos el siguiente problema: en este modo de ejecución, se asignan 64Kb de memoria para el heap de nuestras aplicaciones, por tanto se recomienda allocatar una buena cantidad de memoria al principio del programa, esto se consigue con:
PSP_HEAP_SIZE_KB(20480);
Con esto ya tenemos el código listo, ahora a compilar… ;)
Cambios en el Makefile
Afortunadamente no hay mucho que cambiar, sólo que no podemos genera un archivo elf sino que ahora hemos de crear un prx, además también hay que indicar que queremos crear un archivo para firmware 3.71 o superior, todo se consigue símplemente con:
En realidad basta con añadir las dos primeras lineas a nuestros makefiles… ;)
Apéndice A: adaptando aplicaciones con SDL
Ya hablamos en recetas anteriores sobre SDL, ahora vamos a hablar un poco de sus “tripas”. SDL tiene un componente llamado SDLmain que se incluye automáticamente en los programas que usan esta librería. Ese componente permite abstraer algunos detalles de las arquitecturas, por ejemplo, en las aplicaciones para PSP nos ahorra tener que definir nuestro PSP_MODULE_INFO porque SDLmain tiene su propia definición. Al igual que instala sus propios manejadores para el callback de terminación. Esto antes nos suponía una comodidad y una ventaja, sin embargo ahora, nos viene un poco mal debido a que SDLmain asume que nuestro programa se va a ejecutar como kernel thread y no es cierto.
Afortunadamente no hay que tocar mucho código, excepto incluír todo aquello que SDLmain hacía automáticamente:
PSP_MODULE_INFO
ExitThread y ExitCallback
Ahora debemos modificar los makefiles, dado que los CFLAGS y los LIBS (parámetros al linkador) los establecemos haciendo uso de sdl-config que tenemos en nuestro pspsdk, es decir:
Alguna vez puede darse el caso de que necesitemos proyectar una película o jugar a algunos juegos en un monitor secundario (o proyector) que conectemos a un portátil. Puede haberos pasado (como a mi) que la ventana en el monitor secundario aparezca en negro. Veremos como solucionar el problema en esta micro-receta.
Hola... hoy me he encontrado por ahí una entrevista muy interesante sobre una buena mujer, Ana María Méndez, que por lo visto tenía una tiendecilla de informática y la SGAE la tomó con ella (como con muchas otras). La mujer decidió plantar cara y acabó fundando APEMIT. La entrevista es un poco larga pero tiene cosas muy muy interesantes, de las cuales sólo pondré lo siguiente (que curiosamente no tiene que ver con la SGAE):
Supongo que muchos de vosotros conoceréis libparted, la librería que hay debajo de los programas de particionado típicos de GNU. Muchos de vosotros conocéis también Python, si juntamos estas dos cosas tenemos que hacer programitas que manejen el particionado del disco va a estar al alcance de cualquiera. Llegados a este punto, no sobra decir que: NO me responsabilizo de los daños que pueda causar el uso de esta receta, yo lo he probado con un disco flash y me ha funcionado sin problemas. Quien quiera garantías... que las pague :P.
Leemos en engadget que el nuevo sistema antipiratería del Vista SP1 NO va a inutilizar las copias piratas que detecte, en lugar de eso sólo mostrará mensajes una y otra vez por pantalla dando el coñazo. Por lo visto que el motivo es que "han tomado esta decisión tomando en consideración las opiniones de los usuarios" según Alex Kochis, jefe del producto WGA (protección anti-piratería)... o lo que viene a ser lo mismo: los usuarios de Windows Vista son unos piratas.
Probablemente muchos de vosotros tengáis equipos con varias tarjetas de red, esto puede usarse para muchas cosas, una de ellas (a mi entender muy interesante) es el port trunking o también conocido como port bonding.
¿Qué es el port bonding?
Es una técnica que permite agregar varios interfaces de red físicos en uno único virtual. A cada interfaz físico se le denominará slave (esclavo). Con esto podemos realizar un balanceo de carga entre las dos interfaces y conseguir un ancho de banda final igual a la suma de los anchos de banda de cada slave. Además de una ventaja adicional inmediata: redundancia de la conexión. Tenemos varios enlaces físicos a la red, perder alguno de ellos implica una degradación de servicio pero no la pérdida completa de conexión.
Ingredientes
Es necesario un módulo que viene de serie incluído en los linux 2.4 y 2.6. Además también hace falta el programa que gestiona las interfaces: ifenslave, que viene empaquetado en Debian para disfrute de todos nosotros:
#aptitude install ifenslave-2.6
El módulo bonding
Para crear la interfaz virtual debemos cargar un módulo que la gestione aplicando alguna política o algoritmo para ello. Este módulo tiene muchos parámetros, aunque creo que antes de listarlos todos explicaremos un poco el funcionamiento teórico para entender mejor los parámetros.
Slaves y colas
Toda interfaz de red tiene asignada automáticamente una cola de envío y otra de recepción. Cada slave tiene también sus propias colas. El esquema es más o menos el siguiente (supondremos dos slaves):
RED ----> ETH0(RX) --->\
BOND0(RX) ----> S.O.
RED ----> ETH1(RX) --->/
/----> ETH0(TX) ----> RED
S.O. ----> BOND0(TX)
\----> ETH1(TX) ----> RED
(Ole ese ASCII ART!)
En cuanto a la recepción hay poco que decir, cuando llega un paquete
a algún slave se pasa a la cola de recepción de la interfaz virtual. Si un enlace físico falla, hay poco que podamos hacer: símplemente se degradará el servicio. Pero para el envío hay un poco más de historia, puesto que si detectamos que un enlace se ha perdido, deberemos pasar todos los paquetes de la cola de esa interfaz a la esclava que sigue funcionando para después congelar esa cola de envío degradando así el rendimiento de la interfaz. Por tanto debemos poder detectar cuando un enlace se ha caído, a este respecto existen dos posibilidades: detección por ARP o mediante MII (Media Indepent Interface).
Detección ARP: consiste en enviar periódicamente peticiones ARP por un slave, si estas peticiones fallan el enlace se considera caído.
Detección MII: si el módulo de la NIC (Network Interface Card) implementa ciertas llamadas, se puede detectar cuando un enlace está físicamente caído, en cuyo caso, se deshabilita el slave.
Evidentemente, los esclavos deshabilitados se seguirán probando hasta que vuelvan a estar operativos, momento en el cual se volverán a habilitar dentro de la interfaz virtual.
Balanceos de carga
Probablemente este sea el aspecto más importante del bonding: cómo balancear la carga entre todos los esclavos. En este sentido el módulo tiene un parámetro que permite indicar qué algoritmo se debe usar, los algoritmos implementados son:
balance-rr (modo 0): se emplea un algoritmo round robin entre la cola virtual y las de los esclavos. Es algo así como: un paquetillo para un esclavo, otro para otro esclavo, un paquetillo para un esclavo, otro para el otro... etc. Es el algoritmo que se usa por defecto.
active-backup (modo 1): realmente no balancea la carga, usa sólo un esclavo y en caso de fallar, usa el siguiente disponible.
balance-xor (modo 2): emplea una formulita para decidir por qué interfaz sale: (source-MAC xor dest-MAC) mod n-slaves.
broadcast (modo 3): se transmite todo por todas las interfaces. Este método no balancea tampoco, pero provee tolerancia a fallos.
802.3ad (modo 4): emplea algoritmos definidos en el estándar IEEE 802.3ad.
balance-tlb (modo 5): balancea la carga de transmisión entre los esclavos dependiendo de la velocidad de estos y de la carga total. El tráfico es recibido por un esclavo, en caso de fallar otro esclavo toma su MAC y continúa recibiendo tráfico.
balance-alb (modo 6): realiza el balanceo anterior además de un balanceo también en la recepción. Este método debe modificar las MAC de los esclavos estando las tarjetas activas, esto debe estar soportado por el driver para poder usar este método.
Aunque todo esto parezca muy bonito, hay que tener en cuenta una cosa: algunos métodos necesitan ciertas configuraciones/capacidades en el switch al que estés conectados los esclavos. Ah! se me olvidaba: si el switch tiene un único link de salida a la red y va a la misma velocidad que nuestros esclavos, el balanceo se hace inútil ya que se produce un cuello de botella en el link de salida del switch.
Ahora si: carga y configuración del módulo bonding
Cargaremos el módulo como de costumbre:
#modprobe bonding [parámetros]
Y los parámetros los tenemos a continuación:
arp_interval: si se especifica (por defecto es 0, desactivado) indica cada cuántos milisegundos se enviará un ARP reply. Este tipo de detección es compatible con las políticas 0 y 2.
arp_ip_target: indica cuál será la IP destino. Se pueden especificar varias separadas por comas (como máximo 16).
downdelay: especifica cuántos milisegundos se tardará en desactivar un esclavo cuando se detecte un error en el enlace. Por defecto es 0 (inmediatamente) y sólo se emplea en la detección mediante MII.
lacp_rate: en el modo 802.3ad especifica cada cuánto se va a envíar un mensaje LACDPU. Estos paquetes se encargan de controlar el protocolo de agregación de enlaces. Este parámetro tiene dos posibles valores: slow o 0 (por defecto) y fast o 1.
max_bonds: indica cuántas interfaces virtuales creará como máximo esta instancia del módulo. Por defecto vale 1 (sólo bond0).
miimon: si especificamos un valor distinto de 0 (por defecto) activa la detección por MII, indica cada cuántos milisegundos se va a comprobar el estado del enlace. Un buen valor puede ser 100.
mode: indica que algoritmo de balanceo se va a usar, sus posibles valores se indicaron en el apartado anterior.
primary: este parámetro sólo se usa si se activa el modo 1, y se usa para indicar cuál esclavo es el primario.
updelay: especifica cuánto tiempo en milisegundos se tardará en activar un esclavo cuando se detecta un enlace repuesto. Por defecto vale 0.
use_carrier: por defecto vale 1, lo cual indica que se usará una llamada a netif_carrier_ok() del módulo de la NIC para la detección por MII. Si vale 0 se usarán llamadas ETHTOOL ioctl's, lo cual está deprecated.
xmit_hash_policy: especifica la política de transmisión para los modos 2 y 4. Los posibles valores son:
layer2: se usa la fórmula que se indicó en el modo 2 (apartado anterior). Este algoritmo hace que el tráfico con un mismo destino "salga" siempre por la misma interfaz. Es la política usada por defecto.
layer3+4: con esta política se usará información de niveles superiores al de enlace (realiza XOR's también con las IP's) y no tiene el mismo comportamiento según la clase de tráfico transportado. Es un buen algoritmo pero no es 100% compatible con IEEE 802.3ad.
Con tantos parámetros podremos probar muchas opciones, yo actualmente uso:
#modprobe bonding miimon=100 mode=balance-tlb
Con esto ya tenemos el módulo cargado, sólo nos falta configurar la interfaz y añadir esclavos.
Configurar interfaz bond
Si véis how-to's por internet veréis que montan un "pitoste" de parámetros en ficheros, etc. Pero es porque usan SuSE y cosas de esas raras, encima para tener IP estática. Pues en Debian abrimos /etc/networking/interfaces y añadimos:
iface bond0 inet dhcp
slaves eth0 eth1
Tened en cuenta que eth0 y eth1 no deben estar activos en ese momento (deben estar down). Y finalmente para activar la interfaz:
#ifup bond0
Y ale... a disfrutar... ;)
Apéndice A: Configuración del switch
Los modos active-backup, balance-tlb y balance-alb no requiere ninguna configuración especial en el switch, ideales si no tenemos acceso a la configuración del equipamiento de red ;-).
El modo 802.3ad requiere que el switch tenga los puertos donde conectamos los esclavos en modo 802.3ad aggregation. Esto depende de cada switch, por ejemplo, en los switch's de Cisco esta capacidad se llama EtherChannel y debe estar en modo lacp.
Por último, los modos balance-rr, balance-xor y broadcast generalmente requiere poder agrupar puertos. Las nomenclaturas de estos grupos dependen del fabricante del switch, como hemos dicho antes, Cisco llama a estas agrupaciones EtherChannel, también se usa trunk group, etc.
Enlaces de interés
Pues hay mucho por internet, pero lo mejor es la documentación del propio módulo:
Linux Ethernet Bondign Driver HOW-TO.
Si probáis la receta, podéis envíar vuestras configuraciones (tanto del switch si la conocéis y de vuestro bond para hacer comparativas de rendimientos y todo eso. :-)
Buenas... los debianitas habrán notado como hace algún tiempo que el maravilloso y útil "Menú Debian" ha desaparecido, no se porqué... pero si cómo hacerlo volver.... :D
Aquí estamos de nuevo para dar un poco de caña a nuestras PSP's, ya sabemos cómo desarrollar aplicaciones multimedia para la consola, ahora vamos a dar dos pasos más: las aplicaciones usarán SDL y serán portables entre nuestro GNU/Linux y nuestra PSP.
El desarrollo de Hurd continúa avanzando... lentamente... aún así ya empieza a ser usable por intrépidos usuarios como nosotros que deseamos aprender más y más. Por eso me he decidido a intentar crear una serie de recetas sobre Hurd. La primera de ellas es ésta: probar hurd en una máquina virtual.
¿Qué es GNU/Hurd?
Desde sus inicios, el objetivo del proyecto GNU ha sido crear un sistema operativo completo y libre. En sus inicios el proyecto contaba con diversas herramientas de desarrollo, aplicaciones de sistema, etc. Pero carecían de un elemento bastante importante: un kernel que ejecutase todo eso. Decidieron crear uno: Hurd, pero lamentáblemente eso es un proceso lento y costoso; por ello decidieron adoptar temporalmente el conocido kernel linux.
Actualmente HURD no es usable en entornos de producción pero se encuentra activamente en desarrollo.
Arquitectura Hurd
Como todos sabéis, linux es un núcleo monolítico, como lo era el MS-DOS. Esto significa que todos los componentes del sistema operativo funcionan como un gran programa, esta concepción está ya muy obsoleta (o así debería ser) y actualmente se opta por crear sistemas con sus componentes bien diferenciados e independientes colaborando unos con otros. Esto es hurd: una colección de servidores en la que cada uno implementa el sistema de archivos, la red, etc. Todos estos servidores no pueden ejecutarse ellos sólos, necesitan de un microkernel que gestione el paso de mensajes, la sincronización, etc. entre ellos; este programa es el GNU Mach.
En nuestros sistemas GNU/Linux convencionales tenemos la máquina, sobre ella el linux y sobre éste las aplicaciones. Ahora, en un sistema GNU/Hurd (llamado símplemente: sistema GNU :D) tendremos la máquina, sobre ésta gnumach y hurd y las aplicaciones de usuario que realizaran las llamadas a los servidores de hurd.
En parte, la lentitud del desarrollo de hurd se debe a que éste modelo de servidores es muy difícil de depurar.
Qué necesitamos
Pues instalado en el sistema: qemu (evidentemente).
A la hora de probar hurd me he encontrado con que al usar la aceleración de kqemu el sistema no arrancaba en la máquina virtual, por tanto no recomiendo instalarlo.
Aparte, necesitaremos una ISO (o el CD ya quemado) con una live que tenga grub, por ejemplo: molinux, gnesis, debian netinstall, etc. Finalmente necesitamos el CD de instalación de hurd, yo he usado:
http://ftp.gnuab.org/pub/debian-cd/current/hurd-i386/debian-K14-hurd-i386-mini.iso
No hace falta quemar la ISO, con bajarnos el archivo nos sobra ;).
Creando el sistema base
En primer lugar creamos un directorio donde guarrear:
Ya podemos arrancar nuestra máquina virtual, iniciando desde la ISO para ejecutar la instalación:
$qemu -hda hd0.img -cdrom debian-K14-hurd-i386-mini.iso -boot d
Instalando el sistema
Un "bonito" menú nos va a permitir realizar la instalación de una forma fácil y cómoda, empezamos eligiendo la configuración de teclado (opción 1). Después comenzamos con el particionado (opción 2), donde seleccionamos nuestro disco virtual (/dev/hda en nuestro caso). Como no tenemos ninguna tabla de particiones ahí nos preguntará lo siguiente:
No partition table or unknown signature on partition table
Do you wish to start with a zero table [y/N]?
...y le diremos que sí (es decir, y). Ahora nos aparecerá cfdisk y crearemos dos particiones: la swap y la del sistema. Para ello seleccionamos New, Primary, un tamaño de unos 200MB, Beginning, Type e introducimos un 82. Ya tenemos la swap creada, ahora la partición del sistema: Seleccionamos Free Space (cursor abajo), New, Primary y el tamaño por defecto (el máximo posible); ya tenemos la segunda partición. Ahora seleccionamos Write, le decimos que yes y finalmente seleccionamos Quit.
Ahora inicializamos y activamos la partición swap (opción 3) y le decimos que yes a las dos preguntas. Hacemos lo mismo con la partición GNU/Hurd (opción 4). Después de terminar el proceso nos preguntará si queremos montar esa partición como Root Filesystem, a lo que también diremos que Yes.
Ahora ya podemos instalar el sistema base (opción 6) y seleccionamos como origen CD-ROM drive. Nos preguntará el punto de montaje del mismo, que es el que aparece por defecto. Cuando finalice, reinciamos la máquina virtual (opción 7) y cuando vuelva a aparecer lilo cerraremos qemu para cambiar las opciones de la máquina virtual y no usar esa imagen de CD.
Instalando GRUB
Ahora nos encontramos con un problema: este proceso prepara una partición y copia unos ficheros, pero no instala grub, por tanto no podemos iniciar nuestro disco virtual con qemu. La forma en la que yo he instalado grub es la siguiente: vamos a arrancar el liveCD con qemu de la misma forma que arrancábamos la instalación de hurd y restauraremos GRUB (en el ejemplo he usado el CD de instalación de debian):
$qemu -hda hd0.img -cdrom debian-testing-i386-netinst.iso -boot d
Para continuar con el ejemplo, abriríamos una shell, montaríamos /dev/hda2 en /mnt y ejecutaríamos lo siguiente:
#grub-install /dev/hda --root-directory /mnt
Y con ello ya tendríamos instalado el gestor de arranque. Aunque no lo he dicho antes, es indispensable el gestor grub, cualquier otro como lilo o yaboot no nos sirve para nada. Una vez instalado, apagamos la máquina virtual y cerramos qemu, vamos a inciar por primera vez hurd.
Configurando nuestro sistema
Ahora arrancamos qemu ya sin imágenes de cd-rom, directamente desde nuestro disco virtual:
$qemu -hda hd0.img
Para conseguir una mayor estabilidad de hurd dentro de qemu yo utilizo las siguientes opciones:
$qemu -hda hd0.img -std-vga-no-acpi-net none
Y ahora, para empezar a usar nuestro nuevo sistema, debemos configurarlo primero: se tienen que crear los nodos para los dispositivos, configurar los paquetes base, etc. Arrancaremos el sistema en modo single, esto lo podemos hacer con los siguientes comandos en la shell de grub (a la que accedemos pulsando c estando en el menú de arranque):
En cuanto a la notación de unidades de grub es la siguiente:
(hdD,P)
Donde D es el disco duro, empezando por 0 como primario maestro y 3 como secundario esclavo; y P es la partición, comenzando desde 0 para la primera partición. La notación en hurd es del estilo BSD, es decir:
hdDsP
Donde D es igual que en grub y P también es la partición pero comenzando desde 1 (igual que en grub pero sumando 1).
¡Y ahí va! comienza el arranque de nuestro sistema GNU. Ahora sólo nos queda ejecutar el script de autoconfiguración:
sh-3.1#./native-install
Esto creará los dispositivos iniciales y configurará algunos paquetes iniciales; cuando termine, reiniciamos otra vez el sistema, volvemos a arrancar en modo single (la misma secuencia de comandos en el grub que antes) y volvemos a ejecutar el script para terminar de configurar el sistema y los paquetes:
sh-3.1#./native-install
Nos preguntará por nuestra zona geográfica, indicaremos Europe (código 8 ) y después nuestra zona horaria, teclearemos Madrid. Continuará configurando paquetes, cuando finalice podremos reiniciar la máquina virtual y ya tenemos nuestro sistema gnu listo para funcionar!.
Arranque normal del sistema gnu
La secuencia de comandos de grub para arrancar el sistema de forma normal es:
Pero he de decir que por alguna razón, puede ser que no arranque el sistema de esta forma (se queda congelado en el inicio), si sucede esto no hay más remedio que iniciar como se ha explicado antes: con los comandos en la shell de grub.
Apéndice B: Instalación nativa desde Debian
Si queremos ir más allá que ejecutar hurd en una máquina virtual, podemos instalarlo en nuestra propia máquina. Este proceso es aún más sencillo que el anterior, sólo necesitamos una partición de un par de gigas, por compatibilidad con todo lo anterior, supongamos que esa partición es /dev/hda2 en nuestro disco duro, primero la formateamos (debe ser de tipo 83 - linux):
#mke2fs -b 4096 -o hurd /dev/hda2
Ahora instalamos un paquetito muy chulo:
#apt-get install crosshurd
Este paquete nos permite realizar una instalación cross-system de diversos sistemas operativos. Montamos la partición formateada en algún sitio:
#mount /dev/hda2 /mnt/hurd -t ext2
...y ejecutamos la instalación:
#crosshurd
Esto nos pedirá el punto de montaje, introducimos /mnt/hurd o el que hayamos usado y seleccionamos el tipo de instalación, gnu en nuestro caso. Esto copiará todos los archivos necesarios en esa partición. Una vez terminado añadimos los items en el archivo /boot/grub/menu.lst del apéndice A y realizamos el proceso de configuración de la misma forma que lo hacíamos en la máquina virtual.
Es muy normal que hurd no arranque y se quede colgado en el inicio, esto se debe a que aún no está implementada la capacidad de cargar/descargar módulos del núcleo, por tanto se compilan todos de forma estática, esto provoca que en determinados hardwares se quede colgado, la única solución es recompilar hurd para la máquina específica... que esto puede ser motivo para una nueva receta :P
Gracias a nuestro amigo Arturo, si no queremos instalar ni configurar nada, sólamente queremos probar hurd sobre qemu podemos usar la imagen de este blog: Zaborowski.
Hay muchos más enlaces... todos los podéis encontrar a partir del enlace en Debian. Espero que os sea útil o por lo menos tan entretenido como a mi! ;)
Máquinas PPC
Cuando uclmwifi y euroroam soporten pump y se hiele el infierno }:).
Existen ya dos recetas sobre la PSP en CRySoL: una pequeña introducción al uso de la PSP en sistemas GNU/Linux y otra sobre cómo instalarse el pspsdk completo en el sistema. Ya sólo faltaba ésta: cómo programar una aplicación. Para ello he pasado de hacer el hola mundo convencional y he decidido escribir una pequeña intro como las de la vieja escuela. De eso va esta receta: programar una pequeña intro para la PSP desde GNU/Linux.
Introducción
Para empezar tenemos que saber que es una intro: hace tiempo, cuando los sistemas monousuario tipo DOS pululaban nuestros PC's, antes de que Internet fuese lo que es hoy, la gente gustaba de hacer pequeñas joyas de programación (generalmente en ensamblador puro) que consistían en algún efecto visual acompañado de alguna musiquilla tipo nintendo NES. Se hacían competiciones (y se hacen) como las famosas Assembly's.
Nosotros no vamos a programar en ensamblador del Mips, para eso tenemos Arquitectura e Ingeniería de Computadores, vamos a usar C++ (aunque casi podría tratarse de C) y no vamos a trabajar con la máquina desnuda, realizaremos llamadas a funciones de librerías.
Para crear una intro tienes que tener en mente el efectillo que quieras crear, una musiquilla que acompañe y, finalmente, cúales y cómo serán los créditos que irán apareciendo. Una intro suele ser siempre cíclica y no precisa de interacción con el usuario (salvo para finalizar).
Ingredientes
Tenéis que instalar el toolchain de la psp (ver receta al respecto) y el pspsdk completo, además de la librería cpplibs incluída como extra. A parte de esto es necesario el arte de la intro, que en nuestro caso se compondrá de un fondo de pantalla, un tipo de letra raster y un archivo mod de cuatro canales con una música al más puro estilo "pitiditos".
Esqueleto de un programa para la PSP
Realmente no existe una gran diferencia entre hacer un programa para un sistema convencional o uno para la PSP, sólo debemos tener en cuenta una cosa muy importante: la terminación. Nuestros programas se lanzarán como un hilo de usuario dentro del XMB de la PSP. Para ello crearemos un nuevo hilo que esperará la llamada del XMB (un callback) para finalizar la aplicación, éste hilo terminará lo que tenga que terminar de nuestro programa, básicamente consiste en lo siguiente:
/*
* Esqueleto de aplicación para PSP
*/
#include <pspkernel.h>
// Aquí configuramos nuestro hilo
PSP_MODULE_INFO("nombre programa", 0, 1, 1);
PSP_MAIN_THREAD_ATTR(THREAD_ATTR_USER);
int done = 0; // Indica cuando terminar
int SetupCallbacks();
int main(int argc, char* argv[])
{
SetupCallbacks();
// Nuestras inicializaciones
// y movidas...
...
// Nuestro bucle principal, esto
// se ejecutará hasta que nuestro
// manejador del callback lo diga...
while (!done)
{
// Aqui va el meollo del programa
}
// Ahora finalizamos las cosas que hayamos
// inciado
...
// Finalmente cerramos el hilo
sceKernelExitGame();
return 0;
}
// Manejador del callback de salida
int exit_callback(int arg1, int arg2, void *common)
{
done = 1;
return 0;
}
// Crea el callback de salida
int CallbackThread(SceSize args, void *argp)
{
int cbid;
cbid = sceKernelCreateCallback("Exit Callback", exit_callback, NULL);
sceKernelRegisterExitCallback(cbid);
sceKernelSleepThreadCB();
return 0;
}
// Crea y configura el hilo para el callback, retorna su ID
int SetupCallbacks(void)
{
int thid = 0;
thid = sceKernelCreateThread("update_thread", CallbackThread, 0x11, 0xFA0, 0, 0);
if(thid >= 0)
{
sceKernelStartThread(thid, 0, 0);
}
return thid;
}
Y bueno... ahora sólo nos queda saber qué vamos a hacer... ;-)
Ambientación
O lo que es lo mismo... un fondo de pantalla y la musiquita ;-). Para esto ya necesitamos usar cpplibs así que ya sabéis:
Para dibujar en la pantalla haremos lo siguiente: obtendremos un manejador de la VRAM de forma que todas las escrituras se realizan en un buffer de RAM (muy rápido) y una vez hayamos compuesto el frame en el buffer, lo volcaremos todo de una:
Screen *screen = Screen::getInstance();
Para cargar la imagen y la música usaremos cpplib, es muy fácil:
Image background("background.png");
Music::init();
Music music("music.mod", true);
...y reproducir la música en un hilo a parte y de forma cíclica (para eso el true de ahí arriba) hasta que se finalice el programa:
music.start();
Ale... ahora sólo nos falta dibujar el fondo, esto lo haremos en cada
frame (ahora no sería necesario, pero cuando haya animación sí):
while (!done)
{
// Volcamos el fondo (a un buffer intermedio)
screen->blit(&background, 0, 0, 480, 272, 0, 0);
// Aquí vendrá el codigo de los efectos
// Esto dibuja el frame
screen->flip();
}
Con esto ya tenéis una aplicación que os mostrará una bonita imagen y estará sonando una musiquita hasta que se apague la PSP o se salga del juego.
Fuentes raster
Estas fuentes, a diferencia de las vectoriales clásicas, se almacenan en un PNG (o formato que permita transparencia). La imagen tiene unos píxeles de forma que delimitan cada carácter. Todo esto no debemos hacerlo nosotros, existe una librería que maneja estas fuentes:
#include <libpsp2d/Font.h>
Ahora debemos crear un objeto con la cadena que queramos mostrar:
string msg("My first intro by Int-0");
Para poder centrar la cadena debemos conocer la fuente que vamos a usar y con ello la longitud en pixels de la cadena renderizada con el siguiente método:
Font font("font.png");
centerx = (480 - font.getTextWidth(msg)) / 2;
Finalmente sólo nos queda renderizarla en el buffer de la VRAM, es muy simple, pero recordad que hay que volcarlo después de volcar el fondo (si no lo sobreescribiríamos):
font.drawText(screen, msg, centerx, 5);
El problema de este método es que estas fuentes suelen ser muy grandes y no son muy útiles para mostrar mucho texto en la pantalla, por tanto los usaremos para títulos y encabezados.
El efectillo
El efecto que he pensado es muy simple: vamos a dibujar el logo de "PSP" a base de puntitos. Los puntitos irán girando y haciendo tontunas, además tendrán una pequeña estela (que consiste en los mismos puntos en la misma situación en la que estuvieron hace algunas iteraciones... pero pintados de un color más oscuro). Para situar los puntos haremos lo siguiente: dos vectores de enteros que contienen el desplazamiento en X y el desplazamiento en Y de cada punto teniendo como origen el centro del logo. Para dibujar el logo sólo tenemos que elegir un punto cualquiera de la pantalla, recorrer los vectores y pintar cada punto según el punto seleccionado y los desplazamientos de los vectores:
// Añadimos un segundo desplazamiento a los puntos: la rotacion
// para ello necesitamos variar un angulo de forma ciclica
ang = (ang + 0.01);
// El limite a 100 esta puesto a ojimetro (y con que tino!)
if (ang > 100) { ang = 0;};
// Iteramos en todos los puntos de "PSP", si, son 156 puntos
for (idx = 0; idx < 156; idx++){
// Posiciones absolutas del siguiente punto a dibujar
// La razon de no calcular el seno y el coseno aqui esta en que
// para dibujar la estela restaremos un valor al angulo para que
// se quede igual que en iteraciones anteriores... muy feo!
px = (int)(fx[idx] * 6);
py = (int)(fy[idx] * 6);
// Poniendo el punto que nos interesa y tres mas de estela...
// Las estelas no habria que calcularlas... deberian estar en un
// buffer, esto permitiria calcular un seno y un coseno por iteracion
// y no las cuatro veces que se hace (aumentaria la velocidad
// considerablemente)
screen->putPixel(0x000000, 240 + (int)(px * cosf(ang - 0.12)), 130 + (int)(py * sinf(ang - 0.12)));
screen->putPixel(0x4F4F4F, 240 + (int)(px * cosf(ang - 0.06)), 130 + (int)(py * sinf(ang - 0.06)));
screen->putPixel(0x8F8F8F, 240 + (int)(px * cosf(ang - 0.02)), 130 + (int)(py * sinf(ang - 0.02)));
screen->putPixel(0xFFFFFF, 240 + (int)(px * cosf(ang)), 130 + (int)(py * sinf(ang)));
}
Los créditos
Finalmente quedan los créditos, para quien vea el código, veréis que hay un ltfont.c extraño por ahí...¿de que va eso? pues no es otra cosa que unos métodos que manejan fuentes gráficas simples (no rasters) formadas por matrices de 8x8 puntos (8 bytes por carácter) así al estilo antiguo. Es un código muy feo pero muy sencillo... además se sale un poco del objetivo de la receta, por tanto creo que no es útil ni necesario hablar de ello aquí. Sólo diré que todas las letrillas que aparecen por la intro se renderizan punto a punto con esa librería.
La forma en la que imprimimos los créditos es la siguiente: primero una frase haciendo scrolling horizontal de forma contínua, esto se hace de forma gratuita en los framebuffers ya que si nos salimos por un lado de la pantalla el pixel aparece automáticamente por el otro... jejeje...
// El cartel que va haciendo scrolling vertical
myPutCicleStr(screen, tx++, 180, 0xFFFFFF, thks);
tx = tx % 480;
En cuanto los créditos propiamente dichos, pues fácil: según su coordenada Y sabremos si debemos subirlo, bajarlo o mantenerlo un rato:
// Los creditos
myPutCicleStr(screen, xc, yc, 0xFFFFFF, credits[ic]);
yc = yc + yinc;
// Cuando alcanzan la altura deseada lo paramos un rato
if (yc == 215) {
yinc = 0;
++wt;
}
// Transcurrido el rato lo podemos volver a ocultar
if (wt == 120) { yinc = 1; }
// Una vez ocultado (aprovechamos el cropping que
// implementamos en ltfont.c) vamos al siguiente...
if (yc >= 291) {
wt = 0;
// Siguiente credito (este 53 de aqui da pena!)
ic = (ic + 1) % 53;
yc = 290;
yinc = -1;
xc = 240 - (credits[ic].length() * 4);
}
Compilando el engendro
Sólo nos queda hacer el Makefile, esto nos obliga a conocer como llamar al compilador, librerías, etc. o también podemos usar las reglas predefinidas del pspsdk con lo que nos queda un archivo bastante sencillito:
Para usar las reglas predefinidas debemos crear unas variables para generar lo que deseemos, principalmente hay que definir las siguientes:
EXTRA_TARGETS: indica qué queremos generar, podemos crear desde un simple EBOOT.PBP (lo que hay que hacer para firmwares customizados a unos archivos para el kxploit (lo necesario para firmware 1.50).
PSP_EBOOT_TITLE: es el título que pondrá el menú del XMB cuando nuestro archivo esté seleccionado.
PSP_EBOOT_ICON: el icono del programa dentro del XMB.
PSP_EBOOT_UNKPNG: imagen transparente que superpondrá a PIC1.
PSP_EBOOT_PIC1: Imagen de fondo que reemplazará al fondo del XMB cuando se seleccione nuestro programa.
Un PBP puede incluír más archivos como una música en formato ATRACT3, el icono puede ser un vídeos y no sólo un PNG... etc.
Apéndice A: instalación en firmware 1.50
Para instalar las aplicaciones que generemos en este firmware, el objetivo a invocar por make debe ser kxploit o (preferiblemente) SCEkxploit. Los dos objetivos generan los mismos archivos, pero existe una diferencia: el nombre de los directorios. En un caso creará nombreproyecto/ y nombreproyecto%/ y en el otro __SCE__nombreproyecto y %__SCE__nombreproyecto. La ventaja de este último método es que al instalar nuestros programas, no aparecerá en el menú del XMB los incómodos "datos dañados" que aparecerán con el otro.
Una vez compilada nuestra aplicación con cualquiera de estos dos objetivos, copiaremos esos directorios en /PSP/GAME de nuestra memorystick y descomprimiremos el arte en /PSP/GAME/nombreproyecto o /PSP/GAME/__SCE__nombreproyecto.
Apéndice B: instalación en firmware 3.xx customs
Mucho más sencillo que en el caso anterior, simplemente debemos invocar la regla EBOOT.PBP del make y copiaremos el archivo y el arte en algún subdirectorio dentro de /PSP/GAME150.
Sin más... disfrutadlo... a ver si hacemos unas cuantas intros chulas y podemos montar una mini-compo de intros... si tenéis dudas sobre el código o el proceso de creación ya sabéis, pero os recomiendo usar la lista de correo porque es más dinámica para estas cosas... en fin... nos vemos! ;)
Si conocéis a alguien que use Gentoo puede que tengáis que aguantar frases del tipo "todos mis programas están compilados y optimizados a mi sistema", etc. Bueno, pues en Debian podemos tener eso también, o incluso mejor: tener paquetes deb optimizados a nuestra arquitectura. Y lo mejor: sólo para los paquetes que nosotros queramos.
Hola majetes! Supongo que todos vosotros tendréis webcams y quizá hayáis probado a enchufarlas en vuestras distros y... ohhh... desilusión... el linux no la pilla! (Si tenemos Debian es peor todavía porque de serie apenas tenemos módulos adecuados). No hay que preocuparse... vamos a hablar de unos cuantos módulos que hay por ahí con los que, en total, tendremos soporte para varios cientos de cámaras. No quiero decir que estén todos los que hay, pero al menos sí algunos de los más importantes.
Hace tiempo, hubo una actualización en Sid que hizo que sudo volviese a pedirnos la contraseña de usuario. Si, vale que sea muy seguro, pero también es más rollo... vamos a volver a dejar las cosas como estaban y de paso nos asomaremos al fichero /etc/sudoers que tan buena pinta tiene.
Hola buenas! todos nosotros somos adictos en mayor/menor medida a las redes P2P, de ellas descargamos películas, discos y algunos delincuentes programas y juegos. No es ningún secreto que la mayoría de los internautas españoles usan su conexión a internet para esto, las ISP's lo saben y como pasan de que su red se colapse realizan un filtro de protocolo a emule y torrents (las compañías evidentemente te lo negarán). No vale cambiar el puerto de escucha porque no se hace un filtro de puertos, se realiza filtro de protocolo. Se sospecha que Telefónica y Ono lo hacen; si es verdad que lo hacen deberían por lo menos avisar, así que nosotros vamos a intentar hacerles la pirula.
Conexiones ofuscadas
Nuestro problema está en que si un router de nuestro ISP sabe qué protocolo está transportando, podrá aplicar unas reglas de QoS (calidad de servicio) que probablemente a nosotros no nos haga ninguna gracia. La solución es más o menos sencilla: ofuscar el protocolo. Ofuscar una conexión es "desbaratar" el paquete saliente de forma que sea irreconocible, cuando llega a su destino, el receptor conoce la forma de recomponer el paquete. Hasta lo que sé, por ahora es la propia aplicación la que debe ofuscar el protocolo.
Emule
En GNU/Linux no disponemos de un buen cliente para edonkey que permita ofuscación de protocolo... debemos recurrir al maravilloso y archiconocido eMule. Tranquilos porque tiene licencia GPL :-P. Pero Int-0 se ha vuelto loco!! si eso es para hassefroch!!. Pues si... pero nosotros tenemos wine ;-)
Pues bien, el emule funciona bastante bien con wine pero existe un problema: para alcanzar buenas velocidades es necesario abrir un raw socket UDP y esto sólo se puede hacer con wine si se es administrador :O. La forma en la que yo lanzo emule (no la versión con instalador, sino la que está lista para ejecutar) es la siguiente:
#sudo wine emule.exe
Hay que advertir que esto es PELIGROSO, para paliar un poco los problemas, podríamos crear una jaula chroot o algo así, si alguno lo hace que mande un post o modifique la receta :-P.
Una vez arrancado la mula, nos vamos a Preferencias > Seguridad > Activar la Ofuscación de Protocolo y listo!. El único problema de todo esto es que no hay mucha gente que use ofuscación, por ese motivo sólo descargaréis a máxima velocidad de clientes que usen también ofuscación.
Torrent
Bueno, este es el protocolo de p2p de GNU por excelencia :-). Aquí tenemos clientes en muchos sabores... pero que permitan la ofuscación de protocolo reduce bastante el abanico, concretamente (que yo conozca): Azureus y ktorrent. El Azureus está muy chulo pero tiene un inconveniente: carga mucho la máquina. El Ktorrent es más ligerito. Tanto Azureus como ktorrent permiten conexiones ofuscadas (pero en las opciones aparece como permitir cifrado de protocolo), así que ya sabeís, cualquiera de los dos os vale, además que ambos son paquete Debian.
Y con esto termino... ya sabéis que la descarga de cierto software es absolutamente ilegal y la desapruebo completamente. Esta receta NO sirve para delinquir sino para paliar parcialmente la política restrictiva de los ISP's (no la discuto, pero me parece FATAL que no lo avisen oficialmente).
Tal vez, antes de hablar en recetas anteriores de bacula hubiese sido conveniente hablar sobre el manejo de cintas de backup a pelo. Esto nos puede ser útil en caso de querer almacenar datos en cinta de forma esporádica o para limpieza de las mismas... o simplemente por saber un poco cómo funciona esto de las cintas SCSI.
Hola amigos informáticos y amigos en general! Hace poco me encontraba con tres amigas cuando una de ellas me dijo que no conseguía instalarse el ADSL en su ordenador porque le faltaba el disco de windows. A lo que otra amiga (que me conocía más) respondió: no, él no te va a ayudar (no me acuerdo porqué dijo). Yo dije que si, que ayudaría todo lo que hiciese falta... pero en GNU/Linux. Finalmente estalló la típica discusión que acabó con el resultado de que yo era un mal amigo con el que no se podía contar porque no iba por ahí arreglando windoses a mis amigos.
A pesar de que en anteriores recetas explicamos cómo realizar y recuperar backups en bacula, esto no es suficiente en el caso de querer recuperar un sistema completo. En caso de desastre total deberíamos volver a crear particiones, instalar un sistema base en el que recuperar los backups y, si no hicimos backup de la configuración del sistema, tendríamos que volver a configurarlo todo. Deberíamos separar backups del sistema y backups de los datos del sistema. Así podremos encontrar un método mejor para realizar nuestros respaldos.
Backup de los datos
Bien... hay mucho que explicar... pero está todo en las recetas sobre bácula:
Lo único que debemos saber es qué es lo que vamos a almacenar. Esto es fácil: /var/ (no todo... las bases de datos, páginas web, repositorios, etc.) y /home. Como seréis buenos usuarios, no usaréis root para nada, por tanto ese no hace falta salvar.
Ahora sólo nos queda salvar el sistema...
Backup del sistema
Para hacer backup del sistema hay que tener en cuenta un par de cosas: qué ficheros salvar, sus enlaces, atributos, particiones, sector de arranque, etc. y lo que es más importante: en caso de que nos quedemos sin sistema... ¿cómo lo podemos recuperar? ¿una live? como véis no es tan trivial como puede parecer en un principio... necesitamos un método para hacer todo esto de una forma fácil y rápida: mondo.
Instalar mondo
Para los debianitas y similares:
$apt-get install mondo
Lo normal en estos casos es que ahora ponga unos comandillos para invocar a mondo... pero mondo tiene GUI!!! :jawdrop: (para que luego digan los de hassefroch) (algunos dirán que 6 botones en modo texto no son gui... pero otros dicen que un ratón tiene potenciómetros así que estamos en paz). Vienen muchas opciones, la más normal será hard disk. Esta opción creará unas imágenes iso del tamaño que digamos con nuestro respaldo del sistema. Hay una opción (create DVD images) que también podríamos usar... esta opción graba directamente los DVD's... pero tiene un problema: deberíamos estar todo el proceso ahí para ir cambiando los grabables... en un sistema grande eso puede ser un auténtico tostón.
Otra cosa que hay que tener en cuenta es que en el directorio temporal necesitamos una gran cantidad de espacio libre (un poco más que el tamaño total de los ficheros a hacer backup).
A la hora de hacer el backup excluiremos todos aquellos directorios que ya tengamos incluídos en las cintas de backup, /home sobre todo. En cuanto a /var, excluiremos todo aquello que no hayamos metido en cinta, cosas como la base de datos de dpkg, etc.
Restaurar el sistema
Bien... hemos creado las imágenes con mondo y justo después se nos ha reventado el sistema :jawdrop:. No pasa nada! Tanto si perdimos algunos ficheros como el sistema entero... reiniciamos el PC con el primer DVD insertado. El DVD arranca y nos aparece otra gui con varias opciones: testear backup, restauración manual y restauración automática. Realizamos una restauración automática, nos irá pidiendo los DVD's y extraerá los ficheros y tal.
Una vez hayamos terminado reiniciaremos el PC ya sin los DVD's y arrancará nuestro sistema. Como nuestro sistema ya tenía bácula restauraremos los datos de /home desde las cintas (siguiendo las recetas).
Apéndice A: automondo
El uso del gui en mondo tiene un problema: exige interacción con el usuario. Puede ser que necesitemos poder crear imágenes sin que un usuario lo exija (cron). Además puede ser necesario almacenar alguna configuración en algún sitio.
Para estas cosas he creado un pequeño y tonto script que he llamado automondo. El script lo copiaremos en /usr/sbin, lo llamaremos automondo y le daremos permisos de ejecución. El script es el siguiente:
#!/bin/bash
# Cargamos la configuracion (si existe)
#
CONFIG_FILE=/etc/mondo/automondo.conf
if [ -e $CONFIG_FILE ]
then
. $CONFIG_FILE
fi
# Cargamos valores por defecto (en caso de que no exista CFG o falten parametros)
if [ -z "$IMG_DESTINATION" ]
then
IMG_DESTINATION=/root/images/mondo
fi
if [ -z "$IMG_PREFIX" ]
then
IMG_PREFIX=`hostname`
fi
if [ -z "$IMG_SIZE" ]
then
IMG_SIZE=4200m
fi
if [ -z "$BCK_EXCLUDE" ]
then
BCK_EXCLUDE="/tmp /lost+found"
fi
if [ -z "$TMP_DIR" ]
then
TMP_DIR="/tmp"
fi
# Creamos el destino si no existe
if [ ! -d $IMG_DESTINATION ]
then
mkdir $IMG_DESTINATION
fi
# Creamos el temporal si no existe
if [ ! -d $TMP_DIR ]
then
mkdir $TMP_DIR
fi
# Invocamos el asunto...
/usr/sbin/mondoarchive -O -d $IMG_DESTINATION -p $IMG_PREFIX -i -E "$BCK_EXCLUDE" -N -s $IMG_SIZE -9 -T "$TMP_DIR" -S "$TMP_DIR"
Y ahora creamos el archivo /etc/mondo/automondo.conf con el siguiente contenido:
# Destino para las imagenes
#
IMG_DESTINATION=/root/mondo/images
# Prefijo en el nombre de las imagenes
#
IMG_PREFIX=`hostname`
# Tamaño de los iso
#
IMG_SIZE=4200m
# Directorios a excluir (proc y tal lo excluye mondo automáticamente)
#
BCK_EXCLUDE="/var/tmp /var/run /home /root/mondo"
# Directorio temporal
#
TMP_DIR="/root/mondo/temp"
Si ahora ejecutamos automondo se nos crearán automáticamente las imágenes del sistema ;).
Nota: Existe un "pequeño" problema que no se muy bien como arreglar. Resulta que aunque las imágenes las crea bien y funcionan (doy fe) da un "error" al final del proceso y pide la pulsación de intro para continuar. Cleto me ha sugerido el siguiente cambio en la última línea del script:
Esta receta explica cómo configurar una máquina para utilizar un servidor de impresoras CUPS remoto
Configurar la impresora es una tarea tan trivial en GNU que vamos a aprovechar para montar un servicio de impresión decentillo.
Impresoras locales y remotas
Hace falta que explique que es una cosa y otra?. Pues si... que para eso estamos :P.
Una impresora es local o remota si tiene o no un cable que va directamente desde nuestro equipo a la impresora... falso! :jawdrop: Eso depende del equipo donde esté nuestra cola de impresión (de aquí en adelante lo llamaremos spool para evitar suspicacias). Una netprinter es directamente una impresora remota, en eso estamos de acuerdo. Sin embargo, una impresora serie o USB puede ser remota (la impresora se conecta a un equipo y nuestro spool no está en ese equipo) o local (el spool y la impresora residen en el mismo equipo). Gracias a cups podremos imprimir en una impresora local que se encuentre en el otro hemisferio... por ejemplo ;)
Spoolers locales y remotos
Aquí las diferencias son evidentes: el spool está en nuestro equipo? si, pues es local; no, pues es remoto.
A partir de aquí tenemos que saber qué clase de organización queremos tener en nuestro servicio de impresión: podemos tener todas las impresoras compartidas por red, cada cliente tiene su propia cola y todos los clientes envían sus trabajos por red a las impresoras que deseen. También podemos tener una única cola remota donde configuremos todas las impresoras que queramos. Los clientes sólo deben conocer la ubicación de esa cola para tener acceso a todas las impresoras.
Qué instalar y dónde
Bien, primero de todo: cualquier máquina que desee imprimir deberá tener instalado el cliente cups:
$aptitude install cupsys-client
Y ahora tenemos dos opciones: si la máquina tiene una impresora local que deseamos compartir necesitaremos el servidor cups:
$aptitude install cupsys-server
Para las netprinters no es necesario dedicar una máquina, en cualquiera que tengamos ya instalado el servidor de cups podremos añadirlas.
Configurar la interfaz web administrativa de cups
Esta interfaz sólo soporta SSL, por tanto debemos crear los certificados oportunos (una receta por aquí indica cómo hacerlo) y los copiaremos en /etc/cups/ssl con el nombre de cups.pem. Ahora sólo debemos restringir un poco el acceso (malditos hackers :evil:!), en el archivo /etc/cups/cupsd.conf tendremos que modificar algo parecido a:
...
# Acceso al servicio
Order allow,deny
Allow @LOCAL
# Mi LAN
Allow 192.168.0.
# Un equipo cualquiera
Allow 10.0.0.1
# Acceso administrativo
Encryption Requiered
Order allow,deny
Allow @LOCAL
Allow 192.168.0.
AuthType Basic
# Requiere un usuario del sistema local
Requiere user @SYSTEM
Order allow,deny
Allow @LOCAL
Allow 192.168.0.
...
Con esto tendremos acceso a la interfaz administrativa con la que podremos añadir impresoras locales, spoolers remotos y netprinters. Por cada impresora que añadamos podremos indicar políticas de seguridad determinadas: encriptación de documentos, acceso de usuarios y equipos, etc.
Configurar clientes
Bueno, si tenemos el cliente cups instalado y queremos acceder a algún spool remoto con un montón de impresoras ya configuradas y listas para atascarse, creamos/modificamos el archivo /etc/cups/client.conf para dejarlo como sigue:
ServerName 192.168.0.1
Encryption Never
Aunque esto es poco seguro ya que nunca usará TSL (incluso estando disponible)... pero podemos indicar IfRequest en otro caso... ;)
Si ahora ejecutáis gnome-cups-manager os aparecerán todas las impresoras configuradas en el spool remoto y marcadas como públicas.
Apéndice A: Autoconfigurar impresoras locales
Como somos muy vaguetes... alguien por ahí hizo un programa que lo hace solito ;) :
Hola! Dado que en GNU tenemos estupendísimos programas como Inkscape o The Gimp es cada vez más común el querer disponer de una tableta digitalizadora chula para poder trabajar con gráficos de una forma más cómoda y fácil. Si habéis pensado en comprar alguna y tenéis miedo del soporte que linux os pueda brindar, os recomiendo las Wacom, tienen un soporte estupendo (parece ser que wacom colabora con el desarrollador de los drivers).
Instalando software necesario
Los drivers soportan tanto linux 2.4.x como 2.6.x, nosotros explicaremos como instalarlo y configurarlo en linux de la rama 2.6. En Debian (como no podía ser de otra forma):
$m-a ai wacom
Y ya tenemos los módulos para el linux, ahora debemos instalar el driver para X.Org:
$apt-get install xserver-xorg-input-wacom
También puede ser útil contar con:
$apt-get install wacom-tools
Bien, ya tenemos todo listo para configurarlo, vamos a ello...
Configurando X.Org
Si todavía queda alguien que use Xfree86, esto es completamente compatible... ;)
Las wacom disponen de varios dispositivos físicos apuntadores: el lápiz, un ratón, etc. Son capaces de detectar qué dispositivo estamos usando, es decir: si estamos utilizando el lápiz o el ratón (en mi caso). En el archivo de configuración de X.Org configuraremos los distintos tipos que soporta el driver y podremos tener configuraciones específicas para cada uno, así por ejemplo el puntero se comportará de una forma si usamos lápiz o de otra si estamos con el ratón (esto es genial!). Pues aquí va mi código para el archivo /etc/X11/xorg.conf:
En las opciones de los dispositivos se puede controlar TODO, hay muchísimos parámetros (consultad el manual). Pincipalmente tenemos Threshold (sensibilidad) y Mode, que puede ser Relative o Absolute (por defecto). El modo absoluto significa que las esquinas de la tableta son las esquinas de la pantalla, recorrer la tableta es recorrer la pantalla. El modo relativo sirve para trabajar con mayor precisión, pero es más incómodo y necesitaremos usar un ratón también.
El dispositivo /dev/input/wacom
Si instaláis en Debian (y supongo que en otras igual) os aparecerá un dispositivo /dev/input/wacom que será un enlace simbólico débil a /dev/input/eventX, siendo X un número de 1 al que sea. Esto es así porque debe existir una regla para udev tal que así (archivo /etc/udev/rules.d/10_wacom.rules):
Con este archivo ahí y ejecutando lo que tenéis en la sección Comportamiento errático del puntero os debería aparecer ese enlace. De todas formas, si no os aparece esta es mi cutre-solución-o-matic-2000:
Mediante wacdump averiguaremos el dispositivo de nuestra wacom:
Pulsáis Ctrl+C (o Ctrl+X+Alt+Esc+X+F+win+5+Ctrl+Esc+U si fuese emacs) para salir y hacéis el enlace:
$ln-s /dev/input/event2 /dev/input/wacom
Ahora, si reinciamos X.Org, tendremos la tableta funcionando... casi...
Comportamiento errático del puntero
Lo más normal es que mováis un poco el lápiz y el puntero se vuelva loco y se empiece a cliquear todo y se os quede la sesión "medio muerta" y me mandéis un mail poniéndome verde... pues bien, os comento el problema: cuando conectáis la tableta, el módulo usbmouse reclama el nuevo hardware y lo maneja él... MAL! Debemos hacer que se cargue primero el módulo wacom y luego lo que tenga que venir. También se puede configurar udev para ello... pero como tampoco me he pegado con eso, ahí va mi solución cutre:
...y ya podemos reiniciar X.Org y disfrutar de nuestra tableta! :)
Apéndice A: instalación y compilación from scratch
Pues nada... nos gusta vivir al límite... eh? vayamos a la página del proyecto Linux Wacom y pinchamos en Project Status en la versión en desarrollo (actualmente 0.7.7-4), guardamos el archivo en disco y lo descomprimimos:
#./configure
...morralla sin significado aparente para nosotros...
----------------------------------------
BUILD ENVIRONMENT:
architecture - i486-linux-gnu
linux kernel - yes 2.6.18
module versioning - yes -DCONFIG_MODVERSIONS -DMODVERSIONS -include /lib/modules/2.6.18-3-686/build/include/linux/modversions.h
kernel source - yes /lib/modules/2.6.18-3-686/build
Xorg SDK - yes /usr/include/xorg
XSERVER64 - no
dlloader - yes
XLib - yes /usr/lib
TCL - yes /usr/include/tcl8.4/
TK - yes /usr/include/tcl8.4/
ncurses - yes
BUILD OPTIONS:
wacom.o - no
wacdump - yes
xidump - yes
libwacomcfg - yes
libwacomxi - yes
xsetwacom - yes
hid.o - no
usbmouse.o - no
evdev.o - no
mousedev.o - no
input.o - no
tabletdev.o - no
wacom_drv.so - yes /usr/lib/xorg/modules/input
wacom_drv.o - no
----------------------------------------
Aquí nos dice que elementos nos va a generar y de cuáles va a pasar olímpicamente. Nos interesa (sobre todo) que genere wacom.o (el módulo para el kernel) y wacom_drv.so (el driver para X.Org). Si no os aparece a yes puede ser por dos causas: por defecto no se generá (ejecutar ./configure --help y os indicarán los parámetros) o porque os falten librerías de desarrollo de las X o las cabeceras del núcleo. El resto de elementos a generar son módulos más o menos útiles cuya utilidad queda fuera de esta receta...
Una vez hayamos ejecutado el configure y esté todo a nuestro gusto:
#make
$make install
Y si nada de esto da error... ya podemos empezar con la receta como si tal cosa... :)
Ya están los de emacs eligiendo el tema de crysol... vale que el otro fuese barroco... pero crysol-emacs-o-matic es un poco feuno (es una opinión no constructiva... que le voy a hacer)
Bien, ya vimos en una receta anterior como instalar y configurar un sistema bacula pero se nos quedó en el tintero lo más importante: ¿cómo indicar a bacula qué ficheros respaldar? ¿cuándo? ¿cómo?. En esta receta explicaremos cómo terminar de configurar un sistema bacula para su operación normal, recomendamos la lectura de la receta anterior sobre bacula... esta es como un "segundo capítulo".
Trabajos de backup
A la hora de configurar un servicio de backup, antes de modificar a diestro y siniestro archivos de backup, debemos pensar un poco de qué queremos hacer backup y, según su importancia, cuándo y cómo. En el cómo tenemos dos alternativas: completo y diferencial. Un backup completo respaldará toda la lista completa de ficheros a guardar, en cambio, un backup diferencial sólo guarda los ficheros modificados y nuevos respecto a la copia anterior (lo cual permite ahorrar espacio en cintas). Una base de datos tipo MySQL no tiene mucho sentido hacer respaldo diferencial puesto que se almacena toda ella en un único archivo binario y las más mínima modificación implicará el almacenado del fichero completo. En cambio, para una lista de ficheros de texto (un proyecto software, por ejemplo) los incrementales vienen muy bien puesto que pocas veces cambiarán todos los ficheros a la vez sino que se modifican poco a poco.
Para responder al cuándo debemos pensar en la importancia de los datos y en cuánto trabajo se va al garete si se perdieran los ficheros de un día para otro. Un conjunto de ficheros que se modifiquen a diario deberían respaldarse a diario, sin embargo, para ficheros que rara vez se modifiquen puede ser aceptable respaldarlos semanalmente, incluso mensualmente.
Tengamos por ejemplo un sistema Debian, en él tenemos un apache con su php y su drupal, a parte, tiene muchos usuarios que tienen sus proyectos en sus homes. ¿Cómo lo respaldaríamos? pues un ejemplo podría ser el siguiente: cada dos meses un backup del sistema completo (básicamente somos muy vagos y pasamos de reinstalarlo todo en caso de desastre, de esta forma podríamos restaurar el sistema completo sin mucho esfuerzo... aunque existen programas más adecuados para esto, ej: mindi y mondo); como la configuración del sistema es realmente más importante que el resto de archivos del sistema (puesto que un binario del sistema se encuentra a mano en el repositorio de paquetes, un archivo de configuración modificado por nosotros... pues no) realizaremos backups incrementales mansuales (tampoco se modifican taaanto) de los datos variables en la distribución, es decir /etc y parte de /var. También tenemos la base de datos MySQL, esto es más complicado puesto que no podemos hacer copia así como así de ella (¿que pasa si se modifica mientras se está haciendo backup?), la solución pasa por leerse la receta: Salvar (y recuperar) una base de datos MySQL y hacer backup de eso (esto podría ser motivo de una nueva receta). Por último tenemos los homes de los usuarios, como queremos que pierdan poco en caso de desastre realizaremos backups incrementales diarios y completos semanales (esto facilita la recuperación).
Una vez decidido cómo va a funcionar nuestro servicio de backup sólo nos queda configurar bacula director para que lo haga... pues empecemos...
Resource FileSet
Este resource define la lista de ficheros a respaldar. También permite establecer opciones útiles, como por ejemplo calcular sumas MD5 de verificación, o usar compresión gz, etc. Veamos un ejemplo:
Pues muy fácil, hemos creado un conjunto de ficheros, llamado configuracion sistema que incluye todos los ficheros y subdirectorios en /etc. De /var también metemos todo menos la "guarrería" :-P. Además, de los archivos que almacenemos se calculará la suma MD5 para comprobar que se salvaron correctamente. Se pueden usar comodines en plan /usr/share/*/examples y cosas así, tanto para Include como para Exclude. Se pueden especificar ficheros aislados, etc. Echad un vistazo al manual de bacula que vienen muchos ejemplos interesantes. El FileSet por defecto de bacula es el sistema de ficheros completo. Podemos crear los que queramos y posteriormente los identificaremos por su nombre.
Resource Schedule
Mediante estos resources se crean los intervalos de tiempo que emplearemos a la hora de crear los trabajos, al igual que los FileSet los identificaremos por un nombre, por ejemplo:
Schedule {
Name = "CicloSemanal"
Run = Incremental mon-sat at 01:05
Run = Full sun at 01:05
}
Schedule {
Name = "Diario"
Run = Full sun-sat at 23:10
}
Hemos creado dos: CicloSemanal y Diario, como véis, en el primero se realizan backups incrementales de lunes (monday) a sábado (saturday) a las 01:05h y el domingo (sunday) a la misma hora uno completo. En el otro schedule se realizan backups completos a diario. Por defecto éstos son los schedule de bacula (salvo por la hora). El diario se emplea para hacer backup del catálogo de bacula.
Resource JobDefs
Aquí es donde finalmente pegaremos todo lo anterior para definir un trabajo completo de backup, si hemos entendido todo hasta aquí no hay mucho que explicar:
JobDefs {
Name = "estado del sistema"
Enabled = yes
Type = Backup
Level = Incremental
Client = nombre_resource_filedaemon
FileSet = "configuracion sistema"
Schedule = "CicloSemanal"
Storage = nombre_resource_storage
Messages = Standard
Pool = Default
Priority = 10
}
Los campos Client y Storage se explicaron suficientemente en la receta anterior. El Level también se puede especificar aquí, pero si se especifica en el Schedule se usará el de éste último. En Priority indicaremos un número, cuanto menor sea, más prioritario es el trabajo (en caso de que se envíen varias peticiones a un storage daemon, por ejemplo, se atienden por orden de prioridad). En cuanto al Pool... lo explicaremos más adelante :-P. Por defecto en bacula existen dos trabajos: DefaultJob que hace backups incrementales diarios de todo el sistema y completo los domingos, después de cada backup hace uno completo del catálogo.
Resource Job
Todos los campos de un JobDef son válidos para este resource también, la diferencia es que el anterior era la definición de un trabajo y este es el trabajo propiamente dicho. Si tenemos una buena definición, el trabajo quedaría como sigue:
Job {
Name = "estado maquina"
JobDefs = "estado del sistema"
Write Bootstrap = "/var/lib/bacula/estado_maquina.bsr"
}
Con esto tendremos un trabajo en bacula llamado estado maquina, configurado como se indicó en estado del sistema. Además se creará una especie de log sobre el trabajo en el archivo indicado. Éste trabajo será el que podamos arrancar, parar, etc.
Ahora sólo nos queda saber una cosa, la organización del sistema de almacenamiento: los pools.
Resource Pool
En bacula se denomina volume a una cinta física (o archivo de backup). Un conjunto de volumes es un pool. Podemos definir varios para distintos propósitos, por ejemplo: en un pool almacenamos copias incrementales y en otro copias completas. Al instalar bacula se define un pool llamado Default de la siguiente forma:
Pool {
Name = Default
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 365 days
}
El parámetro Pool Type indica el tipo (uy que listo soy!), el único implementado en bacula es Backup, tienen intención de soportar otros como Migration, Cloned, etc. Los últimos tres parámetros tienen que ver con el reciclaje de cintas. Si no quedan mas volúmenes y se permite su reciclado, cuando un volumen sea más antiguo que su periodo de retención (un año en el ejemplo) será sobreescrito por backups nuevos.
Hay que decir que en un Pool podemos especificar parámetros como Client o Storage, que serían los que utilizaría bacula a menos se especificase lo contrario en otra resource "superior". Así pues podemos definir una especie de "valores por defecto" en una pool.
Si nos fijamos bien, en ningún parámetro se especifica qué volúmenes forman parte de esta pool... ¿cómo se hace eso? esto ya debemos hacerlo desde la bacula console. En el caso de las cintas se deben identificar con una etiqueta software que ponemos a las cintas con el comando label/relabel y posteriormente el comando add para añadir un volumen a un pool:
*label
Automatically selected Catalog: MyCatalog
Using Catalog "MyCatalog"
The defined Storage resources are:
1: File
2: respaldadora-sd
Select Storage resource (1-2): 2
Enter new Volume name: cinta01
*add
You probably don't want to be using this command since it
creates database records without labeling the Volumes.
You probably want to use the "label" command.
Automatically selected Catalog: MyCatalog
Using Catalog "MyCatalog"
Automatically selected Pool: Default
The defined Storage resources are:
1: File
2: respaldadora-sd
Select Storage resource (1-2): 2
Enter number of Volumes to create. 0=>fixed name. Max=1000: 0
Enter Volume name: cinta01
Podemos facilitarnos la vida un poco más si en el storage daemon, los resource tipo device que empleemos tienen la opción LabelMedia = yes, esto hará que bacula vaya etiquetando las cintas limpias o reciclables según vaya necesitándolas, es ese caso no necesitamos ejecutar label para nada.
Pues bien, con nuestro pool bien creado y los jobs bien definidos ya tenemos nuestro servicio de backup funcionando... ahora a esperar que no tengamos que usarlo!
Apéndice A: configuración completa de un bacula director
Para hacer una receta de copia-pega vamos a incluír un archivo de configuración completo para el bacula-director, ya sabéis, el archivo /etc/bacula/bacula-dir.conf:
Director {
Name = respaldadora-dir
DIRport = 9101
QueryFile = "/etc/bacula/scripts/query.sql"
WorkingDirectory = "/var/lib/bacula"
PidDirectory = "/var/run/bacula"
Maximum Concurrent Jobs = 1
Password = "password_para_respaldadora-dir"
Messages = Daemon
DirAddress = 127.0.0.1 # Esto obliga a que las consolas bacula solo se puedan ejecutar desde localhost
}
Client {
Name = importante-fd
Address = 192.168.0.1
FDPort = 9102
Catalog = MyCatalog
Password = "password_para_respaldadora-dir"
File Retention = 30 days
Job Retention = 6 months
AutoPrune = yes
}
Storage {
Name = File
Address = 192.168.0.2
SDPort = 9103
Password = "password_para_respaldadora-dir"
Device = FileStorage
Media Type = File
}
Storage {
Name = respaldadora-sd
Address = 192.168.0.2
SDPort = 9103
Password = "password_para_respaldadora-dir"
Device = Autochanger
Media Type = DDS-4
Autochanger = yes
}
Catalog {
Name = MyCatalog
dbname = bacula; DB Address = "" ; user = bacula; password = "password_de_bbdd"
}
Messages {
Name = Standard
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula: %t %e of %c %l\" %r"
operatorcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula: Intervention needed for %j\" %r"
mail = root@localhost = all, !skipped
operator = root@localhost = mount
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Messages {
Name = Daemon
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula daemon message\" %r"
mail = root@localhost = all, !skipped
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Pool {
Name = Default
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 365 days
}
Console {
Name = respaldadora-mon
Password = "password_para_respaldadora-mon"
CommandACL = status, .status
}
JobDefs {
Name = "Usuarios"
Enabled = yes
Type = Backup
Level = Incremental
Client = importante-fd
FileSet = "homes"
Schedule = "Semanal"
Storage = respaldadora-sd
Messages = Standard
Pool = Default
Priority = 10
}
JobDefs {
Name = "Sistema"
Enabled = yes
Type = Backup
Client = importante-fd
FileSet = "sistema sin homes"
Schedule = "Mensual"
Storage = respaldadora-sd
Messages = Standard
Pool = Default
Priority = 10
}
Job {
Name = "Backup Usuarios"
JobDefs = "Usuarios"
Write Bootstrap = "/var/lib/bacula/importante_homes.bsr"
}
Job {
Name = "Backup Sistema"
JobDefs = "Sistema"
Write BootStrap = "/var/lib/bacula/importante_sistema.bsr"
}
FileSet {
Name = "homes"
Include {
File = /home
Options {
signature = MD5
}
}
Exclude {
File = *.avi
File = *.iso
File = *.mp3
File = ~*
File = /home/*/tmp
}
}
FileSet {
Name = "Sistema sin homes"
Include {
File = /
Options {
signature = MD5
}
}
Exclude {
File = /home
File = /var/tmp
File = /var/log
File = /var/cache
File = /var/run
File = /dev
File = /proc
File = /sys
File = /lost+found
}
Schedule {
Name = "Semanal"
Run = Incremental mon-sat at 01:05
Run = Full sun at 01:05
}
Schedule {
Name = "Mensual"
Run = Full on 1 at 01:05
}
Usar este archivo tal cual no es muy recomendable por varias razones, la más importante es que no hace backup del catálogo de bacula, el archivo por defecto de bacula si lo hace; por otro lado, tampoco tiene el trabajo de restauración de ficheros (lo cual puede ser peor...), por tanto coged las partes que os interesen. ;-)
Apéndice B: Comandos útiles en la consola de bacula
El más importante:
*help
;-) ...y después:
*m
Este último te muestra los mensajes que hubiese pendientes, tales como: Job completed o error at XXXX... lo que sea. También podemos ver que tal van las cosas en bácula:
*status
Nos preguntará de qué queremos el estado, le decimos que 4 (all) y listo.
Para saber qué se va a respaldar exactamente podemos estimar el trabajo, fácil:
*estimate
*estimate listing
Primero aparecerá una lista de los trabajos configurados, elegiremos el que queramos estimar, es el primer caso nos aparecerá el número de ficheros que respaldará y cuanto ocupara la copia. En el segundo, a parte de eso, nos saldrán todos los ficheros.
Para mostrar un listado de los volúmenes que tenemos configurados:
*list volumes
Esto mostrará todos los volúmenes del pool actual, cuánto llevan ocupado, retenido, etc. Si queremos saber qué tal van los trabajos también usamos list, pero esta vez:
*list jobs
Nos aparecerá un resumen de lo más chulo: trabajos terminados, erróneos, etc.
Si queremos forzar la ejecución de un trabajo:
*run
Nos aparecerá una lista de trabajos y seleccionaremos el que queramos, automáticamente pasará a la lista de trabajos y de ahí a ejecutarse.
Como véis la consola no es nada difícil... es hasta intuitivo... ;-)
Apéndice C: Recuperar archivos respaldados
Resulta que tenéis vuestro servicio de backup funcionando y (Santa Tecla no lo quiera) resulta que perdéis vuestros ficheros. Pues nada... no preocuparse... arrancamos la bacula console y ejecutamos lo siguiente:
* restore
First you select one or more JobIds that contain files
to be restored. You will be presented several methods
of specifying the JobIds. Then you will be allowed to
select which files from those JobIds are to be restored.
To select the JobIds, you have the following choices:
1: List last 20 Jobs run
2: List Jobs where a given File is saved
3: Enter list of comma separated JobIds to select
4: Enter SQL list command
5: Select the most recent backup for a client
6: Select backup for a client before a specified time
7: Enter a list of files to restore
8: Enter a list of files to restore before a specified time
9: Find the JobIds of the most recent backup for a client
10: Find the JobIds for a backup for a client before a specified time
11: Enter a list of directories to restore for found JobIds
12: Cancel
Select item: (1-12):
Pues nada... seleccionaremos lo que deseemos, una buena opción es la 5: Select the most recent backup for a client, es decir: seleccionar el backup más reciente de un cliente. Seleccionamos esto y nos apareceran los FileSets disponibles:
Automatically selected Client: arco-fd
The defined FileSet resources are:
1: homes
2: Sistema sin homes
Select FileSet resource (1-2):
Ahora seleccionaremos el primero (o el que necesitéis), después de eso bacula buscará en qué cintas está lo que buscamos y se hará sus cuentas (buscará todos aquellos ficheros que deba recuperar) y nos mostrará una shell al estilo bash:
You are now entering file selection mode where you add (mark) and
remove (unmark) files to be restored. No files are initially added, unless
you used the "all" keyword on the command line.
Enter "done" to leave this mode.
cwd is: /
$
Si introducimos help veremos una lista de comandos disponibles, tenemos cd y ls de toda la vida (navegaremos por todos los ficheros posibles para recuperar según lo que eligiésemos). Luego tenemos mark y markdir para marcar (recursivamente) archivos a recuperar, los archivos que con ls aparezca un asterisco delante, significa que está marcado (en caso contrario no está seleccionado para recuperar).
$mark *94,668 files marked.
Con lsmark mostramos sólo archivos marcados. Podemos desmarcarlos con unmark y unmarkdir. También podemos estimar la cantidad de volumen que llevamos marcado con estimate. Cuando lo tengamos todo a punto:
$doneBootstrap records written to /var/lib/bacula/stallman-dir.restore.3.bsr
The job will require the following
Volume(s) Storage(s) SD Device(s)
===========================================================================
cinta0004 stallman-sd Autochanger
94,668 files selected to be restored.
Run Restore job
JobName: RestoreFiles
Bootstrap: /var/lib/bacula/respaldadora-dir.restore.3.bsr
Where: /tmp/bacula-restores
Replace: always
FileSet: Full Set
Client: importante-fd
Storage: respaldadora-sd
When: 2007-03-19 21:02:49
Catalog: MyCatalog
Priority: 10
OK to run? (yes/mod/no):
Si decimos que yes lanzará el trabajo que se ejecutará cuanto antes. Podemos cambiar el directorio destino donde guardará todos los archivos recuperados (en el ejemplo /tmp/bacula-restores) introduciendo mod, en cuyo caso mostrará una lista de parámetros modificables. Hay que decir que este directorio es local a la máquina que ejecuta el client (un bacula file daemon) que aparece en el resumen y que seleccionamos al principio del proceso de restauración.
Pues nada... que dando una vuelta por ahí me he encontrado la página del tipo que hace gráficos para muchos programitas de esos que usamos comúnmente... entre ellos Frozen Bubble. Está chulo pero son un poco "pingüineros"... en fin... por lo menos hay muchísimos temas...
Si alguno es un afortunado poseedor de una tarjeta wifi con chipset Atheros (que es el que viene usando Cisco) debéis saber que todo un mundo de diversión inalámbrica está a vuestro alcance ;-)
Esta receta describe la consola portátil GP2X y da una primera idea de sus posibilidades dentro del mundo del software libre
Introducción
Antes de empezar con la receta diré que esto no es en realidad una receta... :-P es algo así como un review. El soft libre tiene un mercado que avanza muy rápidamente y prueba de ello está en que cada vez más dispositivos vienen con un Linux integrado y se basa en soft libre. Hace tiempo, la empresa koreana Game Park Holdings sacó una consola portátil llamada GP32.
Esa consola vio muy pocos juegos comerciales porque la gente se dedicó a desarrollar homebrew para dicha consola. Viendo el "éxito" especial que tuvo esta consola, meses después se decidió a sacar una nueva consola, la GP2X, mucho más potente que su antecesora (de hecho se compara con la Nintendo DS) y directamente para que la gente desarrolle para ella.
Se ha denominado "la portátil opensource" (aunque en realidad GamePark Holdings apuesta muy poco por el GPL y el soft en general... como veremos a continuación...). Sea como fuere aquí pretendo contar un poco mis primeras experiencias con esta consolilla para dejar esta receta como "introducción" a una serie de recetas que, espero, sean más "divertidas" que ésta...
El hardware
Bueno, básicamente disponemos de un sistema basado en dos procesadores ARM, 32M de RAM y otros 32M de flash interna, socket para tarjetas SD, puerto USB 2.0, pantalla LCD de 320x240, joystick digital, 10 botones y unos cuantos puertos interesantes como son el de TV-OUT o el JTAG.
El main core (llamado MagicEyes o MP2520F) tiene como núcleo dos CPU's que van a 200MHz (dopables):
ARM920T (Rev 1)
ARM940T (Rev 2)
El que ejecuta la chicha, (o host) es el ARM920, el otro se emplea para el tratamiento de gráficos 2D y "cierta" aceleración 3D. Antes de que alguno pregunte porqué no se usan los dos en modo SMP hay que decir que el ARM940 viene sin MMU y tiene algunas instrucciones especiales para el acceso a la memoria, por eso no se ha portado un núcleo SMP para este micro.
El controlador de USB es un NET2272 con soporte para Microsoft’s Media Transfer Protocol (MTP), es decir: DRM (nos han chuleao!!).
Para la salida de TV dispone de un CX25784, que genera señales PAL y NTSC de hasta 720x480. Hay que decir que la consola no tiene un conector para enchufar directamente la tele, hay que comprarse un cable...
En cuanto al audio... un chip AC'97 llamado WM9711L bastante chulo.
El software
Pues un Linux de toda la vida, concretamente un 2.4.25 compilado con gcc 2.95.3, es el núcleo que ejecuta la maquinita. Viene con una mínima cantidad de módulos. En el gestor de eventos encontramos a hotplug.
En cuanto a librerías, tenemos unas cuantas: libSDL (incluyendo SDL_image, SDL_mixer y SDL_ttf), libjpeg, libncurses (¿para qué?), libogg, libpng, libvorbisdec, a parte de librerías típicas del sistema.
Tenemos unas cuantas utilidades GNU como grep, fgrep, egrep, doexec, fdisk, ftp, hostname, ipcalc, netstat, nohup, who, etc...
Viene con servidores típicos como telnetd (q miedo!), ftpd, samba, thttpd, etc.
Una utilidad interesante que trae es el mplayer de toda la vida, portado y GPL (no tienen más remedio, les obliga la licencia...). Después viene un reproductor de música y un visualizador de imágenes y texto y los... impresentables de GPH no lo tienen liberado (al igual que el menú de la consola)... me parece una cutrez pero bueno.
Cómo funciona
Muy simple, dispone de un cargador del núcleo (tipo lilo o grub) llamado U-BOOT que soporta múltiples plataformas. El cargador arranca el linux y comienza un arranque como el de cualquier otro sistema basado en GNU/Linux, salvo que no hay más que un runlevel y un único usuario. El último comando del script de arranque es el menú de la GP2X (que no es más que un ejecutable como otro cualquiera).
Primeros cacharreos
Lo más básico que podemos hacer: conectarnos por puerto serie y ver "qué hace" la consola. Fácil: utilizad algún programa como minicom (paquete Debian) y configurad el puerto de la siguiente forma:
115200 8N1
Ahora encendéis la consola y (con el último fw, 2.1.1 a fecha de hoy) saldrá:
U-Boot 1.0.0 (Apr 20 2006 - 12:51:09)
U-Boot code: 03E00000 -> 03E49610 BSS: -> 03E82208
IRQ Stack: 03ea3204
FIQ Stack: 03ea4204
DRAM Configuration:
Bank #0: 00100000 63 MB
Flash: 0 kB
NAND:Probing at 0x9c000000
Flash chip found:
Manufacturer ID: 0xEC, Chip ID: 0x76 (Samsung K9F1208 64Mb)
1 flash chips found. Total nand_chip size: 64 MB
Get Environment from NAND offset 0x70000 ...
*** Warning - bad CRC, using default environment
In: serial
Out: serial
Err: serial
NAND read: device 0 offset 0x1a0000, size 0x40000 ... 262144 bytes read: OK
NAND read: device 0 offset 0x80000, size 0xb0000 ... 720896 bytes read: OK
### main_loop: bootcmd="bootm"
Hit any key to stop autoboot: 0
## Booting image at 01000000 ...
Image Name: GP2X-F100 2.1.1
Created: 2006-10-30 8:12:53 UTC
Image Type: ARM Linux Kernel Image (gzip compressed)
Data Size: 618462 Bytes = 604 kB
Load Address: 00008000
Entry Point: 00008000
Verifying Checksum ... OK
Uncompressing Kernel Image ... OK
Starting kernel ...
MMC/SD Card Detected
MMC/SD Slot initialized
Partition check:
mmcsda: p1
Register SD: 976MsB
mount...1
mount...2:
Reading data from NAND FLASH without ECC is not recommended
Freeing init memory: 280K
INIT: version 2.84 booting
\<7\>**\>\>ecc error unfixed on chunk 3268:0
Started device management daemon v1.3.25 for /dev
\<7\>**\>\>ecc error unfixed on chunk 3844:0
Mount image directory, if not mounted...
You must set heads sectors and cylinders.
You can do this from the extra functions menu.
You must set heads sectors and cylinders.
You can do this from the extra functions menu.
Partition table size is 4096
Loopback device setup...
losetup: ioctl: LOOP_CLR_FD: No such device or address
MSDOS FS: IO charset utf8
MSDOS FS: IO charset utf8
Apply LCD Timing
Using /lib/modules/2.4.25/kernel/drivers/usb/gadget/net2272.o
net2272: Set 2272 bus timing
USB SUSPEND MODE
net2272: PLX NET2272 USB Peripheral Controller
net2272: irq 222, mapped mem c280c000, chip rev 0011
net2272: running in 16-bit, byte normal bus mode
net2272: version: 2006 April 5, v3
net2272: unbind
Si estamos conectados por el puerto serie, podemos usar las siguientes teclas para controlar la consolilla:
I --> Joy UP
J --> Joy LEFT
K --> Joy DOWN
L --> Joy RIGHT
Intro --> Joy CENTER
D --> Vol -
F --> Vol +
Q --> L
E --> R
W --> Y
A --> A
S --> B
Z --> X
C --> Select
V --> Start
Conclusiones
Pues, aunque tiene muchas cosas mejorables (sobre todo en la parte soft), este dispositivo parece muy interesante y puede tenernos muchas horas y horas entretenidos cacharreando con él... hay hasta un X11 para la consola;y si no nos gusta cacharrear hay que decir que tiene muchísimos emuladores portados al sistema y cómo no... el mplayer en el bolsillo ;-).
Hola buenas... recientemente tuve que realizar la documentación de una práctica y por la cosa de coger soltura la realice 100% en LaTex. Como tenía que hacer diagramitas chulos y tal me puse a buscar que extensión podía ayudarme y encontré una maravillosa: xymatrix. Espero que esto sea un "primeros pasos" de xymatrix ya que la potencia (como todo lo que rodea al LaTex) es increíble y el límite lo ponemos nosotros.
Ingredientes
Para trastear con la receta os hará falta:
Unos conocimientos muy mínimos de LaTex.
Tener instalado LaTeX/TeTeX.
Un buen Makefile y/o rubber.
Excepto el primer requisito... todo es paquete Debian.
Instalación de xymatrix
Instrucciones para Debian (y supongo que Ubuntu):
#apt-get install tetex-extra
Instrucciones para otras distros: ¿hay otras? :-P
El preámbulo
Bueno, sabréis que un documento en LaTex debe tener un pequeño preámbulo donde se define qué tipo de documento se está creando, paquetes que se emplearán, etc. Lo que yo uso para añadir y configurar xymatrix es:
Pero esto provocaba que no se me dibujasen las flechitas.
Crear una matriz
Pues nada, vamos a crear una matriz de 2x2 con los elementos A, B, C y D:
\[ \xymatrix{
A & B \\
C & D}
\]
Activamos el modo matemático (con "\[" y "\]"), en él insertamos un elemento xymatrix con los elementos citados. Los elementos de una columna los separamos con ampersand, es decir "&", y una nueva fila con la doble barra, "\\". Que yo lo haya puesto en distintas líneas en el código ha sido para que se vea más claro, pero podríamos haber hecho:
\[\xymatrix{A&B\\C&D}\]
Los ejemplos anteriores habrían dado como resultado:
La dimensión de una matriz se calcula por el número de columnas de la primera fila y después el número de filas creadas. Esto es importante, todas las filas tienen que tener el mismo número de columnas. Si por ejemplo nuestra matriz no va a tener elemento C debemos hacer lo siguiente:
\[\xymatrix{
A & B \\
& D}
\]
Recordad que podemos hacer cosas como:
\[\xymatrix{
A && B & C}
\]
En este caso tendríamos una matriz fila de cuatro elementos, en el que el segundo elemento es nulo. Podéis ver como quedaría aquí:
Como último ejemplo de matriz vamos a definir:
Debemos hacer una matriz de tres filas y cinco columnas. ¿Por qué cinco? pues tenemos tres elementos y dos huecos entre ellos en la fila con más columnas de todas. Quedaría como sigue:
\[\xymatrix{
& &1& & \\
&2& &3& \\
4& &5& &6}
\]
Los huecos entre ampersand's los coloco para que se vea más claro, pero podría haber escrito:
\[\xymatrix{
&&1&&\\
&2&&3&\\
4&5&6}
\]
O incluso:
\[\xymatrix{&&1&&\\&2&&3&\\4&5&6}\]
El manual de xy tiene los ejemplos en la segunda forma, por lo que más vale entender esto bien, incluso practicarlo un poco. Yo en ejemplos más complicados tuve que usar lápiz y papel para entenderme (menudo informático de pacotilla! :-P). Entendiendo esto bien podemos pasar al siguiente punto: la flechas entre elementos.
Las flechitas
Bien, las flechas tienen un origen y un destino (ohhh), el origen es el elemento donde se crea y el destino es el elemento que le indicaremos nosotros. Todas las flechas tienen dirección por lo que si queréis una bidireccional entre A y B (por ejemplo) debéis crear una entre A y B y otra entre B y A (esto creo que debería estar en el TO-DO de xy).
La forma en la que indicamos el elemento destino es indicando su desplazamiento con respecto al elemento origen. Los desplazamientos se indican con una letra: u,d,l,r; esto es: up, down, left, right (vaaaale: arriba, abajo, izquierda y derecha :-P). Por tanto, si queremos una flecha desde un elemento hasta el siguiente elemento a la izquierda, lo indicaríamos con [l]. Si queremos una flecha desde un elemento hasta el elemento dos lineas mas arriba y una columna más a la derecha pues [uur]. Al principio puede parecer lioso, pero veamos un ejemplo: en la matriz de ejemplo primera, la de 2x2, vamos a hacer un triángulo de flechas entre los elementos A, B y D con el sentido de las agujas del reloj, es decir, lo siguiente:
Pues el código es muy simple:
\[ \xymatrix{
A \ar[r] & B \ar[d]\\
C & D \ar[ul]}
\]
Veamos: con \ar añadimos una flecha, un elemento puede tener todas las que quiera, los destinos pueden ser elementos vacíos y tiene que estar obligatoriamente dentro de los límites de la matriz, en caso contrario no compilará. Si no entendéis bien el ejemplo, dibujad en un papel un cuadro de 2x2 y observad los desplazamientos. Ahora vamos a crear una matriz fila de tres elementos: A, B y C, uniremos todos de forma cíclica, es decir: A con B, B con C y C otra vez con A:
\[\xymatrix{
A \ar[r]& B \ar[r]& C \ar[ll]}
\]
Si compiláis veréis lo siguiente:
Deberíamos poder arquear la flecha para que esto no ocurra, es decir, queremos obtener lo siguiente:
Pues el código es muy simple, simplemente debemos añadir lo siguiente:
\[\xymatrix{
A \ar[r]& B \ar[r]& C \ar@/^/[ll]}
\]
Para arquear una flecha añadimos la arroba al final de ar después viene lo siguiente: "/^/" indica cómo debe ser el arco. La concavidad/convexidad es relativa a la dirección de la flecha, "/^/" lo hace de una forma y "/_/" de la otra. También podemos aumentar la curvatura: "/^1pc/", "/^2pc/", etc.
Algunos ejemplos
Hasta aquí supondré q lo entendéis todo bien e incluso lo habéis probado. Si no entendéis bien lo anterior... esto os va a resultar algo extraño...
Vamos a dibujar cuatro elementos formando un cuadrado pero con un quinto elemento central, todos los elementos exteriores tendrán una flecha hacia el elemento central:
\[\xymatrix{
A \ar[dr]& & B \ar[dl] \\
& E & \\
C \ar[ur] & & D \ar[ul]}
\]
Que resulta en lo siguiente:
Ahora vamos a dibujar un cubo, para saber cómo debemos representar un cubo mediante una xymatrix os recomiendo el uso de lápiz y papel... tal vez este ejemplo empiece a ser un poco extraño... ;-)
\[\xymatrix{
& E \ar[rr]&& F \ar[dd]\\
A \ar[rr]\ar[ur]&& B \ar[dd]\ar[ur]&\\
& G \ar[uu]&& H \ar[ll]\\
C \ar[uu]\ar[ur]&& D \ar[ll]\ar[ur]&}
\]
Con lo que obtendríamos un bonito:
Y finalmente una rayada: no voy a decir de que se trata para que a alguno le pique la curiosidad y lo pruebe :-P .Sólo diré que de la figura completa hay cuatro aristas curvadas para que no se emborrone el resultado final. Además, hay un elemento más que complica el ejemplo: todas las flechas son bidireccionales ;-), en fin, ahí tenéis:
Si entendéis este ejemplo podréis hacer cualquier otra cosa de este tipo. El manual de xymatrix es todavía mas rayante...
Enlaces de interés
Manual de xymatrix
Y como siempre que escribo una receta...
Manual de xypic
Lo de xypic no lo conocía pero parece que es bastante mejor que xymatrix... habrá que echarle un ojo ;-)
Recientemente ha caído en mis manos un juguetito muy chulo: un kit de conexión a banda ancha móvil... me he pasado unas cuantas horas pegándome con un sinfín de recetas y módulos hasta conseguir la dichosa conexión... que va freshhquísima... aquí viene un resumen de mis periplos...
Es un poco vieja por lo que supongo que todos lo sabrán ya... me gustaría saber si a día de hoy seguiría diciendo lo mismo...
En resumen: Bill Gates: "nunca he tenido virus en mi ordenador".
Lo que no dice es el sistema operativo que usa... :-P
Todos conocemos Apache, un servidor web con muchos modulos, muchas cositas, muy usado, muy bueno, muy todo... pues bien, un programador de por aquí se decidió por crear un nuevo servidor web, más ligero y rápido y con la misma funcionalidad básica que apache: SSL, PHP, CGI y todas esas cosas que podemos pedir de un servidor Web normalito. Otra ventaja de cherokee es que es menos "atacado" que el apache, por tanto se conocen menos fallos. En fin, que vamos a explicar como habilitar el https en cherokee.
Configuración de cherokee
Sólo diré que la configuración es muy similar al de apache, el objetivo de esta receta no es explicar como configurar cherokee, sino simplemete una opción del mismo. Por tanto os remito a la documentación que tendréis en /usr/share/doc/cherokee cuando instaléis el paquete. Lo que si que voy a decir (y que conviene tener en cuenta) es que cuando cambiéis algo en la configuración, al reiniciar el servidor, en caso de error, no obtendréis ningún mensaje de error y el servicio no arrancará. Para probar los cambios es mejor arrancar el servidor "a lo bruto", es decir:
#/usr/sbin/cherokee
Así obtendréis mensajes de error y veréis si arranca o no. En fin, al trabajo...
Certificados
Es necesario crear una certificación para los sitios seguros, por eso de que sea un sitio confiable o no, etc. Por tanto, antes de nada debemos crear el nuestro propio, si tenemos los certificados creados para el apache, en /etc/apache2/ssl/apache.pem podemos usarlo directamente en el cherokee copiando el archivo en /etc/cherokee/ssl/cherokee.pem. Si necesitamos crear una certificación nueva, necesitaremos el paquete openssl y debemos hacer lo siguiente: crearemos un certificado CA, después deberemos crear una petición de certificación y finalmente firmaremos el certificado, esto se hace directamente en tres pasos:
/usr/lib/ssl/misc/CA.pl -newca
Introduciremos los datos que nos pidan (frase secretam etc.); esto generará un certificado CA, pero que todavía debemos firmar. Ahora creamos la petición de certificación:
$/usr/lib/ssl/misc/CA.pl -newreq
Introduciremos los datos que nos vaya pidiendo. Con esto habremos obtenido una firma digital para nuestro certificado, ahora lo firmamos:
$/usr/lib/ssl/misc/CA.pl -sign
Ya tenemos nuestro nuevo certificado firmado y listo para usar con cherokee (o apache) en un archivo pem. Lo copiamos a /etc/cherokee/ssl y lo llamamos cherokee.pem. Ahora sólo nos falta activar ssl en el cherokee.
Activar módulos
Habilitar/deshabilitar módulos es tan fácil como en apache: tenemos los módulos instalados en /etc/cherokee/mods-available y para activarlos debemos crear un enlace simbólico del módulo en /etc/cherokee/mods-enabled, es decir:
Buenas, hace poco (hoy) recibí mi flamante nuevo disco duro para el portátil, como paso de reinstalarme todo y me encuentro muy agusto con su actual funcionamiento me decidí a realizar una "migración cutre" de todo el disco al nuevo... puede parecer una tontería (y lo es) pero hay un par de cosas a tener en cuenta...
Esta receta explica cómo instalar y preparar bacula para posteriormente montar un servicio completo de backup. Quizá lo que buscas es cómo configurar bacula para hacer backups.
Muchos de nosotros tenemos en nuestros discos duros información que valoramos de valiosa (otros sólo tienen fotos de choteras y cosas de esas :-P ). Aunque confiemos plenamente en nuestra ext3 y todas esas cosas puede ser que el día menos pensado nuestro HDD decida jubilarse sin consultarnos (¿Hace falta una receta sobre S.M.A.R.T. para conocer de antemano cuando va a decidir jubilarse un HDD?). En fin, me dejaré de tonterías y empezamos con el meollo.
Qué es bacula
Bacula es un programa para hacer copias de seguridad de una máquina... pues no del todo: bacula es una colección de demonios que cooperan entre sí para realizar copias de respaldo de los archivos necesarios, sean de la máquina que sea. Para interactuar con bacula se necesita un elemento más: la consola de bacula. Todos estos elementos son independientes entre sí y pueden estar en máquinas distintas, así pues el principal problema a la hora de configurar bacula consiste en hacer que todos estos elementos se comuniquen correctamente entre ellos.
Los elementos necesarios para que bacula funcione son:
bacula-dir (o bacula-director)
bacula-sd (o bacula-storage daemon)
bacula-fd (o bacula-file daemon)
Si, como es de suponer, queremos poder interactuar con el servicio de backup, necesitaremos:
bacula-console (disponible en varios sabores:gnome y wx)
bacula-director
Es el demonio que maneja al resto. El servidor de la base de datos MySQL debe estar accesible desde la máquina que ejecuta el director (o estar en ella misma y escuchar en localhost... como viene siendo habitual en Debian). Debe poder acceder tanto al bacula-sd como al bacula-fd para poder leer los archivos a guardar y para poder guardarlos en el soporte físico final.
En el archivo de configuración del director configuraremos dónde y cómo acceder al resto de demonios, la contraseña para el acceso mediante bacula-console y los trabajos o jobs.
bacula-storage daemon
Este demonio es el encargado de manejar el dispositivo de almacenamiento de los backups; esto exige que este demonio esté instalado en la máquina que contenga físicamente el dispositivo de almacenamiento, que puede ser: archivos en el disco local, grabadoras de CD o DVD y unidades de cinta.
Su archivo de configuración define el (o los) dispositivos de almacenamiento que maneja así como que directores pueden utilizarlo.
bacula-file daemon
Mediante este demonio bacula obtiene los ficheros que necesita respaldar, así pues éste es el componente que hay que instalar en las máquinas que necesiten respaldo.
El archivo de configuración es el más simple de todos, símplemente especifica qué directores pueden realizarle peticiones.
bacula-console
Una vez instalado y configurado bacula comenzará a realizar copias de seguridad el solito sin intervención nuestra, pero puede suceder que queramos forzar una copia cuando nosotros lo deseemos, o que tengamos que recuperar unos ficheros (protégenos Santa Tecla) o símplemente saber qué tal está nuestro bacula. Para ello necesitamos este componente, similar a una shell pero con pocos comandos (resulta hasta intuitivo... en serio...). Existen varios tipos de consolas: en modo texto, para gnome, con widgets wx, etc. Supongo que también existirán clientes gráficos que no tengan nada que ver con una consola y que harán lo mismo... yo por ahora no he buscado ninguno... :-P
Qué necesitamos
Bueno, bacula necesitará de una base de datos SQL para apuntar sus cosillas, así pues es necesario tener instalado y configurado MySQL.
No es obligatorio pero si muy recomendable que todas las máquinas que intervengan en el proceso sean accesibles por un nombre de dominio (o tengan IP estática).
Si tenemos nuestra base de datos lista ya podemos instalar en la máquina que realizará los backups los siguientes paquetes:
#apt-get install bacula-director-mysql
Bueno, hay que decir que exiten más versiones del director: pqsql (para postgress SQL, sqlite y sqlite3 (imaginad...). En la instalación del director os pedirán los datos necesarios para configurar la base de datos que necesitará bacula. Es muy sencillo y si os equivocáis simplemente haced:
#dpkg-reconfigure bacula-director-mysql
Y arregláis el fallo... zoquetes! :-P
Ahora, en la máquina que tenga nuestra unidad de almacenamiento (una cinta, por ejemplo) y que puede ser la misma o no que la anterior, instalamos lo siguiente:
#apt-get install bacula-sd bacula-sd-tools
Al igual que el director, este componente también tiene más alternativas: mysql, pgsql, sqlite y sqlite3. Usaremos el simple porque nuestro director ya se encargará de crear catálogos y todo eso, no es necesario que nos los cree también el storage daemon.
Finalmente, instalaremos lo siguiente en la máquina que queramos respaldar:
#apt-get install bacula-fd
Ahora sólo nos faltará configurar todo esto para que se comuniquen entre sí... vamos a ello!
Atención: Debian unstable instala la versión 1.38.11-7 (a fecha de 6 de feb, 2007) y el paquete no consigue configurar correctamente su base de datos. Pasa lo mismo con los paquetes 2.0.1 de la página de bácula. Consulta los apéndices de la receta para más información.
Configurando bacula-fd
Por ser más simple será el primero que configuremos, echemos un vistazo a su archivo de configuración (/etc/bacula/bacula-fd.conf):
Director {
Name = director_admitido1
Password = "password_chorrotronica_para_el_director_admitido1"
}
Director {
Name = backup-mon
Password = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
Monitor = yes
}
FileDaemon {
Name = nombre_del_file-daemon
FDport = 9102
WorkingDirectory = /var/lib/bacula
Pid Directory = /var/run/bacula
Maximum Concurrent Jobs = 20
FDAddress = maquina.dominio # O si tiene IP estatica pues X.X.X.X
}
# Esto es nuevo en bacula 2.0.0
Messages {
Name = Standard
director = director_admitido1 = all, !skipped, !restored
}
Vemos que los archivos de configuración tienen una estructura que se repite:
nombre_resource {
opcion = valor
...
}
Es lo que en bacula llaman resources. Un resource define un elemento de bacula, hay muchos tipos de resources diferentes, cada uno con sus propias opciones. El manual describe detalladamente todos ellos... ;-)
En este archivo hemos definido tres tipos de resources distintos:
Director: Identifica qué director puede conectarse con este file daemon; como veis se definen dos: director_admitido1 y backup-mon. El segundo es un director especial que actúa de monitor... se configura automáticamente. El primero es el que hemos añadido/modificado nosotros. El nombre que especificamos es el nombre que hemos dado a nuestro director (lo veremos más adelante) y la password es la que se espera que dé cuando se autentifique.
FileDaemon: Define los parámetros del propio file daemon, parámetros como el puerto de escucha o la IP a la que debe asociarse (recordad que si esa IP es 127.0.0.1 el demonio sólo aceptará conexiones de la propia máquina local). Como véis también especifica el nombre que se da a nuestro file daemon, es importante que coincida con el nombre que luego introduciremos en el director.
Messages: Indica qué mensajes podemos enviar a cada director.
Una vez modificado el archivo reiniciaremos el demonio y lo tendremos listo para funcionar con bacula, ahora vayamos con el siguiente.
Configuración de bacula-sd
Abramos su archivo de configuración (/etc/bacula/bacula-sd.conf) y veamos sus resources (este es una modificación del "original", para utilizar como almacenamiento un carrusel automático de cintas con seis slots):
Storage {
Name = nombre_del_storage-daemon
SDPort = 9103
WorkingDirectory = "/var/lib/bacula"
Pid Directory = "/var/run/bacula"
Maximum Concurrent Jobs = 20
SDAddress = maquina.dominio
}
Director {
Name = director_admitido1
Password = "password_chorrotronica_para_el_director_admitido1"
}
Director {
Name = backup-mon
Password = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
Monitor = yes
}
Device {
Name = FileStorage
Media Type = File
Archive Device = /tmp
LabelMedia = yes; # lets Bacula label unlabeled media
Random Access = Yes;
AutomaticMount = yes; # when device opened, read it
RemovableMedia = no;
AlwaysOpen = no;
}
Autochanger {
Name = Autochanger
Device = Tape1, Tape2, Tape3, Tape4, Tape5, Tape6
Changer Command = "/etc/bacula/scripts/mtx-changer %c %o %S %a %d"
Changer Device = /dev/sg2
}
Device {
Name = Tape1
Drive Index = 0
Autochanger = yes
Media Type = DDS-4
Archive Device = /dev/nst0
AutomaticMount = yes
RemovableMedia = yes
RandomAccess = no
AutoChanger = yes
LabelMedia = yes
}
...
Device {
Name = Tape6
Drive Index = 0
Autochanger = yes
Media Type = DDS-4
Archive Device = /dev/nst0
AutomaticMount = yes
RemovableMedia = yes
RandomAccess = no
AutoChanger = yes
LabelMedia = yes
}
Messages {
Name = Standard
director = director_admitido1 = all
}
Storage: Como antes, se define así mismo y qué parámetros usar.
Director: Igual que en el file daemon.
Device: Especifica un dispositivo de almacenamiento manejado por el storage daemon. El nombre que se le da aquí y el tipo de medio es el que luego necesitaremos usar en el director. Es importante aclarar que si tenemos un dispositivo de cintas con una sola unidad no será necesario definir tantos "devices" como cintas tengas, ya que todas serán cargadas por el autochanger
Autochanger: Es un Device especial que define un cargador automático de cintas. Se debe indicar el comando a emplear para usar el cargador.
Existen muchísimos parámetros para los resources de tipo device pero no es objetivo de la receta crear un manual de bácula en castellano... así que... al manual... :-P
Configurando bacula-director
Este es el archivo más complicado... pero que sólo veremos "a medias", la "otra mitad" se queda para una próxima receta.
Veamos la parte que nos interesa ahora, tenemos esto en el fichero /etc/bacula/bacula-dir.conf:
Director {
Name = director_admitido1
DIRport = 9101
QueryFile = "/etc/bacula/scripts/query.sql"
WorkingDirectory = "/var/lib/bacula"
PidDirectory = "/var/run/bacula"
Maximum Concurrent Jobs = 1
Password = "password_chorrotronica_para_las_consolas" # Console password
Messages = Daemon
DirAddress = 127.0.0.1 # Esto sólo vale para las consolas
}
[... cosas interesantísimas que ahora no vienen a cuento ...]
Client {
Name = nombre_del_file-daemon
Address = maquina.dominio
FDPort = 9102
Catalog = MyCatalog
Password = "password_chorrotronica_para_el_director_admitido1" # pwd for FD
File Retention = 30 days # 30 days
Job Retention = 6 months # six months
AutoPrune = yes # Prune expired Jobs/Files
}
Storage {
Name = File
Address = maquina.dominio
SDPort = 9103
Password = "password_chorrotronica_para_el_director_admitido1"
Device = FileStorage
Media Type = File
}
Storage {
Name = nombre_del_almacenamiento
Address = maquina.dominio
SDPort = 9103
Password = "password_chorrotronica_para_el_director_admitido1"
Device = Autochanger
Media Type = DDS-4
Autochanger = yes
}
Catalog {
Name = MyCatalog
dbname = bacula; DB Address = "" ; user = bacula; password = "XXXXX"
}
[...cosas tremendamente interesantes que ahora tampoco explicaremos...]
Como este tiene más chica, explicaremos resource a resource más despacito.
Director
Igual que en los casos anteriores, se define a sí mismo, los campos habituales son:
Name: Nombre que damos al director. Es el mismo nombre que hemos permitido en los otros demonios.
DIRport: Puerto de escucha para las consolas.
QueryFile: Archivo con las consultas a la bbdd.
WorkingDirectory: Directorio de trabajo (no cambiar).
PidDirectory: Directorio donde crear los archivos con pid.
Maximum Concurrent Jobs: Número máximo de trabajos concurrentes que acepta. En los casos anteriores teníamos un valor mayor a 1, esto permitirá que varios directores utilicen esos demonios a la vez. Establecer aquí este valor a 1 implica que el director sólo hará un trabajo cada vez, que es el valor por defecto.
Password: Contraseña que se pedirá al programa de consola. Esta contraseña no se pide por teclado sino que también se almacena en el archivo de configuración del programa de consola.
Messages: Donde se enviarán los mensajes no asociados a un trabajo concreto.
DirAddress: Dirección donde escuchará el director. Indicar 127.0.0.1 implicará que no podrán abrirse consolas bacula en máquinas remotas, pero no causa problemas si tenemos los demás demonios en otras máquinas puesto que es el director el que abre las conexiones con los otros demonios.
Client
Aquí especificaremos los datos del bacula file daemon con el que necesitamos conectar para leer los ficheros necesarios. Para ello especificaremos lo siguiente:
Name: Nombre del file daemon. Este nombre no tiene porqué coincidir con el que dimos a nuestro file daemon, es para nombralo dentro de bacula. Mi recomendación es que coincida, más que nada para entendernos mejor.
Address: IP o hostname de la máquina que tiene nuestro file daemon.
FDPort: Puerto donde escucha el file daemon.
Catalog: Qué catálogo usa nuestro file daemon. Un catálogo es algo así como un listado de los ficheros que se están respaldando.
Password: Contraseña que enviará el director al file daemon para autentificarse.
File Retention: Este parámetro indica cuanto tiempo deben permanecer los archivos en el catálogo. Pasado este tiempo se eliminan del catálogo (pero esto no influye en que se haga o no backups de estos ficheros).
Job Retention: Indica cuanto tiempo como máximo estará un trabajo esperando.
AutoPrune: Si está a yes, una vez pasados los periodos File Retention y/o Job Retention se eliminan del catálogo y/o cola los ficheros/trabajos.
Storage
Ahora especificaremos los dispositivos que podrá emplear bacula para hacer las copias de respaldo, pueden existir varios (que se diferenciarán por el nombre). Debemos indicar los siguientes campos:
Name: Nombre del medio de backup. No es el nombre del storage daemon sino del medio, por ejemplo: Carrusel_cintas o Fichero_local, etc.
Address: Máquina donde está el storage daemon que maneja el medio de almacenamiento.
SDPort: Puerto de escucha.
Password: Contraseña que enviará el director para autentificarse contra el storage daemon.
Device: Nombre del medio configurado en el storage daemon que debemos usar. Como dijimos, el storage daemon configura uno o varios dispositivos de almacenamiento, nombrándolos de alguna manera. Pues ese nombre es el que usamos aquí.
Media Type: Cuando se configura el medio se especifica que tipo de medio es, aquí también tenemos que indicarlo (y debe coincidir). Bacula lo usa para "hacer sus cuentas".
Autochanger: Parámetro opcional, indica si es o no un autocargador.
Catalog
Name: Nombre del catálogo (que usamos en el resource del file daemon).
dbname: Nombre de la base de datos.
DB Address: Máquina donde tenemos nuestro servidor MySQL.
user: Usuario con privilegios en la base de datos especificada anteriormente suficientes como para crear y modificar datos.
password: Password de dicho usuario en esa base de datos.
Bien, con todo esto ya tenemos un sistema bacula distribuido funcionando a las mil maravillas... para comprobarlo podemos hacer lo siguiente:
#apt-get install bacula-console
Y lo configuramos para conectarse a nuestro director modificando /etc/bacula/bconsole.conf:
Director {
Name = nombre_director-dir
DIRport = 9101
address = maquina_director.dominio
Password = "passwordchorrotronicaparalasconsolas"
}
Si todo ha ido bien podremos ejecutar bconsole como root o como un usuario que pertenezca al grupo bacula y teclear lo siguiente:
*status
El asterisco es el prompt de la consola de bacula, ejecutamos status y le decimos que all cuando nos pregunte de qué queremos el estado. Si algún componente no puede contactarse, se notificará con el error correspondiente. Si no obtenemos ninguno de esos errores tenemos el bácula funcionando. Ahora sólo nos queda indicarle qué archivos hay que respaldar y cuando.
Existe un problema que no puede detectarse así y que es muy peligroso: puede suceder que el director pueda comunicarse con el storage daemon y con el file daemon, por tanto dirá que todo esta funcionando; sin embargo, el storage daemon y el file daemon no puedan conectarse entre sí; esto provocará que los backups darán siempre error y no se realizarán. Esto sucede porque cuando el director va a hacer una copia, conecta al file daemon con el storage daemon directamente y ellos dos realizan las transferencias de datos. Debéis tener esto en cuenta cuando pongáis vuestro bacula a funcionar.
Apéndice A: Preparar la base de datos bacula en MySQL
Bueno, como dijimos antes, la instalación de bacula por paquetes no crea la base de datos que utiliza para realizar los backups, así que nosotros haremos ese trabajo "a mano". Vamos a asumir que tenemos correctamente instalado y funcionando MySQL Server y phpmyadmin (tal y como se quedan después de una instalación con apt-get).
La base de datos que debemos crear es la que se especificó en el resourceCatalog que vimos anteriormente, por ejemplo una base de datos llamada bacula (que es la usada por defecto). La creamos con phpmyadmin, también podemos crear el usuario (que por defecto también debe ser uno llamado bacula) con la contraseña que hayamos especificado. Lo único que debemos hacer ahora es crear unas tablillas y listo, la siguiente porción de código SQL (que se puede pegar directamente en phpmyadmin y listo) lo debería resolver (por cierto que está sacado de un script que viene en los paquetes de bacula pero que a mi no me funcionaba):
Ejecutáis eso (como administradores de MySQL si queréis), dáis permisos al usuario bácula en todas esas tablas creadas y ya tenéis la base de datos lista para su uso por parte del director. :-)
Apéndice B: Archivos de configuración de ejemplo
Por último, pondré unos archivos que uso yo y están funcionando, para que veáis unos ya configurados y tal. Las contraseñas debéis cambiarlas (es un consejo). El escenario es el siguiente: tenemos un equipo con cargador de cintas (de tres slots) que hace backup de un segundo equipo. Para no instalar muchas cosas en el segundo equipo (no interferir en su funcionanmiento) lo único que instalaremos en ese equipo es el file daemon. El equipo con el cargador va a tener por tanto el director y el storage daemon. La máquina con el director se llamará respaldadora (192.168.0.2) y de la que queremos hacer backup se llamará importante (192.168.0.1).
Primero instalamos bacula-fd en importante y lo configuramos con este fichero (/etc/bacula/bacula-fd.conf):
Director {
Name = backup-mon
Password = "password_para_backup-mon"
Monitor = yes
}
FileDaemon {
Name = importante-fd # Podria ser cualquier otro nombre
FDport = 9102
WorkingDirectory = /var/lib/bacula
Pid Directory = /var/run/bacula
Maximum Concurrent Jobs = 20
FDAddress = 192.168.0.1
}
Messages {
Name = Standard
director = respaldadora-dir = all, !skipped, !restored
}
Reinciamos el demonio y ya podemos olvidarnos de esta máquina ;-).
Ahora vamos con respaldadora, primero instalamos el storage daemon y lo configuramos con el siguiente arhivo (/etc/bacula/bacula-sd.conf):
Storage {
Name = respaldadora-sd
SDPort = 9103
WorkingDirectory = "/var/lib/bacula"
Pid Directory = "/var/run/bacula"
Maximum Concurrent Jobs = 20
SDAddress = 192.168.0.2
}
Director {
Name = respaldadora-dir
Password = "password_para_respaldadora-dir"
}
Director {
Name = respaldadora-mon
Password = "password_para_respaldadora-mon"
Monitor = yes
}
Device {
Name = FileStorage
Media Type = File
Archive Device = /tmp
LabelMedia = yes;
Random Access = Yes;
AutomaticMount = yes;
RemovableMedia = no;
AlwaysOpen = no;
}
Autochanger {
Name = Autochanger
Device = Tape1, Tape2, Tape3
Changer Command = "/etc/bacula/scripts/mtx-changer %c %o %S %a %d"
Changer Device = /dev/sg2
}
Device {
Name = Tape1
Drive Index = 0
Autochanger = yes
Media Type = DDS-4
Archive Device = /dev/nst0
AutomaticMount = yes
RemovableMedia = yes
RandomAccess = no
AutoChanger = yes
LabelMedia = yes
}
Device {
Name = Tape2
Drive Index = 0
Autochanger = yes
Media Type = DDS-4
Archive Device = /dev/nst0
AutomaticMount = yes
RemovableMedia = yes
RandomAccess = no
AutoChanger = yes
LabelMedia = yes
}
Device {
Name = Tape3
Drive Index = 0
Autochanger = yes
Media Type = DDS-4
Archive Device = /dev/nst0
AutomaticMount = yes
RemovableMedia = yes
RandomAccess = no
AutoChanger = yes
LabelMedia = yes
}
Messages {
Name = Standard
director = respaldadora-dir = all
}
Y finalmente instalamos el bacula director y lo configuramos, muy importante: este archivo no está completo, falta la definicion de trabajos que se explicará en una próxima receta. El archivo es el siguiente (/etc/bacula/bacula-dir.conf):
Director {
Name = respaldadora-dir
DIRport = 9101
QueryFile = "/etc/bacula/scripts/query.sql"
WorkingDirectory = "/var/lib/bacula"
PidDirectory = "/var/run/bacula"
Maximum Concurrent Jobs = 1
Password = "password_para_respaldadora-dir"
Messages = Daemon
DirAddress = 127.0.0.1 # Esto obliga a que las consolas bacula solo se puedan ejecutar desde localhost
}
Client {
Name = importante-fd
Address = 192.168.0.1
FDPort = 9102
Catalog = MyCatalog
Password = "password_para_respaldadora-dir"
File Retention = 30 days
Job Retention = 6 months
AutoPrune = yes
}
Storage {
Name = File
Address = 192.168.0.2
SDPort = 9103
Password = "password_para_respaldadora-dir"
Device = FileStorage
Media Type = File
}
Storage {
Name = respaldadora-sd
Address = 192.168.0.2
SDPort = 9103
Password = "password_para_respaldadora-dir"
Device = Autochanger
Media Type = DDS-4
Autochanger = yes
}
Catalog {
Name = MyCatalog
dbname = bacula; DB Address = "" ; user = bacula; password = "password_de_bbdd"
}
Messages {
Name = Standard
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula: %t %e of %c %l\" %r"
operatorcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula: Intervention needed for %j\" %r"
mail = root@localhost = all, !skipped
operator = root@localhost = mount
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Messages {
Name = Daemon
mailcommand = "/usr/lib/bacula/bsmtp -h localhost -f \"\(Bacula\) %r\" -s \"Bacula daemon message\" %r"
mail = root@localhost = all, !skipped
console = all, !skipped, !saved
append = "/var/lib/bacula/log" = all, !skipped
}
Pool {
Name = Default
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 365 days
}
Console {
Name = respaldadora-mon
Password = "password_para_respaldadora-mon"
CommandACL = status, .status
}
Enlaces
El maravilloso manual de bacula: http://www.bacula.org/en/?page=documentation.
Venga... en breve tendréis la segunda y última receta de bacula, con ella ya podréis montar vuestros propios servicios de backup distribuidos con bacula.
En los meses veraniegos los equipos con refrigeracines poco eficientes (como muchos portátiles) sufren unos calentones bastante importates. Puede resultar muy recomendable contar con los sensores de temperatura para, en caso de calentamiento excesivo, dejar el ordenador un rato y ponernos a hacer cosas menos interesantes, como leer un libro o algo... :D
Pues nada... otro script tonto pero que puede ser útil... este script es para bash pero no lo invocaremos directamente... sino que será una opción nueva en nautilus... más cómodo imposible! :D
Sabéis lo que es un CBZ o un CBR?, si no lo sabéis os lo digo: Comic Book Zip y Comic Book Rar. En vez de tener los jpeg's de un comic (o una serie de imágenes) por ahí como si fueran hojas sueltas... los comprimimos en un zip (o rar), le ponemos esa extensión y ya tenemos un comic book :D. Si además os instaláis el paquete comix tendréis un estupendo visualizador de comics en el PC.
Nota: una cosa muy chula (a mi me lo parece) que sucede al instalar comix es que se registran esos dos tipos de fichero y el nautilus te crea unos bonitos thumbs con las portadas de los comics al visitar esos directorios... muy mono...
Muy buenas... hartos ya como estamos de la guerra abierta entre formatos ofimáticos, en los que el ejército enemigo son los propios usuarios y su dejadez, voy a escribir este documentillo para demostrar de una vez por todas porqué el mejor formato ofimático de todos es el de Microsoft Word.
Últimamente todo el mundo por la televisión sale hablando de una cosa difusa que llaman TDT. El nombre de TDT es algo que se inventó algún redactor de T5 por lo visto, lo que llaman TDT es la implementación del DVB-T en el territorio español. Vemos como aparecen en el mercado muchos sintonizadores TDT con HDTV y "nosecuantas" cosas "nuevas"... ¿qué es todo esto? pues vamos a intentar hacer una breve introducción para explicar conceptos fundamentales a ver si todos (incluído yo) nos enteramos un poco mejor... al final un ejemplo de uso: ver la "tele" digital en nuestro escritorio (o en nuestra consola!).
Bien... supongo que quien tenga una PSP y tenga espíritu aventurero (o firmware 1.50) habrá pensado alguna vez hacerse un programita para la PSP... ver su "creación" en semejante aparatejo. Si tenéis una importante empresa y mucho dinero tal vez podáis pedir el SDK oficial a Sony y si a ellos les apetece, poder formar parte de los elegidos capaces de crear pequeñas joyas portables para disfrute de todos (o unos pocos). Por el contrario, si lo único que queréis es sacar el máximo partido posible a algo vuestro, usándolo como más os guste y sin tener que gastaros otra fortuna gracias al software libre (que, además, es gratuito), necesitaremos un SDK... no tan oficial como el de Sony pero que nos permitirá realizar nuestras propias aplicaciones. Eso vamos a intentar, configurar e instalar nuestro propio SDK (o homebrew como se conoce coloquialmente a este tipo de SDK's no oficiales).
Estado del arte
Bien, a partir de ahora llamaremos scene al estado del arte del homebrew, no por hacernos los "guays" sino porque en google obtendréis mejores resultados con "psp scene" que con "psp estado del arte". O dicho de otro modo: así se le llama a este mundillo.
Actualmente disponemos de un completo toolchain para las psp. Esto nos permitirá usar la potencia del gcc para crear ejecutables para nuestras consolas.
Además de programar en C, se han creado intérpretes de LUA y de python por lo que podremos empezar a crear programillas sin tener que meternos de lleno con el gcc. Además se han portado muchas librerías a LUA como por ejemplo SDL, etc. El python también está cada vez menos "verde", etc. De todas formas, aquí explicaremos como instalarnos el pspsdk homebrew, con lo que obtendremos el gcc-psp y los intérpretes de LUA y python así como muchas librerías interesantes tipo SDL. Vamos al trabajo!
Instalación del toolchain
Esto es lo primero y lo principal... sin esto no podemos empezar a hacer nada, nos bajaremos el repositorio de todo el SDK completo que, entre otras cosas, incluye estos scripts (yo uso el normal... no el "sudo"... bastantes emociones tengo ya... ;-)). Antes de instalarlo debemos asegurarnos que tenemos instalados los siguientes paquetes:
automake1.9
bison
dot2tex
doxygen
flex
libncurses5-dev
libreadline5-dev
texinfo
libusb-dev
libgmp3-dev
libmpfr-dev
libreadline-dev
Ahora descargamos el repositorio completo:
$svn co svn://svn.ps2dev.org/psp/trunk
Para ejecutar el script tendremos que establecer algunas variables en el sistema:
Es recomendable dejar fijos estos cambios, para ello (y si no queremos interferir en el resto de usuarios) modificaremos el archivo ~/.bashrc y añadiremos las siguientes líneas:
Ya sólo nos queda ejecutar el script del toolchain:
$cd trunk/psptoolchain
$./toolchain.sh
Bien, esto se descargará todas las herramientas de GNU necesarias, los últimos parches disponibles para ellas, los aplicará, compilará las herramientas y finalmente, las instalará. No hace falta ser root (no debemos serlo) ya que instala todo eso en /usr/local/pspdev y ahí podremos escribir si pertenecemos al grupo staff.
Instalación del homebrew
Tenemos la gran mayoría del homebrew recopilado en el repositorio subversion que descargamos anteriormente, además de unas cuantas librerías y utilidades bastante "entretenidas" (por ejemplo: SDL, prx-tools, etc.).. , sólo debemos compilarlo e instalarlo. No es difícil, es más bien repetitivo.
Ya que tenemos el compilador para psp listo, lo siguiente es compilar el pspsdk, que son las bibliotecas de acceso a los recursos de la psp:
Al igual que antes, no es necesario ser root en ninguno de los pasos, todo se instalará en los directorios de /usr/local/pspdev.
Instalación automática de librerías
Gracias a uno de los sceners que más han contribuído al pspsdk, un tal oopo, tenemos un script que nos descargan y compilan el resto de librerías extra como son zlib, SDL, etc. Para usar este script es necesario tener instalado libtool:
$cd trunk/psplibraries
$./libraries.sh
Esto nos instalará (en este orden): zlib, bzip2, freetype, jpeg, libbulletml, libmad, libmikmod, libogg, libpng, libpspvram, libTremor, libvorbis, lua, pspgl, pspirkeyb, sqlite, SDL, SDL-gfx, SDL-image, SDL-mixer, SDL-ttf, smpeg-psp y zziplib. ¿Suficiente? ;-)
Instalación manual de librerías
Si no queremos instalar todo eso, podemos instalar las que deseemos una a una, a modo de ejemplo vamos a instalar una libreria, aunque el sdk incluye muchas, todas se suelen hacer de igual o similar forma. En cualquier caso, en cada directorio tenéis un fichero README.PSP que os lo explica, así como si la librería tiene dependencias (en cuyo caso hay que compilar e instalar sus dependencias antes). Vamos a instalar SDL, por ejemplo: leemos su archivo README.PSP y encontramos las instrucciones para hacerlo:
Repito que en ningún paso es necesario ser root. Esto instalará las librerías para psp y sus cabeceras. En el README.PSP explican cómo escribir aplicaciones para psp que usen estas librerías, incluyendo las opciones del compilador.
El orden de instalación de las utilidades y las librerías que YO he seguido es el siguiente:
psptoolchain
pspsdk
cppunit
pspgl
SDL
SDL_gfx
jpeg
zlib
libpng
SDL_image
libTremor
libogg
libvorbis
libmikmod (ver parche más abajo)
mikmodlib
cpplibs
SDL_mixer
freetype
SDL_ttf
cal3D
Con esto tendréis toda la versatilidad de SDL al alcance de vuestra psp ;-) (así como otro montón de librerías interesantes).
Nota: libmikmod compila y se instala sin problemas, sin embargo, no se puede usar de forma "automática" en tus compilaciones porque no se ha incluído el programa libmikmod-config. Yo he creado el mio propio que debéis copiar en /usr/local/pspdev/psp/bin (bueno... depende de donde estéis instalando todo, en realidad sería en $(psp-config -p)/bin). Una vez compilado e instalado libmikmod copiáis este archivo y seguís la instalación de las librerías de forma normal.
#! /bin/sh
prefix=`psp-config -P`
exec_prefix=${prefix}
exec_prefix_set=no
usage="Usage: libmikmod-config [--prefix[=DIR]] [--exec-prefix[=DIR]] [--version] \
[--libs] [--cflags] [--ldadd]"
if test $# -eq 0 ; then
echo "${usage}" 1>&2
exit 1
fi
while test $# -gt 0 ; do
case "$1" in
-*=*) optarg=`echo "$1" | sed 's/[-_a-zA-Z0-9]*=//'` ;;
*) optarg= ;;
esac
case $1 in
--prefix=*)
prefix=$optarg
if test $exec_prefix_set = no ; then
exec_prefix=$optarg
fi
;;
--prefix)
echo $prefix
;;
--exec-prefix=*)
exec_prefix=$optarg
exec_prefix_set=yes
;;
--exec-prefix)
echo $exec_prefix
;;
--version)
echo 3.1.11
;;
--cflags)
includedir=${prefix}/include
if test $includedir != /usr/include ; then
includes=-I$includedir
fi
echo $includes
;;
--ldadd)
;;
--libs)
libdir=-L${exec_prefix}/lib
echo $libdir -lmikmod -L`psp-config -P`/lib -L`psp-config \
-p`/lib -lm -lpspvfpu -lpspdebug -lpspgu -lpspctrl -lpspge -lpspdisplay \
-lpsphprm -lpspsdk -lpsprtc -lpspaudio -lc -lpspuser -lpsputility -lpspkernel
;;
*)
echo "${usage}" 1>&2
exit 1
;;
esac
shift
done
DevKit Pro
Gracias a la inestimable ayuda de Paco, disponemos de un paquete debian con la toolchain y el pspsdk completo, como podéis ver en este aviso. Funciona perfectamente, pero no se puede compilar e instalar directamente el resto de librerías puesto que los scripts del homebrew son un poco cutres y hay que maquillarlos un poquito... cuando tenga tiempo intentaré buscar alguna solución...
Conclusiones
Bueno... con esto tendréis un completo entorno de desarrollo para psp. Era el objetivo de la receta. De todas formas falta aún una cosa: crear un archivo EBOOT.PBP listo para su ejecución en la consola. El problema se reduce a tener el Makefile apropiado. Os sugiero que os descarguéis el código fuente del port del maravilloso ScummVM, tiene el mejor Makefile sobre el tema que he visto. De todas formas, si no dáis con ello, se hace una receta y en paz, ok?
Disfruten! :-)
Esta receta no se si tendrá muchas aplicaciones "domésticas", en ella vamos a tratar de crear n máquinas virtuales en una única máquina física. Esto permitirá crear (por ejemplo) n servidores, cada uno con unos servicios determinados en una misma máquina física. Con ello se consigue (entre otras cosas) proteger unos servicios mas "críticos" de otros más "vulnerables" (lo que pase en una máquina es independiente al resto).
Bien, supongamos un procesador MIPS R4000. Si conseguimos un thread de usuario, sería posible de alguna forma conseguir ejecutar código a nivel de kernel desde ese thread?
A estas alturas, con tantas recetas como existen, hay todavía muchas cosas que no podemos hacer o que intentamos rodear para evitar lo inevitable: una compilación del núcleo. Existen por internet muchísimas recetas sobre compilaciones y tal, yo no pretendo hacer una receta completísima, ni tan siquiera completa, sólo pretendo hacer una miniguía del núcleo linux, que sirva como base para recetas más completas o que crezca (con la ayuda de todos) hasta convertirse en una guía útil de compilación de Linux. Así pues, los que no sepáis espero que lo encontréis interesante y no demasiado aburrido y los que ya sabéis leedlo para corregirlo y aportar nuevos apartados y trucos.
Añadir nuevos módulos/drivers
Bueno, este título es incorrecto (intencionadamente). Para los usuarios de sistemas tipo hasefroch 95, XP, etc. os puede resultar más cómodo pensar en los módulos del linux como en los drivers de los dispositivos. Esto no es del todo correcto ya que existen módulos que no hacen la función de drivers. A partir de ahora eliminaremos el calificativo de “drivers” y usaremos “módulos” (más correcto).
Generalmente, la compilación de nuevos módulos no incluídos de serie en el kernel, no requiere de una compilación completa del núcleo, ni tan siquiera tener los fuentes completos (linux-source), simplemente una parte de ellos: las cabeceras (linux-headers). Así pues, para compilar módulos para nuestro núcleo tendremos que instalarnos las cabeceras:
#apt-get install linux-headers-$(uname-r)
Puede que nuestra distro cuente con los fuentes del módulo que queremos instalar, entonces esta receta termina aquí, sólo tenéis que ejecutar modules-assistant y seguir las instrucciones. Si el módulo es “extraño” y los fuentes no vienen “de serie”, tendrán instrucciones apropiadas, que generalmente se resumirán en:
$make
#make install#depmod -ae
(Notad que el primer make se hace como usuario, el install y el depmod como superusuario) Todos los modulos se relacionan entre si por sus dependencias, esto es: para cargar un módulo se requiere cargar otro previamente (lógico). Con depmod volvemos a calcular todas esas interdependencias, siempre que añadáis un módulo (o lo eliminéis) ejecutar esa línea para actualizar cambios.
Instalar un módulo en realidad es copiar un fichero .ko en el directorio /lib/modules/$(uname -r)/ (y ahí se puede poner en cualquier subdirectorio, depmod los recorrerá todos).
Normalmente los módulos suelen compilarse e instalarse así sin ningún problema, pero los hay más rollazos y puede ser que necesitemos parchear nuestro kernel.
Esto es otro cantar.
Parcheando Linux
Diversos motivos pueden llevarnos al parcheo de un núcleo, el más común será el de instalar un módulo nuevo.
Para parchear el kernel necesitaremos los fuentes (aquí no nos sirve uname -r porque los paquetes no nombran las revisiones del núcleo):
Si el parche no está en el repositorio oficial de la distribución vendrá con las oportunas intrucciones de uso, leedlas y que la fuerza os acompañe. Si el parche si está en vuestra distro, se instala, por ejemplo:
#apt-get install kernel-patch-mppe
Estos parches tienen una forma automática de aplicarse:
Pero existe una forma mejor que se explicará más adelante…
Configurando un Linux
Antes de compilar un kernel debemos configurar sus parámetros, son muchos y una gran cantidad de ellos no sabremos para qué sirven (la dura realidad). Normalmente deberemos modificar algún que otro parámetro para ajustarlo a las necesidades de algún módulo o programa. Entonces… ¿cómo hacemos para no cambiar todas las opciones al tuntún?… fácil, en /boot/config-$(uname -r) tenemos la configuración de los parámetros actuales del kernel en ejecución. Para que nuestro núcleo use esos parámetros haremos lo siguiente:
Con esto asumimos que el linux en ejecución tiene una versión 2.6.14, no es muy recomendable usar archivos de configuración para versiones distintas, sobre todo porque os faltarán parámetros. Una vez copiado este archivo procederemos a cambiar los parámetros apropiados, esto es, reconfigurarlo:
#cd /usr/src/linux-source-2.6.14
#make menuconfig
o también:
#make xconfig
La primera opción requiere tener instaladas las librerias de desarrollo de ncurses y la segunda (más bonita) las de qt. Modificaremos los parámetros y finalmente salvaremos la configuración en el archivo .config.
Finalmente la compilación
Bueno, la compilación a la antigua se hace muy fácilmente:
#cd /usr/src/linux-source-2.6.14
#make
Si el parche se aplicó bien y el núcleo esta bien configurado se compilará todo tranquilamente. Eso si… obtendremos una gran cantidad de archivos binarios que no podremos utilizar para nada, la forma correcta de compilarlo será usando el programa kernel-package:
Esto creará un paquete .deb con nuestro nuevo núcleo, que podremos instalar y (teóricamente) usar.
Hacerlo todo junto en un sólo comando
Si tenemos el Linux sin parchear (pero configurado como se ha explicado antes) podemos parchearlo y compilarlo todo de una forma fácil; supongamos que tenemos instalado el parche mppe como se dijo anteriormente, para hacerlo todo de una basta con teclear:
Además, si quedó algún nuevo parámetro por configurar (debido al resultado de aplicar el parche) se pedirá por consola su valor. Normalmente, cuando se pregunta por el soporte de un módulo en el núcleo las opciones son: Y, N y M. Si se responde Y el módulo será incluído en la misma imagen del núcleo, esto aumenta la velocidad de carga pero también aumenta el consumo de memoria (el núcleo ocupa más). Si se responde N el núcleo no soportará esa característica (estad seguros cuando eliminéis algo!) y lo más normal M que creará un módulo para soportar dicha característica.
Enlaces de interés
La lista podría ser enorme, pero vamos a poner unos pocos (añadid vosotros los que queráis):
En fin… creo que esto es todo lo que quería contar hasta ahora, el tema es muy extenso (sólo echad un ojo a make-kpkg) hay muchas cosas que se puedan hacer… bastante será que lo que haya aquí no contenga errores… así que espero que poco a poco se puedan añadir más cosillas y las que hay se corrijan y mejoren.
Madremia... esta web cada vez está más chula! quien es el artífice de todos estos nuevos cambios?? voy a tener que ponerme un poco al día de todo esto del drupal, el php, el internet y los ordenadores. Que están llenos de cositas que no vemos y que son de mírame y no te menees!!
Bueno... si tenéis la suerte de contar con una PSP os habréis fijado que aunque la scene pertenece casi por completo al mundo GNU/Linux, las utilidades para PC relacionadas con la PSP suelen ser para sistemas windoze/hasefroch. La razón es muy simple: en GNU/Linux no nos hacen falta programas extraños... lo tenemos todo a nuestra disposición, así que... manos a la obra!
El soporte USB de linux y nuestra PSP
Pues nada, enchufad la PSP a algún USB de nuestro PC, ahora, en la PSP activáis el Modo Conexión USB. Si al cabo de unos segundos ejecutáis:
$dmesg
Veréis que al final aparecerá un nuevo dispositivo USB de Sony... ¿adivináis cuál? pues si... la PSP funciona perfectamente como USB Mass Storage Device, así que ya sólo nos falta montarlo.
Montar correctamente la PSP
Tal vez se monte automáticamente la PSP al enchufarla, también veréis que podéis montarla directamente como VFAT sin más, sin embargo, esto puede traeros problemas porque los nombres de ficheros en la MemoryStick deben tener la misma capitalización que se espera de ellos, esto es: si un archivo tiene que tener su nombre en mayúsculas, hay que ponerlo así o no funcionará. Si usáis la PSP tal cual se monta automáticamente o como dispositivo VFAT veréis que si creáis un fichero con todas sus letras en mayúsculas luego con ls aparece en minúsculas (aunque en realidad, en la MS sí se grabó en mayúsculas). Para evitar este pequeño lío añadiremos la siguiente fila al archivo fstab:
Debéis crear el directorio /mnt/psp o podéis usar /media/psp, como queráis. Como véis, lo montamos como VFAT pero especificando que los nombres cortos se usarán al estilo de Hasefroch95 y respetando la capitalización del sistema de ficheros. Bien, ahora ya podemos montar correctamente la PSP:
$mount /mnt/psp
Grabando música y fotos
Bien, para grabar MP3 lo único que debemos hacer es meterlos en la carpeta /mnt/psp/PSP/MUSIC.
Para subir fotos, grabaremos nuestros JPG's y PNG's en la carpeta /mnt/psp/PSP/PHOTO.
Los formatos aceptados por la PSP varían según el firmware de la consola, yo uso el 1.50 (por razones evidentes) y puedo cargar también TIFF's (creo... la verdad que no lo he probado).
Pasando vídeos
Bueno... para esto necesitáis el ffmpeg de la ultimísima versión que podáis pillar, es decir, la de la rama sid/unstable. Recordad que podéis encontrarlo en el repositorio de marillat.
Antes de subir un vídeo tenemos que recodificarlo:
Salvo la resolución, el resto de parámetros podéis cambiarlos para mejorar la calidad o el espacio del video en la MS. Los parámetros podéis consultarlos en la página del manual del ffmpeg... que tampoco os voy a dar todo mascadito!!. En breve intentaré modificar un script de un crysoliano para encodear pelis realizando autocropping y cosas así usando el mencoder.
Una vez tenemos el nuevo vídeo, lo renombramos a M4V00001.MP4, lo de 00001 es el orden, por si tenemos más vídeos pues 00002, 00003, etc. Para que la PSP lea esos vídeos deben estar en la carpeta /mnt/psp/MP_ROOT/100MNV01.
Si deseámos que salga la fotillo del vídeo en el menú de la PSP sólo debemos crear un JPG de 160x120 y llamarle de igual forma que el vídeo (y en la misma carpeta) pero con extensión THM. Si queréis sacar un fotograma directamente de la peli:
El fichero que se creará es M4V00001.THM pero debéis llamarlo de la misma forma que el vídeo (si es que cambiasteis el nombre del vídeo). Como véis (y si no ya os lo digo) lo de -ss 1 significa que coja el fotograma del segundo 1, modificadlo si queréis otro fotograma. Y recordad que los thumbs van en el mismo directorio que los vídeos.
Bueno, eso es todo, intentaré hacer más recetillas sobre la PSP y el GNU/Linux, ok?
Hace unos dias me puse muy malillo, como no podía hacer nada pues me dediqué a navegar... navegando navegando encontré la "Revolución FON", os resumo brevemente que pretenden esta gente:
Esta receta en realidad debió ser un taller de la Install Party, pero por problemas de tiempo no se pudo realizar así que ahora la publico para que quien tenga más de un equipo a su disposición pueda manejar ambos de una forma cómoda.
Esta receta está dedicada a todas aquellas personas que van por ahí diciendo que su KDE o su file-roller son mejores que Nautilus por el simple hecho de que no tiene la opción "Abrir terminal aquí"... bueno pues nada, buscad nuevos argumentos porque ese hace tiempo que no os vale... Debéis saber que a Nautilus se le pueden añadir toda la funcionalidad que queráis de una forma muy sencilla: Nautilus-scripts (o G-scripts).
Nautilus-scripting
Nautilus permite al usuario crear sus propios scripts en cualquier lenguaje, ya sea python, perl, bash-script, etc. Para ello, lo único que debemos hacer es copiarlos en el siguiente directorio:
~/.gnome2/nautilus-scripts
La primera vez que ponemos un script debemos reiniciar nautilus para que nos aparezca la nueva entrada en el menú contextual, después se actualizará dinámicamente con los scripts y directorios que creemos en dicha carpeta.
Abrir terminal aquí
Además, nautilus crea unas variables de entorno para facilitar más aún escribir scripts útiles, una de ellas nos permite obtener la lista de ficheros seleccionados, si seleccionamos una carpeta y abrimos una shell ahí tendremos lo que queremos... en bash-script esto es extremadamente fácil: creamos el archivo "terminal aqui" con el siguiente contenido:
#!/bin/bash
cd $NAUTILUS_SCRIPT_SELECTED_FILE_PATHS
gnome-terminal
Cambiamos los permisos y lo movemos a la carpeta de scripts de nautilus:
Reiniciamos nautilus (esto no parece muy elegante...):
$killall nautilus
Si ahora pinchamos con el botón derecho sobre una carpeta nos aparecerá una nueva opción en el menú contextual y ahí la opción "terminal aqui". Podeis crear subcarpetas para hacer subsecciones, etc. Hay muchos scripts útiles (aunque algunos ya están un poco obsoletillos...)
El gestor de arranque GRUB permite hacer operaciones muy sensibles, como por ejemplo, modificar el dispositivo desde el que arranca el sistema o arrancar sin tener la contraseña de super-usuario. Para evitar esto, tienes la posibilidad de protoger GRUB con su propia contraseña
Para ponerle una contraseña debes hacer lo siguiente (como root):
#grub-md5-crypt
Te pedirá una contraseña y su verificación, como resultado te dará un puñado de caracteres, los copias.
Ahora edita el fichero /boot/grub/menu.lst y antes de la lista de items de arranque añade:
password --md5 pega_puñado_de_caracteres
Ahora cuando arranque grub sólo te permitirá seleccionar un item de arranque, o pulsar 'p' para introducir la clave y a partir de ahí tendrás acceso total hacer lo que quieras.
Por cierto, si en alguna entrada de arranque pones 'lock' te pedirá la misma contraseña para poder usarla.
fácil...
Bueno... hace unos días se habló en CRySoL de realizar una "install party"... pero como viene siendo habitual si no hay nadie que diga: "va, lo hago yo" pues no se hace. Pues bien yo (Tobias Diaz) y el siempre bien ponderado Cleto hemos decidido decir: "va, lo hacemos nosotros" y hemos empezado a preguntar por aquí y por allí a ver qué podemos y qué no podemos hacer.
Finalmente hemos llegado a la feliz idea de realizar una install party con talleres variados... es decir, pasaremos unas amenas horas instalando un sistema base tipo Debian/Ubuntu/Gnesis/MoLinux y después sacando parte del jugo a nuestros "hijos".
Todavía queda mucho por decir, pero lo mas inmediato es decidir que días os vienen mejor, para eso esta la encuesta... votad por favor!
En próximos días os contaremos como van los progresos... ok?
Ah! ya pediremos colaboraciones a ver si es verdad que todos los "podéis contar conmigo" eran de verdad o de boquilla... jejejeje...
Pues eso, que he mirado el correo y he visto un mensaje de David anunciando la nueva web de crysol y después de haberla visitado, pues eso, que me acabo de registrar.
Me voy a la cama que estoy un poco cansado y mañana hay que madrugar para seguir currando.
Saludos.
En esta receta explico un par de opciones muy útiles para configurar la forma que tiene Emacs de realizar la indentación. Por ejemplo, Emacs indenta el código C con dos espacios, pero quizá a tí te gusta más con 4. También permite cambiar la forma de indentar las llaves, paréntesis, etc.
Como nunca me acuerdo de cómo son los nombres de las teclas en Python, y soy tan torpe que no encuentro nunca la página con los nombres, me he escrito este pequeño programita. Lo dejo aquí por si es útil a alguien más:
Gdm3 supuso un paso atrás en lo que a personalización del escritorio se refiere, ya que no hay una manera directa de configurarlo mediante temas, y la mayoría de la gente tiene el horrible tema de las estrellitas y la navecita espacial, dibujadas por un niño de 6 años.
En barrapunto me he encontrado con la noticia de la publicación de este libro. La presentación del mismo reza así:
«Los arquitectos examinan miles de edificios durante su formación, y estudian las críticas de esos edificios que escriben los maestros de la profesión. En cambio, la mayoría de los desarrolladores de software sólo llegan a conocer bien un puñado de aplicaciones grandes -normalmente las que escribieron ellos- y nunca estudian los grandes programas de la historia. Como resultado, repiten los errores de otros, en lugar de construir sobre los aciertos de los demás.»
http://www.aosabook.org/en/
Hace unos días estuve leyendo las licencias (EULA: End User License Agreement) de Windows y MacOS para una charla que íbamos a dar en Daimiel. Me parece que son lo suficientemente interesantes como para compartirlas con todos vosotros:
Muchas veces se habla sobre cómo deberían hacerse las cosas, pero a veces no se muestran los contraejemplos. A raíz de una conversación en la lista de correo se me ha ocurrido que podría ser útil tener una lista de ejemplos de malas prácticas de programación, cosas a evitar, desde fallos de novato hasta cosas más complejas.
Al parecer, Javier Bardem ha salido en "defensa" de los artistas y arremete contra los "piratas" en un artículo publicado en el diario El País, titulado El Botón Mágico. Por suerte, el usuario humitsec (fan de los tebeos de Superlópez) le ha respondido en un aplastante comentario en meneame. Lo reproduzco aquí a continuación:
En esta receta veremos cómo añadir un efecto de resplandor a un objeto, gracias a los nodos de composición.
Preparación de la Escena
Seleccionamos el objeto que queremos que brille y le aplicamos un material de color blanco, y activamos la opción Shadeless. En la pestaña de propiedades del objeto, localizaremos el deslizador Pass Index y le asignaremos un número que lo distinga de todos los demás objetos que no brillen. Normalmente los objetos tienen índice 0, así que podemos utilizar el 1, por ejemplo.
En el panel de propiedades de renderizado, desplegamos la pestaña Layers y comprobamos que la opción Object Index esté activa.
Composición
Supongo que ya tenéis un nodo Render Layers y otro Composite, además de Use nodes activo. (ver receta dof)
Añadimos un nodo ID Mask (add→convertor→id mask) y conectamos a su entrada la salida Object index del nodo Render Layers (si no la ves, revisa la sección anterior). Elegimos el valor del índice que le pusimos a nuestro objeto brillante (en nuestro ejemplo, 1).
Añadimos un nodo para desenfocar (add→filter→blur), elegimos fast-gaussian e incrementamos el valor del desenfoque en x e y hasta unos 4 ó 5 pixeles.
A continuación, utilizaremos el mezclador de color (add→color→mix) para unir el resultado del blur con la imagen original, y uniremos este resultado con el nodo Composite.
Si queréis que el brillo sea de un color, en lugar de blanco, podéis añadir un nodo Color Ramp (add→convertor→color ramp) y colocarlo entre el nodo de Blur y el de Color Mix.
La profundidad de campo (DoF por sus siglas en inglés, depth of field) es un efecto que se produce cuando se enfoca un punto concreto, y el resto de elementos, tanto los que están más lejos como los que están más cerca, aparecen desenfocados, en una cantidad proporcional a la distancia del punto de enfoque. Puede sirve para dar un efecto artístico a la imagen, o para centrar la antención en un elemento concreto. En esta receta veremos cómo simular este efecto en Blender 2.54
Ajustes de Cámara
Normalmente, al renderizar una escena, todos los elementos de la imagen aparecen enfocados, ya que no hay definido ningún punto de enfoque. Lo primero que hay que hacer para conseguir este efecto es definir el punto en el que la imagen será completamente nítida y estará perfectamente enfocada.
Para ello, seleccionamos la cámara y, en el panel de propiedades, localizaremos en la pestaña Lens la parte donde pone Depth of Field. Aquí encontraremos dos elementos: un cuadro de texto y un botón deslizante etiquetado como Distance. Con estos dos elementos podemos controlar el punto de enfoque. Para saber dónde está y ver las modificaciones que hacemos, activaremos el checkbox Limits, que se encuentra un poco más abajo. Veremos que aparece una cruz amarilla, que indica el punto de enfoque.
Desplazando el deslizador Distance podemos situar el punto de enfoque a una distancia específica de la cámara. Esto es útil cuando sabemos exactamente la distancia a la que queremos situarlo, aunque esto no es lo habitual.
Lo más común es querer situar el enfoque en un objeto concreto, y para eso utilizaremos el cuadro de texto. En él podemos escribir el nombre del objeto que queremos enfocar, y la cruz amarilla que representa el foco se colocará sobre él.
Aunque hemos definido una distancia de enfoque, podemos comprobar que al renderizar la imagen sigue saliendo totalmente nítida. Para aplicar el efecto es necesario utilizar los nodos de composición.
Composición
Seleccionamos la vista de composición y activamos el botón Compositing Nodes y el checkbox Use nodes. Tomaremos la entrada del nodo Render Layers (Add→input→render layers), y la salida será el nodo Composite (add→output→composite). Si queremos, podemos añadir un nodo Viewer, cuyo resultado podemos ver en la ventana de edición de imagen, seleccionando Viewer Node. De esta forma podemos ver los cambios que vayamos haciendo sin necesidad de renderizar cada dos por tres (seis).
Para aplicar el efecto de DoF, añadiremos un nodo Defocus (add→filter→defocus) y conectaremos la salida de render layers con la entrada image del defocus. También conectaremos la salida Z con la entrada homónima, y activamos el checkbox Use z-buffer. Con esto conseguimos controlar la cantidad de desenfoque mediante el búfer de profundidad de la imagen. Debería quedar algo como la imagen:
Podeis jugar un poco con los parámetros del nodo Defocus, para ajustar el efecto del desenfoque:
El Bokeh type define cómo se ven los objetos desenfocados. Yo he usado triangular, por eso el fondo se ve con triángulos de colores (el fondo es un cielo negro con estrellas de colores. Lo sé, es hortera, pero es para efectos demostrativos).
Angle sirve para aplicarle una rotación al bokeh
fStop: este es el parámetro más importante. Define la cantidad de desenfoque. El valor por defecto (127) indica un desenfoque nulo, es decir, todos los objetos están enfocados. A medida que lo disminuyáis, aumentará el desenfoque (y se notará más en los objetos más alejados del foco).
MaxBlur: permite establecer un máximo de desenfoque, de manera que el cálculo se detenga aunque el valor de fStop indique que deba continuar. Es útil para que el renderizado no se eternice.
Threshold: indica el umbral de distancia para considerar que el desenfoque es seguro. Se utiliza para corregir errores que pueden surgir al tener, por ejemplo, un objeto enfocado contra un fondo lejano muy desenfocado; en este caso es posible que el desenfoque del fondo se introduzca en los bordes del objeto. Generalmente no hace falta cambiarlo.
Preview: permite obtener una vista rápida del efecto de desenfoque.
Use Z-Buffer: indica al nodo que utilice la entrada “Z” para calcular el desenfoque. Si no se usa, el desenfoque se controla con el botón deslizante que aparece en la entrada “Z”.
Z-Scale: Es posible conectar una textura en blanco y negro en la entrada Z para utilizarla como buffer. Las texturas se interpretan en el rango [0, 1], que puede resultar demasiado estrecho. Con este valor se consigue aumentar el rango.
Erratas
Si encuentras algún error o incongruencia en la receta, por favor, deja un comentario.
Así, tal cual suena. :jawdrop: Visto en barrapunto. Alguien debería patentar el arranque del SO, o el uso del monitor, o el uso de la electricidad... Algo, lo que sea, y quitarles los cuartos y dejarlos en la ruina. ¡Qué asco de empresa, coño! :barf:
En esta receta se explican los pasos a seguir para poner en marcha un sistema HYDRA desde cero, utilizando la versión SID (Still in Development) del repositorio.
A falta de una documentación de pynotify, explicaré en esta receta cómo usar el binding de python para libnotify, para poder crear notificaciones de eventos en tus aplicaciones.
FACUA-Consumidores en Acción ha iniciado una campaña contra la polémica, antipopular y financiada-por-los-lobbys-de-la-música ley de Economía Sostenible. Esperemos que sirva de algo:
https://www.facua.org/es/sieslegaleslegal/index.php
Parece que todo el mundo quiere subirse al modelo de negocio de la $GAE, en el que cobran por todo lo que puedan, incluyendo el trabajo de los demás. No os perdáis las declaraciones del presidente de Timofónica, hablando sobre cobrar a los buscadores porque utilizan "sus redes", cobrar a los desarrolladores de aplicaciones porque publicitan y distribuyen su aplicación usando "sus redes", y cobrar el uso del "cloud computing" porque «la inteligencia está en la red, y la red es nuestra»
A. K. A. Cómo suplantar un servidor :P
Aunque suene un poco delictivo (o como les gusta llamarlo ahora, pirata), esto puede ser una buena solución para muchas situaciones; como crear "islas" dentro de una misma red, u ofrecer servicios adicionales.
Tres Anillos para los Reyes Elfos bajo el cielo.
Siete para los Señores Enanos en palacios de piedra.
Nueve para los Hombres Mortales condenados a morir.
Uno para el Señor Oscuro, sobre el trono oscuro
en la Tierra de Mordor donde se extienden las Sombras.
Un Anillo para gobernarlos a todos. Un Anillo para encontrarlos,
un Anillo para atraerlos a todos y atarlos en las tinieblas
en la Tierra de Mordor donde se extienden las Sombras.
Ante la inclusión en el Anteproyecto de Ley de Economía sostenible de modificaciones legislativas que afectan al libre ejercicio de las libertades de expresión, información y el derecho de acceso a la cultura a través de Internet, los periodistas, bloggers, usuarios, profesionales y creadores de internet manifestamos nuestra firme oposición al proyecto, y declaramos que...
Lo siguiente es un ejemplo mínimo de cómo se usa el widget gtk.IconView, añadiendo iconos desde ficheros nuestros (sin usar los iconos de stock). Para ver cómo usar los iconos de stock puedes consultar (Py)GTK Tips 'n Tricks
Al parecer, en el Reino Unido están realizando una prueba piloto, parecida al sistema de 3 avisos que ya funciona en Francia y que quieren imponer en España. El experimento ha durado unas 10 semanas, en las que mandaban advertencias a los usuarios de P2P que descargaban contenido protegido, junto con abundante publicidad de tiendas de música on-line.
Hay unas cuantas piezas de fruta que nadie se come porque están empezando a pasarse, y no son tan apetecibles como el resto de la fruta. ¡Estupendo! Haz una mermelada con ellas.
Ingredientes
N gramos de fruta
N/2 gramos de azúcar
agua
Preparación
Echar un poco de agua en una cazuela y poner a hervir con el azúcar.
Opcionalmente, se puede añadir una rama de canela.
Picar la fruta en trozos muy pequeños, cuanto más, mejor. Como si quisiéramos hacerla puré.
Echarla a la cazuela y hervir, removiendo constantemente. A medida que la cocción vaya avanzando, la mezcla se irá solidificando.
Cuando tenga la textura adecuada, retirar del fuego y dejar enfriar en un bol.
¿Cuál es la textura adecuada?
Bueno, pues eso es muy subjetivo. Obviamente, no debe ser tan líquido como para chorrear, ni tan sólido como para cortarlo con cuchillo. El problema es que, al dejarla enfriar, se endurecerá aún más. Si habéis echado demasiado azúcar puede quedar demasiado dura. En ese caso, se puede volver a calentar al baño maría y rebajarla añadiendo un poco de agua.
Si alguna vez habéis utilizado VirtualBox, QEMU, VMWare o similares, puede que os hayáis encontrado con el problema de que no podéis acceder a servidores que se ejecutan en el SO huésped desde otros equipos externos.
Eso es porque estas máquinas virtuales suelen traer soporte para NAT pero no siempre para bridging. Una solución es crear un dispositivo que haga de puente entre el interfaz de red del SO huésped y el del SO anfitrión. En esta receta veremos cómo hacerlo.
Ingredientes
uml-utils
bridge-utils
El Puente
Necesitamos crear un dispositivo en nuestro sistema anfitrión que haga las veces de puente. Lo podemos poner directamente en el archivo /etc/network/interfaces, de forma que se cree en el arranque y esté disponible en el sistema. Añadiremos las siguientes líneas al fichero:
#dispsitivo puente para virtualización
iface br0 inet dhcp
bridge_ports eth0
up chmod 0666 /dev/net/tun
A continuación, reiniciamos la red con:
#/etc/init.d/networking restart
Si miramos ahora las interfaces de red, veremos que tenemos un nuevo dispositivo llamado br0, que es el puente entre nuestra eth0 y los SO huésped.
El Enlace
Antes de nada, nos aseguramos de tener cargados el módulo tun y el kqemu (en caso de utilizar QEMU, claro).
#modprobe tun kqemu
Antes de arrancar la máquina virtual, será necesario crear un dispositivo que será el que se comunique con el interfaz del SO huésped, y añadirlo al puente br0.
#tunctl -u$USERSet 'tap0' persistent and owned by uid 1000
#ifconfig tap0 up
#brctl addif br0 tap0
Si volvemos a mirar las interfaces de red, además del br0 encontraremos también el tap0. Cuando vayamos a arrancar la máquina virtual, hay que configurarla para que utilice el dispositivo tap0 como interfaz de red. Las siguientes imágenes muestran cómo hacerlo en VirtualBox y QEMU:
En ambos programas hay un campo de texto que pide el nombre de un script. Si hemos colocado las instrucciones anteriores de creación y configuración de los dispositivos br0 y tap0 en un script, podemos poner aquí el nombre del mismo. Así, supuestamente, se ejecutará el script antes de arrancar la máquina virtual, aunque a mí no me ha funcionado muy bien y he tenido que ejecutar el script manualmente.
Leyendo barrapunto, me he encontrado con una noticia que, sinceramente, no sé cómo calificar. Al parecer, la esgae es capaz de cobrar, lucrarse y enriquecerse hasta del contenido libre de autores no afiliados a ella, y ha obtenido alrededor de 500.000 € (no os perdáis el vídeo) de compensación por copia privada de (atención) LinEx.
A veces puede resultar útil poder programar el sistema para que realice tareas a una hora determinada. En esta receta veremos dos maneras de hacerlo.
at
La utilidad at nos permite ejecutar tareas a una determinada hora. Si no la tenéis en el sistema, basta con instalar el paquete at de la manera estándar.
Por ejemplo, vamos a programar que aparezca el eye-of-gnome a las 12:05. Para ello, ejecutamos en un terminal el comando at, indicando a continuación la hora a la que debe comenzar la tarea. Como veréis, aparece un prompt en el que indicaremos las tareas que queremos que se ejecuten, una por línea. Para salir del prompt, hay que pulsar Ctrl+D. Aparecerá un mensaje confirmando la hora y el número de la tarea (job).
$at 12:05
warning: commands will be executed using /bin/sh
at>eog
at><EOT>
job 2 at Fri Oct 17 12:05:00 2008
A menudo, lo que queremos es ejecutar varias tareas, pero en un orden secuencial, no todas a la vez (vamos, lo que viene siendo un script). Suponiendo que queramos ejecutar mistareas.sh, haremos lo siguiente:
$at -f miscript.sh 13:45
warning: commands will be executed using /bin/sh
job 4 at Fri Oct 17 13:45:00 2008
También se podría poner miscript.sh como una tarea en el modo interactivo del prompt, siempre y cuando tenga los permisos adecuados de ejecución.
Cabe destacar que con at, las tareas quedan programadas para una sola vez, y se borran después de ejecutarse. Es decir, al día siguiente no volverán a ejecutarse.
Si queremos borrar una tarea que tenemos programada, debemos conocer primero su número (el que sale al programarla). Para borrarla, utilizamos atrm. Si no conocemos el número de la tarea o lo hemos olvidado, podemos consultar las tareas programadas con la opción -l:
$at -l4 Fri Oct 17 13:45:00 2008 a nacho
$atrm 4
$at -l$
cron
Cron es una herramienta que permite la ejecución de tareas periódicamente en varios intervalos: horario, diario, semanal y mensual. Su utilización es más sencilla que la de at: Basta con guardar el script que queramos ejecutar (éste no tiene modo interactivo) en el directorio correspondiente a cuándo queremos que se ejecute.:
Cada hora: /etc/cron.hourly/
Cada día: /etc/cron.daily/
Cada semana: /etc/cron.weekly/
Cada mes: /etc/cron.monthly/
Esta simplificación de uso es específica de Debian (y derivados quizá). Aunque la funcionalidad es posible conseguirla en otras distribuciones, no es tan sencillo (y puede que los directorios mencionados no existan).
Para saber exactamente cuándo se van a ejecutar las tareas, echamos un vistazo al fichero /etc/crontab. Éste es el mío:
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
Las columnas indican lo siguiente:
m = minute (minuto)
h = hour (hora)
dom = day of month (día del mes)
mon = month (mes)
dow = day of week (día de la semana)
Por lo tanto, mi crontab indica que:
- Las tareas "horarias" se ejecutarán en el minuto 17 de cada hora.
- Las tareas diarias se ejecutarán a las 6:25
- Las tareas semanales se ejecutarán el séptimo día de la semana, a las 6:47 (0 y 7 indican Domingo, 1 es Lunes, etc...)
- Las tareas mensuales se ejecutarán el día 1 de cada mes, a las 6:52
Aquí tenéis un artículo muy interesante sobre la oferta de sistemas operativos disponibles. Si queréis ser originales de verdad, dejarsen de Güindor, de Linus y de macoesequis, y probad alguno de estos:
Ya que nuestros programas "modo texto" son bastante sosos y puede ser difícil leer la salida (sobre todo si son muy "verbosos"), a veces es útil poder imprimir en colores en pantalla.
Es posible crear scripts y hacer que se ejecuten durante el arranque del sistema, antes de que se nos muestre el login. En esta receta veremos cómo incluirlos y cómo borrarlos.
Introducción
Durante el arranque y la parada del ordenador, el sistema entra en varios niveles de ejecución. Los niveles 2, 3, 4, 5 son los de arranque o inicio; 0, 1, 6 son los niveles de parada o apagado; y S es el nivel monousuario.
En el directorio /etc hay una serie de directorios nombrados rcX.d, donde la X indica el nivel de ejecución. Dentro de estos directorios hay una serie de enlaces simbólicos hacia los scripts que se ejecutan en cada nivel.
Los enlaces se llaman igual que el script al que apuntan, pero con un prefijo consistente en una S o una K más un número de dos dígitos. La letra indica si es un script de inicio (Start) o de parada (Kill), y el número indica el orden en que se ejecuta. Por defecto, este número es 20, aunque se puede cambiar, como veremos más adelante.
Manejando los Scripts
Lo primero es crear el script. Es necesario que exista antes de incluirlo para su ejecución en el arranque. Si echamos un ojo a los directorios rcX.d, veremos que la gran mayoría de los scripts están en /etc/init.d, así que es de suponer que ese es un buen lugar para colocar el nuestro (de hecho, no puede estar en otro sitio)
Añadir un script
El comando que vamos a utilizar es update-rc.d. Para añadir un script de inicio, lo haremos de la siguiente forma:
#update-rc.d miscript.sh defaults
Con esto incluimos miscript.sh para que se ejecute en el arranque (en los niveles 2, 3, 4 y 5), y en la parada (niveles 0, 1 y 6). Es equivalente a escribir:
(nótese el punto al final)
Supongamos ahora que queremos incluir nuestro script sólo en el inicio, con orden de ejecución 95, y sólo en los niveles 2 y 3:
#update-rc.d miscript.sh start 95 2 3 .
(nótese el punto al final)
Borrar un script
Para borrar un script haríamos:
#update-rc.d miscript.sh remove
Esto borra únicamente los enlaces simbólicos, no el script; y siempre y cuando se haya borrado el script previamente. Si se quiere borrar los enlaces aunque no se haya borrado el script, hay que utilizar la opción -f (force):
#update-rc.d -f miscript.sh remove
Para evitar liarla parda, tanto en la adición como en el borrado, es útil utilizar la opción -n (not really). Esto hace que no haga realmente las operaciones, si no que solamente nos diga qué habría hecho.
Sí tienes una cuenta jabber (o gtalk que es lo mismo) puedes usar Pidgin para unirte a salas de chat al más puro estilo de IRC. En esta receta te explico cómo unirte a la de tu portal favorito: CRySoL
Unirse a un Chat
En la ventana principal de Pidgin, pulsa en Amigos --> Unirse a un chat
Si conoces los datos de la sala, puedes rellenarlos directamente, tal como se ve en la imagen. Si no, puedes buscar una sala en la lista de salas disponibles, pulsando en Lista de salas.
Añadir la Sala como contacto
Se puede también añadir la sala como si fuera un contacto más de jabber. Una vez dentro de la sala, pulsa en Conversación --> Añadir. De esta forma podrás tenerlo siempre a mano, a sólo un doble-click de distancia.
Para que se conecte automáticamente cuando abras pidgin, abre el menú contextual de CRySoL en la lista de contactos y marca «Conectar automáticamente».
El siguiente enlace es un ejemplo del grado de ridiculez que alcanza la estupidez humana en su afán por adueñarse de lo que es universalmente de dominio público:
Leo en barrapunto que están desarrollando un filtro contra la estupidez. Al parecer es como un anti-hoygan, pero mucho más potente, pues no sólo evalúa la ortografía, también la gramática y otras cosas.
…al menos para hacer la documentación. Mirad lo que me he encontrado en una página de Microsoft sobre DirectX, en la que explican los conceptos básicos de las 3D. Al parecer, prefieren no pagar las licencias y patentes que tanto defienden.
Así, en frío, no suena a nada, pero detrás de ese nombre tan raro se esconde el creador del Tetris, ahí es nada.. Os dejo un enlace a una entrevista en la que afirma que “el software libre nunca debería haber existido y a día de hoy no debería existir”.
Correo que me han mandado los de Hassefroch, supongo que os habrá llegado también, si tenéis cuenta en hotmail.
Razones de peso por las que necesitas Windows Live!
1. Porque si tienes una cámara digital, la Galería fotográfica de Windows Live te permite importar, administrar y compartir fotos fácilmente en Windows Live Spaces y en otros servicios.
Estás en Siberia, sólo tienes acceso a un terminal en modo texto, no tienes ningún cliente de correo y quieres enviar un email. ¿Imposible? Apúntate estos pasos y lo conseguirás. La receta explica cómo enviar correo usando directamente el protocolo que entiende el servidor.
Encontrando un servidor
Para poder enviar un email, es necesario hacerlo a través de un servidor. Todos conocemos multitud de ellos (yahoo, hotmail, latinmail, gmail…). Pero no debemos conectar con el servidor en general, si no con una parte de él llamada Mail Exchanger (MX). Para averiguar el nombre del MX de un servidor, utilizaremos nslookup.
$ nslookup
> set type=mx
> wanadoo.es
Server: 80.58.61.250
Address: 80.58.61.250#53
Non-authoritative answer:
wanadoo.es mail exchanger = 10 inw.wanadoo.es.
Authoritative answers can be found from:
inw.wanadoo.es internet address = 62.36.20.20
>
Quiero llamar vuestra atención sobre el uso de este comando. Al escribirlo sin argumentos, entramos en modo interactivo, es decir, el programa nos presenta su propio “prompt”, indicándolo con un signo >. Es decir, una vez escribamos nslookup en la línea de comandos, debemos escribir set type=MX para que nos filtre sólo los intercambiadores de correo. Después, ponemos el nombre del servidor al que queremos conectarnos.
Enviando correos
Una vez tengamos el nombre del MX, nos conectaremos a él usando telnet. Abriremos una conexión en el puerto 25 (el del correo) y seguiremos el protocolo SMTP:
$ telnet
telnet> <b>open inw.wanadoo.es 25</b>
Trying 62.36.20.20...
Connected to inw.wanadoo.es.
Escape character is '^]'.
220 dam17 ESMTP
<b>helo pepe</b> # escribe "helo" y lo que quieras (es para saludar al servidor)
250 dam13.wanadoo.es Hello pepe
<b>mail from: vader@deathstar.empire.com</b> # la dirección del remitente
250 Ok
<b>rcpt to: yoda@jedicouncil.net</b> # la dirección del destinatario
250 Ok
<b>data</b> # indica el comienzo del cuerpo del email
<b>Date: 8 Jan 2004 18:45:00 GMT</b> # opcional
<b>From: your@address</b> # opcional
<b>To: recipient@address</b> # opcional
<b>Subject: Let's have a cup of tea.</b> # opcional
<b>Hola, esto ya es el cuerpo del mensaje. Cuando hayas terminado el correo,
terminalo con una línea que contenga únicamente un punto,
como la que viene a continuación.
.
</b>
Y listo. Para salir de telnet, escribid quit. La dirección que se pone en mail from no se comprueba (es decir, puedes poner la que quieras). Y también se puede enviar un correo con fecha del año 3249 ;)
Posibles problemas
Dependiendo de la configuración del servidor, es posible que os dé errores de relay (reenvío). Eso significa que el servidor sólo reenvía los correos que vienen de o van hacia unas direcciones determinadas. A seguir probando…
Existen utilidades que permiten conocer la temperatura de nuestro microprocesador, el disco duro, la placa madre y la velocidad de los ventiladores. Con esta receta veremos cómo hacerlo.
Paquetes necesarios
xsensors
lm-sensors
sensors-applet
hddtemp
Configurando
Una vez hallamos instalado los paquetes, tenemos que detectar los sensores que tiene nuestro sistema. Para ello, debemos ejecutar una utilidad que viene en el paquete lm-sensors:
#sensors-detect
Es un poco rollo, porque para cada dispositivo te pregunta si quieres detectar sensores. Después de varias pulsaciones de ENTER, hará un resumen y te dirá que necesitas cargar algunos drivers del kernel. Además, el programa es muy amable y se ofrece a poner sus nombres en /etc/modulespara que la próxima vez que arranques ya los tengas cargados. Para cargarlos a mano ahora sin tener que reiniciar hay que escribir un poco:
#modprobe -a <modulo1> <modulo2> ... <moduloN>
Esto difiere de un ordenador a otro, y depende de los dispositivos en los que hayais buscado. Es decir, si antes habéis contestado que no busque sensores en algún dispositivo, quizá no os pida algún módulo. En mi caso, tuve que poner:
#modprobe -a i2c-dev i2c-sis96x i2c-isa eeprom it87
Vigilando
Muy bien, ya tengo los sensores en marcha. ¿Y ahora cómo los miro? Pues bien, tenemos varias opciones.
Comando sensors
Es un comando de la linea de órdenes. Imprime el valor de los sensores en ese momento, y bueno, es un poco feo verlo en modo texto.
xsensors
Este es un programa en modo gráfico. Además, se va actualizando cada pocos segundos.
sensors-applet
Es un applet para el panel de Gnome (existe también ksensors, para kde) que permite monitorizar el estado de los sensores. Te permite colocar en el panel unos iconos del dispositivo (ventilador, disco duro, cpu...) y el valor de temperatura o rpm correspondiente.
MRTGMRTG (Multi Router Traffic Grapher) es un programa que permite hacer unas gráficas muy chulas. En principio se pensó para controlar el tráfico de red, pero permite configurarlo para monitorizar muchas más cosas: espacio en disco, memoria usada, velocidad de ventiladores, temperaturas...
Espero hacer pronto una recetita sobre esto.
Con esta receta podrás utilizar las teclas para ajustar el brillo del monitor y el volumen de los altavoces internos de tu portátil y expulsar el CD/DVD, además de hacer que aparezca un indicador gráfico en la pantalla
Ante todo he de decir que mi experiencia en el mundo de los portátiles es bastante corta. Quizá esta receta no sea necesaria y resulta que ya lo tenéis todos. Bueno, a lo que vamos.
Lo que voy a contar está probado en un powerpc con una Debian, aunque supongo que no debería haber problemas para el resto de arquitecturas y distros. Los paquetitos que necesitamos son:
pbbutonsd
gtkpbbutons
El primero es el demonio, y permite la funcionalidad de todas las teclas (a mí sólo me funcionaba la disminución de brillo). Con instalarlo de la manera habitual es suficiente.
El segundo es el encargado de mostrarte en pantalla el porcentaje de brillo o volumen que tienes configurado. Además de instalarlo, hay que ejecutarlo, por lo que recomiendo agregarlo a la lista de programas que deben ejecutarse atomáticamente al inicio de la sesión gráfica. En gnome esto se hace en Escritorio->Preferencias->Sesiones->Programas al Inicio.
Y ya está. Yo al menos, no he tenido que tocar nada más. Obviamente, debes tener el teclado configurado correctamente (layout, idioma, etc).
Temas
El gtkpbbutons tiene varios temas, para cambiar el aspecto del indicador gráfico. En la instalación vienen 3 temas: el default (por defecto o predeterminado), Crystal y MacOSX. Para ejecutarlo con un tema concreto, p.ej. MacOSX, habría que escribir:
$gtkpbbutons -t MacOSX
Créditos
Aunque la receta la escriba yo, el verdadero artífice es Cleto. ¡Hurra por él! :D
En principio iba a exponer esto como un comentario en el hilo del frikismo del amigo informático que inició Cleto, pero he decidido que merece una entrada aparte para él solito.
Hace algunos meses escribí una receta sobre como desplegar una distribuición Emdebian para una tarjeta FriendlyArm. Una opción muy interesante para este tipo de dispositivos es poderlos utilizar como nodo en un sistema distribuido mucho mayor. Si tenemos una distribución Debian corriendo en el dispositivo podemos utilizar Ice con dicho propósito.
En una entrada anterior escribí sobre cómo compilar e instalar u-boot en una tarjeta mini2440. Ahora voy a explicar cómo compilar un núcleo Linux para ésta misma plataforma. En una próxima receta tengo intención de explicar los pasos para configurar u-boot y hacer arrancable éste núcleo en nuestra amada tarjeta. De momento, vamos lo que interesa: El núcleo.
Perdón si a alguien le resulta offtopic. Buscando unas cosas que no vienen al cuento me he encontrado un resumen de estilos de indentación. Simplemente me ha parecido curioso y he decidido ponerlo aquí para compartirlo y tenerlo localizado.
Cheers.
u-boot es un bootloader libre para dispositivos empotrados de bajo poder computacional. Para los no versados en el tema, es algo así como el grub de tu PDA o de tu navegador GPS, pero con notables diferencias, claro está. En ésta receta hablaré sobre como instalarlo y como usarlo para crear distintas particiones en la memoria Flash de tu handheld para, de este modo, poder instalar un sistema arrancable. Para ello, pondré como ejemplo la tarjeta mini2440 que compré hace unos días.
Si tienes una línea móvil de datos y un módem usb, tal vez te apetezca poder utilizarlo en tu GNU/Linux. Actualmente, los modems Huawei son los mas utilizados para éste tipo de propósitos. Aquí explico lo que hay que hacer para poder dar soporte al modelo Huawei E160, un módem que por lo que he podido probar, funciona pero que muy bien bajo GNU/Linux
Pues nada, que me hice eco de ésta noticia en barrapunto. No sé si será una coña, pues está fechada el pasado 28 de Diciembre, pero no he podido evitar sentir un escalofrio recorriendo mis entrañas....
Atentos al comentario sobre el backup de la tripulación, me ha dejado sin palabras ¡¡BUENÍSIMO!!
En realidad no sé si debo catalogar ésto como una receta o no. A mi me ha sido algo útil buscando formas de hacer análisis de discos duros (el mio últimamente falla mas que una escopetilla de plomo y solo tiene un año).
Quien haya intentado hacer alguna práctica para alguna asignatura de Arquitectura de Computadoras o similares utilizando éste simulador, habrá observado que es una auténtica pesadilla utilizarlo: NO FUNCIONA. De ninguna de las maneras.
Cómo escribir reglas para udev permitiendo a dispositivos USB ser usados sin necesidad de ser root
Introducción
A veces sucede que quieres utilizar un dispositivo USB un poco "exótico" y resulta que no puedes utilizarlo sin ser root. Un ejemplo de ello puede ser dfu-programmer o pk2, que son aplicaciones no muy estándard y por lo tanto no se les ha dado el soporte necesario, haciendo que haya que invocarlas como root si queremos utilizarlas.
La solución para ésto pasa por crear unas reglas para udev que permitan que éstas aplicaciones accedan al puerto USB de nuestro PC en modo normal.
Un ejemplo: dfu-programmer
Ilustraré el proceso con una aplicación de ejemplo: dfu-programmer. Se trata de un cliente para el bootloader USB instalado en los micros con soporte para dicho interfaz de Atmel.
Para añadir las reglas, abrimos (mas bien creamos) el archivo que contedrá dichas reglas:
Básicamente lo que se hace es indicar a udev que dfu-programmer usa el sistema USB, dando información detallada acerca del vendorID y el productID del dispositivo que se va a conectar al puerto. También indica con qué permisos se debe acceder al puerto y especifica el grupo cuyos permisos hereda la aplicación.
Si utilizas varias aplicaciones que tienen librerías que entran en conflicto entre sí, una solución puede ser "enjaularla" para que no entre en conflicto con tu sistema. Aquí explico cómo crear una jaula en pocos pasos, que permitirá entre otras cosas aislar aplicaciones.
Además, el uso de jaulas también puede resultar útil si tienes ciertos servicios como servidores web o ftp y quieres aumentar un poco mas la seguridad del sistema, ya que hace, al menos algo mas difícil, el acceso al sistema, debido a que éste queda, en teoría, fuera del alcance del sistema enjaulado.
En mi caso, yo he utilizado la jaula para aislar dos compiladores cruzados para microcontroladores AVR, debido a que utilizo tinyos y necesita una versión muy concreta de avr-libc que entra en conflicto con ya que yo tengo instalada.
Empezando
Bueno, para poder empezar, necesitas tener instalado cdebootstrap, si usas Debian ya sabes, apt-get (o aptutude, que esto parece como ser del Bétis o del Sevilla ;)).
Una vez con cdebootstrap instalado, creas un directorio en el lugar en el que quieras tener tu jaula instalada. Yo por ejemplo, la he creado en /usr/local/tinyos por ésto de tener las cosas un poco mas ordenaditas. Cuando ya tengas el directorio creado invocas a cdebootstrap con un comando tal que éste:
Esto crea, dentro de /usr/local/tinyos/ un sistema unstable totalmente desnudo (con lo mas básico) partiendo del repositorio que le hemos pasado.
Ahora, para poderlo utilizar, necesitas montar /proc y /dev. Éste último no es que sea especialmente necesario a menos que vayas a utilizar algún dispositivo de entrada/salida. En mi caso, como necesito un puerto serie para poder programar las motas, he de montarlo dentro de la jaula.
Para montar las unidades y acceder a la jaula, se puede utilizar un script como el siguiente, que lo hace todo de forma automática:
#!/bin/bash
sudo mount -t proc none /usr/local/tinyos/proc
sudo mount -t sysfs none /usr/local/tinyos/sys
sudo mount --bind /dev /usr/local/tinyos/dev
sudo chroot /usr/local/tinyos
sudo umount /usr/local/tinyos/dev
sudo umount /usr/local//tinyos/sys
sudo umount /usr/local/tinyos/proc
Este script monta /proc, /sys y /dev dentro de la jaula y ejecuta chroot para cambiar el raíz. Cuando sale del chroot, desmonta todo otra vez.
Pues la verdad es que viendo este articulo que me he encontrado buscando algunas cosas, me he sentido muy identificado (yo creo que hasta he sentido algo de nostalgia de cuando programaba con Visual Basic allá por los noventa…)
Cómo parsear un archivo Slice (el lenguaje de especificación de interfaces de ICE) para obtener toda la información semántica que contiene utilizando libSlice (el Parser proporcionado por ZeroC)
Introducción
Los archivos slice todos sabemos lo que son: Archivos que proporcionan una descripción de las clases, módulos, interfaces y operaciones que implementará un sistema distribuido basado en ICE.
La gente de ZeroC proporciona el código fuente de su middleware, pero éste no está muy bien documentado (siendo generosos), así que la manera de parsear un archivo slice y obtener toda la semántica que se necesitaba, ha pasado por hacer un poco de ingenería inversa del código de una de las utilidades que da ZeroC (en concreto slice2cpp). Así que para evitar tener que repetir el trabajo, aquí dejo un poco documentado el funcionamiento del parser para Slice que la gente de ZeroC montó.
Prerequisitos
Antes de empezar, no estaría de mas conocer un poco el patrón de programación visitor, ya que se utilizará para acceder a la información proporcionada por el parser. También se supone que se tienen nociones básicas de C++.
Yo he utilizado ice-3.3-beta así que tampoco estará de mas que además de tener ice instalado, se instalen los fuentes:
javieralso@avalon:~$apt-get source zeroc-ice33
Parseando que es gerundio…
Para parsear un archivo slice, necesitaremos utilizar la librería Slice/Parser proporcionada por ZeroC. Un ejemplo de función que llama al parser sería la siguiente:
¿y como funciona esto? Bueno, la clase OurParser será quien realice todo el trabajo. Básicamente, su cometido consiste en crear una instancia del preprocesador pasándole el archivo a parsear y un conjunto de opciones (en nuestro caso, como no queremos pasarle nada, se le pasa un vector de cadenas vacío, dummyArgs). Después de instanciar el preprocesador, se preprocesa el archivo:
u es quien realiza todo el trabajo de parseado. Las opciones que se pasan cuando se crea se utilizan entre otras cosas para propósitos de depuración y las que se dan en el ejemplo son válidas en general. Si se quiere, se puede jugar con los valores a ver qué pasa o directamente echar un ojo al código de slice2cpp donde están un poco mas comentadas.
la variable parseStatus almacena el resultado del parseo.
Una vez que se ha terminado de parsear el archivo, ya se cuenta con toda la información semántica, así que solo nos resta obtener dicha información y procesarla a nuestro antojo. Como se ha intentando que el parser sea lo mas general posible, de modo que pueda ser reutilizado para lo que sea necesario (vamos, que haya buena separación entre frontend y backend), se ha hecho uso del patron de diseño visitor que se comentó anteriormente. En nuestro caso creamos una clase que contendrá una serie de métodos que serán llamados en determinados momentos, como por ejemplo cuando se inicie la declaración de un módulo, su finalización, cuando se declare una función, sus parámetros, metadatos, se defina una estructura de datos o una clase, etc….
En nuestro caso, después del parseo, “visitamos” al parser para pedirle toda la información:
OurVisitorvisitor;u->visit(&visitor,cppHandle);
visitor es una instancia de nuestra clase visitante, que implementará los métodos necesarios para procesar la información.
Ésta clase viene a ser algo como ésto:
Bueno, como se puede ver, nuestro “visitante” tiene que heredar de la clase ParserVisitor, además, debe implementar todos los métodos que se ven. Éstos métodos serán llamados por el parser y será en ellos en los que nosotros definamos el procesado que queremos hacer de la información.
“Extrayendo” información
Bueno, aquí voy a comentar qué he hecho yo para obtener cierta información que necesitaba del Slice. Si se necesitase otra información, pues nada, a mirar el código de los conversores de código que da ZeroC, que es muy entrentenido :-P …
Modulos
Cada vez que se inicia el parseado de un módulo, se invoca la función visitModuleStart de nuestro visitor. Entre otras cosas, la información que puede ser necesaria en este punto es el nombre del módulo y su ámbito de declaración. Para acceder a esa información, algo como esto:
boolOurVisitor::visitModuleStart(constModulePtr&p){cout"Nombre del modulo: "<<p->name()<<endl;cout"Ambito de declaracion: "<<p->scope()<<endl;returntrue;}
Cuando se abandona la declaración de un módulo, se invoca a visitModuleEnd, pasandole exactamente la misma información que a su homólogo de inicio de módulo.
Clases e Interfaces
Cuando se declara una clase o una interfaz en el Slice, el parser visita la misma función: visitClassDefStart para el inicio de la declaración y visitClassDefEnd para finalizar la declaración. Si la declaración se encuentra dentro de un módulo, estaremos en la declaración de una interfaz. En caso contrario, se tratará de una clase.
Aquí la información que leí fue la misma que en el módulo, así que el código es casi idéntico:
boolOurVisitor::visitClassDefStart(constClassDefPtr&p){cout"Nombre del interfaz: "<<p->name()<<endl;cout"Ambito de declaracion: "<<p->scope()<<endl;returntrue;}
Operaciones
Para el caso de las operaciones necesitaremos leer mas información aparte del nombre y el ámbito. Ésta información se refiere al tipo de retorno, tipo de la función (por ejemplo puede ser idempotent), y los argumentos (nombre, tipo y dirección).
El procedimiento encargado de obtener la información de las operaciones es VisitOperation y un ejemplo de implementación que simplemente imprime información sería el siguiente:
voidOurVisitor::visitOperation(constOperationPtr&p){size_tstrIndex;stringmetadataName,metadataValue;StringListoperationMetaData;cout"Nombre: "<<p->name()<<endl;cout"Ambito de declaracion: "<<p->scope()<<endl;TypePtrret=p->returnType();stringretS=returnTypeToString(ret,"",p->getMetaData());cout<<"Tipo de retorno: "<<retS<<endl;if(p->mode()==Operation::Idempotent||p->mode()==Operation::Nonmutating){// Idempotent operationcout<<"Funcion idempotente"<<endl;}// Looking for metadata.operationMetaData=p->getMetaData();cout<<"Metadatos:"<<endl;for(StringList::iteratorit=operationMetaData.begin();it!=operationMetaData.end();it++){cout<<*it<<endl;}}// Looking for parameters.ParamDeclListparamList=p->parameters();cout<<"Parametros:"<<endl;for(ParamDeclList::const_iteratorq=paramList.begin();\
q!=paramList.end();++q){cout<<"Nombre: "<<(*q)->name();StringListmetaData=(*q)->getMetaData();if(!(*q)->isOutParam()){cout<<"Parametro de salida"<<endl;typeString=inputTypeToString((*q)->type(),false,metaData);cout<<"Tipo del parametro: "<<typeString<<endl;}}
Vayamos por partes: Lo primero que hemos obtenido, ha sido el nombre y el ámbito de declaración de la operación. Después de ésto, se obtiene el tipo de retorno. Éste tipo es un enumerado, por lo que deberemos transformarlo a una cadena con el nombre adecuado para poderlo imprimir (o hacer cualquier otro tipo de proceso que nos interese)
Después se consulta el modo de la operación, que nos dirá si es o no idempotente.
A continuación yo necesitaba los metadatos de las operaciones. getMetaData() devuelve una lista de cadenas, cada una de las cuales es un metadato, así que con un iterador recorremos dicha lista y vamos imprimiendo todos los metadados de cada operación. Ésto también se puede hacer con módulos, clases, interfaces, etc….
Finalmente, se consultan los parámetros: parameters() devuelve una lista de parámetros. Una vez que se tiene esa lista, hay que iterar sobre ella e ir obteniendo toda la información sobre cada uno de los parámetros:
Nombre: (q)→name()
Dirección: (q)→isOutParam(), devuelve verdadero si el parametro es de salida.
Tipo: (*q)→type(), enumerado con el tipo del parametro.
Sobre los tipos de retorno y de los parámetros
returnTypeToString, inputTypeToString y outputTypeToString son funciones que son llamadas para convertir los enumerados que determinan el tipo de una función o parámetro en la cadena que los representa textualmente. En la implementación que tenemos, éstas funciones se encuentran dentro de un módulo llamado Slice/CPlusPlusUtil que hay que incluir. Cuando se detecte un string, int o bool por ejemplo, nuestro programita responderá con algo como ::ICE::string o ::ICE::int pero ¿y si queremos que, por ejemplo, cuando detecte un entero nos diga “cacho entero” (por ejemplo ;-))? Bueno, pues tendremos que sobreescribir las funciones de las que hablé antes para que nos devuelva lo que nosotros queramos. Yo en mi caso, modifiqué las tres. Aquí muestro mi outputTypeToString:
Lo único que modifiqué fue la tabla de nombres del principio, dándole los que yo quise. Si los nombres que vamos a dar a los parámetros de entrada, de salida y al tipo de retorno van a ser los mismos (es decir, no vamos a distinguir por ejemplo un entero de salida, un entero de entrada y un tipo de retorno entero, llamandolos por el mismo nombre de forma interna en los tres casos) podemos utilizar solo una de éstas tres funciones y llamarla en todos los casos. En caso contrario, habrá que utilizar una función distinta para cada caso y llamarla cuando sea necesaria.
Bueno, pues como dije en mi post anterior sobre KICAD, mandé los diseños que hice a China y ¡¡¡Ya han llegado!!!. Bueno, tengo que decir que el resultado es genial, muy buen acabado y totalmente profesional. Y lo mas importante: todo el diseño hecho únicamente con Software Libre.
Bueno, pues yo como los locos, sigo a lo mio. Mi Proyecto con Kicad ya está de viaje en China y en un par de semanas aproximadamente palparé los resultados :-D
Creando librerias para kicad como churros (y me quedo corto).
Pues si, en en siguiente enlace podemos encontrar un script para la creación rápida de librerías de componentes. Además genera previsualización del resultado final en formato png ¡¡¡Chulísimo!!!
Como lo prometido es deuda y yo prometí hace unos meses que probaría el paquete kicad y después os contaría mis experiencias, pues aquí estoy dispuesto a cumplir como está mandao…
Impresiones personales
Bueno, pues después de varios meses utilizando kicad para un proyecto mas o menos profesional y partiendo desde cero, tanto en la captura de los esquemas como en la creción de algunos componentes que no existian en las librerías, he de decir que los resultados me han sorprendido gratamente.
Ésta suite de diseño electrónico, está compuesta básicamente por un editor de esquemas electrónicos, un editor de PCBs, un editor de asociaciones componentes-huella (para el diseño del PCB) y un visor de archivos GERBER. Todo está centralizado bajo un mismo interfaz, desde el que abriendo el archivo de proyecto se puede acceder a todas las partes del proyecto (captura, PCB, etc…..)
El proceso de captura, con ésta herramienta es cómodo y bastante fácil. No hay mucho que contar aquí. Los menús son intuitivos y bastante cómodos. Para la selección de huellas en el proceso de fabricación del PCB, se lanza otra aplicación que permite ir buscando componente a componente, la huella mas apropiada a nuestras necesidades. Así mismo, también puede hacer una prebúsqueda de candidatos para dichas huellas, que unas veces con mayor acierto, otras con menos, pero facilita pelín el trabajo.
A la hora de la creación del PCB, la herramienta cuenta con un algoritmo de posicionado automático de componentes, que aunque no sirve para mucho, al menos viste ;-)
Al igual que antes, también tengo que decir que es intuitiva y fácil de usar. Basta con cargar la netlist generada por las dos herramientas anteriores y él solo busca todos los componentes y los coloca en el PCB. Nuestro único trabajo es ubicar los componentes estratégicamente según necesitemos y tratando siempre de facilitar el trabajo del rutado.
En cuanto al rutado, me ha dejado gratamente impresionado. Hay que decir que le puede llevar bastante tiempo, incluso horas, aunque eso dependerá de la rejilla que hayamos elegido. A menor espaciado, mas tiempo, porque tenemos mas posibilidades de rutado.
El algoritmo genera un rutado bastante bueno, pudiendo especificarle el espacio mínimo entre pistas (clearance). Siempre será necesario repasar el PCB a mano y modificar alguna pista, algo inevitable, pero en general el proceso es bastante rápido.
Como conclusión, kicad me ha parecido una buena herramienta para captura de esquemas y diseño de PCBs, mas recomendable que otras herramientas como por ejemplo gEDA o pcb.
Algunas fotillos
Aquí dejo algunas capturas de pantalla del proyecto en el que he estado trabajando con kicad. Especialmente quiero enseñar los resultados obtenidos con PCB.
Espero que os gusten.
Solo me queda decir que proximamente enviaré a una factoría en Japón los Gerber de los PCBs que diseñé para que me los fabriquen. Cuando lleguen prometo contaros que tal es el resultado final. ;-)
Comparto la opinión del autor de la noticia. Se están perdiendo un gran número de cosas interesantes. Una pena que aún haya quien defienda lo indefendible….
Cómo tracear un programa en C para AVR en GNU/Linux con avarice “in circuit”
Introducción
Bueno, como lo prometido es deuda he conseguido tracear un programa escrito en C para un ATMEGA128 en la propia placa de desarrollo utilizando solamente software libre. Aquí explicaré como lo he hecho y además, como extensión a la receta anterior sobre simulación de código para AVR explicaré como depurar con la herramienta libre ddd, que es básicamente un front-end para gdb muy fácil y cómodo de utilizar.
Así pues, sin mas preámbulos ¡¡¡¡Al turrónnnnn!!!! :-P
Preparando el terreno
Bueno, para nuestros propósitos neceistaremos un AVRJTAGICE. Se trata de un programador/emulador para AVR y soporta muchísimos de los micros de ésta familia.
En lo referente al software, utilizaremos avarice que no es ni mas ni menos que nuestro interface con el JTAG. También haremos uso del ya conocido avr-gdb y de ddd como front-end de avr-gdb.
Bueno, pues suponiendo que seguisteis con atención la receta anterior en la que hablé de cómo simular los AVR, tan solo tendremos que instalar ddd y avarice en nuestra máquina para empezar…
Bueno, para la compilación del código necesitamos exactamente las mismas opciones que para la simulación. De hecho, el proceso es el mismo, ya que en ambos casos usamos avr-gdb. La única diferencia es que avarice no necesita para nada el archivo .bin que creamos. En su lugar utilizaremos el .hex, que será el que carguemos en el microcontrolador para tracear. Por lo tanto podemos seguir utilizando el Makefile de la receta anterior y supondré que, de hecho, estamos trabajando con el mismo proyecto.
Simulando con ddd
Bueno, antes de empezar a tracear, voy a contar como utilizar ddd para simular. En realidad es muy sencillo. De hecho, hay que seguir exactamente todos los pasos de la receta anterior, salvo que en lugar de llamar a avr-gdbtui, se llama a ddd diciéndole que use por debajo a avr-gdb. Resumiendo, tenemos que hacer algo como esto:
Antes de ponernos manos a la obra, explicaré un poco el uso de avarice. Bueno, avarice permite borrar, programar, cambiar los valores de los fusibles, leer el contenido de la memoria del chip, verificar el código del chip y, por supuesto, tracear. Para todo ello necesitaremos, como es de suponer, el JTAG antes mencionado.
Si queremos hacer cosas como por ejemplo borrar un chip, haríamos lo siguiente:
javieralso@avalon:~$avarice -2--erase--jtag usb
la opción -2 se utiliza para decirle a avarice que estamos trabajando con el JTAG mkII, que es algo así como la segunda versión. —jtag usb indica que estamos utilizando la conexión USB del dispositivo. Si quisiéramos utilizar un puerto seríe, habría que sustituir usb por la ruta del archivo de dispositivo del puerto a utilizar.
Para programar un micro:
javieralso@avalon:~$avarice -2--erase--program--file archivo.hex --jtag usb
Después de pasar la opción —program, tenemos que decir qué archivo queremos utilizar. Para se utiliza la opción —file seguida del archivo que queremos transferir.
Si se utiliza la opción —P seguido de un modelo de micro podemos decirle a avarice que estaremos utilizando ése micro. Lo normal es que avarice sea capaz de leer la información de identificación del micro sin problemas.
Siempre que queramos programar un micro, deberemos borrarlo antes de manera explícita, ya que el borrado no se hace de forma automática al iniciar la programación, como si pasa con otros entornos.
Al meollo del asunto: TRACEANDO
Ahora ha llegado la hora de la verdad. Con todo listo, nuestro JTAG conectado al usb del ordenador y a la tarjeta a tracear nos disponemos a empezar. La forma en que se ejecutan las aplicaciones es la misma que en la receta anterior. De hecho, para avr-gdb, avarice cumple exactamente el mismo papel que simulavr y lo ve de la misma manera.
Lanzamos primero avarice, diciéndole que programe el micro si esque no lo habíamos hecho nosotros antes:
Ésto es exactamenet lo que hicimos antes, pero con el añadido de que además, le hemos dicho que se quede escuchando conexiones entrantes por el puerto 1212
Ahora tenemos que lanzar ddd, pero antes necesitamos un archivo de comandos para que los ejecute al comienzo. Éste archivo es casi igual que el de la receta anterior, solo que cambian un par de cosillas, así que lo pongo tal y como lo tengo yo:
set debug remote 1
file rs232toRS485.out
target remote 192.168.0.19:1212
break main
continue
Bueno, podemos ver que el archivo es casi igual. Solo se ha eliminado el load, que aquí lo que hacía era cargar el código del micro en el simulador, cosa que no nos interesaba. También activamos la simulación remota (set debug remote 1).
Una vez hecho ésto, solo nos queda llamar al simulador:
y ¡¡YA ESTÁ!! a partir de ahora, lo que hagamos en ddd se verá reflejado en nuestra placa de desarrollo. Podremos leer variables, asignarles otros valores, etc etc etc. Eso si, existen algunas limitaciones, como por ejemplo que solo podemos tener 3 breakpoints como mucho, pero vamos, menudencias ;-)
Pues nada més. Espero que lo disfrutéis como lo estoy disfrutando yo y que os sea tan útil para vuestros proyectos como lo está siendo para mi ;-)
Cómo depurar un programa en C para AVR en GNU/Linux con avr-gdb
Introducción
Después de haberlo intentado varias veces, habiéndome dado por vencido siempre, he vuelto a las andadas, ésta vez para no parar hasta conseguir depurar un programa escrito que utiliza avr-libc (se puede consultar la receta sobre instalar la toolchain para AVR en éste mismo blog).
Para la depuración he utilizado avr-gdb y simulavr desde distintas máquinas, consiguiendo de ese modo ver en una la ejecución del programa objeto de la prueba y en otra el contenido de los registros y de la memoria del micro.
A partir de ahora, explico cómo lo he hecho todo, desde la compilación (se necesitan parámetros específicos para el enlazador) hasta la puesta en funcionamiento del simulador. Doy por sentando que se conoce el uso de gdb para depurar.
Praparándolo todo
Bueno, para que podamos funcionar tan solo necesitamos simulavr y avr-gdb. En nuestro querido Debian ya sabeis:
Para poder simular el código, debemos pasar la opción -g a avr-gcc. Además, de eso, debemos decirle al enlazador que utilice la opción -gstabs. Os paso directamente el Makefile del proyecto que utilicé como prueba para que lo veais mas claro. Está un poco “guarro”, pero servirá para ilustrar el ejemplo ;-):
Además de lo comentado anteriormente, también se ha marcado una regla que se encarga de la creación de una imagen binaria del código de salida. Ésta imagen es importante, ya que es la que cargará simulavr para poder llevar a cabo la simulación del micro.
NOTA: Para que se pueda ver el contenido de las variables locales dentro del entorno de simulación, es muy importante que el flag de optimización esté puesto a 0. ($(CC) $(CFLAGS) -O0 -c $^).
Simulando
Bueno, una vez que ya tenemos nuestro programita compilado toca simularlo. Supondremos que vamos a correr simulavr y avr-gdb en la misma máquina, aunque ésto no tiene por qué ser así, de hecho yo lo hago en máquinas separadas para poder ver la traza y el estado de los registros. Pero ésto ya va a gusto del consumidor :-P.
Para nuestros propósitos simulavr funcionará como un gdbserver, es decir, le dirá a avr-gdb cómo debe comportarse. Por ello tenemos que arrancarlo primero. Para ello lo lanzamos de la siguiente manera:
¿Qué hemos hecho? pues hemos llamado a simulavr diciéndole que vamos a simular un atmega128. Como queremos ver el contenido de los registros hemos llamado tambíen a simulavr-disp ya que simulavr solo dice a avr-gdb cómo comportarse, pero no muestra información alguna. simualvr-disp es el frontend que nos permite ver el contenido de los registros internos de la máquina que estamos simulando.
Para lanzar avr-gdb crearemos antes un archivo de comandos a ejecutar para “automatizar” un poco el uso. Éste archivo tiene algo como ésto:
file rs232toRS485.out
target remote localhost:1212
load
break main
continue
En él decimos a gdb que cargue el archivo a simular, se conecte con en esta mísma máquina (localhost) y escuchando en el puerto 1212 que es donde por defecto escucha simulavr.
Lanzamos avr-gdb (a mi en especial me gusta mas avr-gdbtui) de la siguiente manera:
javieralso@avalon:~$avr-gdbtui -x comandos.gdb
siendo comandos.gdb el archivo en el que guardamos los comandos anteriores.
Podremos ver como inmediatamente cambian los valores de los registros mostrados en simulavr y avr-gdb queda parado en el main de nuestro programa. Ésto sucede porque nuestro programa empieza a simularse inmediatamente después de lanzar el depurador y para en el primer breakpoint que encuentra, que se encuentra en main (breakpoint por defecto). Cómo antes de eso se tiene que ejecutar código (arranque del micro, configuración de la pila, registros de configuración iniciales, inicialización de memoria, etc….) vemos los cambios en los registros de la máquina reflejados en simulavr. Ahora ya podremos simular/depurar como se hace usualmente con gdb.
¡¡Ale, a disfrutarlo :-D!!
En el futuro…
Actualmente también me estoy peleando con avarice que permite borrar, programar, leer, verificar y depurar “on board” muchos dispositivos de la familia AVR utilizando un AVRJTAGICE y avr-gdb o insight. En cuanto sea capaz de terminar de hacerlo funcionar, prometo explicarlo en otra recetilla. Mientras tanto a esperar pacientemente jugueteando con todo lo que ya tenemos sobre AVR….
Cómo conectar a Internet por medio de un teléfono 3G en un sistema GNU/Linux
Introducción
Explicaré como he conseguido conectarme a internet desde mi Debian. En concreto yo me he conectado a través del operador Simyo, que ofrece una tarifa de internet móvil de lo mas competitivo que he visto (perdón si ha parecido que hago publicidad, pero me ha parecido un "chollo" y tengo que compartilo con vosotros :-D).
Ingredientes
Ésto es lo que yo he utilizado:
Teléfono libre con tecnología 3G (yo en concreto he utilizado un Nokia 6630)
Una tarjeta Simyo
wvdial
También supondremos que tenemos tanto una conexión bluetooth establecida con nuestro teléfono en /dev/rfcomm0 como una conexión USB en /dev/ttyACM0.
Configuración de wvdial
La conexión la estableceremos a través de wvdial. Para ello deberemos crear un archivo llamado .wvdialrc con el siguiente contenido:
En una entrada anterior de mi blog hablé acerca de kicad, un software libre para desarrollo electrónico. Prometí contar los resultados y bueno, lo prometido es deunda....
Segunda entrega de esta serie de recetas sobre el movimiento homebrew para ésta consola...
En una receta anterior de éste mismo blog hablé sobre la instalación de las herramientas para poder programar la NDS bajo GNU/Linux. El problema es que el tiempo pasa y los scenners siguen trabajando y claro, cometen errores y las cosas dejan de funcionar como lo hacían antes (menos mal que suele ser de forma temporal). Con ésto quiero decir, que a día de hoy, la toolchain no compila correctamente, así que me he visto obligado a buscar por ahí la toolchain precompilada y a instalarla en mi equipo.
He conseguido instalar libnds, libfat, dswifi y PAlib. Ésta última es una una abstracción a alto nivel de funciones para vídeo, texto, audio, etc... que tienen por debajo libnds.
Buscando por ahí también he encontrado mas información y tutos sobre ésta última librería, en la página que comento mas arriba, así que me he decido a empezar a trastear en mis pocos ratos libres con PAlib.
Para empezar, después de conseguir instalar las librerías precompiladas en mi máquina, las subí a arco. Dentro del paquete dsTools.tgz se encuentra el árbol de directorios ya montado con toda la toolchain. Para instalarla, basta con descomprimir el paquete dentro de un directorio cualquiera de nuestra máquina y agregar las rutas a nuestros PATHs. Para ello, suponiendo que hemos descomprimido el paquete dentro del directorio /usr/local/stow/dkp/ tan solo tenemos que añadir lo siguiente al archivo ~/.bashrc:
Un nuevo entorno de desarrollo electrónico libre, multiplataforma y con muy buena pinta: kicad
Introducción
kicad es un entorno de desarrollo para electrónicos totalmente libre, multiplataforma y (en apariencia) fácil de utilizar y versátil.
Dispone de los siguientes módulos:
Kicad: El gestor de proyectos en sí.
Eeschema: Programa para la captura de esquemas.
PcbNew: Para la creación de los pcbs.
Gerview: Visor de archivos gerber.
Cvpcb: Programa para la selección de huellas para los componentes.
Su instalación en Debian es muy sencilla con el uso de APT.
Actualmente me encuentro evaluando el paquete de la mejor forma posible: Migrando un proyecto electrónico a ésta suite. En principio, una vez que te vas acostumbrando, es fácil e intuitivo. La creación de librerías es rápida y la integración entre todas las herramientas no deja mucho que desear.
Estoy haciendo una librería con componentes propios y existen otras librerías con componentes y sus huellas exportados de las librerías de eagle. Para tenerlo todo mas a mano, he subido al repo público de Arco las librerías exportadas que estoy utilizando y las que estoy haciendo yo. Para descargarlas, puedes utilizar subversion.
Para finalizar...
De momento seguiré haciendo pruebas e intentaré llevar a buen puerto el proyecto en el que estoy. No creo que tarde mas de dos semanas desde hoy en acabar la captura e intentar la realización del PCB. En cuanto lo tenga todo, prometo escribir, contando, aunque sea un poco por encima, como empezar con éste software...
Cómo mantener sincronizados directorios en varios PCs de forma rápida y sencilla utilizando la herramienta libre unison-gtk.
Introducción
Si tienes varios PCs que usas frecuentemente (por ejemplo un portátil y el ordenador de casa o el del trabajo) tal vez te haya surgido la necesidad de tener ciertos directorios con información “sensible” sincronizados entre dichos PCs. Una forma muy sencilla de conseguir eso en GNU/Linux es utilizar la herramienta libre unison.
Ingredientes
unison
unison-gtk
En mi caso concreto, he utilizado la versión 2.9.1, es decir, los paquetes
Tienes que instalar los dos paquetes, ya que aunque unison-gtk necesita de unison, no lo instalará como dependencia. También necesitas ssh.
Una nota importante es que debes instalar la misma versión de unison en todas las máquinas que vayas a sincronizar. Si intentas sincronizar dos máquinas con distintas versiones de unison, se producirá un error y se abortará la sincronización.
Configurando unison
Este paso sólo hay que realizarlo en una de las máquinas. Suponiendo que has instalado unison2.9.1-gtk lo invocas:
javieralso@richie:~$unison-2.9.1-gtk
Esto abrirá la ventana principal de unison-gtk. Ahora debes crear un perfil. Para ello pulsa el botón Create new profile y escribe un nombre para dicho perfil, por ejemplo “Documentos casa”.
Verás que se ha añadido dicho perfil a la lista de perfiles existentes. Si haces doble click te aparecerá una ventana en la que te pedirá que introduzcas el nombre del directorio que deseas sincronizar dentro de tu máquina local. Pon por ejemplo el directorio ~/Documentos. Pulsa en “aceptar” y pasarás a la ventana de selección del directorio con el que deseas sincronizar el directorio anterior.
Utiliza SSH para conectar, selecciona esa opción y elige el directorio en la máquina remota con el que deseas sincronizar tus archivos, por ejemplo ~/Documentos.
En el campo Host escribe IP del host con el que deseas sincronizar o el nombre de la máquina si están en el DNS de tu red. Si el usuario de la máquina remota es distinto del usuario de la máquina local en la que deseas sincronizar, escribe el nombre.
Sincronizando
Con lo anterior unison está configurado y listo para la sincronización. Ahora, en la ventana principal, selecciona el nombre del perfil que quieras. Dependiendo de la versión que tengas instalada, te pedirá la clave del usuario del equipo remoto, bien por consola (desde la que has invocado a unison-gtk) o bien en una ventana emergente. Una vez que introduces dicha contraseña, unison comenzará a escanear todos los archivos y subdirectorios contenidos en el directorio principal. La primera vez puede tardar tiempo. Cuando termine, verás aparecer una lista con todos los archivos y subdirectorios tanto en la máquina local como en la remota. unison hará una propuesta de actualización basada en la antiguedad de los archivos. Intentará que prevalezcan los archivos más modernos frente a los mas antiguos.
Todo ésto se verá con una flecha que indica la dirección en la que se llevará a cabo la actualización. Si hubiese dos archivos o subdirectorios con el mismo nombre y unison no supiese cual de los dos elegir, pondría una interrogación roja entre medias. Puedes cambiar la dirección de sincronización con las teclas de cursor. Cuando estés seguro, pulsa el botón GO y unison comenzará la sincronización.
La primera vez que se lleve a cabo la sincronización, es muy recomendable que uno de los directorios se encuentre completamente vacío; de ese modo se evitan mucho problemas.
Algunos parámetros que hay que configurar (modificando las librerías) para que las aplicaciones escritas en tinyOS 2 funcionen bien y/o se adapten a tus necesidades específicas.
Frecuencia de transmisión/Recepción de la radio
Los dispositivos que utilizan el chip de radio cc1000 de Chipcon pueden no funcionar bien en tinyOS 2 debido a que en las motas, estos chips deben estar configurados para funcionar en el rango de 915 a 998 MHz y por defecto no es así. La forma de solucionar ésto es editando el archivo CC1000Const.h. Suponiendo que tienes el árbol de tinyOS instalado en /opt/tinyos-2.x/, deberás modificar el archivo /opt/tinyos-2.x/tos/chips/cc1000/CC1000Const.h y hacer que la macro que define la constante CC1K_DEF_PRESET quede de la siguiente forma:
De éste modo, en los futuros programas, la radio se configurará para funcionar a la frecuencia correcta.
Longitud del campo de datos en la estructura message_t
La estructura message_t proporciona una abstracción para enviar y recibir mensajes a través de la radio o del puerto serie. El campo de datos de ésta estructura, tiene una longitud máxima prefijada de 28 Bytes, que en muchos casos puede ser mas que suficiente, pero en otras ocasiones podemos quedarnos cortos.
Para solucionar ésto, debemos pasar a nesC el flag DTOSH_DATA_LENGTH para indicar la longitud máxima que queremos que tenga dicho campo de datos.
La forma de hacer ésto es editando el fichero Makefile de tu proyecto añadiendo lo siguiente:
NESC_FLAGS ?= -DTOSH_DATA_LENGTH=250
COMPONENT=sampleApp
include $(MAKERULES)
No suele ser recomendable definir una longitud mayor que esa, ya que puede haber problemas de compilación.
Instalación de librerías propias
Si tenemos pensado escribir nuestros propios módulos e interfaces, como se explica en una receta publicada también en éste portal, podemos guardarlos todos bajo un mismo directorio (por ejemplo ~/tinyOS_libs/) y a continuación hacer lo siguiente para que el compilador sepa encontrar dicha librería:
Editamos el archivo Makefile de tu proyecto para hacer que incluya el directorio de tu librería:
NESC_FLAGS ?= -I ~/tinyOS/libs/
COMPONENT=sampleApp
include $(MAKERULES)
Con esto, cuando compiles, se buscarán las librerías también en ese directorio.
Después de pelearme con tinyOS he conseguido comprender mas o menos como va el tema de los módulos y wiring (conexionado lógico entre módulos). Aquí dejo un ejemplo muy básico y la explicación que ilustra lo suficiente para poder comenzar a hacer cosillas.
Introducción
tinyOS se basa en el uso de módulos que se "cablean" (wiring) entre sí para dar lugar a la aplicación en sí. Este cableado se lleva a cabo en lo que se conoce como configuraciones y podemos tener montones de configuraciones distintas para una misma aplicación. De este modo, podemos conseguir que una misma aplicación pueda correr en distintas arquitecturas hardware sin apenas tocar código, solo modificando las configuraciones, lo que hará que se utilicen unos módulos u otros que se encargan del control a mas bajo nivel.
Básicamente, aquí hablaré de:
Módulos
Interfaces
Configuraciones
Todo el código de ejemplo que se usa en esta receta puede descargarse, vía subversión, del repositorio público de ARCO de la siguiente forma:
javieralso@richie:~$svn co https://arco.inf-cr.uclm.es/svn/public/prj/tinyOS
y con ésto ya podremos seguir todos los ejemplos dados a continuación.
Interfaces
Las interfaces se pueden definir como la parte "visible" de los módulos. No se puede acceder a ninguna función de un módulo si antes no ha sido definida en una interfaz.
Una interfaz puede ser provista por varios módulos distintos. Por ejemplo, podemos tener una interfaz de comunicaciones que abstraiga los procedimientos de envío y recepción de mensajes y varios módulos que hagan uso de esa interfaz, uno para cada tipo de hardware subyacente (por ejemplo no se maneja igual el hardware de comunicaciones de una mica2 que el de una telos). Los métodos serán los mismos y se llamarán igual (la interfaz es la misma), pero la implementación interna puede ser totalmente distinta. Nosotros lo veremos como una caja negra.
En nuestro ejemplo se utilizan dos interfaces: interfaz2, en el archivo interfaz2.nc e interfazPRB en el archivo interfazPRB.nc. Las implementaciones son las que siguen:
para interfazPRB.nc
Bueno. Se puedes ver, escribir una un interfaz es bastante simple. Lo único que hay que hacer es especificar el nombre de la y los comandos de que consta. Estos comandos son los prototipos (como se llama en ANSI C) de las funciones precedidos de la palabra reservada command. Si quisiesesmos declarar señales, utilizariamos el modificador signal. El nombre del archivo debe de ser el mismo que el del interfaz, respetando las mayúsculas y con extensión .nc.
Módulos
Los módulos implementan bloques funcionales generalmente de un nivel de abstracción más bajo que el bloque que los referencia. Un mismo módulo puede proveer varias interfaces y por lo tanto puede implementar distintas funcionalidades (Por ejemplo el módulo AMSender provee las interfaces Packet, AMPacket, AMSend, etc...). Lo lógico es que todos los conjuntos de funciones (interfaces) que implementa un módulo guarden algún tipo de relación.
En nuestro caso, utilizamos dos módulos: modulo2C, implementado en modulo2C.nc y moduloC implementado en moduloC.nc.
Éste es el contenido de los archivos:
modulemodulo2C{provides{interfaceinterfaz2;/*
Única interfaz proporcionada por el módulo
*/}}implementation{commandvoidinterfaz2.i2c1(){intv1=5;intv2;v2=v1;}commanduint16_tinterfaz2.i2c2(intc){return(uint16_t)2*c;}commanduint16_tinterfaz2.i2c3(chard){return(uint16_t)d*d*d;}}
Cada uno de los módulos se compone de dos partes. La primera es la declaración. En ella se especifica el nombre del módulo, así como las interfaces que provee y las interfaces que usa. En el caso de moduloC, por ejemplo, podemos ver que la interfaz que proporciona es la interfaz interfacePRB y utiliza las interfaces interfaz2 y Leds.
A continuación sigue la implementación. Aquí debe hacerse la implementación de cada uno de los comandos especificados en la interfaz. En éste caso no hay señales. Si las hubiese, la forma de lanzarlas es llamarlas como funciones normales (precedidas de la palabra reservada signal) cuando sea necesario. En éste caso, como se trata solo de un ejemplo, las funciones son totalmente triviales.
No queda mucho mas que comentar acerca de los módulos. Básicamente, después de ésto solo faltaría escribir la configuración con el wiring entre módulos e interfaces. ¿Y qué es eso?, pues ahora mismo lo explico.
Configuraciones
Como se ha dicho anteriormente, una aplicación escrita para tinyOS se compone de implementación de módulos y de configuraciones. En algunos casos, pueden hacerse aplicaciones solo con archivos de configuraciones. Un archivo de configuración consiste básicamente en un archivo formado por los módulos (o componentes) a utilizar en la aplicación y la relación que hay entre dichos módulos y las interfaces utilizadas por otros módulos.
En un principio esto puede parecer bastante lioso, así que nada mejor que verlo con algún ejemplo. Veamos primero el archivo de configuración moduloEjm.nc:
Paso a paso para no liarnos:
Lo primero que tenemos que hacer es indicar que estamos hablando de una configuración, en éste caso moduloEjmC. Como siempre, dicho nombre coincide con el del archivo en el que se aloja. Ésta configuración, provee una interfaz (aunque podrian ser mas), la interfaz interfazPRB.
En la parte de implementación vemos que utilizamos tres módulos o componentes: LedsC, modulo2C y moduloC. Éstos son los módulos cuya funcionalidad necesitaremos para llevar a cabo las tareas de la configuración en la que estamos trabajando.
Después nos encontramos con la parte de wiring. Aquí tenemos dos conexiones:
moduloC.Leds -> LedsC;
moduloC.interfaz2 -> modulo2C;
¿Qué hace ésto? fácil, hemos conectado la interfaz Leds utilizada en la implementación del módulo moduloC con el componente (o módulo) LedsC que provee dicha interfaz y que hemos declarado anteriormente en la sección components. Con ésto, cada vez que invoquemos a alguno de los comando de ésta interfaz, lo que en realidad estaremos haciendo será llamar a los métodos con dicho nombre que haya implementados en el módulo LedsC. Si tuviésemos otro módulo con la misma interfaz, podriamos haberlo utilizado indistintamente, con la única diferencia de la implementación que esconda detrás, claro.
La segunda conexión ya queda algo mas clara, conecta el interfaz interfaz2 de moduloC con el módulo modulo2C que provee dicha interfaz y que nosotros mismos escribimos.
Finalmente, en la última línea, podemos ver una asignación distinta a todas las vistas anteriormente. Ésta asignación lo único que hace es conectar la interfaz que se provee (interfazPRB) con el módulo que proveerá la funcionalidad a dicha interfaz, que en éste caso es moduloC.
Ahora, lo único que falta es utilizar todo ésto:
Aquí tenemos el contenido de ejmAppC.nc, que tiene la configuración ejmAppC.
Esta configuración podemos ver que no provee interfaz alguna, pero que sí usa componentes, en concreto MainC, ejmC y moduloEjmC. Los dos últimos son familiares ;-)
Después tenemos los wirings: uno que conecta la interfaz Boot del módulo MainC (utilizado para informar de que tinyOS ha arrancado y demás) con el módulo de mayor nivel de nuestra aplicación (la aplicación en si), ejmC y otro que conecta la interfaz interfazPRB que utiliza la aplicación, con el módulo (aunque lo hayamos "implementado" en un archivo de configuración, lo estamos tratando como un módulo, ya que esa configuración corresponde a la de un módulo) moduloEjmC.
Con ésto, ya solo nos falta implementar las funciones de nuestro programita propiamente dicho:
Aquí puedes ver cómo se define un módulo llamado ejmC y que utiliza las interfaces Boot e interfazPRB que ya conectamos anteriormente a cada uno de los módulos que queríamos que nos diesen la funcionalidad.
A continuación, en la parte de la implementación tan solo tenemos que implementar las funciones y comandos que necesitemos para dar la funcionalidad que queramos a nuestro programita.
¿Qué por qué este es el módulo de mayor nivel? Bueno, por nada en especial. Simplemente que implementa la interfaz Boot del módulo MainC, quien lanzará el evento Boot.booted cuando tinyOS termine de arrancar y por tanto entregará el control del hilo principal a dicho evento, comenzando la ejecución del programa por ahí.
Programación de bucles de eventos en C para GNU/Linux utilizando GLib
Introducción
Siguiendo con la línea de david en su entrada GLib IO Channels con python en el que implementaba el patrón reactor en python, ahora haré una pequeña introducción a la programación de éste mismo patrón en C.
Patrón reactor en C.
El código de ejemplo para ésta receta se encuentra disponible en el repo público de Arco y puede ser descargado utilizando subversion. Aquí se muestra el contenido del archivo con la implementación del patrón reactor:
El código que se muestra es bastante simple y fácil de entender. Al principio, después de las inclusiones de las cabeceras necesarias, se declaran tres funciones que consisten en los manejadores de los eventos capturados. Los dos primeros son exactamente iguales y lo único que hacen es escribir un mensaje por pantalla. El tercer manejador se llama cuando se introducen datos por teclado. Lo único que hace es inicializar un buffer en el que después copiaremos los datos introducidos y finalmente los imprimiremos. Podemos ver que éstas tres funciones devuelven TRUE, mas adelante se verá el porqué.
La "chicha" del asunto está en la función main, que es la que se encarga de asignar los manejadores anteriores a cada una de las señales y de inicializar el bucle de eventos.
Las llamadas a g_timeout_add asignan los dos primeros manejadores a un evento de tiempo, que se generará, respectivamente, cada segundo y medio segundo. Por su parte, la llamada a g_io_channel_unix_new asigna el tercer manejador a los eventos de escritura generados a través de la entrada estándar (el teclado).
Finalmente, la penúltima línea se encarga de poner en funcionamiento el bucle principal, creado por la función que se llama como primer parámetro. En ese momento, el programa se queda "congelado" ahí y lo único que hace es esperar a que se produzcan los eventos programados (los dos de temporización y la entrada por el teclado).
Antes comenté que los manejadores siempre devolvian TRUE. Ésto se debe a que si devolviesen FALSE, no volverían a ser llamados. Así conseguimos que los manejadores vuelvan a ser ejecutados cuando se producen de nuevo los eventos.
¿Qué? ¿Cómo? ¿Que tienes una Nintendo DS por casa? ¡¡Estás de suerte!!. Con unos minutos, la lectura de esta recetilla, un espíritu jóven y la ayuda del Software Libre tienes en tus manos un maquinón al que le podrás sacar todo el jugo. Veamos cómo....
Introducción
Pues lo dicho. La Nintendo DS (NDS a partir de ahora), es un "cacharrito" que tiene dentro un ARM7 y un ARM9 trabajando en paralelo. También dispone de WIFI, pantalla táctil y un buen audio (entre otras muchas cosas, aún no he podido profundizar mucho en la arquitectura hardware de la máquina).
Si queremos introducirnos en el mundo del homebrew para ésta consola (o scene, con lo que encontrareis mas cosas googleando -thanks int0-) , gracias al Software Libre lo tenemos francamente fácil, ya que tenemos en nuestras manos herramientas tales como emuladores, librerías cruzadas, etc..... es decir, una toolchain completa.
Aquí iré explicando paso a paso cómo la he instalado en mi máquina, ya que todo ésto ha sido la "recopilación" de varias búsquedas por la red y de varias consultas en algún que otro foro (gracias chicos, por la paciencia con los novatos ;))
Primeros pasos: Descargando fuentes
Todos los fuentes de las librerías que necesitamos se encuentran en sourceforge. Aquí se pueden encontrar tanto las librerías ya compiladas como los fuentes. Yo en mi caso he preferido bajarme los fuentes y compilarmelos (como está mandao 8)). Ésto es todo lo que hace falta para poder empezar a trabajar:
build scripts
libfat
dswifi
y por supuesto nds-examples
Nos bajaremos las útlimas versiones de dichos paquetes para evitar problemas de compatibilidades. En arco he dejado los paquetes que he utilizado yo. En el momento en el que escribo este documento (marzo de 2007), la versión de build scripts es la 20060724. Ésta descarga unos paquetes un poco "anticuados", así que he modificado uno de los scripts que hay dentro del paquete y lo he dejado fuera. Éste script debereis descargarlo para poder compilar la toolchain correctamente.
Instalación
Bueno, pues suponiendo que tenemos el directorio nds que hay en ARCo dentro de nuestra máquina, procederemos a compilar la toolchain.
Entramos en el directorio scripts y descomprimimos el paquete que contiene los scritps de instalación. Una vez que hayamos hecho eso, sobreescribimos el script build-devkit.sh con el script del mismo nombre que hay en el raiz. Es decir:
javieralso@Gezel:~/nds/scripts$bunzip2 -c buildscripts-20060724.tar.bz2 | tar xf -
javieralso@Gezel:~/nds/scripts$cp-f ../build-devkit.sh ./
A continuación ejecutamos el script. Cuando hagamos ésto, nos preguntará para qué arquitectura queremos el kit. En nuestro caso la queremos para arm (ds, gp2 y gba), así que pulsamos la opción 1. Después le decimos que queremos que descargue los paquetes y finalmente dónde queremos que nos compile la toolchain:
javieralso@Gezel:~/nds/scripts$./build-devkit.sh
This script will build and install your devkit. Please select the one you require
1: build devkitARM (gba gp32 ds)
2: build devkitPPC (gamecube)
3: build devkitPSP (PSP)
1
The installation requires binutils-2.17, gcc4.1.1 and newlib-1.14.0. Please select an option:
1: I have already downloaded the source packages
2: Download the packages for me (requires wget)
2
Please enter the directory where you would like 'devkitARM' to be installed:
for mingw/msys you must use <drive>:/<install path> or you will have include path problems
this is the top level directory for devkitpro, i.e. e:/devkitPro
/usr/local/stow/dkp
Yo en mi caso le he dicho que quiero que me instale la toolchain en el directorio /usr/local/stow/dkp, aunque ésto no es nada crítico.
En éste momento, comenzará la descarga, descompresión, compilación e instalación de los paquetes. Deberemos ser pacientes, ya que puede tardar su tiempo. Cuando termina de descargar los paquetes nos pide confirmación para comenzar la instalación. Confirmamos y ya ta :D
Después de finalizar ésta parte, deberemos exportar los PATH's para que cuando compilemos los makefiles sepan cuales son las rutas. Para ello editamos nuestro archivo ~/.bashrc y añadimos lo siguiente:
Vosotros debereís introducir vuestras rutas. Cuando hayais hecho ésto tendreis lo básico funcionando y ya podreís hacer programas bastante interesantes...
Librerías extra
Dentro del subdirectorio libs tenemos los fuentes de las librerías para la wifi (dswifi) y los fuentes para las librerías de sistema de archivos FAT (libfat). Éstas librerías no se instalan de forma automática, pero es muy fácil hacerlo manualmente.
Instalación de dswifi
descomprimimos el archivo con las fuentes (en una shell nueva, para que los PATHs se hayan cargado) y ejecutamos make y después make install:
javieralso@Gezel:~/nds/libs$bunzip2 -c dswifi-src-0.3a.tar.bz2 | tar xf -
javieralso@Gezel:~/nds/libs$make
javieralso@Gezel:~/nds/libs$make install
Con ésto, la librería habrá quedado instalada en nuestro sistema :D
Instalación de libfat
PENDIENTE
A probarlo todo :P
Bueno, pues ahora ya estamos listos para compilar algunos ejemplos y probarlos en nuestra NDS. Dentro del directorio ejemplos tenemos un paquetito con montones de ejemplos de manejo de la wifi, la pantalla táctil, gráficos en 2D y 3D y un largo etcétera. Para probarlos es tan fácil como descomprimir el paquete y ejecutar make desde el raiz. Si todo funciona bien (que debería ser así) se generará un directorio bin en el que estarán todos los archivos *.nds listos para ser cargados en nuestra NDS
Y para la próxima....
Bueno, pues por mucha consola que tengamos, no está de mas tener un emulador para hacer pruebas rápidas sin tener que cargarlas en la máquina (que puede ser un poco engorroso). Próximamente explicaré como instalar dsmume, un emulador bastante majo que corre también en GNU/Linux y que aunque tiene algunas limitaciones, nos permitirá, por ejemplo, probar varios de los ejemplos que hemos compilado anteriormente.
Un manual muy básico de cómo manejar señales en GNU/Linux
Introducción
GNU/Linux soporta las llamadas Señales fiables POSIX y las Señales en Tiempo Real POSIX. No voy a listar todas éstas señales, ya que se encuentran en signal.h y se pueden consultar en cualquier manual de GNU/Linux
Para explicar el proceso de escribir un manejador de señales (en C), usaré un ejemplo muy sencillo y lo iré explicando después.
El código de ejemplo
Bueno, éste es el código que utilizaré como ejemplo. Guardadlo en un archivo con el nombre que querais y lo compilais con gcc (como toda la vida :D)
Bueno, el código está formado por dos funciones, una es el main de toda la vida. La otra, timerHandler es el manejador de señales, que se ejecutara, en este caso, cada vez que se lance una señal SIGALRM.
La función del manejador no tiene mucho misterio. Tan solo se trata de una línea que imprime el valor de un contador y una función que restaura el temporizador para que se lance una señal un segundo después de ejecutarse (Bueno, no es un segundo exacto, recordad que estamos en un entorno multiprogramado ;)).
La función main empieza con una instancia de una estructura tipo sigaction. Es en ésta estructura donde se guarda la información de qué manejador se asocia a qué señal. La implementación de sigaction es la siguiente:
y la utilidad de los campos de dicha estructura es la que sigue a continuación:
sa_restorer: Está obsoleto y no debería utilizarse. POSIX no especifica ningún elemento sa_restorer.
sa_handler: Especifica la acción asociada a la señal signum. Ésta acción puede ser:
SIG_DFL para la acción por defecto,
SIG_IGN para ignorar la señal o
un puntero a una función que actue como manejador de dicha señal.
sa_mask: Proporciona una máscara de señales que deben ser bloqueadas durante la ejecución del manejador de señal. Además, la señal que activó el manejador actual también será bloqueada a menos que se utilicen los flags SA_NODEFER o SA_NOMASK.
sa_flags: Especifica un conjunto de flags que pueden variar el comportamiento del manejador de señal.
signum: Especifica la señal a capturar y puede ser cualquier señal válida excepto SIGKILL y SIGSTOP.
Bueno, podemos ver que después de limpiar (o iniciliazar para los mas puristas) la estructura, asignamos el manejador que queremos que sea ejecutado en el campo sa_handler. sa_restorer es mejor inicializarlo a NULL para evitar problemas.
A continuación, se llama la función sigaction (¿de qué me sonará el nombre? ;)). El prototipo de ésta función, es el que sigue:
int signum: Se utiliza para especificar la señal que desea capturarse.
const struct sigaction *act: Especifica la estructura sigaction en la que se encuentra la información sobre el manejador a asociar a la señal capturada.
struct sigaction *oldact: Una estructura en la que se almacenará la información del antiguo manejador instalado para esa señal. Se puede dejar a NULL si se desea.
La función sigaction retorna 0 si todo ha ido bien y -1 si ha habido algún error.
En nuestro caso, utilizamos ésta función para asociar timerHandler con la señal SIGALRM.
Una vez hecho esto, ya solo queda llamar a la función alarm para que se lance una señal SIGALRM en un segundo y generar un bucle infinito para que el programa no finalice nunca ;).
Un ejemplo de programación utilizando la librería libusb
Pues eso, éste verano desarrollé un cliente para el Bootloader USB que se encuentra en los AT90USB1287. Luego resulta que me dijeron que ya existía uno llamado dfu-programmer (y mira que pregunté antes de ponerme con el mio...). En fin, mi programador no es que sea una obra de la ingeniería del software, pero por lo menos es un ejemplo del uso de la librería libusb, que en mi opinión no está nada mal. Para escribir el cliente necesité consultar el datasheet del bootloader que lleva programado éste micro.
Tengo que decir que el cliente lo programé con cierta prisa y que algunas funciones ni siquiera estan implementadas del todo. Tenía pensado arreglarlo con el tiempo, pero bueno, como encontré el dfu-programmer ese pues ya no me molesté.
Pues nada, espero que esos trozos de código os sean útiles a alguno.
Un saludo.
Ubicación del código fuente y los esquemas de Yago dentro del repo público de ARCO
Buenas a todos. Como lo prometido es deuda, aquí os dejo un enlace al código y los esquemas de Yago.
De momento no tengo mucho. En src podreis encontar además de un Makeconf un poco genérico que encontré por ahí y que luego modifiqué, una carpeta con las pruebecillas que voy haciendo. De momento no hay mucho. Hay un par de archivos, yago_drv.c y yago_drv.h que pretendo que sean los drivers "a bajo nivel" del robot, aunque puede que yago_drv.h lo acabe fragmentando en mas archivos. Ya iré viendo (o me ireis aconsejando, espero ;-)).
En cuanto a los esquemas, están los de la tarjeta de periféricos (con un pequeño fallo en los transistores que aún no he corregido) y los de la etapa de potencia para los motores. Ésta última placa la rescaté del proyecto arcoBot, que se quedó un poco "colgado" (un minuto de silecio por arcoBot, que siempre estará en nuestros corazones ¿verdad brue? :-().
Bueno, pues ésto es lo que hay. De momento poco. Ya iré sacando tiempo para explicar cosillas y seguir actualizando. Aunque creo que la mejor manera de explicar es que me pregunteis. Por lo pronto, en cuanto pueda, me pongo a comentar un poco el tema de los motores y así empiezo por algún sitio.
Un saludo.
Os presento un robotillo que estoy haciendo en mis ratos libres. Se trata de un bicho basado en un micro AVR (en concreto usa un AT90USB1287) y que dispone de varios sensores como infrarojos, sensor PIR, ultrasonidos, etc… Tanto el software como el hardware que desarrolle para este proyecto será libre, y además todo (incluidos los diseños de PCBs) está hecho con software 100% libre.
Mi intención es ir publicando todo lo que vaya haciendo referente a él por aquí, para que a quien le interese pueda meter mano y, ¿por qué no? dar ideas. En cuanto el repo público de ARCO haya sido migrado, haré disponible el código fuente y los esquemas electrónicos.
Introducción
Pues eso. Yago, como he decidido que se llame la criatura (bueno, lo decidieron en consenso unos amigos durante una larga noche) utilizará un microcontrolador de la casa ATMEL. El micro elegido es un AT90USB1287. En principio iba a haber utilizado uno de sus hermanos mayores y mas antiguo, pero un amigo al que le estoy haciendo un proyecto basado en éste micro, me regaló una pequeña placa de desarrollo y decidí utilizarla (¡¡gracias Pandro!! ;-)). Bueno, pues toda la información que querais del micro, la podeis consultar del datasheet del micro. La plaquita de desarrollo en la que me estoy basando se llama USBKEY y se puede conseguir a través de digikey.
¿Qué va a tener?
Bueno, pues en principio y como es de suponer, el cacharro en sí puede tener lo que nos dé la gana que tenga. Yo en mi caso he comprado un par de sensores de infrarrojos, un detector de sonido, un medidor de distancias ultrasónico, un sensor PIR, un par de bumpers delanteros, un servo para posicionar los ultrasonidos…. Vamos, que lo que queramos.
La estructura es metálica, la he hecho con un juego de esos copias de mecano que me costó 9€ en una juguetería. Imaginación al poder (y lo digo yo que se me da fatal la mecánica ;-)). Para el tema de la tracción, después de haber probado con motorreductoras, he decido usar unos motores FUTABA S3003 trucados. Tranquilos que ya os diré donde compré cada cosa y las manipulaciones que hice.
Con respecto a la electrónica, aparte del AT90USBKEY, en cuyo datasheet se puede ver el esquema electrónico, utilizo otra tarjeta como extensión de periféricos que diseñé enteramente con software libre. Ésta tarjeta dispone de 16 entradas TTL, 12 salidas TTL y 4 de potencia, una memoria I2C y un reloj calendario en tiempo real. ¿Qué por qué poner estas dos cosas si pueden parecer tonterias para un microbot? muy fácil, porque quise, mas para trastear :-P
Bueno, pues de momento, para ir abriendo boca, ya os he contado un poco cuales son mis intenciones. Espero que os gusten y que alguno se anime aunque sea a ir leyendo lo que hago. Por lo pronto, os dejo alguna que otra fotillo para que lo vayais viendo….
Una vista del lateral trasero…
Y un primer plano del sensor PIR trasero y los infrarrojos…
Siguiendo mis experimentos con el XPORT de Lantronix he descubierto cómo obtener la configuración de este dispositivo, modificarla y aplicársela después. Aquí comento un poco los resultados obtenidos.
INTRODUCCIÓN
En una entrada anterior de mi blog referente al XPORT, comenté un poco ciertas características de este dispositivo y como configurarlo para realizar conexiones activas y pasivas por TCP y envío y recepción de datagramas UDP además de como entrar en su Modo monitor. Esto último permite hacer ciertas operaciones de diagnóstico, como ya comenté en su momento. Aquí las que nos interesan son la obtención de la configuración para su posterior modificación y reconfiguración de la unidad.
OBTENCIÓN DE LA CONFIGURACIÓN
Bueno, para obtener la configuración de la unidad lo primero que tenemos que hacer es entrar en Modo Monitor. Una vez que hemos entrado en dicho modo, pedimos la configuración al dispositivo a través del comando GC:
Welcome to minicom 2.2
OPCIONES: I18n
Compilado en Jan 7 2007, 18:00:43.
Port /dev/ttyUSB0
Presione CTRL-A Z para obtener ayuda sobre teclas especiales
AT S7=45 S0=0 L1 V1 X4 &c1 E1 Q0
OK
*** NodeSet 2.0 ***
0>GC
:20000010000005000000002D00000000000000004C0200001127204EC0A8000AD600000062
:20002010000080000000000000000000000000000000000000000000000000000000000030
:200040104C0200001227000000000000C00000000000000000000000000000000000000049
:1800601000000000000000000000000000000000000000000000000078
:00000001FF
0>
Con esto tenemos la configuración actual del XPORT. Lo que nos ha devuelto es un archivo en formato INTEL HEX. Bueno, para el caso de las conexiones TCP, la dirección de las conexiones activas se encuentra a partir de la dirección 0x18: en nuestro caso podemos ver que la información aquí guardada es C0A8000A. Esto se corresponde con la IP 192.168.0.10. Para el caso del puerto remoto, la información referente se encuentra a partir de la dirección 0x16. Observamos que es 204E, que corresponde con el puerto 20000 usando little endian. Bueno, para cambiar la IP y el puerto tan solo tenemos que modificar la información en estas direcciones (sin olvidar actualizar el último byte de la línea correspondiente al Checksum), enviar el nuevo archivo al xport y reiniciar.
RECONFIGURACIÓN DE LA UNIDAD
Bueno, pues vamos a reconfigurar "al vuelo" el XPORT para asignarle la dirección <192.168.0.20:20150>. Para ello cogemos el arhivo anterior y sustuimos la primera línea por la siguiente:
Después volvemos al modo monitor y con el comando SC enviamos el archivo enterito:
Welcome to minicom 2.2
OPCIONES: I18n
Compilado en Jan 7 2007, 18:00:43.
Port /dev/ttyUSB0
Presione CTRL-A Z para obtener ayuda sobre teclas especiales
AT S7=45 S0=0 L1 V1 X4 &c1 E1 Q0
OK
*** NodeSet 2.0 ***
0>GC
:20000010000005000000002D00000000000000004C0200001127B64EA1432614D600000020
:20002010000080000000000000000000000000000000000000000000000000000000000030
:200040104C0200001227000000000000C00000000000000000000000000000000000000049
:1800601000000000000000000000000000000000000000000000000078
:00000001FF
0>SC
0>RS
NO CARRIER
Una vez que se invoca al comando SC se queda en espera de recibir el archivo de configuración. Cuando se le envía (En la captura mostrada no ha habido eco), responde con 0> para indicar que ha sido guardado correctamente.
Para finalizar se reinicia la unidad con el comando RS. El XPORT tarda unos 10 segundos en reiniciar y acto seguido informa de que está disponible con el mensaje NO CARRIER.
Si volvemos a leer la configuración del XPORT:
El XPort de Lantronix es un dispositivo que permite conectar cualquier cacharrito con puerto serie a una ethernet. Permite la creación de conexiones TCP activas y pasivas y el envio y recepción de datagramas UDP. Por aquí iré explicando un poco los resultados de las pruebas que vaya haciendo con él. Hoy de momento, el tema de las conexiones.
Conexiones TCP
Veamos, según el datasheet y el manual de usuario del XPORT, éste permite conexiones entrantes desde cualquier IP a un puerto determinado, denominado Local Port. A su vez, al XPORT se le pueden programar una IP y puerto al que realizar las conexiones por defecto: Remote host y Remote Port. Las opciones para la creacion de conexiones activas (conexiones creadas por el XPORT) son las siguientes:
No active startup: No genera conexión activa en ningún caso
With any character: Si no existe ninguna conexión activa y se recibe un caracter cualquiera por el puerto serie, el XPORT intenta abrir una conexión con la IP y puerto configurados por defecto y una vez abierta dicha conexión, envia los caracteres que reciba por el puerto serie
With DTR active: Igual que el caso anterior, pero si la línea DRT no se encuentra activa, no intenta abrir conexión
With a Specific start character: Sólo intenta conectar cuando recibe un caracter específico por el puerto serie. Por defecto, si el usuario no especifica otro, el caracter de inicio de conexión es un retorno de carro
Manual connection: Intenta abrir la conexión a una IP y puerto cualquiera que puede ser especificado a través del puerto serie
Modem mode: Permite utilizar comandos AT a través del puerto serie para gestionar las conexiones.
Conexiones activas en Modo Manual
La forma básica de indicar al XPORT a qué IP y puerto conectar utilizando el modo manual es enviar a través del puerto serie comandos que empiecen por el caracter "c", por ejemplo
c192.168.0.10/20000
hará que el XPORT intente conectar al puerto 20000 de la máquina 192.168.0.10
Si la opción Connect Response se encuetra en Char Response, en el momento en el que se establezca la conexión el XPORT responderá con el caracter "C" a través del puerto serie. Si no se puede establecer conexión, responderá con una "N". Cuando se cierra una conexión activa, el XPORT responde enviando el caracter "D".
Con el comando
c0.0.0.0/0
se entra en el modo monitor. Desde aquí, se pueden hacer varias cosas, como leer la configuración actual del XPORT, su IP, MAC, o cambiar dicha configuración a través del puerto serie.
Conexiones activas en modo Modem
El XPORT tiene varias opciones distintas a la hora de emular un DCE tipo módem y pueden elegirse a través de la opción Modem mode. Éstas opciones son las que siguen:
Without echo: El módem no enviará respuesta alguna a los comandos que se le envien.
Data Echo & Modem Response: Aquí el módem envía a través del puerto serie tanto un eco del comando recibido como la respuesta generada por dicho comando. A su vez, esta opción tiene dos subtipos:
Full Verbose: Las respuestas se dan en forma de cadena ASCII.
Numeric Response: Las respuestas se dan en forma de código numérico.
Modem Response only: Es exactamente igual que la opción anterior, con la diferencia de que sólo se envía la respuesta de los comandos ejecutados sin eco alguno de los comandos.
Comandos AT mas importantes
Los comandos que mas importancia pueden tener para la gestión de la conexión son los siguientes:
ATDTx.x.x.x,pppp: Se utiliza para abrir una conexión TCP a la dirección <x.x.x.x:pppp>.
ATH: Cierra la conexión activa en ese instante.
+++: Es la secuencia de escape por defecto. Si durante una conexión se envía dicha secuencia y se espera 1 segundo sin enviar mas datos (siempre hablando desde el DTE al DCE), los siguientes caracteres que se envíen precedidos de un retorno de carro se entenderán como un comando AT.
.
La mejor manera de ver todo ésto es con un ejemplo:
Welcome to minicom 2.2
OPCIONES: I18n
Compilado en Jan 7 2007, 18:00:43.
Port /dev/ttyUSB0
Presione CTRL-A Z para obtener ayuda sobre teclas especiales
AT S7=45 S0=0 L1 V1 X4 &c1 E1 Q0
OK
ATDT192.168.0.1,20001
NO CARRIER
ATDT192.168.0.1,20000
CONNECT
OK
ATH
OK
RING 192.168.0.10
CONNECT
hola
NO CARRIER
En éste ejemplo, el primer OK después de la inicialización realizada por minicom indica que el XPORT está funcionando y listo para recibir comandos AT. Seguidamente intentamos crear una conexión a la dirección <192.168.0.1:20001>, pero el XPORT nos responde con "NO CARRIER" debido a que no hay nadie escuchando en esa dirección.
Lo volvemos a intentar otra vez, en esta ocasión en la dirección <192.168.0.1:20000>. Ahora si ha habido suerte, por lo que el XPORT nos responde con "CONNECT".
A continuación se ve una línea en blanco y seguidamente una confirmación ("OK"). Esto ha sido porque hemos introducido la secuencia de escape "+++". El minicom estaba configurado si echo, por eso no se puede ver, pero el XPORT, transcurrido un segundo, devolvió "OK" indicando que ha recibido e interpretado la secuencia de escape y se encuentra preparado para recibir un comando AT.
El comando que enviamos es "ATH", con lo que cerramos la conexión. Podemos ver que nos responde con un "OK" indicando que el comando ha sido procesado y por lo tanto la conexión se encuentra ya cerrada.
Finalmente, somos nosotros los que conectamos remotamente con el XPORT, desde la IP 192.168.0.10. Se puede observar que el XPORT informa de ello con la cadena "RING 192.168.0.10". Una vez que se ha establecido la conexión, envía "CONNECT" para indicarlo.
Finalmente, al cerrar la conexión remotamente, el XPORT devuelve "NO CARRIER", con lo que sabemos que la conexión se ha cerrado.
Datagramas UDP
En lo referente a Datagramas UDP la cosa cambia bastante, ya que no se tiene tanta libertad para elegir dirección destino como con TCP.
Básicamente, podemos recibir datagramas UDP desde cualquier sitio sin ningún tipo de problemas (obvio), pero a la hora de enviar datagramas UDP, éstos solo pueden enviarse a la dirección configurada dentro del XPORT o a una lista de direcciones también configurada dentro del propio XPORT. De cualquier modo, aún tengo que realizar mas pruebas a éste respecto....
Nota
Es importante remarcar que los comandos introducidos en el XPORT acaban todos con el caracter 0x0d (CR) al igual que las respuestas que envía el XPORT. La única excepción que he encontrado, se produce cuando se hacen conexiones activas: La respuesta tan solo es un caracter ASCII (el "1" de conexión efectuada o el "3" de error en la conexión). Todo esto lo digo refiriéndome al modo "Numeric Response only"
Cómo compilar e instalar GCC para tener soporte para el AT90USB1287 y algunos micros AVR nuevos
Introducción
Algunos micros muy nuevos de ATMEL, como pueden ser el AT90USB1287, muy parecido en prestaciones al ATMEGA128 pero con soporte para USB parece ser que no están soportados en la toolchain para ésta familia de micros. Ésta receta explica como compilar dicha toolchain para poder usar éste micro y algunos mas en nuestros proyectos.
El código fuente de GCC lo podemos descargar del repositorio subversion. Para ello:
javieralso@Gezel:~/avr-toolchain/gcc$svn co svn://gcc.gnu.org/svn/gcc/trunk source
Con esto tendremos los fuentes de GCC dentro del directorio gcc/source.
Una vez que hemos descargado y descomprimido todo el código que necesitamos, procedemos a la compilación e instalación.
Compilando e instalando
La compilación e instalación de la toolchain debe de hacerse en un orden concreto, ya que unas herramientas necesitan a otras para poder compilarse.
En concreto, el orden de instalación es el que se describe a continuación.
Compilación e instalación de binutils-avr
Lo primero que necesitamos es binutils-avr. Para compilarlo entramos en el directorio en el que descomprimimos los fuentes y procedemos:
javieralso@Gezel:~/avr-toolchain/binutils-2.17$sudo make install
Compilación e instalación de avr-gcc
Ahora viene lo mas largo y pesado, y lo que mas probabilidades tiene de fallar, compilar gcc para dar soporte a los micros avr. Dentro del directorio en el que tenemos el subdirectorio con los fuentes (gcc en nuestro caso), creamos otro subdirectorio, por ejemplo build. Éste subdirectorio lo necesitaremos porque no podemos compilar gcc en el mismo directorio en el que están los fuentes. Una vez que tengamos el subdirectorio, entramos en él y ejecutamos el script de configuración ubicado en el directorio de los fuentes desde él:
A ver, después de tres días de peleas con el PIC16F690 ¡¡¡por fin he conseguido un echo del puerto serie!!!. :-P :-P :-P Los puertos de éste micro son como los de cualquier otro PIC, excepto PORTB, que por lo visto se utiliza también como entrada analógica para los (creo que) cuatro canales analógicos de entrada que tiene el micro.
Bueno, ya metidos con el 16F690, voy a explicar como hacer para poder utilizar el oscilador interno del chip (ahorrando componentes, pines del micro y algo de consumo, aunque de ésto último no estoy del todo seguro) ;)
Muy buenas. Navegando por internet encontré una emisora de radio alemana bastante chula. Tiene para elegir entre varios tipos de música, chill out, lounge, dance, etc....
Echadle un vistazo y ya me contareis que os parece.
http://www.radio42.com
Los microcontroladores AVR de ATMEL son una familia bastante potente y asequible. Son RISC y ofrecen características como la programación ISP (en el propio circuito), temporizadores, comparadores analógicos, PWM, RS232 y un largo etcétera. Aquí se explica qué se necesita para poder escribir programas en C y C++
Ingredientes
Lo primero que necesitas instalar son las librerias:
El siguiente ejemplo de Makefile sería para poder compilar un programa dividido en varios ficheros fuente para un AT90S8515. Se trata de un micro con 512 Bytes de RAM, 8 K de Flash y 512 Bytes de EEPROM. Éste modelo ya está un poco obsoleto y ha sido sustituido por el ATMEGA8515, que es totalmente compatible pero ofrece varias mejoras. Aunque este ejemplo servirá para ilustrar la creación de un Makefile:
Esto genera un fichero, prueba.hex con el contenido del código máquina para el microcontrolador. El código está en formato de INTELHEXADECIMAL. También obtendrás otro archivo prueba.dsm en el que puedes ver el desensamblado del código generado.
Los ficheros fuente de los que se parte son prueba.c, potencia.c y williams_8515.c
Otras cosas interesantes
Algunas cosas interesantes que nos ofrecen las binutils son por ejemplo:
$avr-objdump -h prueba.out
prueba.out fue generado por el Makefile y contiene información diversa sobre la compilación. En éste ejemplo, la salida mostrará el tamaño de las diferentes secciones del programa.
$avr-size prueba.out
Hace lo mismo que el comando mostrado anteriormente, pero de forma mas resumida.
Cómo compilar e instalar los drivers para las tarjetas WiFi RT2500 de Ralink en GNU/linux
Introducción
Las tarjetas wifi con chipset Ralink RT2500 cada vez son más comunes. Se encuentran integradas en muchos equipos portátiles y como tarjetas PCMCIA para portátiles, por ejemplo. Por desgracia, los núcleos Linux no traen soporte para este chipset. Poe eso hay tienes que añadirlo tú, aunque la tarea es bastante más fácil de lo que puede parecer.
Lo primero, ¿Tienes una RT2500?
Bueno, para los menos versados en este tema, la forma de saber qué chipset utiliza tu interfaz wireless (así como cualquier hardware de nuestro equipo) es con el comando lspci.
Cuando ejecutes este comando, podrás ver una lista de todos los dispositivos PCI que tienes en tu sistema (si tienes insertada alguna PCMCIA en tu también aparecerá). Ahora solo queda buscar el dispositivo de red que tengas instalado y si ves que su chipset es RT2500 puedes continuar.
Qué necesitamos
Necesitas los fuentes del driver. Éstos se pueden obtener de varias maneras:
Paquete debian:
$apt-get -f install rt2500-source
Bajarte el Código Fuente del driver directamente de internet. De esta forma podrás conseguir la última versión disponible.
También necesitas los headers del núcleo que estés utilizando. En Debian:
# apt-get -f install linux-headers-$(uname -r)
Ahora ya puedes continuar con la compilación.
Compilación e instalación
En primer lugar deberemos crear un enlace hacia el directorio en el que están nuestros headers que se llame linux para que a la hora de compilar se encuentren todas las librerias necesarias:
$ cd /usr/src/
$ ln -s kernel-headers-2.6.8-1-686 linux
Otra cosa importante es que debes compilar este driver con la versión 3.4 de gcc, si no, es muy probable que surjan problemas. Si no lo tienes instalado:
# apt-get -f install gcc-3.4
Ahora ya estás en condiciones de descomprimir los fuentes y compilarlos. Si has descargado los fuentes con apt, éstos se encontrarán en /usr/src/rt2500.tar.gz. Descomprímelos y compílamos:
$ tar -zxvf rt2500.tar.gz
$ cd modules
$ make CC=gcc-3.4
Una vez compilado todo sin problemas, puedes proceder con la instalación:
$ make install
La instalación habrá creado el fichero /etc/modprobe.conf. Dentro de este fichero habrá algo del estilo 'alias ra0 rt2500'. Tienes que copiar esa línea dentro del archivo /etc/modules.conf y después borrar el archivo /etc/modprobe.conf.
Con esto, se supone que el driver ha quedado instalado. Ahora tan solo queda cargar el módulo:
# modprobe rt2500
Si esto no funciona (que debería), puedes probar esto otro (dentro del directorio donde has compilado el driver):
# insmod rt2500.ko
y con esto el driver deberia quedar perfectamente instalado y tu dispositivo de red detectarse como ra0.
A veces (sobre todo con las versiones más nuevas de Linux) el comando depmod parece no funcionar bien, por ello, es conveniente, después de tener el módulo cargado ejecutar:
# update-modules
Con ello habrás actualizado correctamente la lista de módulos y el correspondiente a tu WiFi se cargará durante el arranque.
Cómo programar microcontroladores de la familia PIC de Microchip en GNU/Linux
Introducción
Si tienes un programador serie de la familia T20 o derivados estás de suerte. Ahora, con una mínima modificación en tu programador, puedes programar microcontroladores PIC utilizando la herramienta PICPROG que actualmente se encuentra en su versión 1.7 (y tu programador seguirá siendo compatible con icprog
Qué necesitamos
Hablaremos del software. Lo único que nos hace falta es tener instalado picprog. Bajamos el paquetito debian que vemos (a la hora de escribir éste documento es picprog-1.7-2_i386.deb
Cuando tengamos el archivo, lo instalamos. Como root tecleamos
~#dpkg -i picprog-1.7-2_i386.deb
Después de la instalación ya estaremos listos para utilizarlo como se muestra a continuación.
Utilización
Borrado del microcontrolador
Para borrar por completo el microcontrolador escribimos:
--burn Si no utilizamos ésta opción, en realidad no haremos nada sobre el micro, tan solo simularemos la operación, lo cual nos sirve para verificar que la sintaxis ha sido correcta.
-d pic16f84 Microcontrolador sobre el que operar. Picprog es capaz de autodetectar gran cantidad de micros por si mismo, pero no está de mas ayudarle un poco.
-pic /dev/ttyS0 Puerto a utilizar para comunicarnos con el programador. Por defecto se utiliza /dev/ttyS0, pero tampoco está de mas indicárselo. No debemos olvidar dar los permisos necesarios a los puertos para poderlos utilizar.
Con la opción --output le decimos a picprog dónde queremos que guarde los datos leídos.
Notas
Es útil indicar que se pueden realizar varias operaciones a la vez, como por ejemplo el borrado y la programación en una misma llamada, para ello solo hay que indicar las dos opciones a la vez y picprog borrará y después programará nuestro micro con el archivo que le indiquemos.
Para los menos versados en el tema que seguro que se preguntan que qué pasa con los fusibles, con la EEPROM, etc... Bueno, tanto los fusibles como el espacio de EEPROM pertenecen al espacio de direcciones de los micros, por lo que solo hay que buscar en la documentación de cada micro e indicarle al ensamblador con las directivas adecuadas qué valores hay que almacenar en cada dirección de memoria (usualmente suelen utilizarse directivas db para éso.
El hardware
Para poder utilizar el programador T20 con picprog (y aún así que sigua siendo compatible con icprog) deberemos hacer una pequeña modificación en el hardware. Ésta modificación consiste tan solo en cortar un par de pistas e introducir un transistor MOS 2N7000 o compatible.
En el siguiente enlace sobre modificación del T20 podremos ver de forma gráfica éste proceso.
Es muy sencillo, y si no nos atrevemos nosotros seguro que conocemos a alguien que se atreva a hacerlo por nosotros.
Cómo utilizar spamassassin junto con sylpheed-claws para filtrar todo el spam y correo basura que recibamos
Introducción
Seguro que a todos nos pasa que recibimos montones de correos basura, publicidad, spam, archivos infectados y un largo etcétera que nos roban cantidad de tiempo aunque solo sea borrándolos de nuestro gestor de correo... En GNU/Linux existen gran cantidad de herramientas que nos permiten gestionar todo nuestro correo electrónico, como evolution, sylpheed-claws, mozilla, etc... Además de numerosos filtros antiespam tales como pueden ser bogofilter y spamassassin. En mi caso en particular, utilizo spamassassin junto con sylpheed-claws para filtrar y gestionar todo mi correo electrónico y el resultado es bastante bueno. Spamassassin no sólo permite filtrar el correo "basura" distinguiéndolo del que no lo es con gran precisión, sino que además es fácil de configurar, es capaz de aprender de sus propios errores y tiene muchas opciones configurables que le hacen un filtro bastante potente. Aquí se describe su configuración y uso con el gestor de correo Sylpheed-claws.
Qué necesitamos
Lo primero que tendremos que hacer es instalar en nuestra máquina tanto Sylpheed-claws como Spamassassin. En Debian:
~#apt-get -finstall spamassassin sylpheed-claws
Tampoco estaría de mas instalarnos los plugins y demás módulos para sylpheed-claws si tenemos pensado utilizarlo de forma regular como nuestro gestor de correo. Para buscar qué módulos y/o plugins hay disponibles:
~#apt-cache search sylpheed-claws
Configuración de SpamAssassin
La configuración realizada aquí se ha hecho en sylpheed-claws. Si utilizas otro tipo de gestor como evolution o mozilla, deberás averiguar antes como crear y configurar reglas de filtrado, ya que es a través de éstas reglas como se configura spamassassin.
En nuestro caso, una vez abierto sylpheed-claws nos iremos a Configuración -> Filtrado... Aquí se nos mostrará la ventana para edición de reglas de filtrado. Nosotros deberemos crear tres reglas de filtrado:
Una para analizar todo el correo.
Otra que nos permita marcar como válido un correo considerado spam por spamassassin.
Una última que nos permita marcar un correo como spam en caso de que spamassassin lo pasase por alto.
Creamos la primera regla, que hará que spamassassin revise todo el correo y decida según su criterio cual es spam y cual no. En la línea correspondiente a la condición escribiremos algo como:
test "spamassassin < %F | grep -c \"X-Spam-Flag: YES\""
Spamassassin recibe como entrada nuestro correo y su salida será el mismo correo pero con algunas líneas nuevas en la cabecera. En concreto nos interesa la existencia de la línea "X-Spam-Flag: YES". Ésta línea indicará que el correo ha sido considerado como spam y por tanto deberá ser tratado.
Como la salida de spamassassin tiene formato de texto, tan solo hará falta comprobar con el comando grep si existe dicha línea.
Para la acción:
move "#mh/Buzon/Spam"
La carpeta Spam dentro de Buzon es donde yo he elegido que guarde todo el correo spam que encuentre.
Para el caso de la segunda regla, en la que un correo válido ha sido marcado como spam, la condición será:
colorlabel 6
Si encontramos como spam algún correo que no lo es (nadie nace enseñado, y spamassassin tampoco) deberemos indicar que ese correo es válido. Para ello lo etiquetaremos de color verde y lo filtraremos.
Para la acción:
Así haremos que el correo vuelva de nuevo a la carpeta de entrada y spamassassin lo marque como válido para de ése modo "aprender" de su error.
Por último, la última regla de filtrado, cuya misión es contraria a la anterior. Su condición es:
colorlabel 2
Los correos spam que se le hayan "colado" a spamassassin los marcaremos con color rojo y volveremos a filtrar. La acción entonces será:
Con ésto, el correo se marcará como spam y será enviado a la carpeta correspondiente.
Notas importantes sobre la configuración
Éstas reglas de filtrado, deberán ser colocadas al principio para que sean las primeras en ser ejecutadas, ya que de lo contrario, el correo no se filtrará de forma adecuada.
Cuando se filtra el correo con spamassassin, el proceso puede durar bastante tiempo, especialmente cuando spamassassin lleva bastante tiempo aprendiendo, ya que tendrá que comprobar mas reglas. Por ello no hay que perder la paciencia y pensar que algo va mal si el filtrado se toma varios minutos (a veces incluso media hora) cuando se tiene que filtrar una cantidad bastante elevada de correos electrónicos.
Otras opciones
Spamassassin tiene varias características configurables que lo hacen bastante potente, pero tal vez dos de las características que mas útiles pueden llegar a ser en un momento dado sean la de whitelist y blacklist. Se trata de dos listas, una con direcciones de correo que se consideran como válidas (whitelist) y otra con direcciones de correo desde las cuales todo el correo recibido se tratará como spam (blacklist).
Los parámetros para poder añadir y eliminar direcciones de éstas listas son los siguientes:
--add-to-whitelist Añade la dirección del remitente del correo a la lista de direcciones válidas. Ningún correo que llegue desde ésta dirección será considerado como spam.
--add-to-blacklist Añade la dirección del remitente del correo a la lista de direcciones no válidas.
Todos los correos recibidos desde esa dirección serán tratados como spam.
--remove-from-whitelist Elimina la dirección del remitente del correo de la lista de direcciones válidas.
--add-addr-to-whitelist = addr Igual que la opción --add-to-whitelist, pero ahora la dirección se introduce de forma manual.
--add-addr-to-blacklist = addr Igual que la opción --add-to-blacklist, pero ahora la dirección se introduce de forma manual.
--remove-addr-from-whitelist = addr Igual que la opción --remove-from-whitelist, pero como antes, la dirección deberemos introducirla de forma manual.
El Ayuntamiento de Daimiel organiza una Install Party y un videoforum para la tarde del día 17 de mayo. El evento cuenta con la participación de miembros de CRySoL.
Ya podéis ver algunas de las fotos de las Jornadas en:
http://arco.esi.uclm.es/~cleto.martin/fotos_jornadas/
Aún me quedan por conseguir algunas, por lo que lo actualizaré en breve.
Gracias a Sergio Pérez, Francisco Sánchez y Cayetano J. Solana por las fotos.
Currently I am building tests for an existing implementation of IDM. I am using google-mock, a mocking library for C++ classes. Let’s see an example of dependency injection. This basic technique is used when you are mocking your classes and, thus, obtain non-fragile tests.
Esta receta explica cómo montar un repositorio de paquetes medianamente decente, que se pueda manejar con las herramientas estándares de Debian y se puedan utilizar firmas PGP tanto para el repo como para los paquetes.
Este artículo es una guía de referencia para el uso básico de cámaras AXIS 214 Pam-Tilt-Zoom (PTZ). No obstante, es posible que para otros modelos de AXIS sea útil.
Esta receta explica cómo utilizar, fundamentalmente, el comando INSTALL de CMake para crear objetivos de instalación.
El comando INSTALL
CMake proporciona el comando INSTALL que facilita en gran medida seleccionar los componentes de nuestro proyecto que queremos instalar y dónde.
En esta receta nos vamos a centrar en un uso básico del comando. Para algo más avanzado nada mejor que la documentación.
Ejemplo
Supongamos que queremos instalar un binario y dos versiones de una misma librería: una estática y otra dinámica. El código CMake para este caso podría ser el siguiente:
Inicialmente, podrías añadir un comando por cada uno de los componentes que queremos instalar indicando el directorio destino. Sin embargo, como es habitual necesitar instalar varios objetivos, el comando INSTALL proporciona una forma más compacta:
En primer lugar, se asocia a la librería dinámica las cabeceras que serán necesarias instalar posteriormente como "cabeceras públicas" utilizando el comando SET_TARGET_PROPERTIES. Es posible asociar distintos archivos a objetivos para, posteriormente, usarlos en el comando INSTALL. De hecho, lo apropiado sería crear un FRAMEWORK... pero quizás es demasiado para este ejemplo. Consulta el manual para obtener más información que, además, explica cómo utilizar INSTALL de otras formas.
La forma en que se ha usado INSTALL es la más compacta. Básicamente, viene a decir lo siguiente (por defecto, CMAKE_INSTALL_PREFIX=/usr/local):
Al objetivo hello se le debe tratar como un ejecutable (RUNTIME) y debe instalarse en el directorio ${CMAKE_INSTALL_PREFIX}/bin.
Al objetivo dummy_static se le debe tratar como una librería estática (ARCHIVE) y debe instalarse en el directorio ${CMAKE_INSTALL_PREFIX}/lib/static.
Al objetivo dummy_shared se le debe tratar como una librería dinámica (LIBRARY) y debe instalarse en el directorio ${CMAKE_INSTALL_PREFIX}/lib.
Finalmente, las cabeceras públicas (PUBLIC_HEADER) configuradas a lo largo del programa deben instalarse en ${CMAKE_INSTALL_PREFIX}/include.
Y con ello, ya disponemos de un objetivo install en el Makefile generado que nos permitirá instalar el software.
¿Cómo personalizar mi instalación?
Supón que tienes un directorio en tu home llamado ~/usr y que las variables de entorno pertinentes las tienes configuradas a ese path. Estaría muy bien que pudieras hacer que CMAKE_INSTALL_PREFIX tuviera un valor concreto para instalar el software en ese lugar. Para ello, simplemente ejecuta lo siguiente:
$cmake -DCMAKE_INSTALL_PREFIX=~/usr ..
Sin embargo, es posible que hayas instalado otras cosas en ese ruta (cabeceras de código, por ejemplo) y las uses en tu proyecto. Obviamente, CMake no puede buscar en todo el disco duro en busca de la cabecera problemática. Por ello, es recomendable que cuando cambies el directorio de instalación también cambies lo siguiente:
En esta receta se explica cómo linkar binarios con librerías estáticas y dinámicas.
Linkado básico
A estas alturas ya conocemos cómo construir archivos binarios y librerías en CMake. Ahora supón que la librería dummy que se viene utilizando en los ejemplos está instalada en un path accesible y que el programa hello.cpp hace uso de la librería de forma dinámica. Una posible implementación de este escenario sería la siguiente:
CMAKE_MINIMUM_REQUIRED(VERSION 2.8)
PROJECT(hello)
# Para includes
FIND_PATH(dummy_path dummy.h)
IF(NOT dummy_path)
MESSAGE(FATAL_ERROR "** Falta la cabecera dummy.h, dummy!")
ENDIF()
INCLUDE_DIRECTORIES(${dummy_path})
# Búsqueda del .so
FIND_LIBRARY(dummy_lib dummy)
IF(NOT dummy_path)
MESSAGE(FATAL_ERROR "** Falta la librería dummy, dummy!")
ENDIF()
ADD_EXECUTABLE(hello hello.cpp)
TARGET_LINK_LIBRARIES(hello ${dummy_lib})
En primer lugar, se comprueba que es posible acceder a la librería dummy (tanto la cabecera como el archivo .so). Utilizando el comando TARGET_LINK_LIBRARIES se indica a CMake que el objetivo hello debe ser linkado con la librería dummy_lib.
Para una librería estática, sería muy similar el código ya que CMake detecta que se trata de un tipo u otro y genera el código necesario para linkar estática o dinámicamente según la librería encontrada.
FindPkgConfig
Habitualmente, muchas librerías que se utilizan en sistemas como GNU utilizan la herramienta pkg-config que ayuda a obtener las distintas variables necesarias (CFLAGS, LDFLAGS, etc).
CMake proporciona un módulo llamado FindPkgConfig que incluye comandos útiles para encontrar librerías que utilizan pkg-config. Pese a que se incluye en la distribución estándar, CMake no recomienda el uso de este módulo porque es posible que haya sistemas privativos que no tengan instalada la aplicación pkg-config. Pero eso, no nos preocupa... ¿verdad? :-)
Supón que el programa hello utiliza glib. Podríamos comprobar que está instalado y enlazarlo como sigue:
#Carga del módulo
include(FindPkgConfig)
PKG_CHECK_MODULES(glib REQUIRED glib-2.0) # REQUIRED=Fallará si no lo encuentra
# En "glib_INCLUDE_DIRS" se han cargado los directorios (-I del compilador)
INCLUDE_DIRECTORIES(${glib_INCLUDE_DIRS})
ADD_EXECUTABLE(hello hello.cpp)
# En "glib_LIBRARIES están el nombre de las librerías (-l del compilador)
TARGET_LINK_LIBRARIES(hello ${glib_LIBRARIES}
¿Y cómo es que en glib_LIBRARIES y glib_INCLUDE_DIRS se guardan esos datos?. Los módulos Find* de CMake crean variables para que el usuario las pueda utilizar en caso de encontrar la librería o el objeto que se esté buscando. Una buena forma de saber sobre qué variables se dispone es consultando la documentación. En la cabecera de los módulos también viene esta información (en Debian /usr/share/cmake2.8/Modules/*.cmake).
Esta receta explica cómo compilar un Hola Mundo para el middleware ZeroC Ice utilizando CMake.
Software necesario
Puedes descargarte el software que se va a utilizar del siguiente repo subversion:
$svn co https://arco.esi.uclm.es/svn/public/samples/cmake/hello_ice
En el repositorio se encuentra la implementación de un "Hola Mundo" para ZeroC Ice y el CMakeLists.txt asociado.
Herramientas externas
Un programa en Ice presenta un problema común: archivos que se generan con herramientas externas al proyecto son necesarios para la compilación. En Ice, slice2cpp genera código que debe ser incluido en la compilación.
CMake proporciona un comando muy útil llamado ADD_CUSTOM_COMMAND y que permite definir cómo se generan ciertos objetivos. Utilizando este comando, veamos cómo quedaría el programa CMake para construir el Hola Mundo en Ice:
CMAKE_MINIMUM_REQUIRED(VERSION 2.8)
PROJECT(hello_ice)
FIND_LIBRARY(ice_lib Ice)
FIND_PATH(ice_path Ice)
IF(NOT ice_path)
MESSAGE(FATAL_ERROR "** Librería de Ice no encontrada")
ENDIF()
# Variable con los slices necesarios
SET(SLICES ${CMAKE_CURRENT_SOURCE_DIR}/slice/hello.ice)
# slice2cpp
ADD_CUSTOM_COMMAND (
OUTPUT hello.cpp hello.h
COMMAND slice2cpp ${SLICES}
)
INCLUDE_DIRECTORIES(
${CMAKE_CURRENT_SOURCE_DIR}
${CMAKE_CURRENT_BINARY_DIR} # slice2cpp deja el .h en el directorio en 'build'
${ice_path}
)
ADD_EXECUTABLE(Client hello.cpp Client.cpp)
ADD_EXECUTABLE(Server hello.cpp helloI.cpp Server.cpp)
TARGET_LINK_LIBRARIES(Server ${ice_lib})
TARGET_LINK_LIBRARIES(Client ${ice_lib})
Al principio, se hacen unas liberas comprobaciones de que la librería de Ice existe. A continuación se define el comando slice2cpp diciendo que como salidas los ficheros hello.cpp y hello.h a partir del fichero Slice hello.ice. Los archivos de salida son dependencias de los distintos ejecutables que se deben crear. Finalmente, se enlaza con las librerías necesarias.
Esta receta es una guía rápida de CMake. Se trata de una herramienta para la construcción automática de proyectos software, facilitando su portabilidad.
Esta receta explica cómo construir librerías estáticas y dinámicas con CMake.
Software necesario
Los ejemplos que vamos a utilizar puedes descargarlos utilizando subversion desde:
$svn co https://arco.esi.uclm.es/svn/public/samples/cmake/libstatic
$svn co https://arco.esi.uclm.es/svn/public/samples/cmake/libshared
Los directorios contienen una librería con una definición de la clase Dummy (dummy.h y dummy.cpp) con un único método. También se incluye el CMakeLists.txt correspondiente.
Librería estática
Para crear una librería estática nada más fácil que lo que sigue:
El comando INCLUDE_DIRECTORIES permite añadir los directorios donde se encuentran las cabeceras del proyecto. En este caso, el fichero dummy.h se encuentra en el mismo directorio donde están los fuentes (el mismo en el que se encuentra CMakeLists.txt). La variable global CMAKE_CURRENT_SOURCE_DIR tiene esta ruta.
De una forma similar a como se añadían ejecutables, para crear una librería se debe utilizar ADD_LIBRARY que acepta, entre muchos otros, los siguientes parámetros:
objetivo: se trata un nombre simbólico para el objetivo que representa el crear la librería. Si no se especifica otra cosa, este nombre se utilizará para crear el fichero final de la forma libobjetivo.a.
STATIC: modo de la librería.
dependencias: de qué ficheros u objetivos depende la librería para su construcción
Librería dinámica
A la vista de lo anterior, parece sencillo crear una librería dinámica. ¿Bastará cambiar STATIC por SHARED?. Sí, con eso bastaría. Pero vamos a añadir algo más para hacer que la librería sea más "distribuible":
En CMake, los targets (objetivos) tienen propiedades que, a priori, tienen ciertos valores por defecto. La propiedad SOVERSION de los objetivos que son librerías dinámicas, por defecto, no tiene valor. Sin embargo, es conveniente versionar las librerías para que aquellas plataformas que lo soporten (como por ejemplo, GNU) puedan gestionar las versiones.
Con el comando SET_PROPERTY se puede modificar las propiedades de las estructuras que se van creando en el programa. En este caso, para el objetivo 'dummy' se cambia el valor de la propiedad SOVERSION a 1.0. De esta forma, al compilar la librería CMake generará los enlaces simbólicos necesarios de forma automática.
Librería estática y dinámica
Es posible que para una misma librería quieras que pueda ser enlazada de forma estática y también dinámica. Veamos una posible solución:
No se puede utilizar dummy como objetivos de ambas librerías. Lo que se puede hacer, por tanto, es crear un objetivo por cada tipo de librería (dummy_shared y dummy_static). Si no decimos nada más, CMake nos generará los archivos libdummy_static.a, libdummy_shared.so,... Y eso, obviamente, no es lo deseable.
Por ello utilizamos SET_TARGET_PROPERTIES que sirve para configurar propiedades de objetivos (es un caso particular de SET_PROPERTY).
Referencias
Documentación CMake2.8: consultar las propiedades genéricas y de los diferentes tipos abstractos (directorios, objetivos, ficheros fuente...).
En primer lugar, se especifica la versión mínima de CMake que se debe utilizar. A continuación, se debe dar un nombre al proyecto utilizando el comando PROJECT.
Como se trata de un proyecto archi-sencillo, sólo consta de un ejecutable y éste se debe generar a partir del fichero "hello.cpp" (su dependencia). El comando ADD_EXECUTABLE acepta una lista de dependencias. Como puedes ver, prácticamente es una regla de Makefile pero más abstracta de forma que sea posible no sólo crear Makefiles sino también exportar a proyectos de Eclipse y otros entornos de desarrollo privativos (a los cuales no recomiendo exportar).
Versión "paranoic"
En el ejemplo anterior, desde un punto de vista ortodoxo, hemos supuesto muchas cosas. Por ejemplo, en el fichero "hello.cpp" se incluye la cabecera "iostream". ¿Hemos comprobado que está instalada? El compilador de C++ que utilizamos, ¿tiene soporte para que se pueda utilizar el namespace "std"? Como ves, hay muchas cosas que se han dado por supuestas en el ejemplo anterior.
Aunque para este ejemplo no sea necesario, veamos una versión del archivo CMakeLists.txt más avanzada:
CMAKE_MINIMUM_REQUIRED(VERSION 2.8)
PROJECT(hello)
INCLUDE(TestForSTDNamespace)
IF (CMAKE_NO_STD_NAMESPACE)
MESSAGE(FATAL_ERROR "** El compilador no soporta std:: en clases STL")
ENDIF()
INCLUDE(CheckIncludeFileCXX)
CHECK_INCLUDE_FILE_CXX(iostream IS_OSTREAM)
IF(NOT IS_OSTREAM)
MESSAGE(FATAL_ERROR "** No se encuentra la cabecera 'iostream'")
ENDIF()
ADD_EXECUTABLE(hello hello.cpp)
En este ejemplo se introduce el uso de módulos que se proporcionan en la distribución de CMake 2.8 en Debian:
TestForSTDNamespace: incluye el código necesario para comprobar que existe el compilador soporta el uso del espacio de nombres std. Esta macro modifica una variable global (CMAKE_NO_STD_NAMESPACE) con el resultado de dicho test.
CheckIncludeFileCXX: se trata de un módulo que contiene el comando CHECK_INCLUDE_FILE_CXX que acepta como primer parámetro el nombre del archivo a incluir y, como segundo parámetro, una variable donde almacenar el resultado. De esta forma, utilizando un IF podemos comprobar que efectivamente se encuentra instalada la cabecera iostream.
En esta receta se muestran los pasos básicos para crear un paquete binario Debian de forma que puedas empaquetar tu programa de forma fácil y sencilla.
Un blog llamado unidadlocal.com copia artículos de CRySoL violando la licencia del portal. unidadlocal.com comete plagio puesto que no indica en ningún momento el autor y/o la procedencia del contenido.
Si en el segundo encuentran algún tipo de referencia al primero o algo similar que respete la licencia de contenidos de CRySoL, por favor… que alguien me lo diga.
En la siguiente receta se exponen algunas ideas y recomendaciones a la hora de crear un Makefile de tal forma que sea sencillo el proceso de creación de los paquetes Debian.
Empaquetar un programa, librería o cualquier otro elemento software en Debian puede ser una tarea complicada, sobre todo si queremos añadirlo a Debian donde es necesario que cumpla muchos requisitos (concretamente, la conocida Debian Policy).
Esta guía puede ser considerada por algunos como quick&dirty, pero ofrece un punto intermedio entre la política de Debian y lo que se podría llamar “cutre”. La guía se compone de recetas que te servirán de ayuda para empaquetar tus programas y distribuirlos de forma personal.
Ejecuta la aplicación Azilink en el móvil y activa el botón "Service active". En la parte donde se muestra el estado aparecerá el mensaje "Waiting for connection". A continuación, ejecuta lo siguiente en el PC:
Si todo ha ido bien, el mensaje de estado cambiará a "Connected to host". Ya tienes conexión a internet, pero no hay DNS configurado. Para ello, sólo tienes que editar el archivo /etc/resolv.conf y dejarlo con el siguiente contenido:
Esta receta explica cómo configurar tu máquina Debian para poder empezar a desarrollar programas con tu flamante móvil HTC Magic (G2).
Introducción
Existe un SDK con multitud de herramientas para desarrollar en sobre teléfonos Android (como es el caso del HTC Magic que, a día de hoy, Vodafone vende en exclusividad). Sin embargo, para sacarle todo el partido al entorno de desarrollo es necesario tener configurado correctamente tu ordenador para que al enchufar el móvil via USB puedas utilizar las herramientas del SDK. En esta receta se explica precisamente esto último sobre un sistema Debian GNU/Linux.
Primero, asegúrate de que el teléfono tiene el modo USB de depuración activado. Esto se encuentra en Ajustes->Aplicaciones->Desarrollo.
Una vez comprobado, conecta el teléfono al PC.
Probando que todo funciona...
Descomprime el SDK que te has descargado en el directorio que prefieras. Dentro del árbol de directorios que se ha generado hay uno llamado "tools". Dentro de él, hacemos:
$./adb start-server
$./adb shell
Si todo ha ido bien, tendrás una bonita shell dentro de tu móvil. Listemos los paquetes Android (ficheros .apk) que tenemos:
En esta receta se explica cómo hacer downcasting de los elementos de un contenedor a una clase más derivada.
Introducción
Supongamos que tenemos la siguiente jerarquía (nos servirá a lo largo de toda la receta):
classA{public:virtual~A(){}};classB:publicA{public:stringgetB(){return"Soy de tipo B";}};classC:publicA{public:stringgetC(){return"Soy de tipo C";}};
El vector de B's y C's
En muchas ocasiones, utilizamos los contenedores de C++ (como vector, stack...) para almacenar distintos tipos de datos. Por ejemplo, imagina que queremos tener un 'vector' que contenga tanto instancias de 'B' como de 'C'. En C++ es necesario crear un vector de la clase padre de ambas, o sea, un 'vector' de A's. Un pensamiento ingenuo (como el mío), implementaría esto mismo así:
Bb;Cc;....vector<A>v;v.push_back(b);v.push_back(c);..../*
Aquí el downcasting. Pero habrá una sorpresa...
*/
¡Y compila!. Lo que está ocurriendo es legal, pero realmente no es lo que queremos ya que el compilador "trunca" el objeto para añadirlo al contenedor y satisfacer el tipo del vector. Este proceso se denomina "Object Slicing". De esta forma, NO estas incluyendo en el vector objetos de tipo 'B' o 'C', sino que todos son de tipo 'A' y, por lo tanto, cuando quieras recuperarlos te encontrarás con que no es posible hacer el molde a tipos más derivados (esa es la sorpresa de la que habla el comentario del texto :-)).
Solución
Antes de dar la solución, vamos a pensar qué queremos realmente. Queremos tener un contenedor que tenga varios tipos de objetos. Hemos visto que el compilador hace slicing de los objetos si estos son instancias. Pero si lo que introducimos en el contenedor son referencias a los objetos, el Object Slicing no ocurre, por lo que tendremos los objetos completos para luego hacer el downcasting.
De esta forma, el código correcto sería el siguiente:
// El upcasting se hace sin problemas (Polimorfismo)A*b=newB();A*c=newC();....vector<A*>v;v.push_back(b);v.push_back(c);....// DowncastingB*be=dynamic_cast<B*>(v[0]);C*ce=dynamic_cast<C*>(v[1]);cout<<be->getB()<<endl;cout<<ce->getC()<<endl;
Como puedes ver, para hacer el downcasting C++ ofrece el operador dynamic_cast. Es necesario que las clases que intervienen en el casting dinámico estén "en una jerarquía polimórfica real", es decir, la clase padre tiene que tener, al menos, un método virtual.
Si tenemos un servicio de hosting remoto con FTP, es probable que nos interese subir archivos de bakcup. Esta receta explica como hacerlo con un breve script de BASH.
Una empresa que desarrolla software (a priori) y que se llama Microsoft tiene una sección muy curiosa sobre "las ventajas del software legal", entiéndase por legal todo aquel producto que vende esta empresa.
Cómo crear fácilmente bindings de Python para una librería C++ usando SIP
Introducción
¿Tienes algunas librerías en C++ hechas y no sabes cómo utilizarlas en Python? ¿Estás "decepcionado" porque tu programa construído totalmente en Python no es tan rápido como esperabas?. La solución es "bien sencilla": te programas una librería en C/C++ (si no la tienes) que haga el trabajo, construyes un wrapper para utilizarla en Python y... ¡listo!
Para el primer paso no hay, de momento, solución automática. Pero para el segundo existen diversas herramientas que ayudan a la construcción del wrapper, su compilación e instalación. Una de estas herramientas, la que vamos a utilizar en esta receta, se llama python-sip. Asiste a la creación de los wrappers para librerías C/C++, aunque los ejemplos que se mostrarán serán de C++. Para más información, consulta la sección de Enlaces.
Ingredientes
#apt-get install python-sip4 sip4
Ejemplo
Librería C++
Para ilustrar el funcionamiento de python-sip, ¡qué mejor que un ejemplo!. Supón que la librería consta de una clase construída en C++ y cuyo fichero de cabecera (Impresora.h) es el siguiente:
Como se puede apreciar, la clase tiene poca historia: tiene un atributo privado ("nombre") y un método para imprimir una lista (conjunto) de strings ordenados alfabéticamente. Para compilar esta librería tenemos el siguiente Makefile:
En definitiva, partimos de un archivo "libImpresora.so" que contiene la librería en C++ ya compilada. Ahora comienza la construcción del wrapper con ayuda de python-sip4.
Construcción del wrapper
Comenzamos creando un archivo que, por convenio, llamaremos "Impresora.sip". En este fichero especificaremos la estructura del wrapper con sintaxis sip, muy parecida a C++. Una primera aproximación sería la siguiente:
%Module especifica el módulo en el que va estar incluída la librería, junto con un número de versión. En el ejemplo, el módulo es "Ejemplo" en su versión "0".
%TypeHeaderCode es necesario para que sip pueda leer la información de la clase que se va a "wrappear". Todo lo encerrado en ese bloque, sip lo utilizará para construir el wrapper con los tipos adecuados.
Nótese que se ha modificado los tipos de los argumentos del constructor y del método "imprimirLista". Sip no soporta tipos como string (y no digamos sets de la STL de C++). Sin embargo, en el caso de string, basta con especificar de que se trata de un "char*" y C++ se encargará del cambio de tipo. El argumento de tipo set se ha sustituído por una constante de sip que representa una lista de Python. Existe una constante de este tipo para cada uno de los tipos de Python (SIP_PYDICT...). Consúltese las referencias para más información.
Como se puede apreciar, no está especificado el atributo privado "nombre". Sip no soporta atributos ni métodos privados para la construcción del wrapper.
SIP_PYLIST representa a una lista de Python pero, ¿cómo se hará la correspondecia set->PythonList?. ¿Sip se encargará de ello?. Pues no. La correspondencia entre tipos complejos (objetos propios, clases auxiliares...) debe hacerse de forma explícita. Para especificar la conversión de uno a otro utilizaremos la directiva %MethodCode:
Declaramos una variable del mismo tipo que el argumento que espera el método, en nuestro caso un set de strings.
a0 es el argumento (SIP_PYLIST) de tipo PyObject* de la librería CPython. Por tanto, el bucle no sirve nada más que para guardar cada valor de la lista Python en el set.
sipCpp es un puntero al objeto de entorno, en nuestro caso, "Impresora*". Cuando tenemos el set completamente construído llamamos a "imprimirLista" con el parámetro convertido.
Construcción del Wrapper
Una vez tenemos la especificación del fichero .sip, es hora de construir el wrapper de forma automática. Para ello, es aconsejable utilizar un pequeño script en python que genera los archivos .cpp y el Makefile final. Un fichero básico sería el siguiente:
importosimportsipconfig# The name of the SIP build file generated by SIP and used by the build
# system.
build_file="impresora.sbf"# Get the SIP configuration information.
config=sipconfig.Configuration()# Run SIP to generate the code.
os.system(" ".join([config.sip_bin,"-c",".","-b",build_file,"Impresora.sip"]))# Create the Makefile.
makefile=sipconfig.SIPModuleMakefile(config,build_file)# Add the library we are wrapping. The name doesn't include any platform
# specific prefixes or extensions (e.g. the "lib" prefix on UNIX, or the
# ".dll" extension on Windows).
makefile.extra_libs=["Impresora"]makefile.extra_lflags=["-L."]# Generate the Makefile itself.
makefile.generate()
El código de este script es "autocomentado". Supongamos que el fichero que contiene el código anterior se llama "configure.py":
$python configure.py
El comando anterior genera el wrapper en C++ y el Makefile que construirá todo.
$make
La compilación del wrapper generará un archivo "Ejemplos.so", que es la librería compartida que será utilizada por Python.
Probando
Tenemos 2 opciones:
Ejecutar "make install" y, por tanto, instalaremos el archivo "Ejemplos.so" en /usr/lib/pythonX.X/site-packages donde será accesible para cualquier programa Python que utilize el módulo Ejemplos.
Probar la librería con iPython, ejecutándolo en el directorio donde se encuentra el nuevo módulo
Cualquiera que sea el modo de prueba se debe modificar la variable de entorno LD_LIBRARY_PATH para que el intérprete de Python pueda localizar el "libImpresora.so". A continuación, un ejemplo utilizando iPython:
~/pruebas/python-sip$ export LD_LIBRARY_PATH=.
~/pruebas/python-sip$ ipython
In [1]: import Ejemplos
In [2]: imp = Ejemplos.Impresora("HAL9000")
In [4]: imp.imprimirLista(["Dave", "tengo", "miedo"])
Dave miedo tengo<--- Imprime HAL9000
Referencias
Documentación de sip4 en /usr/share/doc/sip4/reference/sipref.html, incluída en el paquete sip4
¡Hola amigos! Si os habéis fijado en el bloque de proyectos, existe un nuevo proyecto llamado dotBF. Se trata del desarrollo de un IDE para Brainfuck, hecho completamente en Python y 100% GPL. Estamos Javier Peris y yo trabajando en ello (como diría Aznar) y necesitamos de vuestra creatividad para ponerle un logo.
Esta receta explica cómo hacer un _major mode_ para facilitar la edición de un lenguaje de programación, incluyendo resalte de sintaxis e indentado automático.
La siguiente receta explica como construir un analizador léxico con Flex y un analizador sintáctico con Bison, utilizando C++. Además, incluye un pequeño Makefile para el enlazado de todos los archivos y un ejemplo mínimo de uso.
libcURL es una librería para hacer más fácil la programación de aplicaciones que tienen que hacer uso de protocolos de red. En esta receta encontrarás una breve introducción a la programación con libcURL con un ejemplo básico.
La siguiente receta explica como crear un servicio para IceBox. El ejemplo está hecho en C++, sin embargo es aplicable para los lenguajes soportados por ZeroC-Ice. Sólo es un leve cambio de sintaxis... :-P
Esta receta es la primera parte de la Guía Rápida. En esta primera parte mostraremos los conceptos básicos para conocer y comprender la estructura de IceGrid.
Conceptos básicos
IceGrid es el servicio de Ice que puede proporcionar transparencia de localización en un sistema distribuido dinámico. Es decir, la transparencia de localización permite a un cliente contactar con un objeto remoto sin conocer realmente en qué máquina y en qué puerto está.
Ice proporciona métodos para especificar un Endpoint determinado. Recordemos:
Explícitamente en el código.
Pasado como párametro en la línea de órdenes.
En un fichero de configuración.
Los dos primeros métodos requieren utilizar la función createObjectAdapterWithEndpoints, que necesita el endpoint como parámetro; mientras que el tercero requiere un fichero de configuración y el uso de createObjectAdapater.
Sin embargo, si nos encontramos en un sistema dinámico en el que no se conocen la situación exacta de los servidores (o ésta cambia con el tiempo), el cambio en los Endpoints supondría, por este orden según el método utilizado:
Modificar el código y recompilar la aplicación.
Modificar scripts de inicialización de la aplicación.
Modificar el fichero de configuración
IceGrid permite a un cliente encontrar adaptadores de objetos remotos de los cuales sólo conoce el nombre (Objeto1@Adaptador). Este tipo de objetos son los "well-known objects" (objetos bien conocidos).
Estructura de un sistema que use IceGrid
Para IceGrid, el sistema distribuído tiene la siguiente jerarquía:
Registry: nodo del sistema que se encarga de la transparencia de localización y funciona como "DNS" de todo el sistema. Por ello, debe conocer la estructura completa del sistema y de todos los recursos. Debe de ser único (puede haber otro registry en el sistema, pero con funciones de respaldo).
Nodos: normalmente se identifica a un computador físico del sistema. Esto no es del todo cierto, ya que un mismo computador puede tener varios nodos. Sin embargo, para el objetivo de esta guía es suficiente pensar que un nodo es un computador del grid.
Servidor: un nodo puede tener varios servidores, es decir, un punto del sistema puede ofrecer distintos servicios al resto de nodos. Un servidor, de una forma muy somera, puede verse como una aplicación corriendo en un puerto determinado.
Adaptadores de objetos: cada servidor puede tiener uno o varios adaptadores de objetos. Es en este punto donde podemos especificar cuáles van a ser los objetos bien conocidos y otros parámetros.
En la siguiente parte...
Se propondrá un ejemplo de uso de IceGrid mediante la herramienta IceGrid-gui con un ejemplo básico.
Acabo de subir al repositorio de GNESIS un nuevo paquete para la conexión con la nueva red WiFi de la universidad: eduroam. El programa está basado, como se puede apreciar, en el funcionamiento de UCLM-WiFi y es muy fácil de utilizar. En principio debería funcionar sin problema en Debian, Ubuntu y otras distros derivadas.
El anterior fragmento de código genera una gráfica cuyo contenido son los puntos contenido en la lista "a".
No obstante, lo más habitual es que se quiera representar la línea que une los puntos dados en una lista. El siguiente fragmento hace esto mismo para los datos anteriores:
a=[[1,2],[3,4],[5,6]]gp=Gnuplot.Gnuplot()gp("set data style lines")gp.plot(a)
Como se puede aprecia, python-gnuplot provee al usuario de un método anónimo por el que se puede ejecutar comandos de gnuplot para el objeto creado.
Ejemplo
Sea el siguiente fragmento de código un ejemplo más elaborado:
importGnuplotgp=Gnuplot.Gnuplot(persist=1)gp('set data style lines')graf1=[[1,2],[3,4],[5,6]]graf2=[[1,3],[2,-1],[3,6],[4,2],[5,0]]plot1=Gnuplot.PlotItems.Data(graf1,with_="lines",title="Temp./Tiempo")plot2=Gnuplot.PlotItems.Data(graf2,with_="lines",title="Estado Mental del desarrollador de UCLMWiFi")gp.plot(plot1,plot2)
¡Hola amigos y amigas!
Me es grato comunicaros que "uclmwifi" sigue avanzando. La gente que ya se instaló la versión 1.2 habéis "sufrido" las distintas actualizaciones y cambios que ha sufrido uclmwifi. Si aún no lo has probado añade el siguiente repositorio:
Si vives en Ciudad Real (y alrededores) y has sintonizado tu televisión recientemente, te habrás dado cuenta de que existe un nuevo canal en antena: Quijote Información. Yo lo sintonicé hace tiempo (desde su nacimiento, por pura casualidad) y quiero comentar un par de cosas interesantes.
Si tienes una Nintendo Wii y has comprobado todo lo que puedes hacer con un Wiimote, es hora que lo conectes a tu PC con GNU. Esta receta es un ejemplo muy básico de lo que se puede hacer con él.
Cómo crear una GNESISUSB si sólo dispones de un ordenador con Windows. Ya no tienes excusa, si sufres Windows es porque quieres.
Si estás leyendo esta receta, a priori, pensaría que utilizas Microsoft Windows de forma habitual y eso no puede ser. Sin embargo, estoy seguro que no es así y que simplemente te has equivocado de sitio por un despiste. Por ello, es conveniente que consultes Instalar GNESIS en un dispositivo USB desde GNU/Linux, que es lo que realmente usas ;-).
Ingredientes
Un pendrive USB
Microsft Windows XP (o sistema repugnante similar)
Al igual que en GNU, el programa dd te permite volcar el contenido del archivo .img a tu dispositivo.
Copiando GNESIS
Descomprime el ejecutable dd.exe por ejemplo, en C:\. Seguidamente, abre una cosa fea, rara y sin transparencias que se llama símbolo de sistema. Se encuentra en la ruta “Inicio→Todos los programas→Accesorios→Símbolo de Sistema” . Una vez abierto situate en el directorio en el que hayas descomprimido el ejecutable de dd:
cd C:\
Suponiendo que tienes el archivo .img el mismo sitio, es decir, en C:\; y que ya tienes enchufado el dispositivo USB, debes ejecutar lo siguiente:
Para tener la opción persistente de GNESIS es necesario utilizar un particionador (libre, por supuesto) con el que puedas crear una partición adicional (de tipo ext3). Puedes crear tantas particiones como quieras pero, al menos, una de ellas tiene que estar etiquetada como “casper-rw”. Se recomienda que si el dispositivo tiene poca memoria (1-2GB) sólo se haga una partición para persistencia.
Para crear la partición, como he dicho, puedes utilizar cualquier particionador, o bien arrancar tu GNESIS y seguir la otra receta.
Referencias
Para más información acerca del dd para Windows puedes ver su web oficial, llena de ejemplos.
Para instalar GNESIS en un dispositivo USB de almacenamiento necesitamos:
Un pendrive completamente vacío.
La herramienta dd, fdisk y mkfs.ext3 (o algún otro programa similar a este último como Gparted).
Es MUY IMPORTANTE que el dispositivo USB esté disponible para ser formateado por completo. El procedimiento que vamos a explicar (utilizando dd y fdisk) eliminará cualquier información almacenada para albergar GNESIS.
Instalando el sistema base
Una vez tengamos nuestro archivo imagen.img procedemos a volcarla al disco USB. Con todas las particiones de dicho dispostivo desmontadas y suponiendo que se encuentra en /dev/sda hacemos lo siguiente:
#dd if=imagen.img of=/dev/sda
Esto tardará un poco. Esperamos a que salga un mensaje de finalización, junto con la tasa de transferencia del proceso.
Creando la partición persistente
Una vez instalado el sistema base, podemos comprobrar que nuestro dispositivo USB tiene una partición de tipo FAT16 con el sistema live. El resto del espacio está sin particionar, por lo que debemos crear una partición de tipo ext3 para que se puedan almacenar los cambios que vayamos realizando en nuestra GNESIS. Para ello utilizamos fdisk (o Gparted):
#fdisk /dev/sda
En el prompt de fdisk debemos actuar en este orden:
'n' - para crear una nueva partición.
'p' - indica que es de tipo primaria.
'2' - indica en número de partición. Como ya tenemos una (FAT16) a esta le asignamos el número 2; así, más tarde podremos referirnos a ella como /dev/sda2.
En los 2 pasos siguientes podemos utilizar los valores por defecto que ofrece fdisk pulsando Enter. Estos últimos pasos deciden a partir de qué parte del disco se pone la partición (por defecto, al principio del espacio no particionado) y de qué tamaño (por defecto, el espacio restante).
'w' - para escribir los cambios en el dispositivo
El comando 'w' escribirá los cambios y saldrá de fdisk. Ahora debemos formatear dicha partición a ext3 y, de paso, la etiquetamos como "casper-rw" (gracias a Paco):
#mkfs.ext3 -L casper-rw /dev/sda2
El etiquetado es paso imprescidible para que el arranque de GNESIS pueda identificar la partición y permitir la persistencia de los datos. Como ya he dicho, podéis utilizar Gparted (con entorno gráfico) para hacer todo lo referente a la partición "casper-rw".
Usando GNESIS 3.0
Para poder arrancar la distribución, obviamente, se debe configurar el ordenador para que se inicie desde un dispositivo externo USB.
Si has terminado de utilizar GNESIS y quieres apagar/reiniciar el ordenador, el sistema no se apaga hasta que pulses "Enter". Es posible que te salga un mensaje anunciándote este suceso (en la versión minima siempre sale), pero si instalas un entorno gráfico puede que no te aparezca dicho mensaje. Este es un problema que viene desde Debian-Live y que se está solucionando. Por lo que, aunque no aparezca un mensaje informativo, debes pulsar "Enter" para apagar/reiniciar el ordenador.
Es un honor anunciamos, amigos míos, que ya está disponible una versión preliminar de Gnesis 3.0. Esta versión es un sistema base, es decir, herramientas GNU básicas y un kernel (por desgracia :-)) Linux 2.6.18-4.
A veces, para tener nuestros paquetes Debian generados disponibles en un repositorio no es necesario montar uno complejo (por ejemplo, cuando tus paquetes sólo están para una arquitectura). Los repositorios triviales nos permiten tener nuestros paquetes Debian personalizados disponibles en menos de 10 minutos.
Estructura de directorios
Inicialmente, debemos crear una estructura de directorios para nuestro nuevo repositorio trivial. Vamos a tomar como raíz el directorio /var, y dentro creamos los siguientes directorios:
-var
+-mirepo
+-binary
+-source
Utilizamos el comando mkdir para crear el antrerior árbol de directorios.
Llenando el repositorio
Una vez creada la estructura, copiamos nuestros paquetes binarios Debian (los .deb) en el directorio binary y los paquetes fuentes (los .dsc) en el directorio source. A continuación, creamos los ficheros índices de nuestro repositorio trivial utilizando dpkg:
Como vemos, lo anterior nos crea los índices de nuestros paquetes que serán consultados por apt cuando consulte el repositorio.
Utilizando el repositorio
Una vez que hemos hecho todo lo anterior podemos añadir la siguiente línea a nuestro /etc/apt/sources.list para utilizar el repositorio de forma local:
deb file:///var/mirepo binary/
Y si quieres tenerlo accesible de forma remota, puedes crear un enlace simbólico en /var/www/ para redireccionar la consulta http a tu servidor Apache:
Como ya anunciamos, Gnesis 3.0 está en marcha. Una de las características principales de esta distribución es que se incluirán las transparecencias y herramientas necesarias para las distintas asignaturas de la carrera (tanto para las Ingenierías Técnicas como para la Superior).
Si quieres colaborar manteniendo algún paquete específico de alguna asignatura concreta, esta receta te enseñará a crear y mantener tu propio paquete
Introducción
En el presente documento veremos cómo crear un paquete Debian para empaquetar la documentación y las herramientas propias de una asignatura en cuestión. El proceso que paso a describir es bastante... "pagano". Se trata, sin duda, de la forma menos ortodoxa pero más sencilla de generar un paquete Debian. Si conoces otro método mejor, más fácil de mantener y con idénticos resultados, no dudes en utilizarlo.
Construyendo un paquete
Como ejemplo, vamos a suponer que estamos interesados en mantener un paquete para las asignaturas de Redes. Primeramente, creamos un directorio donde trabajaremos:
$mkdir mipaquete
$cd mipaquete
Una vez situados dentro del directorio de trabajo creamos la siguiente estructura de directorios:
|- DEBIAN
|- usr
|-share
|-doc
|-gnesis-redes
En usr/share/doc/gnesis-"asignatura" copiaremos las transparencias y la documentación. Es conveniente estructurar la información que vamos a incluir como documentación, de tal forma, que quede bien definida. Por ello, si es necesario, creamos la siguiente estructura de directorios dentro de gnesis-"asignatura":
|- gnesis-redes
|- sistemas
|- gestion
|- superior
|- extra
En cada subdirectorio incluímos la documentación que corresponda y, en el directorio extra, añadimos documentos comunes como libros, vídeos y otro material no clasificado.
Nótese que el directorio DEBIAN va con mayúsculas. En él vamos a incluir un archivo llamado control en que describiremos el paquete y las dependencias que éste tiene:
Package: gnesis-redes
Version: 6.7-1
Section: network
Priority: optional
Architecture: all
Depends: wireshark, dialog, python, scapy, net-tools, netcat, iptraf, tcpdump, ssh, nmap, traceroute
Maintainer: Cleto Martín cleto.martin@alu.uclm.es
Description: Paquete con las utilidades necesarias para las asignaturas de Redes de
la Escuela Superior de Informática de Ciudad Real (UCLM).
Observemos los parámetros más relevantes:
Package: el nombre de paquete.
Version: se trata de la versión del paquete. El criterio de versiones es sencillo: "año académico"-"revisión". En el ejemplo, el paquete gnesis-redes pertenece al año académico 2006-2007 y está en su primera revisión. El número de revisión no vamos a utilizar en el caso de que haya que actualizar un paquete (bien sea por cambios en las transparencias, nuevo material, etc...). Si incrementamos el número de revisión, haremos que la anterior versión del paquete quede obsoleta y APT instale la nueva. Así, por ejemplo, si el profesor cambia las transparencias, con tan sólo un "apt-get upgrade" tendrás la documentación actualizada.
Architecture: es posible que en la asignatura haya herramientas que sólo están disponibles para arquitecturas específicas. Si no es el caso, o el paquete sólo incluye documentación, debemos especificar que es para cualquier arquitectura (all).
Depends: lista de los paquetes que son dependencias. Aquí, podemos especificar las herramientas y aplicaciones software que se utilizan en la asignatura. Si no importa la versión, podemos listar únicamente los nombres separados por comas. Si necesitamos una versión mínima o igual a alguna otra podríamos especificarlo de la siguiente forma:
Maintainer: aquí tu nombre y tu dirección de correo.
Description: esta parte mostrará la descripción del paquete. Puedes tomar como plantilla la propia del ejemplo.
Una vez creado el archivo control vamos a crear otro archivo en el directorio DEBIAN llamado postinst para mostrar un pequeño aviso de fin de instalación:
#!/bin/sh
dialog --msgbox "La documentación y transparencias de redes está disponible en /usr/share/doc/gnesis-redes" 8 40
Le asignamos permisos de ejecución con:
$chmod +x DEBIAN/postinst
Por último, debemos crear un archivo con todos los MD5 de los archivos que contendrá nuestro paquete Debian. Así:
$md5sum*> DEBIAN/md5sum
Y ya sólo queda construir el paquete con dpkg. Pero antes, es posible que nuestro editor nos haya salvado copias de seguridad de los archivos creados (aquellos con el nombre arhchivo~). Si tenemos este tipo de archivos en DEBIAN los borramos con:
$rm DEBIAN/*~
Ahora construímos el paquete:
#dpkg -b. ../gnesis-redes-6.7-1.deb
Esto nos creará en el directorio padre un paquete con el nombre indicado. Se deben respetar las versiones y revisiones que se hayan descrito en el fichero control a la hora de nombrar el .deb definitivo.
Manteniendo el paquete
Para mantener el paquete puedes desarrollarte un pequeño script a partir de lo anteriormente dicho. Si existe alguna modificación en el contenido de tu paquete basta con incorporar los nuevos archivos, actualizar el número de revisión, actualizar los MD5 y reempaquetar.
¿Qué hago para que se publique?
Sólo tienes que enviarme un correo a Cleto.Martin@alu.uclm.es contándome un poco cuál ha sido tu elección y, si está dentro de los márgenes de tamaño lógicos, enviarme el paquete. Si el tamaño del paquete no permite su envío por correo electrónico podemos establecer otro método de entrega.
NOTA
El software y documentación que se distribuyan en los paquetes debe de ser LIBRE. NO SE ADMITIRÁ NI SE DISTRIBUIRÁ ningún material que infrinja las leyes de propiedad intelectual.
Si posees un iBook o PowerBook comprado a mediados de 2005, tu ordenador tiene SMS (Suddent Motion Sensor) para proteger tu disco duro de caídas estrepitosas. Con esta receta lo harás funcionar en tu GNU/Linux y, si quieres, comenzar el desarrollo de aplicaciones para él. Este procedimiento está probado en un iBook G4 con Ubuntu Edgy.
¡Hola chicos/as!
Leyendo cosas por internet he llegado a una conclusión, o mejor dicho, a un punto de vista en el que nunca había caído hasta el momento. Todos las personas que estudiamos informática o, simplemente, nos gusta la informática y conocemos parte de ese inmeso universo hemos sufrido las consecuencias del llamado “amigo informático“.
Esta receta describe qué hacer en GNU/Linux cuando se tiene entre manos un formato de audio propietario como APE.
Introducción
Se trata de archivos nativos correspondientes a una aplicación propietaria llamada monkey's audio. Para poder convertirlo a formato más extendidos y comunes como WAV existe una aplicación libre llamada Mac-port.
Esta receta indica cómo tener comunicación entre GNU/Linux y la calculadora HP48/HP49G/HP49+
HPTALX
Este programita es muy parecido al "HP Connectivity Kit" y funciona razonablemente bien. Tiene soporte tanto para puerto serie como USB. Utiliza el protocolo Kermit, algo anticuado pero el único disponible para comunicarnos con la calculadora. Conforme vayáis utilizando el programa veréis que se atasca un poco y que, de vez en cuando, hay que reiniciar la conexión. Según he leído, son problemas del propio protocolo.
Bien es cierto que las HP49 utilizan otro, además del Kermit, llamado Xmodem. Herramientas para dicho protocolo no he encontrado y sería una gran mejora para esta receta.
Recomiendo que te bajes la última versión del programa en su página web. Es algo inestable, pero funciona bastante bien.
Instalación
hptalx es GPL y lo que te descargas es el código fuente. Antes de proceder con la instalación debes asegurarte de tener:
Librerías de desarrollo de GTK+2 (>=2.4)
Librerías de Glib2 (>=2.4)
C-Kermit (>= 8.0)
libxml (>=2.5)
Una vez tengamos lo anterior, el archivo descargado y descomprimido, sólo tenemos que ejecutar lo siguiente dentro del directorio:
$ ./configure && make && sudo make install
Probando...
Ejecutamos el programa:
$ hptalx
Para configurar el tipo de conexión que tiene nuesra calculadora lo podemos hacer en el menú File. Utilizar, después, "control+b" para conectar la calculadora al ordenador. OJO!!!! El servidor debe estar ejecutado en la calculadora y NO debe ser el Xmodem. Asegúrate que ejecutas el servidor de Kermit.
Esta receta pretende mostrar cómo deshabilitar las secuencias "control+alt" en el servidor gráfico X. Puede ser útil hacer esto en computadores que van a ser utilizados por el público en general y se requieren restricciones en el teclado para el buen funcionamiento del mismo.
Esta receta describe como añadir el plugin de transparencias opacity para Xgl/Compiz.
Requisitos
Se supone que ya tienes aceleración 3D y Xgl/Compiz funcionando en tu máquina. A parte eso, necesitas como es lógico, el el plugin opácity. Para comprender mejor cómo funciona este plugin para compiz puedes mirar este artículo
Instalando y activando el nuevo plugin
Cogemos el .gz descargado y lo descomprimelo. Posteriormente, cópialo a /usr/lib/compiz, que es donde se encuentran por defecto los plugins de compiz carga. Para ello ejecuta:
Una vez tengamos el archivo .so copiado, debes indicarle a compiz que lo cargue. Para ello, añade como argumento la palabra opacity a la llamada de @compiz@. Si tenías:
Para usar el plugin hay que pulsar control + may.izq + rueda_ratón en una ventana (preferiblemente en la barra de título). Subiendo y bajando la rueda del ratón verás como varía la transparencia de la ventana completa; desde totalmente opaca a casi invisible.
Espero que os guste. Un saludo!
Ya está disponible la nueva versión (beta) de gaim. La verdad es que no cambia mucho con respecto a la anterior pero si se le ha añadido funcionalidades nuevas:
¡Pues tomad Howto's! :-)
Es para la versión Hoary pero hay ciertas cosas que no dependen ni de que sea Hoary, ni que de sea Ubuntu. Muy chulo y muy completo. AQUÍ LO TENEIS.
Un saludo!
Cómo recuperar las fotos y videos borrados por accidente de una tarjeta de memoria o la memoria interna de una cámara digital.
Entre la gran cantidad de software que existe para poder recuperar fotos y videos, he encontrado uno libre y que funciona bastante bien. Se trata de Photorec.
Instalación
Si utilizas Debian, Ubuntu o similar es tan fácil como:
#apt-get install testdisk
Uso
Enchufa tu cámara o disco extraible y ejecuta photorec. Para que funcione correctamente, debes tener la ventana de la consola lo suficientemente grande como para que Photorec se ejecute con normalidad. De todos modos, el programita advierte de esta cuestión.
Aparecerá una lista con los dispositivos que tengas enchufados y, si pulsas INTRO sobre el correspondiente, comenzará el escaneo. Conforme va avanzando, Photorec informa de los archivos encontrados y tardará más o menos en función del tamaño del disco (evidentemente).
Una vez finalizado, las fotos o los videos se encuentran en un directorio que crea Photorec llamado recup_dir.*; siendo * el número de fiheros recuperados.
OJO! Este directorio creado pertenece al root. Tienes que utilizar chown para cambiar de propietario, o bien darle permisos con chmod para que tu usuario pueda ver su contenido sin problemas.
Una vez me instalé el amule en mi Ubuntu Hoary para hacer copias de seguridad de mi Windows :-P. Total, que detecté que al arrancarlo las letras aparecían a un tamaño ridículo. Y no sólo me passaba con el amule, también con pptpconfig y otros.
Menudo cambio ha dado la web!!
Siempre he dicho que los blogs es para gente trabajadora y constante... cosa que dudo que yo sea :). Sin embargo, espero aplicarme y poner aquí todo lo que mi vaguedad me permita :P.
Un saludo!
Como todos sabréis a estas alturas, Google ha decidido dispararse en el pie otra vez. El próximo 1 de Julio cerrará el servicio Google Reader sin dar muchas mas explicaciones. No es este el sitio para entrar en las razones que pueda tener Google para cerrar este estupendo servicio. Las cosas que gratis vienen sin mas explicaciones se van, de manera que va siendo el momento de buscar una alternativa.
Que XBMC es el mejor software para media-centers es algo que poca gente discute. La receta que os traigo os permitirá ver todo tipo de eventos deportivos usando XBMC desde vuestra GNU/Linux usando el protocolo Sopcast.
Adventure Game Studio es, quizás, la herramienta de desarrollo de aventuras gráficas de tipo Point&Click mas difundida y famosa del mundo. Está disponible para todas las plataformas, pero como es natural, el soporte era mas bien desigual. Mientras que el player está disponible para todas las plataformas, el editor solo está disponible para windows. Pero esto puede empezar a cambiar ya que los desarrolladores han decidido comenzar a liberar el código bajo Artistic License 2.0, lo cual lo convierte en Software Libre.
Como algunos que me conocen saben, soy seguidor de la scene desde hace muchísimos años. Quizá últimamente no tengo tiempo de estar al día, pero me sigue gustando escuchar la música que sale de ese mundillo. Para los que lo conocen, el sitio http://modarchive.org es un buen punto donde descargar “mods” de todas las épocas.
Munin es una herramienta de monitorización que recopila multitud de datos del sistema y los presenta en forma de gráficas incrustadas en una página web. La gran virtud de munin es su extrema sencillez a la hora de instalarlo y configurarlo. Trae de serie una grandísima cantidad de plugins para monitorizar casi cualquier variable del sistema.
En esta receta veremos que también es extremadamente sencillo crear nuevos plugins para munin. Como ejemplo crearemos un plugin para monitorizar el consumo de ancho de banda de la aplicación mldonkey.
Cómo crear un plugin para munin
Si conocemos un poco de lenguages de script y la naturaleza de los datos que queremos monitorizar, crear un plugin para munin es algo muy sencillo.
Obtención de los datos
Para el caso de mldonkey, utilizaremos el programa mldonkey_command que puede encontrarse en /usr/bin o bien en /usr/lib/mldonkey/. Este programa se conecta mediante telnet al servidor de mldonkey y ejecuta el comando que le pasemos como argumento. Para obtener los valores de velocidad de subida y descarga en ese mismo instante hay que utilizar el comando bw_stats. En el siguiente ejemplo veremos la salida que produce la ejecución:
Los datos que queremos monitorizar están ahí, tan solo tenemos que limpiar un poco el texto. Utilizaremos los comandos grep y cut. Por supuesto cada uno puede utilizar lo que mejor sepa usar. Estos son los filtros que usaré para obtener cada una de las cifras:
Con esto ya sabemos como obtener los datos en bruto. Para que munin acepte estos valores tan solo tendremos que ofrecérselo de una forma algo estructurada. Algo así:
Aquí observamos que creamos una especie de variable e invocamos su atributo valor, asignándole el dato que hemos leído. Ya tenemos lo complicado del script. El resto es tan solo dar formato a los datos.
La confiuración del plugin
Para que munin sepa mas acerca de la naturaleza de los datos, así como información mas detallada de la representación gráfica, debemos proporcionarsela en nuestro script. Munin lo hace invocando el plugin con el argumento config. En ese momento deberemos imprimir por pantalla las opciones de configuración. Para nuestro plugin serán las siguientes.
graph_title MLDonkey traffic: Indica que el título de la gráfica será MLDonkey traffic.
graph_info This graph shows MLDonkey DL/UL rates.: Es una breve descripción de lo que representa la gráfica.
graph_category mldonkey: Con esto indicamos que nuestra gráfica estará en una categoría llamada "mldonkey". Podríamos perfectamente ubicarla dentro de la categoría "Network".
graph_order upload download: Indica el orden de las variables.
graph_args -l 0 --base 1024: Indicamos que el valor mínimo es 0 y que las medidas serán en múltiplos de 1024.
graph_period second: Indicamos que el periodo de medición de la gŕafica será el segundo. Eso significa que el valor en bruto que obtenemos es la velocidad medida en ese preciso instante.
graph_vlabel bytes per ${graph_period}: Esta es la etiqueta que utilizamos para indicar en que unidades se mide el eje vertical. Como se ve, medimos en bytes por segundo.
Ahora, para cada una de las variables, debemos ajustar algunos parámetros. Como se vio anteriormente, la lectura de velocidad que ofrece el servidor de mldonkey, pero nosotros queremos representarlo en bytes por segundo. Para convertir el dato no es necesario modificarlo en el script, munin lo puede hacer por nosotros. Estos son los datos de configuración para cada variable.
download.label download speed: Esto sirve para darle un nombre descriptivo a la variable.
download.max 50000: Con esto establecemos un valor máximo. 50.000 bytes por segundo parece un buen valor.
download.min 0: Este es el valor mínimo que puede alcanzar la variable.
download.cdef download,1024,*: Por último, multiplicamos la lectura por 1024 para obtener el valor en bytes, ya que el servidor de mldonkey nos da el valor en KB, que asumiremos que se trata de KiB.
Con la variable upload haremos exactamente lo mismo. Y con esto ya tenemos toda la información necesaria para montar nuestro plugin.
El plugin completo en un script
Tan solo nos resta meter todo lo dicho antes en un script, mas alguna cosa mas que se explicará posteriormente.
Cuando el script se invoca con el parámetro autoconf el plugin comprueba que tiene todo lo necesario para ejecutarse. En el segundo bloque viene todo lo explicado anteriormente, que no es mas que una enumeración de todos los parámetros de la gráfica. Muchos de esos valores son opcionales y no dudes en jugar con ellos hasta dar con los mas adecuados. Puedes consultar una referencia completa de todos los argumentos en [3].
Al final se ve que el plugin solo se limita a imprimir las variables con los valores de la forma que se explicó al principio de la receta.
Sólo nos quedaría grabar el script en un fichero, darle atributos de ejecución, grabarlo en /etc/munin/plugins y reiniciar el demonio munin-node.
Publico esta mini receta aquí por si a alguien mas está pasando por lo mismo. El problema lo he detectado en Ubuntu, pero creo que el resto de distribuciones mas o menos modernas no están exentas.
Esto es solo un apunte para los que puedan estar interesados. Fluendo, una compañía asentada en Barcelona, que se dedica al desarrollo y consultoría de sistemas multimedia sobre Unix y GNU/Linux y aporta bastante al desarrollo de Gstreamer, está buscando gente. Hoy me he encontrado la oferta en el blog de Elisa, el media center de Fluendo.
Se requiere en primer lugar conocimientos de Inglés, ya que no es una empresa española si no europea, se trabaja en inglés. El resto lo podéis ver en la propia página.
En esta recetilla cuento los pasos que he seguido para crear un pequeño plugin para Freevo, con el que poder lanzar el juego Stepmania. Como tengo la intención de incorporar más juegos al menú de Freevo, he intentado no hacer el plugin demasiado específico.
Hace unos días en The Inquirer(es) pude leer un par de artículos en los que se planteaban, por un lado que "Windows Vista no es una opción", y por otro lado en respuesta al primer artículo que "Linux no es una opción". Ambos artículos caían en los típicos estereotipos y uno anda ya demasiado leído en estos temas como para dar mayor importancia al asunto.
Muchos de los que usamos Ubuntu vimos con poco agrado que se prescindiese del gestor de Salvapantallas XScreensaver. El sustituto fue gnome-screensaver, mucho mas sencillo y con muchas menos funcionalidades.
Con esta mini-receta trataré de devolver la sonrisa a aquellos que dejaron de poder utilizar Xplanet como salvapantallas.
Aunque gnome-screensaver es mucho mas simplón, no limita las posibilidades. Simplemente están fuera de la interfaz de usuario, pero en la práctica sigue siendo perfectamente posible toquetear en sus tripas. Por ahora solo se puede hacer desde la consola, pero el equipo de gnome-screensaver tiene en mente extender su interfaz para que sea algo mas configurable (ya que a día de hoy no lo es en absoluto).
En el paquete 'xscreensaver-data' podremos encontrar un montón de ficheros con extensión .desktop, estos ficheros contienen los lanzadores de los salvapantallas. Lo único que tendremos que hacer es crearnos nuestro propio lanzador y colocarlo en el sitio adecuado. Además tendremos que crear un enlace para Xplanet en el directorio donde se encuentran los salvapantallas.
En primer lugar, creamos un fichero xplanet.desktop con este contenido.
[Desktop Entry]
Encoding=UTF-8
Name=XPlanet
Comment=This Shows random planets from random points of view using Xplanet.
TryExec=xplanet
Exec=xplanet -vroot -label -body random -origin random -radius 20 -range 10 -wait 30
StartupNotify=false
Terminal=false
Type=Application
Categories=Screensaver
X-Ubuntu-Gettext-Domain=xscreensaver
La etiqueta Exec es la que contiene el comando concreto que deberemos ejecutar para mostrar nuestro salvapantallas. En mi caso muestro un cuerpo aleatorio desde un origen aleatorio y lo cambio cada 30 segundos.
Una vez creado el fichero lo copiamos al directorio /usr/share/gnome-screensaver/themes/.
Actualización: Los usuarios de Ubuntu Edgy deben copiar el fichero en el directorio /usr/share/applications/screensavers/.
El mes de Julio pasado pude ver en vivo el juego de PS2 Guitar Hero. Me sorprendió gratamente, tanto por la originalidad como por la sensación de que un nuevo tipo de entretenimiento se está imponiendo en el panorama actual. Ya no se hace tanto juego “mata mata” y se está dando paso a juegos en los que la habilidad se demuestra de otras formas. Bien sea cantando, bien bailando, bien tocando los bongos o bien tocando una especie de armatoste parecido a una guitarra. Y esto no ha hecho mas que empezar, la próxima Nintendo Wii promete revolucionar el mundo de los videojuegos con su nuevo mando.
Pululando por el blog de desarrollo de la próxima versión del plugin de flash para GNU/Linux, he visto una recetilla que explica cómo solucionar el problema de desincronización de audio y video que sufrimos los que usamos el plugin de flash en GNU/Linux, sobre todo aquellos que no disponen de un ordenador muy potente.
Yo lo he probado en mi portátil, en el que el problema era de lo mas acusado y se ha solucionado como por arte de magia.
La forma de solucionarlo en sistemas Debian y similares es la siguiente.
Instala el paquete “alsa-oss”.
Crea el fichero de entrada “/etc/asound.conf” con este contenido:
Tengo casi a punto un nuevo “sabor” de Molinux. En esta ocasión he conseguido meter la distribución en un “pendrive”. Por ahora es la distribución Live estándar, por lo que hacen falta 620MB de espacio para hacerlo funcionar.
La particularidad de esta versión es que no se limita a ejecutar la distribución Live desde un pendrive sino que permite además que nuestros datos personales permanezcan archivados en el de forma que esta manera de llevar Molinux es algo mas funcional.
He leido (via Barrapunto) que se ha puesto en marcha la iniciativa Neutralidad Tecnológica que pretende lograr que la infraestructura informática del Estado deje de ser monopolio de una sola tecnología propietaria (lease Microsoft).
La iniciativa parte de la asociación Linux Español y el abogado Jose María Lancho, conjuntamente con la asociación de abogados Legalventure y la revista Linux Magazine
Si siempre os habéis preguntado como es el lugar donde se fabrican las placas base, os paso un interesantísimo enlace en el que podréis hacer un completo tour por una de las factorías del fabricante de placas base Gigabyte.
Comienza el viaje
Hace tiempo, concretamente el pasado 12 de Enero de 2004, 3DRealms liberó el código fuente de uno de sus mejores juegos de todos los tiempos, Duke Nukem 3D. Desde aquel momento muchos programadores comenzaron a intentar adaptar el juego a los nuevos sistemas operativos.
No tardaron en llegar las primeras versiones para GNU/Linux, que con mas o menos dificultades consiguieron que se pudiese jugar.
Como esto es todavía algo muy experimental no lo pongo en recetas. El caso es que los propietarios de un iBook de Apple ya pueden tener cierto soporte nativo de su tarjeta wireless. El artículo es una adaptación traducida del catalán de la gente de Bulma. Si se os da bien el catalán siempre podéis mirar el original
Más de uno, al pasarse a GNU/Linux se ha encontrado con el problema de no poder reproducir los ficheros midi porque su tarjeta no tiene ningún sintetizador midi integrado y los drivers alsa no lo emulan (cosa que suele venir de serie en los drivers de windows). Si te gustan los midis, o quieres recuperar el arte del karaoke desde GNU/Linux, ahí va esta pequeña receta.
A veces el servidor de sonido esound es un latazo porque impide que otras aplicaciones que hacen uso del hardware de sonido puedan funcionar. De modo que para jugar a algunos juegos necesitamos apagar el servidor de sonido y siempre resulta algo tedioso.
Esta receta explica como poner un fondo de pantalla muy resultón que consiste en una imagen realista de la Tierra con iluminación y nubes “reales”, que además se va actualizando para representar la situación actual. Todo ello gracias a xplanet.
Esta receta es para todos aquellos que estais en un entorno restrictivo en el que solo hay acceso al exterior a través de un proxy HTTP, como es mi caso actualmente.
Tan solo os será necesario un programa llamado Corkscrew. Los usuarios de Debian y derivados lo tenemos a tiro de apt-get.
Explicación
¿Qué hace este programa? Pues aprovecha una capacidad del proxy, el método CONNECT que permite hacer una conexión a un puerto TCP usando al proxy como intermediario. Lógicamente esto es de sobra conocido por un administrador de red y lo mas normal es que el proxy esté situado detrás de un firewall que no permitirá al proxy acceder a puertos distintos de los puramente web. Estos puertos son el HTTP:80 y HTTPS:443, cabe la posibilidad de que también tengamos acceso a FTP a través del proxy, lo que significará que éste también puede acceder a los puertos 20 y 21.
Con esta información ya nos vamos haciendo una idea de lo que va a pasar. Vamos a invocar ssh a través de Corkscrew para que se conecte al servidor de destino utilizando el proxy. El servidor de SSH utiliza el puerto 22 y lo normal es que el proxy no pueda acceder a dicho puerto, por este motivo será necesario que en el servidor al que queremos acceder le hayamos hecho un pequeño truco previo. El “truco” consiste en redirigir un puerto web que no esté en uso al puerto 22. Usualmente se utiliza el 443.
Vamos a ver como se cocina todo esto junto.
Elaboración
En primer lugar hay que redirigir el tráfico de nuestro servidor, del puerto 443 al 22. Una opción es lanzar el demonio ssh directamente en el puerto 443, pero eso no parece una solución elegante. No obstante quien quiera hacerlo no tiene más que tocar en /etc/ssh/sshd_config.
Lo mas limpio es usar iptables para redirigir el trafico. La orden es esta.
Donde proxy.curro.es el la dirección del proxy de nuestra red y 8080 es el puerto que usa el proxy. Las variables %h y %p se refieren al host y al port que usaremos para conectar y se le pasan desde el comando ssh como veremos a continuación.
Ahora para conectar a cualquier sitio tan sólo necesitamos ejecutar la orden.
$ssh -p 443 usuario@servidor.casa.com
Más difícil todavía
Si nuestro proxy necesita autenticación tendremos que crear un segundo fichero en .ssh/autenticacion con lo siguiente
Si os pasa, además de todo lo anterior, que vuestra conexión se corta cada dos por tres por falta de actividad basta con añadir esto en el fichero ssh_proxy
Vale, ya puedo acceder mediante SSH al ordenador de casa desde el trabajo, ¿y que? Pues si tenéis problemas con el proxy de vuestro trabajo porque os deniega el acceso a algunas páginas web que os son imprescindibles y el departamento de sistemas os ignora completamente, tan solo tenéis que instalar un proxy HTTP en vuestro ordenador, como por ejemplo squid (la configuración por defecto de squid en Debian funciona para lo que queremos hacer) y tunelizar las peticiones desde nuestro ordenador con el siguiente comando.
Estamos suponiendo que el servidor squid casero corre en el puerto por defecto, y redirigimos nuestro puerto local hacia el puerto remoto. Ahora solo tenemos que configurar el programa que queramos para que use como proxy
localhost:3128
y todo listo, ya estamos usando el proxy de casa sin restricciones.
Escenario: trabajas en una oficina y el jefe ha comprado una impresora sin avisar. Y además es una winprinter. Veremos cómo podemos imprimir en una winprinter compartida por red.
El desafío
Al igual que los infames winmodems, también existen winprinters que sólo funcionan en MS Windows, en mi caso me toca sufrir una OKI C3100. Esta impresora en particular salió al mercado en el 2004, y no tiene pinta de que sea soportada en un futuro lejano.
Al jefe, está claro, no le hace ni p$%& gracia que no funcione la dichosa impresora y como siempre recurre a la solución fácil: o imprimen todo quisque o los puestos con GNU/Linux desaparecen.
Qué podemos hacer
El problema que tenemos es que no podemos imprimir directamente en la impresora; pues pongamos algo entre medias que nos comunique con la impresora. El problema de los servidores de impresión tradicionales es que siguen necesitando los drivers para imprimir, mi gozo en un pozo. Gracias a $DEITY un alma caricativa me puso en la buena dirección.
La solución
La cuestión entonces es poner algo que recoja los trabajos y se los encole a la winprinter. Lo malo, sigo necesitando un equipo con MS Windows, pero por lo menos no desaparecerán los puestos con GNU/Linux. Buscando por Google encontré un artículo que trataba sobre cómo crear una impresora Postscript virtual en Windows usando Ghostscript, que es justo lo que estaba buscando.
El artículo explica paso a paso (eso sí, en perfecto inglés) como instalar y configurar Ghostscript y RedMon para crear una impresora virtual, de tal forma que se siga este proceso:
Aunque parezca mentira, no pocas empresas u oficinas tienen algún programa DOS hecho a medida que las hacen depender de MS-DOS, y por tanto de MS Windows. Esto puede ser un gran problema a la hora de una posible migración a GNU/Linux. Con esta receta aprenderemos cómo ejecutar estos programas en una Molinux Sancho gracias al emulador dosemu.
Instalación de dosemu
Dosemu es un emulador de DOS para GNU/Linux, licenciado bajo la GPL, que permite correr un DOS (MS-DOS, FreeDOS...) y aplicaciones DOS. Utilizaremos además FreeDOS. FreeDOS es un proyecto que aspira a crear un sistema operativo libre que sea totalmente compatible con las aplicaciones y los controladores de MS-DOS.
Ni dosemu ni FreeDOS están en los repositorios de Molinux Sancho, así que añadire unos repositorios de Ubuntu Breezy (no olvides que Sancho es en realidad una Breezy). Para ello debes editar el fichero /etc/apt/sources.list y añadir la siguiente línea:
deb http://archive.ubuntu.com/ubuntu breezy main multiverse
y ejecutar posteriormente aptitude update como de costumbre. A continuación instala los paquetes:
El paquete es casi perfecto, sólo necesita un par de ajustes para tener dosemu completamente operativo y funcional.
Violación de segmento al ejecutar dosemu
Si al ejecutar Dosemu te da una violación de segmento con el siguiente error:
ERROR: cpu exception in dosemu code outside of VM86()!
trapno: 0x0e errorcode: 0x00000004 cr2: 0x468a5b2d
eip: 0x468a5b2d esp: 0xbf8fffc5 eflags: 0x00210286
cs: 0x0073 ds: 0x007b es: 0x007b ss: 0x007b
Page fault: read instruction to linear address: 0x468a5b2d
CPU was in user mode
Exception was caused by non-available page
/usr/bin/dosemu: line 218: 16058 Violación de segmento $SUDO $BINARY $XFLAG "$@"
es un problema con versiones del kernel Linux posteriores a la 2.6.12. Es debido a cambios en la ¿generación de direcciones virtuales? (virtual address randomization) del kernel. La solución es ejecutar
sudo echo 0 >/proc/sys/kernel/randomize_va_space
la primera vez que ejecutes dosemu. Lo ideal es hacer un script y ponerlo en el arranque de la máquina.
Cuando ejecuto xdosemu no encuentra la fuente vga, y muchos carácteres están mal
La solución es por tanto sencilla; debes añadir la línea
FontPath "/usr/X11R6/lib/X11/fonts/misc/"
justo después de la línea que nos salió anteriormente. Reinia el servidor X posteriormente.
Invocación
Si ejecutamos dosemu desde una emulación del terminal tendremos bastantes menos problemas que si lo hiciésemos desde un terminal normal y corriente. Además, dependiendo del programa, será posible que necesitemos derechos de superusuario para acceder a determinados puertos y tal.
Para programas DOS normales, la mejor solución sin duda será usar xdosemu:
$xdosemu programa.exe
porque nos ahorraremos un montón de problemas tanto de carácteres como de tamaño del terminal y demás. xdosemu de hecho nos abre una ventana con el programa DOS al igual que si lo hubiésemos ejecutado en MS Windows.
Todos los alumnos y profesores de la UCLM que usan otro navegador web que no sea Internet Explorer saben lo "peculiar" que es la web de RedC@mpus. Esta receta explica cómo arreglar este incomprensible error.
Esta receta describe cómo recoger estadísticas de uso de red mediante la interfaz Ice::Stats en una aplicación que utilice ZeroC ICE.
Herramientas
ZeroC ICE (en este enlace se describe su instalación en Debian).
La interfaz Ice::Stats.
Uso de la interfaz Ice::Stats
La interfaz Ice::Stats permite informar sobre el número de bytes enviados y recibidos por cada invocación:
local interface Stats {
void bytesSent(string protocol, int num);
void bytesReceived(string protocol, int num);
};
El proceso a seguir consiste en implementar la interfaz Ice::Stats y registrar ese sirviente a la hora de inicializar el communicator. Una implementación sencilla consistiría en imprimir la información de uso de red:
// MyStats.h#include <Ice/Stats.h>
usingnamespacestd;classMyStats:publicvirtualIce::Stats{public:virtualvoidbytesSent(conststring&prot,Ice::Int);virtualvoidbytesReceived(conststring&prot,Ice::Int);};// MyStats.cpp#include <MyStats.h>
usingnamespacestd;voidMyStats::bytesSent(conststring&prot,Ice::Intnum){cerr<<prot<<": sent "<<num<<"bytes"<<endl;}voidMyStats::bytesReceived(conststring&prot,Ice::Intnum){cerr<<prot<<": received "<<num<<"bytes"<<endl;}
A continuación, tendremos que instalar un objeto de la clase MyStats en el communicator del cliente, del servidor o de ambos. Este paso se lleva a cabo a la hora de crear el communicator y mediante una estructura del tipo Ice::InitializationData. Como lo normal es que utilicemos la clase Ice::Application, el código del cliente, por ejemplo, quedaría más o menos así:
En esta receta se describe qué es IceStorm (el servicio de publicación-subscripción de ICE) junto con algunos ejemplos que muestran su funcionalidad.
Antecedentes
En Empezar con ZeroC Ice en Debian se describió cómo adentrarse en ZeroC Ice. Ahora llega el turno de conocer IceStorm, uno de los servicios que nos ofrece esta herramienta multiusos.
Nota: Para probar los ejemplos de esta receta se ha utilizado la versión 3.2.1-3 de Ice y la versión 2.4.4 de Python.
Conceptos básicos
IceStorm es un servicio eficiente de publicación-subscripción para aplicaciones Ice. Desde un punto de vista funcional, IceStorm actúa como mediador entre el publicador y el subscriptor, proporcionando varias ventajas:
Sólo es necesaria una llamada al servicio IceStorm para distribuir la información a los subscriptores.
Independencia entre el emisor y los receptores de información, permitiendo que el primero se ocupe de las responsabilidades relativas a la aplicación y no de tareas administrativas.
Los cambios introducidos en el código son mínimos para incorporar la funcionalidad de IceStorm.
De manera general, una aplicación indica su interés en recibir mensajes subscribiéndose a un topic. Un servidor IceStorm soporta cualquier número de topics, los cuales son creados dinámicamente y distinguidos por un nombre único. Cada topic puede tener varios publicadores y subscriptores. Un topic es equivalente a una interfaz Slice: las operaciones del interfaz definen los tipos de mensajes soportados por el topic. Un publicador usa un proxy al interfaz topic para enviar sus mensajes, y un subscriptor implementa la interfaz topic (o derivada) para recibir los mensajes. Realmente dicha interfaz representa el contrato entre el publicador (cliente) y el subscriptor (servidor), excepto que IceStorm encamina cada mensaje a múltiples receptores de forma transparente.
Un ejemplo sencillo
A continuación se mostrará un ejemplo sencillo de cómo utilizar IceStorm. Dicho ejemplo consiste en una serie de objetos cuyo propósito es procesar una determinada estructura de datos. Para ello, se define el siguiente archivo a través de Slice (simple.ice):
Básicamente, disponemos de una estructura que contiene una cadena y una interfaz con una sencilla operación de procesado. Teniendo en cuenta la funcionalidad básica de IceStorm, con esta sencilla aproximación podríamos diseñar un sistema que permitiera procesar esta estructura por distintos servidores empleando una única llamada a IceStorm y de forma transparente para el publicador.
Creando el publicador
Veamos ahora el código del publicador (publisher.py):
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys, Ice, IceStorm
Ice.loadSlice('simple.ice', ['-I', '/usr/share/slice'])
import Simple
class Publisher (Ice.Application):
def run (self, argv):
# Proxy al TopicManager.
prx = self.communicator().stringToProxy('Simple/TopicManager:tcp -p 10000')
topicManagerPrx = IceStorm.TopicManagerPrx.checkedCast(prx)
# Proxy al topic.
try:
topicPrx = topicManagerPrx.retrieve('MyTopic')
except IceStorm.NoSuchTopic:
topicPrx = topicManagerPrx.create('MyTopic')
# Proxy al objeto que publica.
pub = topicPrx.getPublisher()
processorPrx = Simple.ProcessorPrx.uncheckedCast(pub)
# Publicación.
m = Simple.Message('content')
processorPrx.process(m)
return 0
Publisher().main(sys.argv)
Como se puede apreciar, el código habla por sí mismo (incluso sin fijarnos en los comentarios). Ésta es una de las principales ventajas de utilizar Ice: hace que el crear aplicaciones distribuidas implique muy pocos cambios en el código de la aplicación. A nivel general, se llevan a cabo los siguientes pasos:
Se crea un proxy a un objeto de tipo TopicManager.
Se recupera un proxy al topic en cuestión.
Se obtiene un proxy al publicador.
Se invoca a la operación remota process.
Creando el subscriptor
Sencillo, ¿verdad? Pues el código del subscriptor (subscriptor.py) se mantiene en esa misma línea:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys, Ice, IceStorm
Ice.loadSlice('simple.ice', ['-I', '/usr/share/slice'])
import Simple
class ProcessorI (Simple.Processor):
def process (self, message, curr):
print message.content
class Subscriber (Ice.Application):
def run (self, argv):
self.shutdownOnInterrupt()
# Proxy al TopicManager.
prx = self.communicator().stringToProxy('Simple/TopicManager:tcp -p 10000')
topicManagerPrx = IceStorm.TopicManagerPrx.checkedCast(prx)
# Creación del objeto remoto.
oa = self.communicator().createObjectAdapterWithEndpoints('SubscriberOA', 'default')
processorPrx = oa.addWithUUID(ProcessorI())
# Proxy al topic.
try:
topicPrx = topicManagerPrx.retrieve('MyTopic')
except IceStorm.NoSuchTopic:
topicPrx = topicManagerPrx.create('MyTopic')
# Subscripción.
topicPrx.subscribeAndGetPublisher(None, processorPrx)
oa.activate()
self.communicator().waitForShutdown()
topicPrx.unsubscribe(processorPrx)
return 0
Subscriber().main(sys.argv)
El código es prácticamente idéntico. Sin embargo, en este caso tenemos que crear un adaptador de objetos para albergar el sirviente y, posteriormente, registrar este último (encargado de encarnar al objeto remoto). La parte más importante es la relativa a la operación subscribeAndGetPublisher, la cual añade un proxy subscriptor al topic (processorPrx) sin tener en cuenta la calidad del servicio (None).
Ejecutando IceStorm
Llegados a este punto ya tenemos definidas estas sencillas versiones del publicador y el subscriptor. Ahora sólo queda ejecutar IceStorm y poner en funcionamiento el sistema. IceStorm es un servicio relativamente ligero que se implementa como un servicio IceBox. Por lo tanto, el primer paso consiste en arrancar IceStorm:
$icebox --Ice.Config=config.icebox
El archivo de configuración básico (config.icebox) podría ser el siguiente:
Simplemente se informa a IceBox que se va a levantar una instancia del servicio IceStorm, con unas determinadas propiedades especificadas en el archivo de configuración asociado (config.icestorm):
En este archivo de configuración se especifica el nombre de la instancia de IceStorm, la dirección de escucha de un proxy del tipo TopicManager y el directorio utilizado por IceStorm para gestionar su persistencia a través de Freeze (servicio de persistencia de Ice). Ya sólo queda ejecutar el subscriptor (podemos ejecutar tantos como queramos para comprobar que todos reciben las invocaciones remotas):
$python subscriptor.py
Y el publicador:
$python publisher.py
Federación de topics
Una de las funcionalidades de IceStorm más interesantes es la posibilidad de establecer una jerarquía entre los distintos topics, creando un grafo dirigido en el que se establece el concepto de coste. En otras palabras, podemos establecer una jerarquía de topics de manera que los mensajes fluirán por los distintos enlaces que conectan los topics en función del coste asociado al mensaje por una parte, y al enlace por otra.
Imaginemos un grafo en el que tenemos tres topics: A, B y C. A tiene un enlace con B de coste 1, mientras que A tiene un enlace con C de coste 2, es decir:
A ----- c(1) -----> B
A ----- c(2) -----> C
Por otra parte, supongamos un subscriptor Sb vinculado a B, un subscriptor Sc vinculado a C y un publicador P vinculado a A. Si P envía un mensaje de coste 1, este mensaje llegará a A y fluirá a B y C debido a que el coste del mensaje es igual o menor que el de los enlaces, llegando por tanto a los subscriptores Sb y Sc. Sin embargo, si P envía un mensaje de coste 2, éste sólo llegará a Sc ya que el enlace existente entre A y B tiene un coste 1, por lo que el subscriptor Sb quedaría sin notificación y, por otra parte, Sc sí recibiría el mensaje. Merece la pena destacar que un mensaje de coste 0 fluye por todos los enlaces.
Desplegar esta jerarquía de topics en IceStorm es muy sencillo con la herramienta de administración de IceStorm:
El archivo graph.txt representa dicha jerarquía y es muy simple:
create A B C
link A B 1
link A C 2
Con este sencillo archivo de texto creamos los topics y los enlaces entre ellos.
Ahora debemos adaptar el publicador y el subscriptor incluyendo esta nueva funcionalidad. El publicador sólo necesita vincularse al topic A y asociar el coste al mensaje. Para ello se utiliza el argumento implícito de contexto que toda operación de un proxy conlleva. En Python es muy simple:
En este ejemplo en concreto, el mensaje sólo llegará al subscriptor vinculado al topic C:
david@TheSecondWorldHeaven:~/Universidad/ZeroC_ICE/src/icestorm/topicFederation$ python subscriber.py C
Message: content
Cost: 2
Conclusiones
Con IceStorm podemos gestionar el envío y la recepción de eventos de una manera sencilla, flexible y eficiente. La conclusión más importante que podemos obtener es la ventaja que supone el hecho de poder centrarte en la aplicación en cuestión, minimizando el tiempo empleado en cuestiones ajenas a la naturaleza de la misma y obteniendo un sistema eficiente. En particular, la federación de topics ofrece características muy interesantes a la hora de crear aplicaciones distribuidas, permitiendo jugar con la distribución de eventos a nuestro antojo.
¿Y ahora qué?
Por supuesto, todo este despliegue puede ser más sencillo y más transparente si utilizamos IceGrid tanto para desplegar la instancia de IceStorm como para localizar los distintos objetos involucrados en la aplicación. Además, es posible crear un sistema totalmente dinámico que gestione la creación y destrucción de topics en función de la naturaleza de nuestra aplicación. Por otra parte, IceStorm permite añadir más funcionalidades descritas en profundidad en el manual de Ice. Todo eso queda para una futura receta.
Esta receta tiene como objetivo proporcionar una guía para la instalación de una distribución GNU/Linux junto con el SDK para el procesador Cell en PlayStation 3.
Introducción
PlayStation 3 tiene como corazón el procesador Cell. Esta revolución tecnológica fue desarrollada inicialmente para PlayStation 3 por Sony Computer Entertainment, Toshiba e IBM. Sin embargo, el verdadero objetivo de este proyecto es la obtención de un procesador con una gran potencia de cálculo a un bajo coste.
Arquitectura del Cell
Cell es una arquitectura orientada a la computación distribuida de alto rendimiento. De acuerdo con IBM, la potencia ofrecida por este procesador es de un orden de magnitud mayor que la ofrecida por los procesadores actuales. En comparación con las unidades de procesamiento gráfico (GPUs), Cell supone una importante ventaja al tratarse de una herramienta de propósito general que se puede utilizar para una gran variedad de tareas.
Una de las principales características de la arquitectura Cell es el escalado a nivel de procesador. Sin embargo, un único chip proporciona una gran cantidad de cálculo por sí mismo (256 GFLOPS a 4 GHz).
La arquitectura está formada por los siguientes elementos:
1 PPE (Power Processor Element).
8 SPEs (Synergistic Processor Elements).
EIB (bus de interconexión).
DMAC (controlador de acceso a memoria).
2 Rambus XDR memory controllers (controladores de memoria).
Rambus FlexIO interface (interfaz de entrada/salida).
El corazón del procesador es el PPE, un microprocesador convencional cuya principal tarea (aunque puede utilizarse con otros propósitos) es la de distribuir el trabajo entre los SPEs, encargados de efectuar la mayor parte de los cálculos de una aplicación. A pesar de que puede funcionar a una velocidad mayor, el chip Cell utilizado en PlayStation 3 corre a 3,2 GHz y tiene 7 SPEs disponibles.
El PPE es un procesador de 64 bits con una Power Architecture. Este tipo de procesador no se utiliza en los computadores personales y es capaz de ejecutar binarios de POWER y PowerPC.
El SPE se puede considerar como un procesador vectorial independiente de 128 bits. Cada SPE es capaz de ejecutar 4 operaciones de 32 bits por ciclo. Para obtener ventajas en el desarrollo de aplicaciones en el Cell, los programas necesitan ser vectorizados.
Existen muchas más decisiones de diseño en la arquitectura Cell que la hacen muy diferente a las arquitecturas convencionales utilizadas en los computadores personales, proporcionando una revolución y no un simple paso más en la evolución [Blachford_Cell_v2].
Ingredientes
1 PlayStation 3 con una versión del firmware igual o superior a la 1.6.
1 CD o DVD vírgenes para grabar el sistema operativo a instalar.
1 CD vírgen.
1 pendrive.
1 teclado y un ratón con conexión USB.
1 conexión cableada a Internet.
Actualmente, existen distintas distribuciones que pueden instalarse en PlayStation3, como por ejemplo Yellow Dog Linux, Helios Linux, Fedora Core 6, Ubuntu, Gentoo, o Debian, entre otras.
La distribución en cuestión a instalar se deja a gusto del lector, pero es imprescindible descargar una ISO para una arquitectura PowerPC. En mi caso, elegí la distribución Fedora Core 6, y descargué una ISO para grabar en un DVD. También es necesario obtener la ISO relativa al Linux add-on CD, descargando el archivo CELL-Linux-CL-20061110-ADDON.iso. Por último la herramienta más importante, el entorno de desarrollo para el Cell: SDK 2.1.
El cargador de arranque
El siguiente paso es hacerse con un gestor de arranque. La opción más directa es obtenerlo desde el Linux add-on CD. Éste se encuentra en el directorio kboot y su nombre es otheros.bld.
En el pendrive hay que crear un directorio llamado PS3, y dentro de éste otro llamado otheros, en el cual hay que copiar el cargador de arranque (otheros.bld)
Llegados a este punto, se ha de disponer de los siguientes elementos:
1 CD o DVD con la distribución a instalar.
1 Linux add-on CD.
1 dispositivo de arranque (pendrive) con el cargador de arranque.
1 CD con la ISO del SDK.
1 PlayStation 3 con una versión del firmware igual o superior a la 1.6 y una conexión cableada a Internet.
Instalación
En este momento, es importante resaltar que es necesario formatear el disco duro de PlayStation 3, por lo que se recomienda hacer una copia de seguridad. Sin embargo, los ajustes personales no se perderán.
Para formatear al sistema hay que acceder al menú de PlayStation 3 Ajustes -> Ajustes del sistema -> Herramienta de formateo -> Formatear disco duro. La herramienta de particionado ofrece distintas opciones. En mi caso, me dio la opción de hacer dos particiones: una de 10 GB y otra de 50 GB. Yo elegí asignar 10 GB al sistema operativo a instalar y 50 GB al sistema operativo de PlayStation 3 (GameOS).
Para instalar el gestor de arranque, es necesario conectar el pendrive y acceder al menú Ajustes -> Ajustes del sistema -> Instalar otro sistema operativo. El propio sistema localizará el archivo otheros.bld.
Una vez seguidas estas indicaciones, el siguiente paso es cambiar el sistema operativo por defecto y reiniciar. Para ello, se ha de acceder al menú Ajustes -> Ajustes del sistema -> Sistema predeterminado, y elegir la opción Otro sistema operativo. En este punto, el proceso de instalación diverge en función del sistema operativo elegido. En caso de instalar Fedora Core 6, y después de la aparición de la orden kboot, el comando a introducir es install-fc sda. Posteriormente, el sistema pide el DVD de instalación y, eventualmente, el Linux add-on CD para la instalación del sistema operativo. Una vez instalado el sistema operativo, el comando boot-game-os permite arrancar PlayStation 3 con el sistema operativo de los juegos.
En caso de utilizar una televisión con certificación HD Ready o FullHD se puede llevar a cabo el proceso de instalación a través de la televisión sin dañarnos la vista. Sin embargo, si se utiliza una televisión con definición estándar, resulta muy aconsejable continuar con el proceso de instalación de manera remota a través de ssh (en caso de seguir el proceso desde la TV, reducir el contraste puede ayudar).
La instalación es una instalación tradicional, aunque algo diferente en lo relativo al ajuste del modo de vídeo. En el caso de Fedora Core 6, el comando ps3videomode permite ajustar la resolución y el escaneado de la salida de vídeo para un ajuste óptimo en la televisión (o monitor).
Instalación del SDK 2.1
En este paso se asume la instalación de todas aquellas herramientas necesarias para la instalación/construcción de las bibliotecas de desarrollo del SDK 2.1. En caso de instalar Fedora Core 6, se puede utilizar la herramienta yum para la instalación de todas estas herramientas [PS3_FedoraCore6]. El proceso es sencillo:
La instalación del SDK se puede efectuar con o sin simulador:
#./cellsdk install[--nosim]
Este proceso implica la descarga de ciertos archivos. En caso de que haya algún problema en esta descarga, la solución consiste en volver a ejecutar este último comando.
Las bibliotecas de desarrollo no vienen como archivos ejecutables, por lo que es necesario generarlos a partir del compilador xlc o del compilador gcc (opción por defecto):
Este proceso involucra algo de tiempo. Una vez finalizado se desmontará la imagen:
#umount /mnt/cellsdk
¿Y ahora...?
En caso de adentrarse en el desarrollo de aplicaciones para el procesador Cell, es posible sentirse abrumado por la cantidad de documentación e información existente, además del cambio que supone el tratar con una arquitectura tan distinta con la que la mayoría no solemos trabajar. Una buena referencia es el portal PS3coderz, en el cual se indexa la documentación asociada al Cell en varias secciones.
Conclusiones
Si has llegado a este punto, tienes en tu poder un sistema GNU/Linux+Cell SDK 2.1. El siguiente paso y el más importante, en caso de que te pique el gusanillo, consiste en que te familiarices con la arquitectura Cell y con sus herramientas y bibliotecas de desarrollo.
Cada vez escucho con más frecuencia la frase "Los programadores son albañiles"... y cada vez me preocupan más las ideas de algunas personas, sobre todo Ingenieros o Doctores en Informática. Básicamente, la comparación viene a decir que los Ingenieros en Informática serían una especie de arquitectos, mientras que los programadores en cuestión serían los albañiles o los obreros.
En esta receta se describe cómo instalar el middleware ZeroC ICE en Debian SID y cómo ejecutar un ejemplo básico en Python.
Introducción
ZeroC ICE es un middleware orientado a objetos, es decir, ICE proporciona herramientas, APIs, y soporte de bibliotecas para construir aplicaciones cliente-servidor orientadas a objetos. La filosofía de ZeroC ICE es la construcción de una plataforma tan potente como CORBA, pero sin cometer todos los fallos de ésta y evitando una complejidad innecesaria. ICE es software libre y está liberado bajo la licencia GNU/GPL.
Instalación
Si somos usuarios de Debian y/o derivados, la instalación es muy sencilla:
#apt-get update
#apt-get install zeroc-ice33
¡Hola, mundo!
El lenguaje de especificación de interfaces de ICE es Slice, y se utiliza para definir las interfaces, las operaciones, y los tipos de datos intercambiados entre el cliente y el servidor, entre otras cosas.
El clásico ejemplo de ¡Hola, mundo! en Slice sería muy sencillo:
El servidor crea un objeto de tipo HolaMundo y lo registra en un adaptador de objetos, encargado de manejar las operaciones remotas (o locales) sobre sus objetos asociados.
Esta receta explica la instalación y configuración inicial de NINO (NINO is not Openview) en Debian GNU/Linux. Concretamente se ha realizado la instalación en Debian Sid con núcleo Linux 2.6.14.
NINO es una solución para la gestión de red vía interfaz web que emplea SNMP, WMI, y SNMP para monitorizar equipos y dispositivos de red.
Para más información visitar la página oficial de NINO.
A veces necesitamos editar archivos en una o varias máquinas remotas con acceso ssh. Muchas veces en esas máquinas no hay emacs o es una versión antigua que no podemos, no queremos o debemos actualizar. Hay una manera muy sencilla de editar archivos, compilar en máquinas remotas y demás posibilidades que ofrece emacs con tu emacs local: usando "TRAMP mode" (Transparent Remote Access). En concreto yo lo uso con SSH. En las referencias se puede consultar como obtenerlo e instalarlo, en debian basta con instalar el paquete emacs. Una vez instalado sólo tenemos que ejecutar lo siguiente:
En esta receta vamos a ver cómo "sacar" el sonido por algún dispositivo de audio bluetooth. En mi caso he configurado un altavoz bluetooth Yamaha NX-BO2.
Esta receta explica brevemente como configurar emacs para utilizarlo junto con cscope, una herramienta para navegar a través de código fuente C/C++.
Ingredientes
emacs
cscope
Configuración
Si te has instalado cscope en Debian/Ubuntu se te habrá instalado la interfaz de cscope para (X)Emacs que se encuentra en el archivo /usr/share/emacs/site-lisp/xcscope.el. Para el resto de distribuciones tendrás que asegurarte de que el archivo xcscope.el está en un directorio donde Emacs pueda encontrarlo.
El siguiente paso es editar el archivo ~/.emacs añadiendo lo siguiente:
(require 'xcscope)
Si deseas añadir atajos para hacer más comoda la introducción de algunas órdenes puedes añadir los siguiente también el el archivo ~/.emacs:
Abres los ficheros de código fuente C/C++, utilizas los comandos del tipo cscope-* (M-x cscope-* o utilizas las teclas atajo) para buscar deficiones, símbolos, etc. El funcionamiento básico es así de sencillo.
Referencias
El propio archivo xcscope.el explica más profundamente, en los comentarios del principio del archivo, la configuración y el funcionamiento.
Puesto que me encuentro como tantos otros dandole vueltas a la dichosa aceleracion 3d con ATI en Ubuntu, segui un tutorial que recomendaba la eliminacion de todo lo referente al modulo fglrx que viene en los repostiorios, segui dicho tutorial y parece ser que la cosa funciona mas o menos, dmesg no me lanza ningun error relacionando con el driver ni nada por el estilo, pero cuanod ejecuto glxgears:
Bueno, pues hoy arranco la web de CISCO y al intentar ejecutar las pruebas, cual es mi sorpresa cuando veo que el test no se ve apropiademante! Concreto, me aparecen las casillas para marcar las respuestas, las pestañas para seleccionar las preguntas, las imagenes en caso de haberlas, pero no me aparece nada de texto... sorprendente cuan menos!
No se si por algún tipo de incompatibilidad, por ineptitud o sabe FSM qué, Renfe no permite elegir asiento si utilizas un navegador diferente de Internet Explorer. En la receta voy a contaros qué hay que hacer para cambiar el “user-agent” de vuestro navegador y poder comprar así el billete pudiendo elegir asientos. ¡No vuelvas a penar sentado frente a frente con un desconocido!
He visto en varias páginas que ha nacido el primero dominio de primer nivel orientado el software libre :-) Es una iniciativa, parece ser, de Mozilla, para crear un dominio que identifique de alguna manera las webs relacionadas con el software libre.
Si, aunque parezca un título de broma estoy totalmente convencido de que Emacs es el mejor cliente de Twitter (al menos, libre y disponible en GNU/Linux). En esta receta explicaré como instalar Twittering Mode, un plugin para Emacs que nos permite enviar y recibir mensajes de esta famosa red social
Esta receta explicará a través de ejemplos mínimos como utilizar cookies para autenticarnos en una página y poder realizar sucesivas consultas con esa misma autenticación.
Si hace no muchos días nos sorprendías las declaraciones del presidente de Telefónica de querer cobrar a Google por el uso de sus redes, hoy otro abuelo cebolleta, al cuál ya conocemos de otras míticas intervenciones subvencionadas, ha soltado la subsiguiente perla (el titular es de “El País”, no mío):
Mercurial, como ya vimos en la receta «Mercurial, por favor» es un sistema de control de versiones distribuido y demás info que podéis encontrar en los enlaces. En esta receta quiero explicar algo sobre el uso un poco más avanzado: los llamados hooks
Como ayer pudiste ver en la receta Menús y barra de herramientas dinámicas en PyGTK es fácil crear estos menús y barras (incluso menús emergentes) usando UIManager, ÂctionGroup y Action s. En esta receta quiero mostrar como crear elementos diferentes a los vistos en aquella receta para nuestras Toolbar, Menubar y Popup.
Desde hace algunas versiones, GTK incorpora la capacidad para crear menús, barras de herramientas y menús desplegables (alias menú popup) a través de descripciones textuales similares a XML.
Pbuilder es un sistema de construcción automática de paquetes Debian. El principal objetivo de este sistema es poder generar paquetes Debian (o Ubuntu) sin “ensuciar” nuestro sistema con las dependencias de los paquetes que estemos generando.
Hoy, al configurar mi “layout” de escritorio en un PC con doble monitor, he descubierto algo desagradable: la configuración de paneles gráfica que proporciona Gnome (en su versión de Debian Sid) no permite seleccionar en que monitor aparece el panel. Esto hace imposible colocar paneles en el monitor secundario.
Puede que alguna vez necesites (o simplemente quieras) que el cursor que indica la posición de edición en Emacs se asemeje un poco más a lo que suele verse en el resto del sistema (una delgada línea vertical). Si lo necesitas, esta es tu receta :P
A falta de más información sobre el tema quiero felicitar desde aquí a David Castellanos porque con su proyecto eOPSOA ha conseguido ganar el primer premio a la innovación en el Concurso de Software Libre, cuya final se ha disputado entre el jueves y el viernes en Sevilla.
Ayer estuvimos Cleto y yo en Cuenca para la final del II Concurso de Software Libre de Castilla-la Mancha y hubo un buen resultado para usuarios de CRySoL:
Tanto Cleto Martín, con su proyecto “IcePick” como David Castellanos, de Albacete, con su proyecto “eOPSOA” tuvieron premio: Cleto el primer premio en innovación y David el primer premio de la Junta de Comunidades. (noticia en la web del CESLCAM)
Esta mini-receta sobre recordmydesktop (y sus front-ends) consiste en evitar que, al hacer un screencast, no podamos hacer Drag&Drop en cualquier ámbito del sistema.
Creo que es por todos conocido ya el caso de la web InfoPSP, cuyo webmaster ha sido condenado (según los medios de comunicación tradicionales) por pirata y mala gente.
Desde hace algunas versiones metacity incluye un compositing manager que viene desactivado por defecto. Este compositing manager sirve para cosas como tener transparencias reales o para añadir sombras a las ventanas.
Cuando tienes un dispositivo con pantalla táctil y quieres programar algo para él siempre puede ser de ayuda tener un método de entrada tan fácil como la propia pantalla del dispositivo. Si nuestro aparato tiene, como en el caso del Chumby, un Linux metido dentro y tienes forma de compilar software para él, Tslib es tu respuesta.
Todos estamos acostumbrados a utilizar en nuestros sistemas GNU particiones Extended3 (ext3). Sin embargo existen otras muchas alternativas. En esta receta voy a explicar cómo usar una muy interesante: XFS.
Si tienes una tarjeta gráfica de Nvidia y usas GNU normalmente usarás los drivers privativos y gratuitos para la misma. Como sabrás, hace falta compilar el módulo “nvidia” para cada nueva versión de kernel que instales. El problema ha surgido a partir de la versión del kernel linux 2.6.20, en el que se activó algo sobre la paravirtualización que hace que la compilación del módulo nvidia falle.
Como el otro día avisé, en la facultad ya se divisa la nueva red wifi de la Universidad. Su SSID es “eduroam” y para conectarnos desde GNU podemos seguir varios métodos.
Esta receta explica como obtener el plugin Guifications para Pidgin, que como bien sabéis es el nuevo nombre que usa nuestro viejo Gaim. Guifications dota a Pidgin de la funcionalidad de mostrar cuando nuestros contactos cambian de estado, entran, salen, escriben…. todo sea por tenerlos vigilados.
En esta receta os daré un repositorio de paquetes deb para que se pueda instalar Beryl utilizando APT. En un futuro próximo haré una receta de cómo compilar e instalar desde svn.
Introducción
En esta recete explicaré como instalar Beryl. Para quien no lo sepa Beryl es un sistema que convierte nuestros escritorios GNU en un maravilloso mundo en 3D. Para ver de los que hablo, en Youtube hay bastantes vídeos.
¿Qué se explica en esta receta? Solo como instalarlo, nada más. Ni obtener aceleración 3D ni nada. Solo como instalarlo y ya.
Configurar sources.list
Para poder instalar Beryl añadir está línea al archivo /etc/apt/sources.list
deb http://eleka2.dyndns.org/beryl/ binary/
Instalar los paquetes
Para instalar beryl solo hay que escribir esto como root:
apt-get install beryl emerald-themes
El paquete beryl instalará todas sus dependencias y el paquete emerald-themes temas para el gestor de ventanas Emerald. El resto se instalará solo.
Arrancar Beryl
Hay dos formas: ejecutar de algún modo Beryl-Manager o arrancar desde Aplicaciones -> Herramientas del sistema -> Beryl-Manager. Aquí también tenemos programas de configuración, como Beryl Settings.
Para cambiar el tema de Emerald (los bordes y botones de las ventanas), en escritorio -> Preferencias -> Emerald Theme Manager.
Pues eso, que en la página de plugin buscadores de Mozilla he añadido un buscador para añadir en la barra de buscadores de Firefox.
¡Espero que sea útil!
Mozilla-Firefox tiene un gran conjunto de extensiones y plugins para gran variedad de cosas. Entre ellos están los plugins de búsqueda. Aquí explico como añadir nuevos buscadores (aunque sea trivial) y sobre todo, como eliminar los que añadas o los que vienen por defecto y que no puedes borrar de forma tan trivial.
Pues eso, lo leí anoche en los foros de Ubuntu ... parece que la próxima versión, la Dapper Drake (o Dragón Perezoso), será la 6.06, rompiéndose la rutina de Ubuntu de sacar cada 6 meses una nueva versión "estable".
Hola a todos.
Aunque en la encuesta ganó que la "mini-party" se haría esta tarde, no va a ser posible, ya que no había suficientes talleres preparados, así que la posponemos hasta nuevo aviso ... pero no se olvida, serán solo una o dos semanas de retraso.
¡Siento las molestías!
¿Qué tal estaría (y qué tal os vendría a todos?) hacer una mini-party de esas que se hablaron por Crysol para después de examenes? Con alguna receta en particular como "tema estrella" a decidir y tal, es solo una idea ...
Leo en BandaAncha.st que Microchof se ha lanzado a desarrollar unos móviles para el tercer mundo, que no digan que solo les ayuda la ONU ... digo yo que será por eso:
Microsoft desarrollará un movil con conexion a Internet para los paises del tercer mundo.
Al parecer el aparato sera convertible en ordenador, y nace como respuesta a la campaña de "Portatiles por 100$" que NAciones Unidas, en colaboracion con empresas de software libre ha puesto en marcha hace algun tiempo.
Aunque realmente el copyleft tenga, en teoría, poco o nada que ver con el software libre, bien es verdad que defiende la cultura libre de la que tantas veces ehmos hablado aquí, en la lista, y por suerte con David Bravo cuando nos visitó hace un par de meses en la ESI ... pero vean y disfrutend e este artículo que encontré en Banddaancha.st. El títular, sin desperdicio:
Hola a todos ...
Tengo yo una duda: en los repos oficiales de Debian hay varios "sabores", sarge, sid, etch, unstable, stable, testing ... pero yo quieros aber, ¿qué diferencias hay entre sarga-stable, o sid-unstable o etch-testing? ¿No deben ser lo mismo? ¿Por qué no lo son?
I wan't to know :)
Buen sábado a todos.
Escribo para preguntar como poner en Debian Sarge el plugin de Flash para el Firefox ... la cosa está en que, sin intsalar nada, puedo ver las animaciones flash, pero no se me oyen ni para atrás ...
¿Algún método contrastado? googleando solo he encontrado cosas muy sueltas que nome han resuelto gran cosa
Hola a todos
Quería hacer una pequeña "crítica" (cosntructuva, por supuesto) a la web de Crysol ... ¿por qué cuando te "logeas" para poder escribir o responder, desaparece la opción de búsqueda?
Supongo que será un descuido, así que si puede ser colocar el botón de búsqueda en algún lugar de la web para los users registrados, mejor ;)
¡Saludos!
Esta receta pretendo explicar como instalar ndiswrapper para poder utilizar una tarjeta de red inalámbrica en GNU/Linux que, o bien no esté soportada nativamente, o bien no funcione como debería con el soporte nativo
Hola amiguetes, como diría aquel otro
Os iba yo a preguntar, ya que le pregunté a Cleto y su respuesta no me ha funcionado ... ¿algún servidor así potente de rdp o algo similar para poder manejar una máquina conectada vía wifi desde otro PC en local?
Me refiero a algo en plan gráfico, para aprovechar la velocidad de la conexión, y no un simple ssh, que ya conseguí hacerlo funcionar
El próximo día 22 de Febrero se celebrará en la ESI una Debian Install Party.
La party está abierta a todo el mundo y puede venir quien quiera. El horario será de 16:00 - 21:00h, pero no será nada intensivo, más bien relajado y entre amigos.
Si deseas asistir, envía un e-mail a la siguiente dirección: josel.sanroma(arroba)alu.uclm.es para pre-inscribirte, indicando el hardware que tiene el ordenador que vas a llevar. Si tienes una LiveCD, puedes enviar también la salida del comando "lspci". Además si traes un ordenador sin CD, indica si dispones de arranque por red o por USB (puedes encontrar esta información en el manual de instrucciones de tu motherboard o en la BIOS). Necesitamos todo esto para estar preparados ante posibles imprevistos.
La pre-inscripción no obliga a nada, simplemente es para tener un número aproximado de participantes.
Algunas cosas a tener en cuenta:
Lleva el disco duro particionado, necesitas como mínimo unos 20GB de espacio libre y particionado, es decir, una partición con al menos 20GB de espacio libre. En ese espacio se realizarán las particiones necesarias.Si no sabes como hacerlo avísanos antes para que te ayudemos porque en la party no habrá tiempo.
El horario será de 16:00h a 21:00h (Aula aún por confirmar). Estaremos allí a las 15:30h para que los asistentes puedan montar su puesto y estemos todos listos para empezar a las 16:00h. Se ruega puntualidad.
Puedes traer ordenador portátil o de sobremesa, pero no podemos asegurar que tengamos monitor, así que trae el tuyo propio en este caso.
Se realizarán diferentes talleres (Filosofía del Software Libre, Makefiles, conectividad SSH, herramientas colaborativas como repositorios, emacs, videojuegos libres, astronomía, instalación de entorno de desarrollo para Nintendo DS, etc) aún por decidir.
[This is a clone of this post just for avoid it may be lost. All attribution is to its author (Mike)]
I’ve seen the python pty trick in a few places, first when taking OSCP labs. However, if you’ve noticed there’s still some problems. 2 years ago at HackFest @r00k did a presentation where he improved the quality of the shell dramatically. Last year at HackFest, @jeffmcjunkin posted further improvements. All credit goes to them, and the excerpt below comes directly from Jeff McJunkin’s SEC560 notes.
Cuando queremos transmitir datos entre dos máquinas, almacenar la configuración o guardar datos para un uso posterior, tenemos que decidir el formato del archivo que estamos usando.
En algunos casos la decisión pasa por un archivo binario, lo cual puede estar bien en muchos casos. En otros puede ser un gran error, ya que siempre es mejor utilizar formatos existentes. Estos formatos suelen proporcionarnos librerías con el fin de facilitarnos la creación y/o el uso de los archivos.
Tal día como hoy, pero hace ya 5 años, empezaba a funcionar la web de CRySoL (no me atrevo a llamar web a lo que había antes).
En este tiempo "la comunidad" de CRySoL ha sufrido sus altibajos, pero a pesar de todo y gracias al esfuerzo de unos pocos (menos de lo que nos gustaría) seguimos aquí, al pie del cañon. Prueba de ello son los millones de visitas (que no contamos), los más de 1000 posts públicos y 498 recetas (hubiera estado bien llegar a las 500 :-P).
Esta receta es una copia (gracias a su licencia CC) de un post del blog de Vicente Navarro (un blog con un contenido estupendo por cierto). La pongo aquí porque me parece un material muy bueno y en previsión de que (FSM no lo quiera) dicho blog desaparezca repentinamente.
Desde la UCLM y el Centro de Excelencia de Software Libre de Castilla-La Mancha (CESLCAM) se está organizando la Fase Final del I Concurso Universitario de Software Libre de Castilla-La Mancha que tendrá lugar el próximo 17 de abril en la Escuela Superior de Informática de Ciudad Real.
Junto a la entrega de premios, se van a realizar charlas y diversos talleres relacionados con el software libre.
Esta receta pretende recoger una colección sobre pequeños ‘trucos’ de GTK que siempre viene bien tener a mano.
GtkkTreeview
Desactivar los elementos seleccionados: parece intuitivo, pero la primera vez que lo buscas, te vuelves loco. Se debe hacer con un objeto GtkTreeSelection, usando el método unselect_all().
Iconos de stock en IconView: resulta que el IconView es un widget un tanto especial, hasta la fecha. Es muy restrictivo en cuando al modelo que le puedes especificar y no permite usar cell_func para renderizar nuestros datos. Además, los iconos deben ser obligatoriamente pixbuf. Por tanto, si lo que tenemos es los nombres de stock de los iconos, debemos convertirlos a pixbuf antes de meterlos en el store del iconview. Para eso, podemos usar el método render_icon de gtk.Widget. Necesita como mínimo dos parámetros, el stock y el tamaño, y retorna un pixbuf listo para meter en el modelo.
Ejemplo
iv = gtk.IconView()
st = gtk.ListStore(str, gtk.gdk.Pixbuf)
icon = iv.render_icon(“gtk-file”, gtk.ICON_SIZE_BUTTON)
st.append([“un fichero”, icon])
GtkTreeStore, GtkListStore
Crear el modelo con tuplas o listas: quizá en este caso, lo obvio sería utilizar el tipo tuple o list, pero si lo haces, Gtk te responde con un bonito:
TypeError: could not get typecode from object
Así, lo más sencillo es utilizar object de Python, que se acoge a lo que le des :-).
Ejemplo
t = gtk.ListStore(str, object)
t.append([“nums”, (1,2,3,4,5,6,7,8,9,0)])
Nuevos widgets
PyGtk: Generalmente, hacer un nuevo widget en PyGtk es muy sencillo. Basta con crear una nueva clase que herede de otro widget y llamar al ‘inicializador’ adecuado, es decir, en nuestro init llamamos a Gtk.WidgetDelQueHeredamos.init(self) y listo.
Ejemplo
class MyTreeStore(gtk.TreeStore):
def init(self):
gtk.TreeStore.init(self)
Tamaño de un widget
Obtener el tamaño de un widget y su posición: para conseguir esto, el widget ha de estar realized, es decir, ha de haberse llamado a las primitivas para construirlo antes de pintarlo. Si el widget es visible, esto ya ha ocurrido. Si no, es posible utilizar el método realize() para forzarlo. Una vez hecho esto, el objeto tiene su tamaño y sus coordenadas en el atributo allocation, que es un gdk.Rectangle.
Ejemplo
# Tomado de http://faq.pygtk.org/index.py?req=show&file=faq05.009.htp
win=gtk.Window()win.realize()# o win.show()
rect=win.allocation
Gtk.Events
Mejorar el rendimiento: supongamos que tenemos un callback conectado al evento “motion_notify_event”, y que en ese callback dibujamos algo (por ejemplo, usando Cairo). Si el método tarda en dibujar, se encolarán un montón de eventos sin procesar, que se despacharán después de que el usuario haya empezado la sucesión de eventos. Esto provoca, por ejemplo, que al desplazar un elemento, este se mueva siempre por detrás de donde está el ratón, dando una desagradable sensación. Para evitar eso, podemos bloquear la emisión del evento, hasta que se pueda procesar.
Ejemplo
# Callback del evento 'motion_notify_event'
defon_motion_notify_event(self,widget,event):widget.handler_block_by_func(self.on_motion_notify_event)# Your code goes here
def_unblock():widget.handler_unblock_by_func(self.on_motion_notify_event)gobject.idle_add(_unblock)returnTrue
Cairo
Redibujar sólo lo necesario: puesto que el evento expose se produce muchas veces, es interesante poder repintar sólo las zonas necesarias. Para ello, usamos clip(), que crea una zona de dibujo, enmascarando los cambios producidos fuera de esta zona.
Ejemplo
ctx es el contexto de dibujo de Cairo
ctx.rectangle(event.area.x, event.area.y, event.area.width, event.area.height)
ctx.clip()
Crear una ventana transparente: para poder probar esto, es necesario tener habilitado el compositing en el gestor de ventanas. El truco básicamente consiste en crear una ventana sin decoraciones, y con el colormap adecuado (uno que soporte canales alpha), y pintar sobre ella con cairo.
Cargar gdk.Pixbuf desde un buffer: a veces es útil poder renderizar un pixbuf desde datos de un streaming, o desde un socket, en lugar de usar las fuentes comunes de imágenes de gtk (ficheros, stock, etc.). Para ello, es posible usar gdk.PixbufLoader, que nos permite escribir los datos poco a poco, y cuando están todos disponibles, obtener el Pixbuf.
Cargar un gdk.Pixbuf desde stock: aunque esto ya lo hemos visto más arriba, formaba parte de otro ejemplo. Aquí lo vemos más claro. Tenemos un Stock ID, y queremos cargar un gdk.Pixbuf a partir de él. Es fácil si usamos gtk.Widget.render_icon(). Te retorna el Pixbuf directamente.
En nombre de la Escuela Superior de Informática y de Sun Microsystems Ibérica, tengo el gusto de invitar a todos los incondicionales de CRySoL a una jornada técnica sobre sus tecnologías OpenSource (Software Libre para nosotros)
Lugar: Sala Polivalente (planta baja) de la Escuela Superior de Informática
Fecha: 23 de Enero de 2008
Programa:
(12:00-12:50) OpenSolaris
(12:50-13:50) OpenSPARC
(13:50-14:00) Presentación de los Programas formativos gratuitos de Sun
El próximo día 25 de Enero de 2008 se celebrará en la Escuela Superior de Informática de Ciudad Real una Jornada Técnica sobre Software Libre en torno a la presentación de la nueva Molinux 3.2 “Hidalgo”. No olvides inscribirte
Si tenéis un router “La Fonera”, con versión del firmware 0.7.1 r2, esto te interesa. Hasta esta versión era muy sencillo acceder al shell por diferentes maneras, pero los de Fon se lo han currado y en la revisión 2 han cerrado muchos agujeros.
Cómo configurar «a mano», es decir, sin DHCP, los parámetros más importantes de una tarjeta de red en Debian GNU/Linux, Ubuntu o similar.
Hay otras posibilidades (como etherconf) pero la finalidad de esta receta es utilizar los comandos básicos disponibles en los sistemas GNU/Linux, en concreto con ipconfig y route del paquete net-tools.
Ahora que los exámenes han terminado he tenido tiempo para plantearme muchos interrogantes. Entre los más mundanos se encuentra el de qué hacer con mi viejo PII(mmx :-P)a 333Mhz, 128MB de RAM y 3,2GB de disco.
La fundación del Conocimiento Libre, en sus primeras jornadas, propone una serie de talleres y conferencias centradas en la reflexión del concepto libre en diferentes ámbitos, de la programación del arte.
En la web del periódico El país
Podeis encontrar una noticia que igual os interesa, y empieza así:
Erase que se era un señor llamado Bill Gates... y cito textualmente: "Microsoft acata una de las exigencias de la UE y facilita parte de su código".
Buenas, lo que me ha pasado ahora es que he tenido que reinstalar windows en mi portatil, por motivos que no vienen al caso, la cuestión es que he perdido el gestor de arranque. Lo mejor de todo es que ya me había pasado antes e instalé un GAG que encontré en internet. Ahora quiero recuperar el GRUB, sé que se puede hacer con el live CD pero, no sé como, a ver quién me echa una mano, gracias.
Alguien me puede decir como puedo configurar la wifi de la universidad, tengo todos los datos de la conexion y no tengo problemas con la tarjeta wireless, solo que tampoco está configurada. Gracias por adelantado.
Cómo desactivar el touchpad mientras estás escribiendo, evitando así taps involuntarios.
Antes de nada...
Lo primero que tienes que hacer es asegurarte que tu touchpad es synaptics. Si es así, lo siguiente es comprobar que tienes instalado el módulo xserver-xorg-input-synaptics. Si no lo tienes, ¿a qué estas esperando?
Manos a la obra!
Una vez que has instalado el módulo, tendrás el comando syndaemon disponible, el cual monitorizará tu teclado y desactivará tu touchpad cada vez que escribas. Puedes probar su comportamiento introduciendo lo siguiente en una terminal:
$syndaemon -i 1 -d
Con -i 1 le estás diciendo a syndaemon que quieres que tarde 1 segundo en volver a habilitar tu touchpad desde que presionas la última tecla de tu teclado.
Con -d le dices que quieres que se ejecute como demonio del sistema.
Ahora sólo falta que agregues ese comando a tu lista de programas al inicio del gestor de sesiones de Gnome.
Si no usas Gnome, puedes agregar el siguiente script en tu directorio de scripts de inicio:
#!/bin/bash
syndaemon -i 1 -d
Con esto puedes decir adiós a esos molestos taps involuntarios ;)
Hola a tod@ vosotr@s. Esto va dirigido sobre todo a quienes están en su ultimo curso de carrera, o tiene alguna aspiración de ser "Profesor de Informática":
Animo chicos con la party.
Soy un antiguo alumno, de informática de gestion.
Mola ver como os moveis.
Animo de quijote
Si yo pudiera, instalaria y probaría molinux a fondo.
Creo que en inalambricas habría que meter algun .deb mas para que lo configurara antes.
Suerte.
Hola!, he visto en la página de UCLM que hay un curso propio llamado Máster en Tecnologías de la Información y las Comunicaciones (MTIC), y me preguntaba si alguno de vosotros lo conoceis o lo habeis hecho. Por lo que pone en la web, hay una especialidad en Software Libre y sus Aplicaciones. Me podría alguien decir como es este curso y si merece la pena hacerlo. Muchas gracias por todo.
Lo dicho, hoy he visto como el procesador de textos OpenOffice Writer gana al famaso Word, y aún encima con el propio formato .doc. Les cuesto la historia, una compañera tenia un fichero .doc que quería imprimir y para ello lo habre con word. Antes de imprimirlo, examina el fichero y comprueba que todo esta bien. Pues bien, a la hora de imprimirlo se da cuenta de que el texto no salía justificado, sino alienado a la izquierda, algo muy extraño porque en la pantalla se veia el texto justificado.
Hola, al terminar la party quijote 2006 me ha entrado la curiosidad para saber como se monta un hub de direct connect. Se que es sencillo porque me lo han comentado, pero no he encontrado nada, así que he pensado que poniéndolo aquí quizá alguien supiera del tema o me remitiera a algo o alguien que lo sepa. El caso es que me gustaría poner un pequeño servidor en mi residencia del año que viene para compartir por lan. Un saludo y gracias!
Otra más, y van..., esto ya es un cachondeo. Yo no sé a dónde van a llegar. Microsoft ha pagado a google por poner un enlace patrocinado con la palabra "linux". Meteros en el google(.es) y lo veréis.
Esta pequeña pequeñísima receta trata sobre cómo hacer un script para escuchar las radios que más nos gusten por internet sin tener que estar mirando cual era la dirección .asx que tenía tal radio.
ImageMagick es una colección de herramientas y librerías para leer, escribir y manipular una imagen en diversos formatos. Las operaciones de pocesamiento de imágenes están disponibles en línea de comandos. Se pueden redimensionar, cambiar su resolución, rotar, añadir texto, añadir efectos artísticos, etc…, lo que quieras.
Instalación de imageMagick
Yo cuando lo descubrí ya lo tenía instalado, pero de todas formas está en los repositorios, es tan fácil como:
Para rotar hacia la derecha indica el número de grados como un número positivo. Si quieres rotar hacia la izquierda indica el número de grados como un número negativo.
Así rotaríamos 90 grados a la derecha:
$convert -rotate 90 input.jpg output.jpg
Añadir texto a una imagen
Opciones:
fill white rellena las letras de color blan en lugar del negro por defecto
pointsize especifica el tamaño de letra
draw ‘text 10,50 " … "’ Dibuja el texto entre las comillas dobles en la posición 10,50
$convert -font helvetica -fill white -pointsize 36 -draw'text 10,50 "Dia de campo..." imagen.jpg imagencomentada.jpg
Y mucho más
Hay muchos más comandos para hacer efectos artísticos, como por ejemplo “spread” para indicar en qué medida se va a esparcir una imagen; “solarize” para indicar un grado de solarizado; etc, etc, etc, …
Luego seguiré con esta receta, añadiendo bien añadido cómo se hacen los efectos artísticos, cómo se hace un script para hacer lo que quieras con todas las imágenes de un directorio, etc…Pero ahora mismo no puedo ;) Si alguien se anima…
Bueno, esto no sabía si ponerlo como receta o como noticia o como qué, además, no lo he hecho yo, lo he visto en los foros de ubuntu y me ha parecido interesante ponerlo aquí.
Navegación anónima mediante Tor y Privoxy
Comento lo que he leído aquí
Microsoft ha conseguido patentar el sistema de archivos FAT, con lo que dispositivos que usan este formato (como algunos mp3…) van a ver encarecido su precio.
Linux también tiene un módulo para este sistema de archivos.
De momento la patente sólo vale para USA, pero ya se sabe…
Otra victoria más de Bily Puertas
LO siento si me repito, pero es que ES IMPOSIBLE INSTALAR GNU/LINUX EN UN ACER.
Si alguien se atreve el lunes le damos el portátil, nos instala ubuntu, y después se viene al alcázar y le invitamos a las cañas que quiera (que ya están a 1.20 €, que robo, con lo pequeño que es el vaso).
Pues eso, lo dicho.
Para más información mirar la lista de correo :)
Hola, tenía yo una curiosidad:
Papá Noël me ha traído un nokia de estos que lleva mp3 y todo, en concreto el 6630. Lleva el SO Symbian 8.0 (o el 7.0, no sé ahora mismo).
¿Se le podría poner Linux o es imposible?. Era sólo por saberlo, porque creo que hasta te quitan la garantía si haces eso.
Pues eso, para estar escuchando algo mientras estás...estudiando/trabajando.
Si lo quieres sin entorno gráfico (el de mplayer) escribe esto en la consola:
Escribo esto porque al parecer en la nueva Ubuntu 5.10 hay un error de pmount. Por lo que se ve no le sucede a todo el mundo (a mi si) pero si ocurre no deja montar la disquetera y te dice : el UDI introducido no es un volumen montable.
Pues eso, que un 10 para todos los que organizaron la Install Party. Estas cosas habría que hacerlas más de vez en cuando, pero claro, se que es una movida para los que le toca organizar todo.
En esta pequeña receta veremos como hacer paquetes .deb a partir de .rpm y .tar.gz , ya que es mucho más fácil, cómoda y limpia su instalación (con dpkg). Para mucha gente será algo trivial, pero creo que a gente como yo le puede venir bien :)
Hola, quería saber como generar paquetes debian a partir de tar.gz.
En la Espiral hay una receta pero no encuentro el paquete debuild que indica al principio. He encontrado en su lugar el paquete pbuilder pero no se usarlo :(
En la espiral pone que hace falta el paquete "debuild" y es el "dh_make".
El resto del proceso es como indica en la receta
Algunos de vosotros recordaréis los problemas que tuve con DELL. Yo argumentaba que me habían reparado hardware defectuoso con otro peor aun. Pues nada, el New York Times tira de la manta.
http://www.nytimes.com/2010/06/29/technology/29dell.html?adxnnl=1&ref=technology&pagewanted=1&adxnnlx=1277895878-r4fZqd8kAqvHWMEtVhwlCA
Gente sensata: no compen nada a DELL, espero que la empresa vaya a la bancarrota y puesto que los empleados fueron cómplices no sentiría ningún remordimiento si se quedan sin trabajo. A mi me dejaron sin ordenador y me dieron un presupuesto de reparación de más de 800 euros por una placa base... ahora TODO tiene sentido.
Hola a todos,
he colgado mis progresos de una intrillo para CRySoL aquí:
http://www.brue.org/2008/08/12/crysol-intro-linux-x86/
me faltan algunas cosas y estoy haciendo un pequeño sinte que quepa en los 4k finales.
Un saludo desde Lituania.
Adjunto el PPD de dicha impresora, ya que es un poco c*ñazo encontrarlo y ponerlo todo junto.
Como información, cuesta 170 euros y es duplex. Lo poco que he probado ha sido más que satisfactorio. Muy rápida en la primera copia, y muy rápida para imágenes.
Hola a todos, en respuesta a Int-0, que hace poco nos dejó un pequeño tuto sobre intros multimedia (en concreto para la PSP), he hecho una pequeña intrillo.
Yo, personalmente, brue, si hace falta doy mis datos de forma privada a quien los quiera, pienso que Linus Tolvards es tonto. Creo que se cree el rey del software libre cuando es un "cantamañanas". Espero que la gente despierte pronto y que se pase la "linuxmanía" porque, con perdón, "manda huevos" que clase de incultura de masas sigue a un tipo como este. Este personajillo, que no le hace ninguna gracia por lo que sé al señor Stallman (que es alguien que si tiene voz y voto en esto de GNU), hizo un comentario del tipo siguiente:
Si usas el .emacs para definir algunos aspectos de Emacs le obligas a usar el intérprete de lisp. Algunas cosas, como las propiedades de las fuentes, colores, barras … se pueden modificar en el .Xresources , lo que consigue que el arranque de Emacs sea más rápido
Ingredientes
Emacs y X11
.Xresources
El archivo .Xresources contiene información acerca de algunos parámetros de ejecución de aplicaciones en X11.
Este tutorial es extensible a otras aplicaciones… pero pongo un ejemplo para Emacs…
Emacs.toolBar: off
Emacs.font: -misc-fixed-medium-r-semicondensed-*-*-120-*-*-c-*-iso8859-15
Emacs.menuBar: off
Emacs.background: black
Emacs.foreground: white
Es el ejemplito del que yo uso, y creo que se explica por si mismo.
Una vez modificado el .Xresources (en tu $HOME ) debes invocar el siguiente comando:
$xrdb .Xresources
La próxima vez que cargues Emacs, verás la diferencia de usar esta forma de configuración vs. .emacs
Otros ejemplos
Aquí os dejo otros ejemplos de un .Xresources
XTerm*background: black
XTerm*foreground: white
aterm*transparent: true
aterm*scrollBar: false
aterm*shading: 60
*font: -misc-fixed-medium-r-semicondensed-*-*-120-*-*-c-*-iso8859-15
*boldFont: -misc-fixed-bold-r-semicondensed-*-*-120-*-*-c-*-iso8859-15
Proyecto de un juego libre programado un python en el que puedes competir contra ti mismo o contra un compañero, pudiendo tocar una guitarra o una batería.
Hola chicos y chicas…
He hablado con David y he decidido que voy a empezar con esto en breve. Espero que se una toda la gente posible cuanto antes. Creo que David a lo mejor puede hacer una parte importante si el tiempo se lo permite.
El proyecto consiste en un juego arcade donde un jugador puede controlar una guitarra al estilo del FoF y otro una batería. Una vez conseguida la meta principal, se podrán aumentar los instrumentos y las posibilidades.
El primer hito a conseguir es el siguiente, los demás hitos se discutirán cuando se termine este:
(1) Tener un programa en python, modular y extensible, que dado un ogg y un archivo de texto o XML con un formato determinado, reproduzca un sonido al pulsar una tecla (o botón de un pad), un sonido distinto por cada una de las 5 posibles teclas, y que diga si se ha pulsado en el momento correcto según el archivo asociado.
(2) Tener un editor de dichos archivos dado un determinado OGG.
El archivo asociado debería contener la siguiente información:
MD5 y nombre del OGG al que pertenece
Tecla a pulsar (pueden ser varias en un mismo instante)
Momento en el que se pulsa
Tiempo durante el que se pulsa
Modificadores de nota (pulsar por ejemplo otro botón para hacer un bend de guitarra o redoble de charles)
(opcional) Letras de la canción
Se usará para reproducir el audio gstreamer, dejando la opción de incluir pads nuevos en cualquier punto desde la fuente de cada uno de los sonidos, hasta el destino final (alsa, oss, jack… de eso se encarga gstreamer también).
¿Cuánto tiempo nos ponemos para esto?
Unos cuantos números podrían ser:
Disparar sonidos con el teclado: 5 horas
Reproducir un ogg: 1 hora
Leer el formato del archivo asociado: 2 horas
Comprobar si hay una tecla pulsada en el momento correcto: 10 horas
Hay que tener un cuenta de que no se pueden dejar las teclas pulsadas siempre y que el programa crea que lo haces bien… aunque en la primera aproximación, podría ser válido.
Editar el archivo asociado:
Reproducir una parte espećifica del ogg: 5 horas
Diseño GUI: 30 horas
6 checkboxes para cada momento editable
edit o barra con el tiempo asociado a cada checkbox
barra asociada al tiempo (desplazable)
play/stop
play for x seconds
avanzar/retroceder un bpm/resolución beat
Comentarios por favor. El que no quiera currar que no critique, que no vamos a cobrar un duro por el tiempo empleado.
Os dejo aquí una preview de un temilla que estoy haciendo. Este hecho con hydrogen y samples libres. Esto es, no se ha usado nada de software privativo, excepto libmp3lame para comprimir a mp3.
No pensaba publicar esto por si se usaba en Gnesis (por eso de la sorpresa y tal), pero me he enterado que el arte de Gnesis está en buenas manos y que nos sorprenderán con algo muy original :) Quizá este tema se adjunte como alternativo. Espero que os guste!
Aquí podeís ver un wallpaper inspirado por la alegría de la próxima gnesis. blender + gimp + freesans bold.
http://www.brue.org/?q=node/27
La versión de 1280x1024 está aquí
Espero que os guste.
Increble sentencia que hace que M$ tenga que pagar 1.5 billones de dólares a Alcatel por licenciar la reproducción de mp3. Todos creíamos que la patente del mp3 la tenía "Fraunhofer-Gesellschaft", pues M$ también ... ale ... quien a hierro mata, a hierro termina.
Leedlo aquí
En el repo de Mesa hay un bug temporal. El que quiera compilar en debian, tras enfrentarse con los apt-get’s pertinentes de desarrollo (importante x11proto*, libnurbs, libxmu, libxi, libmesa…etc -dev), tendrá que definir la contante DRM_VBLANK_SECONDARY en algún sitio visible para vblank.c.
Por si alguien está interesado en la edición de video y no lo conoce ...
http://lives.sourceforge.net/index.php?do=license
Yo cuando lo pruebe puedo hacer un review si alguien está interesado.
Un saludo,
Sergio.
Da gusto esto... os escribo desde la versión final robada del windows vista, desde casa de uno de esos piratas.
Están de enhorabuena los trolls porque os puedo asegurar que XGL + Beryl, se come a Vista completamente.
La verdad...
Hola chicos, cómo estáis, os quiero un montón y no estoy borracho! ;)
No es ninguna locura. Podríamos movernos un poco y traer a Stallman a la ESI. Hace tiempo Paco me dijo que no era una idea rara y que Stallman, mientras tuviera X cosas mínimas, vendría encantado.
Beber agua embotellada es bueno, pero imaginad lo que sería beber del manantial de donde la cogen para embotellar!!
A ver, ¿cómo se formaliza esta propuesta y a quién tiene que llegar?
Que ilusión poder tocar a Ricardo SAltohombre!!
Muy buenas!!
Me gustaria que he ayudaseis a encontrar informacion, en español si puede ser, de MONO y todo lo relacionado con .NET para Linux.
Muchas gracias!!!!
si dejas las contraseñas en el equipo, la página iniciará sesión automáticamente y algún desarmado podría cambiarte la clave o hablar por ti en los foros y se puede liar parda. Ten cuidado!!
Saludos,
Ritxi
Si desarrollas con Eclipse aplicaciones para Android, y no tienes una máquina muy potente, te habrás dado cuenta de que usar el emulador y Eclipse al mismo tiempo, puede ser un problema. ¿Tienes una segunda máquina a tu disposición? Esta es tu receta entonces.
El algoritmo RC4 se usa para codificar información usando una clave. Es muy sencillo, aunque no es de los más seguros. Sin embargo, para muchas ocasiones es suficiente. Hay implementaciones disponibles en C, C++, C#, Python o incluso JavaScript. Sin embargo, no encontré nada en AWK. Si el sistema es reducido (por ejemplo, una Fonera o un RouterStation), es posible que no quieras instalarte la toolchain para C o no puedas usar un intérprete de Python.
En esta receta veremos cómo hacer un script «hook» que impide a los usuarios puedan subir ficheros que no cumplan los criterios que decidamos. En concreto, vamos a evitar que puedan subir ficheros binarios al repositorio.
Veamos como instalar el driver que da soporte a los dispositivos que utilizan los chipsets de la familia stk11xx, de Syntek Semicon, en concreto, para el EasyCAP USB.
Añadir nueva funcionalidad a ZeroC Ice es fácil: usando plugins. Ice provee una interfaz local, Ice::Plugin, que podemos usar para crearlos. Veamos un ejemplo sencillo. Probado en Ice 3.3.
El objetivo es simple, pero útil. Tenemos un repositorio de mercurial (hg), al que accedemos por SSH. Queremos compartirlo con el mundo, pero no queremos abrirle cuanta ssh al mundo en nuestro servidor. ¿Solución? Compartirlo por HTTP.
Se pretende construir un entorno de desarrollo para crear aplicaciones en diferentes lenguajes (c/c++ y flash mayormente) para el Chumby
Ingredientes
Una máquina con Debian (preferiblemente SID), actualizada
Un Chumby
Las aplicaciones pertinentes en cada sección
Al tema
Existen varias formas de crear un entorno de desarrollo para nuestra plataforma (ARM). Algunas ensucian más el sistema que otras. Por ejemplo, en el wiki de Chumby, te explican que debes bajarte un paquetito (bastante grande, por cierto), y descomprimirlo en /. Esto mete en /usr todo lo necesario, pero no te da nada de control sobre lo que ha pasado. Si tienes que volver al estado anterior, tendrás que hacerlo a mano.
La opción que me he planteado, además de ser más divertida e instructiva, te permite tener más flexibilidad y control sobre todo lo que usas para el Chumby: hacer una jaula (un entorno chroot que lo llaman) donde poner todo lo que necesites.
Creando la jaula
Para hacer el entorno chroot, he seguido la receta de javieralso, con algunas modificaciones (pero no muchas, porque esto es muy sencillo). Básicamente lo que hay que hacer es buscarse una carpeta donde hacer el despliegue (os aconsejo no poner espacios en el nombre, o quizá tengáis problemas):
user@box:~$mkdir chumby
Y ahora, si no tienes instalado cdebootstrap , ¿a que esperas? ;-) Ya sabes, puedes usar apt* para instalarlo de la forma usual. Si tienes dudas, pregunta.
Lo siguiente es el despliegue, que consiste en instalar un sistema Debian básico para ir tirando… :P
Si tienes dudas sobre qué hace este último comando, mírate la receta de javieralso. Una vez que haya terminado, que tardará un ratejo (cosa normal, teniendo en cuenta que, salvo algunos detalles, es una instalación de Debian completamente funcional), lo siguiente antes de continuar es arreglar un par de cosillas pendientes. Para ello, entramos en la jaula:
user@box:~$sudo chroot chumby
root@box:/#
Eres root, así que ten cuidado con lo que haces ;-) Lo primero de todo es instalar algunos paquetes que son vitales para la vida: emacs, bash-completion, locales…
Si te quieres librar del problema de las locales (en caso de que te aparezca), pues simplemente con un reconfigure (‘dpkg-reconfigure locales’) y seleccionando ES_UTF-8 como el predeterminado del sistema (o el que quieras) debe bastar.
Luego, ya que no hay usuarios, puedes crear en /home carpetas con los usuarios del sistema no-chroot que van a usar la jaula, y añadir los scripts de inicio que creas convenientes, alias, prompts, etc.:
alias ls='ls --color'
alias clean='rm *~ \#*\#-rfv'
alias emacs='emacs -nw'
. /etc/bash_completion
PS1='\[\033[01;29m\]CHROOT@Chumby\[\033[00m\]:\[\033[01;34m\]\W\[\033[00m\]\$'
#Mount /proc filesystem
if [ ! -f /proc/cpuinfo ]; then mount -t proc none /proc
fi;#Go to home... :-p
cd
Con un bonito ‘prompt’ para distinguir cuando estas dentro del chroot y cuando no. Ten cuidado al cortar y pegar, pues puede que a bash no le gusten las comillas de tu navegador… :-p Otro detalle de la jaula es que hay ciertos sistemas de ficheros que no te monta automáticamente, por ejemplo /proc y /dev. Si necesitas montarlos, sigue la receta de javieralso, aunque algunos, como /proc y /sys se pueden montar desde la jaula.
El proc es casi imprescindible, así que puedes montarlo de la siguiente forma:
Nota: como puedes ver, he añadido una linea en el .bashrc para que se monte cuando inicies sesión. Así no te tienes que preocupar de estos menesteres.
<b>CHROOT@Chumby</b>:/# mount -t proc none /proc
La GNU Toolchain para ARM
Existen mil formas de instalarla. Desde la web de Chumby te aconsejan que te bajes un paquete comprimido con todo ya compilado y lo descomprimas en /, lo que meterá en /usr todo lo necesario, pero que te dejará el sistema hecho unos zorros. Si lo haces en una jaula, no es tanto el daño. Así que, bájate el fichero (unos 120 MiB), y lo descomprimes en la carpeta raíz:
<b>CHROOT@Chumby</b>:~# cd /
<b>CHROOT@Chumby</b>:/# wget -c http://files.chumby.com/toolchain/arm-linux-v4.1.2b.tar.gz
...
<b>CHROOT@Chumby</b>:/# tar zxvf arm-linux-v4.1.2b.tar.gz
</pre>
¡Y ya está! Lo podemos probar con un ejemplo muy sencillo en C++, el típico, conocido y sufrido Hello world:
<b>CHROOT@Chumby</b>:samples# arm-linux-g++ test.cpp -otest<b>CHROOT@Chumby</b>:samples# lstest test.cpp
<b>CHROOT@Chumby</b>:samples# file testtest: ELF 32-bit LSB executable, ARM, version 1, dynamically linked (uses shared libs), for GNU/Linux 2.6.0, not stripped
<b>CHROOT@Chumby</b>:samples#
Para ejecutarlo, hay que meterlo en el Chumby. Más abajo explico cómo montar una partición NFS para poder mover directamente nuestros binarios allí y tenerlos disponibles en el Chumby automágicamente.
Flash con Haxe
Haxe es un “lenguaje de programación open source multiplataforma” (sic) un tanto especial. Permite compilar el código a otros lenguajes (javascript, php) o al bytecode de ciertas máquinas virtuales (NekoVM) y, que es lo que nos interesa, a Flash (swf).
La instalación es sencilla, puesto que es paquete Debian ;-):
El lenguaje no es muy complejo, sintácticamente parecido a C++ o Java. Tiene algunas librerias interesantes y un sistema para instalarlas basado en repositorios, HaxeLib. Pero, como dice el refrán, un trozo de código vale más que mil comentarios :-p . Veamos un ejemplo (el que viene en la documentación, por cierto):
Nota: ¡Cuidado con los nombres! Sucede como en Java, el nombre del fichero .hx debe ser igual al nombre de la clase que contiene. El nombre del .hxml no es crítico.
// -*- mode: haxe; coding: utf-8 -*-// Test.hxclassTest{staticfunctionmain(){trace("Hello World !");}}
# compile.hxml
-swf test.swf
-main Test
Y para compilarlo, basta con:
<b>CHROOT@Chumby</b>:samples# haxe compile.hxml
<b>CHROOT@Chumby</b>:samples# lscompile.hxml Test.hx test.swf
<b>CHROOT@Chumby</b>:~# file test.swf
test.swf: Macromedia Flash data (compressed), version 8
Si quieres probarlo, de nuevo hay que llevarlo al Chumby. Esto, al ser Flash, presenta varias alternativas. La más sencilla pasa por copiarlo a la partición NFS que montas en el Chumby, y ejecutarlo con el FlashPlayer que tiene dentro. También puedes crear un profile de los que usa el panel del aparato para que lo gestione él. Más abajo veremos la primera. La segunda opción se deja como ejercicio para el lector ;-) En Mixing local widgets into a chanel tienes algunos detalles…
Exportando por NFS
El objetivo es tener una carpeta donde podamos intercambiar ficheros con nuestro aparatito. Quizá lo más sencillo sea usar un PenDrive, pero montar una partición por NFS es sin duda mas cómodo a largo plazo. Como hay muchas recetas ya, simplemente enlazo una:
Como el Chumby lo usamos siempre como usuario root tenemos que tener en cuenta una funcionaldiad sobre seguridad hecha por NFS: no permite montar en modo escritura archivos pertenecientes al usuario “root” y grupo “root”. Ese caso es el nuestro, si montamos por NFS un directorio dentro del chroot. Para saltarnos esa feature tan sólo añadir a la línea de configuración del archivo /etc/exports la opción “no_root_squash”.
La parte de configuración del Chumby explica como montar esa partición para probar los tests.
Configurar el Chumby
Pues eso, veamos principalmente como configurar el Chumby para que monte la partición NFS automáticamente en el arranque. Antes de nada, es necesario que consigas acceso por ssh, permanente o no. Para ello, esta receta te viene que ni pintada ;-) :
Tenemos dos formas de automatizar el montado: usando un PenDrive o modificando los scripts de inicio del GNU/Linux.
La opción más sencilla sin duda es la del PenDrive, pero un tanto incómoda. Hacemos uso de una característica del GNU que lleva el cacharro: cuando arranca, comprueba si hay un fichero en el Pen, llamado debugchumby con permisos de ejecución. Si lo hay, lo ejecuta. Obviamente, lo que hacemos es crearlo y meter el comando pertinente:
#!/usr/bin/env sh
cd /mnt
mkdir nfs
mount -t nfs -o nolock 192.168.0.1:/home/user/chumby/mnt/nfs nfs
Por supuesto, cambia el comando con las opciones que quieras y que te apliquen.
Si quieres hacer esto mismo sin usar el pen, tienes que seguir estas recomendaciones: Running something at boot without debugchumby. Es un hack muy chapucero, y susceptible a fallos ante actualizaciones grandes del sistema. Se me ocurre otra forma de hacerlo, pero pasa por actualizar el firmware, así que será carne de otra receta ;-)
Hay una tercera, que no deja de ser un hack chapucero, pero que es menos peligroso. Se trata de editar el fichero /psp/.profile que se ejecuta cada vez que inicias sesión en el sistema. Tiene el inconveniente de que no se montará automáticamente, a menos que entres por SSH al Chumby. Si te vale, edita el fichero /psp/.profile y añade estas lineas (o algo análogo):
# Mount nfs partitions (oscarah)
if [ ! -d /mnt/nfs ]; then
mkdir /mnt/nfs
mount -t nfs -o nolock 192.168.0.1:/home/user/chumby/mnt/nfs /mnt/nfs
fi;
Una vez montado en NFS, puedes copiar allí los ejemplos de arriba y probarlos:
chumby:/#cd /mnt/nfs
chumby:/mnt/nfs#lstest test.swf
chumby:/mnt/nfs#./test
Hola desde el Chumby!
chumby:/mnt/nfs#stop_control_panel
stopping control panel
...
chumby:/mnt/nfs#chumbyflashplayer.x -i test.swf
...
El ejemplo en Flash debe verse desde el Chumby. No cambia la iluminación del display, por lo que si estaba en modo noche no se verá muy bien… Para recuperar el panel de control, simplemente usa start_control_panel.
Garantía de calidad
Esta receta la terminé de hacer en julio de 2008. Al momento de redactarla, probé todo en una Debian/SID recién instalada y actualizada. Y que conste que todo funcionaba… :-p
Esto va sobre Ice-E, que es simplemente Ice para dispositivos empotrados. Veamos como configurar el entorno de desarrollo necesario para compilar aplicaciones con Ice-E que funcionen en OpenWRT, concretamente en un MIPS: el de la fonera.
La comunicación entre dispositivos es vital para diseñar sistemas más complejos. En este tema, uno de los primeros pasos cuando se trabaja con el PIC es la comunicación con el PC usando el puerto serie.
A continuación veremos las posibilidades disponibles y una implementación de una UART en ensamblador para el PIC.
Escenario
Por supuesto, existen muchos microcontroladores que integran entre sus periféricos una UART. En estos casos es mucho más sencilla la comunicación con el PC o con otros periféricos, pues la UART se encarga de casi todo. El problema surge cuando el micro que usamos no tiene el hardware adecuado (por problemas de espacio, de costo, etc.). En esos casos, es posible utilizar UART's hardware externas, pero que presentan el problema de tener que usar más hardware (encarecimiento, volumen...), por lo que quizá tampoco sea una solución. Para estas situaciones (u otras que se puedan presentar) tenemos la posibilidad de diseñar nosotros mismos la UART e implementarla en software. Veamos un ejemplo de esta implementación.
Ingredientes
Lo que vamos a hacer es conectar un PIC al PC para enviar información entre ambos dispositivos. Usaremos el puerto serie del PC, que emplea la norma RS232. Para hacer esto, tenemos que convertir los niveles de señal entre los que usa el PIC (TTL) y los del puerto serie (RS232). Para ello, necesitaremos un conversor. En este caso, usaremos el DS275. Para el conexionado y las señales, te remito a: La consola de la fonera: DS275. Si no quieres leer mucho, estos son los pines a conectar (usando un DB-9 para el RS232):
En cuanto a hardware, sólo eso. Necesitarás también una protoboard, pines... lo normal en estos casos. El software lo haremos nosotros ;-) .
Comunicación serie
Antes de seguir, nos sería útil saber cómo funciona una comunicación serie, en este caso la que se usa en el puerto serie de nuestro PC (o Fonera...). Serie nos indica uno detrás de otro, y en efecto, cuando transmitimos algo en serie, lo hacemos bit a bit. En el caso del PIC, si queremos transmitir algo, hemos de usar uno de los pines configurado como salida. Para transmitir un '1' lógico, ponemos el pin en nivel alto (+5V por ejemplo) y si queremos enviar un '0', ponemos el pin en nivel bajo (cerca del nivel GND). Así, variando en el tiempo el estado del pin, podemos enviar todos los datos que queramos. La pregunta que surge es: ¿cuánto tiempo mantenemos el nivel? La respuesta es obvia: dependiendo de la velocidad con que estemos transmitiendo. En el RS232 mediremos la velocidad en bps (bits por segundo).
Así pues, tenemos diferentes velocidades 'estándar': 600, 1200, 2400... En nuestro ejemplo usaremos 9600 bps, pero si es necesario podríamos llegar a velocidades de casi 1 Mbps. Luego veremos cuanto ha de durar cada bit para enviar a esa velocidad.
Vemos que si cada bit tiene una duración fija, constante, no es necesario un reloj que marque los cambios de bit. Cierto, no es necesario, es implícito. Pero esto implica que si se comete un error en la transmisión de un bit, el resto de la comunicación sería basura. Existen por tanto ciertos métodos y bits bandera para que esto no ocurra.
En primer lugar, el estado del pin de envio mientras no se está enviando es fijo (deber ser '1'). Así, cuando se empieza la transmisión, enviamos un bit de inicio (que es un '0'). Después, se acuerda entre emisor y receptor cuantos bits van a conformar los datos: 5, 6, 7 u 8. Lo normal es 8 (un byte). Se envían respetando los tiempos de cada bit. Una vez enviados los datos, el siguiente bit es opcional y se usa como mecanismo para evitar errores: la paridad. Consiste en un bit que indicar si el número de unos o ceros en los datos es par o impar. Aquí no lo usaremos.
Para terminar, enviamos uno o dos bits de parada, de forma que el pin de transmisión se quede en el nivel lógico '1'. Así, se termina la transmisión de nuestro dato. Nos quedamos con la velocidad (9600 bps), los bits de datos (8bits), la paridad (N) y el bit de stop (1): 9600 8N1
Podemos verlo todo un poco más claro en el siguiente cronograma:
UART software
Ahora lo que haremos será implementar unas rutinas que nos simplifiquen el envio de datos por el puerto serie. Antes de nada, convenir que pines usaremos. El PORTA,0 será el pin TxD mientras que el PORTA,1 será el RxD. Usaremos el PIC16F84, así lo configuramos:
list p=16f84 ; Procesador a usar.
include <p16f84.inc>
;;; Configuración
;;; Oscilador: cristal de cuarzo
;;; WatchDogTimer: apagado
;;; CodeProtection: desactivado
;;; PoWeR up Timer activado
__CONFIG _XT_OSC & _WDT_OFF & _CP_OFF & _PWRTE_ON
También podemos definir las constantes que usarán las rutinas:
;;; Constantes
tx_port equ PORTA ; Puerto de tranmisión
tx_pin equ 0x0 ; Pin de transmisión
rx_port equ PORTA ; Puerto de recepción
rx_pin equ 0x1 ; Pin de recepción
data_tx equ 0xd ; Datos a enviar
data_rx equ 0xf ; Datos recibidos
count_d equ 0xc ; Contador para el retardo
count_p equ 0x10 ; Contador para el número de bits
Ahora podemos definir la rutina de retardo, que será la que marque el tiempo que consideraremos de un bit. Como hemos dicho, la velocidad de transmisión será 9600bps. También hay un comentario que indica que el reloj que usaremos será de 4 MHz, lo que indica que tendremos un ciclo de reloj de 1 us. Si dividimos 9600/1s = 104 us. Luego la duración de cada bit ha de ser de 104 us. Nuestro bucle será así:
rs232_d:
movlw D'32' ; 1 us (algo menos de 33)
movwf count_d ; 1 us
decfsz count_d, F ; 1 us (+ 1 en caso de skip)
goto $-1 ; 2 us
return ; 2 us
Y como vemos, se ejecuta una media de 3 veces más 5 ciclos de inicialización y retorno. Luego haciendo un cálculo rápido vemos que con justo 33 veces conseguimos que rs232_d dure 104 us. En la práctica, no nos es útil acercarnos tanto al límite, por lo que si usamos 32, funciona mejor.
Ahora, cada vez que enviamos un bit, hemos de esperar el tiempo marcado por rs232_d. Veamos la rutina de envio:
send_b:
movwf data_tx ; Guargamos el dato a enviar
movlw d'8' ; Enviaremos 8 bits
movwf count_p
bcf tx_port,tx_pin ; enviamos el bit de inicio
call rs232_d
s_loop:
btfss data_tx,0 ; comprobamos el primer bit
bcf tx_port,tx_pin ; si es un 0 enviamos un 0
btfsc data_tx,0
bsf tx_port,tx_pin ; si es un 1 enviamos un 1
call rs232_d ; mantenemos el bit el tiempo necesario
rrf data_tx,F ; movemos los bits a la derecha
decfsz count_p,F ; si no se han enviado 8 bits...
goto s_loop ; seguimos
bsf tx_port,tx_pin ; si se han enviado, enviamos el bit de stop
call rs232_d
return
NOTA: enviamos el LSB (least significative bit) primero, el bit 0.
Antes de llamar a esta rutina, debes poner en W el byte que quieras enviar. Este byte se guarda en un registro, así como el número de bits de datos. Se envia el bit de inicio y después el resto de bits. Una vez terminado, nos queda poner el bit de stop y retornar. Sencillo, ¿verdad?
Pues la de recepción no es mucho más complicada:
recv_b:
movlw d'8'
movwf count_p
clrf data_rx ; daremos por hecho que son todo 0's
btfsc rx_port, rx_pin ; comprobamos bit de inicio
return ; datos erróneos
r_loop:
rrf data_rx,F ; rotamos a la derecha (primero LSB)
call rs232_d ; esperamos el tiempo adecuado
btfsc rx_port, rx_pin ; solo cambiamos si es un 1
bsf data_rx,7
decfsz count_p, F
goto r_loop
movf data_rx, W ; retornamos el dato leido, en W
return
Antes de llamar a esta rutina, es necesario que compruebes el pin RxD en espera del bit de inicio. Inmediatamente después de cambiar de estado el pin RxD, se ha de llamar a esta rutina. Es posible retardarse un lapso de tiempo máximo de rs232_d/2, pero no mucho mayor, si se quiere leer algo. Lo más aconsejable es usar como pin RxD uno que sea sensible a cambios de estado mediante interrupciones, y llamar a la rutina de lectura desde el vector de interrupción. Así se evita el hacer un polling al pin RxD.
Ejemplo de uso
Como ejemplo de uso, veremos un simple servicio de echo en el puerto serie: cada byte que se envía desde el PC al PIC es retornado de nuevo al PC. Es algo muy sencillo:
;;; -*- coding: utf-8 -*-
;;; Prueba de comunicación con el puerto RS232 de
;;; un pc. Se establece la comunicación a
;;; 9600bps, 8N1, con un cristal de 4MHz
;;; Author: Oscar Acena, (c) 2006, 2007
;;; License: GPL
list p=16f84 ; Procesador a usar.
include <p16f84.inc>
;;; Configuración
;;; Oscilador: cristal de cuarzo
;;; WatchDogTimer: apagado
;;; CodeProtection: desactivado
;;; PoWeR up Timer activado
__CONFIG _XT_OSC & _WDT_OFF & _CP_OFF & _PWRTE_ON
;;; Constantes
tx_port equ PORTA ; Puerto de tranmisión
tx_pin equ 0x0 ; Pin de transmisión
rx_port equ PORTA ; Puerto de recepción
rx_pin equ 0x1 ; Pin de recepción
data_tx equ 0xd ; Datos a enviar
data_rx equ 0xf ; Datos recibidos
count_d equ 0xc ; Contador para el retardo
count_p equ 0x10 ; Contador para el numero de bits
org 0 ; Punto de inicio
goto main
org 4 ; Rutina de interrupcion
retfie
;;; -------------------------------------------------------------
;;; Tenemos que transmitir a 9600bps, lo que implica 1 bit
;;; cada 1/9600 s -> 104 us. Con un reloj de 4MHz, tenemos
;;; un ciclo de 1us. El siguiente codigo es un bucle que usa una
;;; media de 3 ciclos, por lo que si lo ejecutamos unas 33 veces,
;;; tendremos el ratio deseado: (2+1)*33 + 1+1+1+2 = 104 us
rs232_d:
movlw D'32' ; 1 us (algo menos de 33)
movwf count_d ; 1 us
decfsz count_d, F ; 1 us (+ 1 en caso de skip)
goto $-1 ; 2 us
return ; 2 us
;;; -------------------------------------------------------------
;;; Recibimos un byte, que dejamos en w cuando retornamos. Usamos la
;;; configuración 8N1. El bit de start será el primero que leeremos.
recv_b:
movlw d'8'
movwf count_p
clrf data_rx ; daremos por hecho que son todo 0's
btfsc rx_port, rx_pin ; comprobamos bit de inicio
return ; datos erróneos
r_loop:
rrf data_rx,F ; rotamos a la derecha (primero LSB)
call rs232_d ; esperamos el tiempo adecuado
btfsc rx_port, rx_pin ; solo cambiamos si es un 1
bsf data_rx,7
decfsz count_p, F
goto r_loop
movf data_rx, W ; retornamos el dato leido, en W
return
;;; -------------------------------------------------------------
;;; Enviamos un byte, que debe estar en W antes de llamar a esta rutina
;;; con la cofiguración 8N1, a la velocidad estipulada por rs232_d.
send_b:
movwf data_tx ; Guargamos el dato a enviar
movlw d'8' ; Enviaremos 8 bits
movwf count_p
bcf tx_port,tx_pin ; enviamos el bit de inicio
call rs232_d
s_loop:
btfss data_tx,0 ; comprobamos el primer bit
bcf tx_port,tx_pin ; si es un 0 enviamos un 0
btfsc data_tx,0
bsf tx_port,tx_pin ; si es un 1 enviamos un 1
call rs232_d ; mantenemos el bit el tiempo necesario
rrf data_tx,F ; movemos los bits a la derecha
decfsz count_p,F ; si no se han enviado 8 bits...
goto s_loop ; seguimos
bsf tx_port,tx_pin ; si se han enviado, enviamos el bit de stop
call rs232_d
return
;;; Rutina principal. Configura el pic.
main:
bsf STATUS, RP0
bcf tx_port, tx_pin ; Pin TxD como salida
bcf TRISB, 0x3 ; y pin PORTB,3 como salida también
bcf STATUS, RP0
loop:
btfsc rx_port, rx_pin ; Esperamos al bit de inicio
goto $-1
bsf PORTB, 0x3
call recv_b ; recibimos
call send_b ; enviamos
bcf PORTB, 0x3
goto loop
end
En este caso, tengo puesto un LED en el PORTB,3, que se enciende cuando hay comunicación.
Lo puedes probar con el minicom, o mejor con algo hexadecimal, como el cutecom.
Disclaimer
Esta seguro no es la mejor UART que existe, desde luego. Acepto comentarios que ayuden a mejorarla. Este es mi pequeño aporte, quizá entre todos salga algo decente que podamos usar. Es lo genial del software libre.
Por otro lado, todo esto es software prototipo. No esta completamente depurado y NO ASEGURO QUE FUNCIONE EN NINGÚN CASO. NO ME HAGO RESPONSABLE DE LOS DAÑOS CAUSADOS AL HARDWARE, A LA COMPUTADORA O A SU PERSONA. Puedes modificarlo o usarlo a tu antojo. Queda bajo la licencia GPL v2.0 o posterior.
El router La Fonera, distribuido por Fon, cuenta con un puerto serie interno (por lo menos hasta la versión 2.1, aunque es muy posible que la 2.2 también traiga uno). Veamos como usarlo para acceder a la consola del GNU/Linux que lleva dentro.
Introducción
La fonera trae un GNU/Linux de fábrica. Es una versión modificada de OpenWRT por la gente de FON, pero al fin y al cabo es un GNU/Linux. Además, cuenta con un puerto serie, lo cual es una buena noticia porque nos permite interactuar con el mundo externo de una forma muy sencilla. De momento lo vamos a usar para acceder a la consola del sistema. Al contrario de lo que muchos piensan, usar un emulador de terminal con ese puerto serie no es ni mucho menos tener acceso SSH.
El SSH (Secure SHell) es un protocolo de comunicaciones que permite el control remoto de forma segura (entre otras muchas cosas). Lo que usamos nosotros es simplemente una consola del sistema (como cuando accedemos en un terminal real). El kernel de la fonera está configurado de forma que los mensajes se envíen al puerto serie. Además, se arranca una shell para ese mismo puerto que permite la interacción con el sistema. Es una consola como las de toda la vida.
Nosotros, simplemente tenemos que conectar un puerto serie de nuestro PC con el de la fonera. Bueno, realmente es un poco menos sencillo, por el hecho de que nuestro puerto serie sigue la norma RS232 con respecto a los niveles de tensión, mientras que el de la fonera no (usa niveles convencionales TTL). Luego, necesitamos algo que "adapte" entre los niveles RS232 y TTL. Este algo es un circuto, más o menos complejo.
Existen múltiples versiones. Una de ellas es la conexión directa. Actualmente, las UART de los PC's soportan los niveles TTL sin mucho problema. Otra opción es diseñar un circuito basado en transistores y diodos que haga el trabajo. Sin duda, puede ser una buena opción... a menos que quieras/puedas usar los integrados que existen a tal fin.
La "mejor" (depende de las circunstancias) versión de este adaptador es usar un conversor de niveles integrado. El más conocido es el MAX232. Es un integrado de 16 pines que necesita varios condensadores para trabajar. Otro modelo menos conocido pero quizá más sencillo de usar es el DS275. Es un integrado más pequeño, solo tiene 8 pines, que se conecta directamente, por lo que usarlo es sencillisimo. Es el que vamos a emplear aquí.
El adaptador
Como siempre, antes de usar ningún integrado, recomiendo leerse el datasheet correspondiente. Si ya lo has hecho, podemos continuar... :-)
El puerto serie del PC tiene un montón de señales que no nos interesan ahora. Son 9 pines (en un DB9 claro) de los cuales solo vamos a emplear 3, a saber:
PIN: 2 -> RxD
3 -> TxD
5 -> GND
El RxD es el encargado de la recepción de los datos, el TxD de la transmisión y el GND sólo es la referencia de las señales (GrouND). Sucede lo mismo con el serie de la fonera, solo que en este caso, vamos a usar un pin más: el de 3.5 V de referencia para el integrado. No te preocupes si parece mucho lio, al final lo verás muy claro.
Resumiendo: tenemos en el puerto serie del PC 3 pines a usar y en el de la fonera 4 pines. Los de la fonera son como sigue:
| GND # RxD TxD #
| Vcc # # # #
visto de tal forma que a la izquierda tengamos inmediatamente el borde de la placa. Mmm... quizá una imagen valga más que mil palabras...
Bien, veamos ahora el integrado que usaremos:
Y ahora las conexiones que vamos a hacer... mejor una explicación gráfica:
Y por último todo el invento montado:
Probando
Y ya está. Podemos conectar el puerto serie a la fonera y arrancar un programa de emulación de terminal en ese mismo puerto. Existe uno muy interesante llamado minicom ($ man minicom) que funciona muy bien. Configúralo para que escuche en el puerto serie de tu PC, y como parámetros: 9600 8N1 (es decir 9600 Bps, 8 bits de datos, sin paridad y 1 bit de stop).
NOTA: No te fíes del estado del minicom, que muestra siempre desconectado. Esto te sería util si usaras un dispositivo de red orientado a conexión, pero usas un puerto serie, de tipo caracter que se comporta como un flujo de datos.
Bien, ahora que lo tienes todo listo, arranca la fonera. Espera unos segundos y empezarás a ver el arranque del kernel. ¡Enhorabuena! Ya tienes acceso a la consola de tu fonera.
Si no ves nada en un rato, es probable que hayas metido la pata. Lo siento. Repasa las conexiones con cuidado. Si sigues teniendo problemas, busca ayuda. En internet hay mucha información al respecto.
Estaba pensando hacer una recetilla sobre Cairo y Gtk, algo sencillo, transparencias (adiós) y demás, pero me he encontrado a alguien... ¡que ya lo ha hecho! Increíble en estos tiempos... :-p Así que me limito a poner el enlace de su artículo, por si a alguien le interesa:
Cómo crear un módulo de Python a partir de uno en C: python wrappers para C.
Me encanta Python. La sencillez de uso y la potencia que te ofrece el lenguaje dejan mella en cualquiera. Tiene una gran cantidad de bibliotecas para hacer casi cualquier cosa. Pero claro, no todo está hecho en Python. Hay mucho código escrito en C, particularmente bibliotecas, drivers, etc. que no es accesible desde Python por cuestiones evidentes: ¡está hecho en C!
Por otro lado, es posible que tengas un proyecto en el que haya partes que son especialmente críticas en cuanto al tiempo de ejecución, y quizá te planteés hacerlas en C. Pero... ¿es posible combinarlas con el resto del código, hecho en Python?
Pues sí. Gracias a SWIG
Ingredientes
swig, por supuesto
el módulo a exportar
paciencia (a veces mucha...)
Preparándonos
Como puedes ver por el ingrediente número tres, es posible que exportar un módulo de C a Python se convierta en una verdadera odisea, sobre todo al comenzar. Pero, como todo en la vida, con paciencia es posible. ¡No te quemes!
Otra cosa a contemplar sobre Swig es que no sólo sirve para portar interfaces de C a Python, sino que lo puedes hacer a un montón de lenguajes: Tcl, Perl, Guile, Ruby, Java, PHP... (aquí está la lista completa). Y por si fuera poco, tiene algo de soporte para C++, aunque este no está completo (si quieres portar cosas de C++ a Python, yo mejor probaría con Boost.Python).
Bien, con eso en mente podemos empezar. Swig crea un wrapper (o envoltorio) de las interfaces que queremos tener disponibles para Python. Luego, hemos de especificar de alguna forma qué queremos exportar: qué funciones, qué estructuras, etc. Para eso, tenemos dos opciones.
En primer lugar, podemos modificar los ficheros de cabecera (en donde se supone deben estar los prototipos de las funciones y esas cosas) y añadir instrucciones de compilación condicional que le digan a swig qué cosas debe hacer. Esté método no se aconseja por varias razones, entre ellas, es necesario modificar el código fuente original y eso queremos evitarlo (hazme caso, QUIERES evitarlo :-p).
El segundo método es crear un fichero en el que se haga explícito lo que queremos envolver para Python. Suele tener la extensión .i, por convenio. Este fichero, que estará escrito prácticamente en ANSI C, contiene además las directivas para swig. Pero para muestra, un botón: veamos un ejemplo.
Primer ejemplo
Supongamos que tenemos un módulo sencillo que tiene algunas funciones matemáticas. Su cabecera es la siguiente:
No tiene nada especial: una estructura y cuatro funciones, que están implementadas en ejemplo.c. Para exportarlo todo a Python, podríamos modificar el código añadiendo esto después del #define __EJEMPLO_H__:
Con esto, ya tendríamos las modificaciones necesarias. Pero como esta es la manera que se desaconseja, veamos la otra.
Creamos un fichero nuevo que se llame ejemplo.i y metemos dentro lo siguiente:
La primera línea, %module ejemplo especifica el nombre del módulo y es obligatorio ponerlo, a menos que lo indiques por la línea de comandos. El bloque compuesto por '%{' y '%}' es opcional. Todo lo que haya dentro, se copiará tal cual en el fichero nuevo que swig va a crear y del cual es buen momento para hablar. Cuando swig parsee este fichero, generará uno nuevo, llamado algo_wrap.c por defecto (aunque le puedes decir el nombre que quieras), donde algo es el nombre del fichero original y que contendrá todo el código en C necesario para crear el módulo de Python, es efectivamente el wrapper que queremos. Por eso, es necesario que el wrapper sepa cosas de nuestras funciones, como por ejemplo, donde están los prototipos...
El resto del código es exactamente igual al que tiene la cabecera. Con esto, le decimos qué queremos que contenga el wrapper. Si eliminamos la función potencia() de esta lista, no la veremos en el módulo de Python. Así podemos elegir que exportar y que no.
Compilando
Bueno, es hora de terminar con esto. Sólo nos queda generar el wrapper y compilarlo todo. Para generar el wrapper, usamos swig evidentemente:
$ ls
ejemplo.c ejemplo.h ejemplo.i
$ swig -python ejemplo.i
$ ls
ejemplo.c ejemplo.h ejemplo.i ejemplo.py ejemplo_wrap.c
$
La opción -python es para indicarle que el wrapper lo queremos para Python. Podríamos haber puesto otras opciones, como por ejemplo -o wrapper.c, para indicarle el nombre del fichero, pero no es necesario, como ves ha creado uno llamado ejemplo_wrap.c. También hay otro nuevo, ejemplo.py, que es el módulo final que cargaremos y que a su vez cargará el que está en C.
Ahora podemos compilarlo todo:
Cuando compilamos el wrapper, le especificamos la ruta de las cabeceras de Python que necesita (para este caso, las de Python2.4). Y cuando lo enlazamos, le especificamos que sea -shared. Y el nombre objeto final, ha de ser '_'+nombre del módulo+'.so'.
¡Y ya está! Ahora podemos probarlo.
$python
Python 2.4.4 (#2, Apr 5 2007, 20:11:18)
[GCC 4.1.2 20061115 (prerelease) (Debian 4.1.1-21)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import ejemplo
>>> ejemplo.potencia(2, 10)
1024
>>> ejemplo.Complex()
<ejemplo.Complex; proxy of <Swig Object of type 'Complex *' at 0x81a06c0> >
>>>
Como puedes ver, se pueden usar sin ningún problema. Quizá te sea útil saber las conversiones que se hacen (en este caso, la estructura Complex se convierte en una clase que es un proxy de esa estructura). Lo puedes ver en la documentación.
Los svn:external son una feature muy interesante de subversion, que permite que cuando descargas o actualizas una copia de un modulo automáticamente ‘tire’ de otros módulos que pueden estar en otros repositorios. Una especie de gestión automática de dependencias entre repos.
Es algo bastante sencillo, usaremos las propiedades de SubVersioN. En concreto “externals”. Los externals de svn son un conjunto de mappings entre un directorio local y una url que puede ser de cualquier cosa que se pueda traer mediante svn.
Esto puede serte útil si, por ejemplo, necesitas construirte una copia de trabajo que contenga directorios de diferentes repositorios, o del mismo repositorio, pero de diferentes localizaciones.
Para ello, simplemente editamos “los externals” del directorio en concreto:
$ svn propedit svn:externals .
Lo que nos lanzará un editor de texto en el que podemos poner los mappings, de la siguiente manera:
dir_local url_destino
Cada línea será un directorio nuevo con el contenido que especifiquemos. También podemos ver los que ya existen con:
$ svn propget svn:externals
Existen versiones acortadas de los comandos: pget o pg, pset o ps y pedit o pe para propget, propset y propedit respectivamente.
Tiene algunas limitaciones: no se pueden colocar rutas relativas, ni usar ficheros como mappings. Al hacer commit, sólo se realiza en la copia de trabajo principal, no en las externas.
Posible problema
En los enlaces externos que usan ssh, por defecto determina que el nombre de usuario sea el local (igual que si haces ssh host sin especificar el nombre de usuario). Puedes modificar este comportamiento añadiendo los nuevos hosts en el archivo ~/.ssh/config y especificando ahí el nombre de usuario para el servidor concreto al que se refieres el “external”:
Según la Wikipedia, "FON es una iniciativa empresarial de Martin Varsavsky surgida en el año 2005 con el objetivo de crear una gran comunidad WiFi que permita aprovechar todas las ventajas que esta tecnología ofrece. Está presente en cada vez más países de Europa, Norteamérica y Asia".
Recientemente tuve una conversación muy interesante sobre la idoneidad de los widgets gtk.RadioButton. Vamos a ver… ¿por qué no son más intuitivos? ¿Qué piensas sobre ellos?
Breve reseña de como hacer una interfaz gráfica usando PyGTK y glade-3.
Introducción
Diseñar un interfaz gráfica para tu aplicación es muy sencillo. Además, con glade no tendrás que pelearte mucho con la API que vas a usar, GTK+.
NOTA: Aunque no necesitarás saber ampliamente como funciona GTK, sí que deberías saber un poco sobre GTK. Hay mucha documentación disponible (de hecho, GTK tiene una magnífica documentación).
Ingredientes
Básicamente:
Glade
PyGTK
Y obviamente, Python y Emacs... bueno, realmente te serviría cualquier otro editor, pero ya que estamos, hacemos las cosas bien. :-p
Para instalarlos, como de costumbre (en Debian):
Para empezar, es una buena idea que crees un directorio donde guardar todos los archivos necesarios.
$ mkdir ejemplo
$ cd ejemplo
Lanza glade para crear la interfaz:
$ glade-3
Se abrirá el gestor de proyectos, la paleta y la ventana de propiedades. Como ejemplo, simplemente puedes hacer una ventana con un botón para cerrarla.
Para crear la ventana principal, pincha sobre el widget Toplevels->Window. Aparecerá una nueva ventana, que será con la que trabajarás. Puedes colocar un botón que ocupe todo el área, pero no podrías añadir más cosas. Lo que vas a hacer es insertar un widget especial, que no se muestra, que sirve para almacenar otros widgets, HBox. Está en Containers->Horizontal Box
Cuando lo coloques en la ventana, te saldrá un mensaje preguntándote el número de elementos que quieres meter: 2.
En el lado izquierdo, puedes poner una etiqueta, Control and Display->Label. Por lo menos, para este ejemplo es muy grande, así que en la ventana de propiedades, en la pestaña Empaquetado desmarca Expandir y LLenar. En General puedes ponerle el valor a la etiqueta: 'Acción'.
En el lado derecho coloca un botón, Control and Display->Button. Como también es muy grande, de nuevo en Empaquetado desmcarca Expandir y LLenar. En General cambia el valor que se muestra en el botón (donde pone Etiqueta): 'salir'.
Es un buen momento para guardar. Llámalo como quieras, "ejemplo.glade" es una buena opción. Lo que se guarda en "ejemplo.glade" es un esquema de todos los componentes que has usado en la interfaz, junto con sus atributos, señales, etc. en XML. Esto será lo que luego utilices a la hora de generar la interfaz con libglade.
Por último, vas a añadir un par de manejadores de señal para capturar un evento y una señal. Uno para el evento, "delete-event", de la ventana principal. Este evento se lanzará cuando se cierre la aplicación (bien pulsando Alt+F4, bien haciendo click en el botón de cierre, etc.). El otro para la señal "clicked" del botón que has añadido.
Para ello, selecciona la ventana principal (desde el 'widget tree') y en el gestor de Propiedades, en la pestaña Señales, busca la señal "delete-event" (que pertenece a GtkWidget), y añade un manipulador, "on_window1_delete_event". Repite los mismos pasos para el manipulador "on_button1_clicked" de la señal "clicked" del botón que has creado.
Guarda los cambios y cierra el Glade.
Escribiendo el código
Ahora, desde el mismo terminal, edita un fichero nuevo, que puedes llamar ejemplo.py. Ábrelo con nuestro editor favorito: :-p
En el __init__ puedes ver varias cosas. En primer lugar, cómo cargas la interfaz que has hecho antes:
gtk.glade.XML("ejemplo.glade")
Después, cómo le indicas donde debe buscar los callbacks (o manejadores de señal), para las señales que le has activado, en este caso, en la misma clase.
Por último, el método self.glade.get_widget("window1") devuelve una referencia al widget "window1". Se llama a show_all() para que muestre su contenido y listo.
Sobre las firmas de los callbacks, hay mucha información en la documentación de la API de GTK. Simplemente decir que en este caso, necesitas un argumento para el widget que emite la señal, y, si es un evento, otro argumento para especificar el evento.
De nuevo, guarda los cambios y cierra el emcas (o lo que quiera que estés usando de editor :-p)
Puedes comprobar que funciona de la manera usual.
Seguro que todos habéis oido hablar estos días del los "pactos" entre Novell (distribuidor de Suse) y Microsoft. Como el tema esta muy caliente, me pica la curiosidad por saber que pensáis de ello.
¿No conocéis el humor de la gente de firefox? Pues es un poco extraño. Trasteando con el firefox 1.5.0.7 me encontre con una muestra. Si no me crees, vete al firefox y escribe about:mozilla. No te asustes. ¿Han elegido un color llamativo verdad?
Llegados a este punto, sabemos como crear una pequeña aplicación, bastante sencilla, que use Gstreamer para las tareas multimedia (evidentemente, doy por hecho que has leido el mini-tutorial que dejé. Si todavía no lo has leido, y no sabes de que estoy hablando... ¡a que esperas!).
Se me ocurre que cuando trabajamos con algunas estructuras de datos, a veces es útil poder verlas representadas, aunque solo sea en texto plano. Por ello, me atrevo a enunciar el 5º reto:
Es muy sencillo construirse un reproductor/codificador/decodificador multimedia usando Gstreamer y Python. Aquí, haremos un reproductor de Ogg Vorbis básico.
Ingredientes
python-gst0.10
La instalación, como ya sabrás, es muy compleja y tediosa, pero no hay mas remedio que tragar :-P :
#apt-get install python-gst0.10
Introducción
Antes de empezar a escribir código, unas breves líneas de como rula Gstreamer. Gstreamer es básicamente un framework para la manipulación multimedia. Con él se puede hacer casi de todo, desde un simple reproductor de Ogg Vorbis (como aqui veremos) hasta complejas aplicaciones distribuidas de streaming multimedia. Todo depende de los modulos y plugins de que dispongamos.
Gstreamer funciona como un flujo de datos dentro de una tubería. Se selecciona una fuente de datos, un camino para estos (en el que se pueden modificar o no) y un destino. Podemos manipular los eventos que se produzcan en la tubería, controlar su estado e incluso inyectar más datos a nuestro antojo. Interiormente, en la tubería, los datos también pueden seguir diferentes caminos. Por ejemplo, el vídeo puede ir por un lado, mientras que el audio procesarse por otro.
En Gstreamer, todas las partes que usamos para construir la tubería (la fuente, el destino, los codificadores, etc.) se llaman “Elementos”, que tienen ‘enchufes’ (Pads). Entonces, cuando creamos la tubería conectamos unos enchufes con otros, para que el flujo siga su curso. Y estos Pads, tienen establecido un sentido para el flujo de datos: de salida (llamados Source) y de entrada (llamados Sink). Cada elemento de Gstreamer puede tener uno o varios pads, o ninguno (e incluso, es muy común que los pads se creen dinámicamente, segun sean necesarios).
Por ejemplo, podemos crear una tubería con una fuente que lea de un fichero de audio en Ogg Vorbis, más un demultiplexor para el envoltorio del Vorbis (es decir, un elemento que extraiga del Ogg los datos
codificados con Vorbis), más un decodificador de Vorbis, por supuesto. Además necesitamos un conversor de audio y por último, un destino, que podría ser por ejemplo ALSA. Simplemente con esto, nos construimos un reproductor de Ogg/Vorbis, que es lo que vamos a hacer.
Manos a la obra
Pues bien, como todo lo vamos a hacer en Python, lo primero que necesitamos es importar los modulos que vamos a usar. Es decir:
gst: evidentemente, y además en su version 0.10, con lo que también importaremos pygst para cargarlo.
Hasta ahí nada nuevo. Ahora tenemos que crear la tubería. Para esto hay diversas maneras. Podemos crear cada elemento por separado, enlazar los Pads correspondientes y después meterlos todos en un contenedor. De esta forma, tenemos un mejor control sobre lo que hacemos, pero existe una herramienta con la que es mucho más sencillo todo. Se llama ‘parse_launch’. Acepta una cadena con la estructura final de nuestra tubería, y nos devuelve la tubería hecha. Así, para nuestra tubería, la cadena que tendríamos que formar es:
Esta cadena contiene cada elemento (con el nombre por el cual está definido) más algun atributo de ese elemento, separados con el símbolo de admiración (!). ‘filesrc’ es el elemento que se encarga de leer de un fichero del disco, y con la propiedad ‘location’ establecemos la ruta al fichero que se tiene que leer; ‘oggdemux’ es el demultiplexor de Ogg, etc.
Pues si le pasamos esta cadena a parse_launch, intentará crearnos la tubería correspondiente, y además completamente funcional.
try:pipeline=gst.parse_launch(pipestr)exceptgobject.GError,e:print"No es posible crear la tuberia, "+str(e)return-1
Ahora sería útil añadir un pequeño manipulador de eventos, ya que si se produce algún mensaje dentro de la tubería, debemos gestionarlo nosotros. En esta ocasión, solo haremos caso de dos mensajes: EOF, que
nos indica que debemos terminar (End Of Stream, o fin de flujo) y ERROR, que también nos obliga a terminar, pero advirtiendo de que se produjo un error interno. El resto lo ignoramos. Para ello crearemos una mini función interna que lo gestione todo.
Y la añadimos al bus de comunicaciones que tiene la tubería.
pipeline.get_bus().add_watch(eventos)
Ya tenemos la tubería completamente creada. Ahora sólo nos queda establecer el estado de la misma. El estado de la tubería especifica que es lo que pasa con el flujo dentro de ella. Disponemos básicamente de NULL, READY, PLAYING y PAUSED. El estado inicial de la tubería es NULL, y si queremos que empieze a funcionar, tendremos que cambiarlo
a PLAYING. Una vez ahí, el flujo de datos puede fluir por todos los elementos.
pipeline.set_state(gst.STATE_PLAYING)
¿Qué pasa? ¿No debería sonar ya? Hombre, pues no exactamente. Todavía nos queda un pequeño detalle. Como antes dije, Gstreamer usa Gobject, y por tanto, todos sus elementos bailan al son de Gboject. Por ello, es necesario crear un MainLoop y ponerlo en marcha. También sería bueno poder salir de una manera adecuada cuando se pulsa Ctrl+C.
loop=gobject.MainLoop()try:print"Reproduciendo..."loop.run()exceptKeyboardInterrupt:# Por si se pulsa Ctrl+C
passprint"Parando... \n¡Adios!"
Como nota, he de decir que la función ‘run’ de gobject es un bucle de eventos, es decir, el programa se quedará en ese punto hasta que ‘run’ retorne. En nuestro caso, eso sucede cuando se pulsa Ctrl+C o cuando se produce un evento EOS o ERROR (ya que entonces se llama a ‘quit’ de Gobject).
Ya esta sonando todo… bien. Ahora solo nos queda decidir que hacer cuando termine el flujo o se pulse Ctrl+C. Lo lógico es poner la tubería en estado NULL y salir. Eso haremos.
pipeline.set_state(gst.STATE_NULL)return0
Bien, pues ya tenemos nuestra función principal. Yo añado un par de lineas para que se llame a esa función principal cuando el script se ejecuta como tal, y no cuando se importa como módulo, pero esto es a gusto del consumidor ;-)
if__name__=="__main__":sys.exit(main(sys.argv))
¡Y ya está! Así de sencillo ;)
Comentarios
Como ves, es muy fácil. Casi todo el codigo necesario es para manipular eventos o parte del programa principal. La esencia de todo radica en la cadena de texto que se pasa a ‘parse_launch’. Si cambiamos los elementos, creamos tuberías diferentes. Por ejemplo, en vez de dirigir la salida a ALSA, la puedes dirigir a un fichero (con filesink). Esto lo dejo para tu imaginación ;-p . Gstreamer es muy potente, así que con poca cosa se pueden hacer cosas muy interesantes… ¡que te diviertas!
Todo junto
Para que no tengas que copiar y pegar muchas veces, aquí dejo todo el codigo del programa completo, todo juntito, ¡testeado, funcionando y todo!
importpygstpygst.require("0.10")importsys,gst,gobjectgobject.threads_init()defmain(args):iflen(args)!=2:print"Uso:",args[0]," <archivo Ogg>"return-1pipestr="filesrc location= %s ! oggdemux ! vorbisdec ! audioconvert ! alsasink"%args[1]try:pipeline=gst.parse_launch(pipestr)exceptgobject.GError,e:print"No es posible crear la tubería,",str(e)return-1defeventos(bus,msg):t=msg.typeift==gst.MESSAGE_EOS:loop.quit()elift==gst.MESSAGE_ERROR:e,d=msg.parse_error()print"ERROR:",eloop.quit()returnTruepipeline.get_bus().add_watch(eventos)pipeline.set_state(gst.STATE_PLAYING)loop=gobject.MainLoop()try:print"Reproduciendo..."loop.run()exceptKeyboardInterrupt:# Por si se pulsa Ctrl+C
passprint"Parando... \n¡Adios!"pipeline.set_state(gst.STATE_NULL)return0if__name__=="__main__":sys.exit(main(sys.argv))
Hola. He escrito poco por aquí, pero he leído mucho. Como a mí me encanta GNU/Linux y el SL en general, me gusta "urgar" dentro del mismo, y de linux en particular. Y me he dado cuenta de que existen algunas cosas que son, como poco, útiles y curiosas. Por ello, a lo que iba, me gustaría saber si hay algún hueco para estas cosillas curiosas del SL por aquí. No forman parte del recetario, pues no son recetas, son... eso, curiosidades. Por ejemplo, algo que yo no sabía era de la existencia de zenity. Muy útil y práctico. O del trap de bash, que sirve para muchas cosas. ;) Bueno, pues eso. Consideradlo, si teneis tiempo. Graicas.
El HTC Magic se distribuye bloqueado para que los usuarios no dispongan de permisos de root para su administración. Ello no impide poder instalar o desinstalar aplicaciones, desarrollar nuevo software, o acceder a su sistema de ficheros a través de una shell. Sin embargo en algunos casos puede ser necesario disponer de estos permisos, como por ejemplo para añadir soporte a redes inalámbricas WPA2, que no vienen configuradas de serie.
Sin embargo, al menos de forma temporal, existe una forma de evitar el bloqueo, gracias a un exploit para los núcleos 2.6.x conocido desde hace tiempo (CVE-2009-2692). Este problema ya ha sido corregido en los núcleos distribuidos desde Agosto del 2009, pero aun funciona en aquellos teléfonos que no han sido actualizados.
El código fuente del exploit puede obtenerse del blog de Zen, a partir del cual se ha definido un método muy sencillo para ejecutar como root cualquier aplicación. El procedimiento es el siguiente:
En primer lugar debe descargarse la aplicación FlashRec que permite modificar la imagen de rescate (recovery image) de los teléfonos android.
A continuación debe descargarse la aplicación en el teléfono, ya sea a través de la shell o bien copiando el fichero en la tarjeta microSD y siguiendo el procedimiento descrito en ??
Después se ejecutará la aplicación (icono Recovery Flasher)
La aplicación reconoce el tipo de teléfono y sugiere en la caja de texto la nueva imagen de rescate a descargar, por lo que simplemente debe pulsarse sobre la opción Flash Recovery Image. Mientras dura el procedimiento NO INTERRUMPAS EL PROCEDIMIENTO
Reboot into Recovery Mode. Equivalente a iniciar el teléfono pulsando las teclas de encendido y HOME simultáneamente
(Opcional). Una vez en el modo de rescate no sería mala idea hacer una copia de seguridad del software del teléfono (FIXME: crear la receta correspondiente)
iniciar una shell. Si todo ha ido bien el prompt debería ser el carácter #
montar la partición que contiene el software del sistema, ya que no se monta por defecto en el modo de rescate
/ #mount /dev/block/mtdblock3
crear el comando su
/ #cd /system/bin<br>
/ #cat sh > su<br>
/ #chmod 4755 su
Hola, tengo un pc portatil "beep" con tarjeta de televisión interna y tras muchas pruebas, manuales y recetas... he llegado a la conclusión de que no se configurarla para poder ver la tele en mi ubuntu. Alguien ha instalado alguna?? puede ser problema de que no tenga el chip bt??
Muchas gracias.
Hola, lo primero que quería hacer era agradecer a la gente que maneja mucho este tema y nos ayuda y orienta a los que pretendemos avanzar, aunque sea despacito. Realmente, muchas gracias.
De la mano de Miguel García Corchero, el desarrollador del nuevo museo interactivo de la ESI cuya inauguración es inminente, nos llega este estupendo Howto sobre cómo programar shaders en GLSL bajo GNU/Linux, tarea algo compleja en principio.
Ampliando la información de Cleto sobre el Wiimando… De lo mejor que he visto son las librerías nativas de C libwiimote (paquete debian en su versión muy antigua), aunque a la fecha de escritura de este post van por la 0.4. Pueden descargarse en http://libwiimote.sourceforge.net/. Para compilarlas necesitarás tener libbluetooth y bluez.
Estas librerías permiten recuperar la información de los sensores internos de aceleración y rotación del wiimando, reproducir pequeños samples de sonido en el altavoz e incluso acceder a la información guardada en los slots de memoria… Y además son muy sencillas.
Como ejemplo de uso os dejo este pequeño video de ejemplo que hice ayer, que representa un objeto en OpenGL según la rotación del mando, junto con el código fuente.
La línea de compilación del ejemplo (se debería hacer un bonito makefile), una vez que tengáis instaladas estas librerías y las de OpenGL (+GLUT) sería algo así como:
Una forma sorprendentemente sencilla de hacer streaming de video tipo YouTube, pero usando sólo software libre.
Quién no conoce el streaming de video en flash. Páginas tan famosas como YouTube o la versión de google video.google.com son capaces de reproducir videos en formato FLV de Flash. El formato Flash en si es una especificación libre de la que han salido algunos proyectos interesantes, como Flowplayer; un reproductor libre de formato FLV, con lo que podremos añadir videos a nuestras páginas empleando herramientas libres!! Veamos cómo...
Lo primero que necesitamos es convertir nuestro video original en formato FLV. Para ello, haremos uso de ffmpeg, con una orden similar a la siguiente (os pego directamente la orden del video de ejemplo):
Naturalmente, tendréis que cambiar la resolución del video destino (en este caso 288x144). Bien, tenemos un video en formato FLV. Para que el reproductor pueda saber la duración del video, permitir avanzar o retroceder en el video, etc... el fichero necesita unos metadatos que en la version actual de ffmpeg no añade. Suerte que tenemos un programa hecho en Ruby para estas marranadas llamado flvtool2:
$flvtool2 -U dest.flv
Con esa sencilla orden, flvtool2 añade los metadatos escribiendo sobre el propio fichero que le pasamos como parámetros. Bien, ya casi hemos terminado... Sólo falta descargarnos el fichero swf del FlowPlayer e incluir en nuestro html un objeto como el siguiente:
Os recomiendo echar un vistazo a todas las opciones que soporta FlowPlayer, ya que se pueden poner thumbnails para videos largos, personalizar la imagen de "clicktoplay" (como he hecho en el ejemplo), cambiar el aspecto del reproductor mediante skins, etc...
La resolución de reproducción del video, como veis en el html es en realidad el doble de la del fichero de video. Esto permite que el video se vea más grande, y la pérdida de calidad por el aumento de la resolución no se aprecia demasiado (en las escenas rápidas se ve peor, pero no es problema de la resolución, sino por el algoritmo de codificación). Fijaos en el principio del video...
Bueno, pues os dejo con el video de presentación del festival de cortos Annecy del 2002 titulado "Jurannessic"... o cómo se descubrió el fenómeno de la persistencia de la visión. Bye!!
Estamos realizando un estudio formal sobre cuánto tiempo emplean los usuarios de Yafray en conseguir un buen Setup de iluminación. Para hacer más sencilla la recolección de datos, hemos realizado una página web con un poco de información del proyecto y cómo colaborar con vuestras escenas.
Hay que facilitar la vida al usuario; y nada mejor que hacer un instalador sencillito donde todo está empaquetado en un .sh... pero ¿cómo se hace?
No he encontrado mucha información al respecto y, aunque no es complicado, puede que no se te ocurra directamente cómo hacerlo.
Bien, pues simplemente hay que utilizar la estupenda herramienta cat y añadir el binario a descomprimir al final del fichero de shell... Como muestra un botón. ;)
Bien, con la orden anterior concatenamos el fichero que tendrá las órdenes a realizar del shell (cabeceraInstalador.sh), con el binario comprimido (todocomprimido.tgz), y lo juntamos en el fichero final llamado instalador.sh. ¿Cómo decirle al script dónde empieza la parte binaria del archivo? Utilizando la bonita utilidad tail.
#!/bin/sh
echo ""
echo "AutoInstalador del programa XX.XX v.1.0"
echo ""
# Cogemos la parte de este archivo a partir de la línea 11 y
# se la mandamos al tar para que la descomprima.
tail -n +11 $0 | tar xvz
exit 0
En el caso anterior, le pasamos a tail el parámetro +11, porque el fichero del script tiene 10 líneas. Podemos automatizar la tarea de contar el número de líneas haciendo un script un poco más complejo que, además utiliza un directorio temporal y ejecuta un script de instalación (que estará dentro del .tgz). Veamos el script en versión "pro":
#!/bin/sh
echo ""
echo "AutoInstalador del programa XX.XX v.1.0"
echo ""
# Creamos un directorio temporal donde lo extraeremos
export WRKDIR=`mktemp -d /tmp/selfextract.XXXXXX`
# Contamos las lineas de este fichero con awk. La cadena
# "__AQUI_SIGUE_EL_BINARIO__" debe ser la ultima linea del
# script. Le sumamos una a la ultima linea y la guardamos
# en SKIP.
SKIP=`awk '/^__AQUI_SIGUE_EL_BINARIO__/ { print NR + 1; exit 0; }' $0`
# Cogemos la parte de este archivo a partir de la línea 11 y
# se la mandamos al tar para que la descomprima en el temporal.
tail -n +$SKIP $0 | tar xvz -C $WRKDIR
# Nos vamos al temporal y ejecutamos el script de instalacion
PREV=`pwd`
cd $WRKDIR
./install.sh
# Borramos los ficheros temporales
cd $PREV
rm -rf $WRKDIR
exit 0
__AQUI_SIGUE_EL_BINARIO__
Pues nada más. Seguiré mirando la forma de crear buenos instaladores. Desde luego, el script anterior es muy pobre. Se puede mejorar añadiendo un bonito interfaz en modo texto con dialog o sus equivalentes en modo gráfico gdialog y kdialog aunque no se... me sigue gustando más la de modo texto; además es más estándar y como diría Neal Stephenson, "En el principio fue la línea de comandos".
Ya que nuestros políticos defienden los “derechos” de unos pocos a cobrarnos indiscriminadamente por todo aquello susceptible de contener o propagar cualquier tipo de datos, los usuarios debemos unirnos contra estos impuestos a favor de unos pocos. He aqui una noticia sobre una agrupación contra el CANONDIGITAL
El ordenador en cuestión se encenderá siguiendo los pasos dados en la receta Encendido remoto de un ordenador con Debian, mediante Wake On LAN . Entonces pedirá un servidor PXE. Para ello utilizaremos el servidor de dhcp 3 que soporta este tipo de servicio. Se necesita un servidor tftp, ya que es el único servidor soportado por PXE para la transmisión de ficheros. TFTP es un servidor ftp ligero. No tiene ningún tipo de autentificación así que cuidado con lo que ponéis en su directorio. Usaremos el servidor atftp. Necesitaremos un archivo llamado pxelinux.0 . Este archivo es el encargado de cargar el arranque, algo así como el GRUB en versión red. Existe una versión del GRUB que permite el arranque en red, aúnque parece ser que todavía no funciona correctamente.
pxelinux.0 es el que he usado yo. Seguramente existan versiones más nuevas, pero este me ha funcionado sin problemas. Necesitaremos también un núcleo para compilar y una imagen del sistema.
Configuración de dhcp
Necesitaremos el paquete debian dhcp3-server que será nuestro servidor PXE. Estas son las líneas que hay que añadir al dhcpd.conf
Aquí estamos indicando de donde se obtiene el pxelinux.0 y que grupo de máquinas van a obtener el arranque. La línea de next-server es por si el servidor tftp está en una máquina diferente a la del servidor dhcp. Si no es así, se puede eliminar. Le asignamos una ip fija. No es necesario, pero nos puede venir bien a la hora de hacer los primeros seguimientos de la máquina.
Configuración del servidor tftp
Necesitaremos el paquete debian atftp .
Si lo usamos, deberemos tener en el archivo /etc/default/atftpd la siguiente configuración:
Esta es mi configuración. /tftpboot es el directorio donde debe iremos poniendo los ficheros que vamos a enviar.
Configurando el arranque
Desde ahora tomamos como directorio de trabajo /tftpboot. Copiamos aquí el archivo pxelinus.0. Creamos un directorio llamado pxelinux.cfg . Este contendrá los archivos de configuración para cada máquina. Yo usaré Default , genérico para todas las máquinas. Se puede llegar a personalizar para una máquina determinada o un grupo de maquinas. Este archivo contiene la configuración del arranque y una serie de parámetros que podemos indicarle al kernel.
label linux
kernel bzImage
append nfsaddrs=192.168.0.1 root=192.168.0.1:/tftpboot/192.168.0.12
label indica el sistema operativo que vamos a arrancar.
kernel indica como se llama el fichero que contiene el kernel.
append son una serie de parámetros que podemos pasar al kernel. En la configuración que os doy indicamos que el servidor nfs está en un servidor concreto y donde monta el directorio raíz. Otra opción podría ser cargar el directorio raíz en RAM, siempre y cuando nuestros ordenadores dispongan de los suficientes megas.
Configurando nuestro Linux
Vamos a configurar el sistema que vamos a cargar en los clientes. Primero compilaremos el kernel. Simplemente sugeriros que incluyáis todo lo que valláis a usar en el núcleo, para no cargarlo como módulos. Aquí surge una duda de como seguir. Si vamos a montar el directorio raíz en RAM o NFS deberemos incluir diferentes módulos.
NFS
requiere de los módulos File systems Kernel automonter support File systems -> Network Filesystems: NFS File System Suport y Root File System on NFS .
RAM
no requiere de módulos especiales.
Creando nuestro sistema de ficheros
Vamos a crear ahora nuestra imagen initrd. Esta es una imagen comprimida de nuestro sistema de ficheros que solo es necesaria si usamos RAM para montar nuestro sistema de ficheros. Si usamos NFS todos estos procesos quedarán reducidos a ejecutar la orden debootstrap sobre el directorio del NFS. Dicho directorio debe estar en el del servidor tftp (/tftpboot en nuestro caso)
Creamos un fichero del tamaño de nuestro file system dd if=/dev/zero of=/home/pepe/fsfile bs=1K count=130000 . Con esto he creado un archivo llamado fsfile con un tamaño de 130MB.
Lo formateamos. Aquí os sugiero que si vais a montar vuestro sistema de ficheros en RAM lo formateéis en ext2, el journalism no tiene sentido aquí. mke2fs -j -b 4096 /home/pepe/fsfile . Lo formateo a ext3
(-j) con un inodo por cada 4 kb.
Montamos nuestro filesystem
mount -o loop -t ext3 /home/pepe/fsfile
Lo "llenamos". Podemos montar un sistema "mínimo" de muchas maneras. La mas fácil es la orden debootstrap, aunque de mínima tenga poco (104Mb).
debootstrap sarge /home/pepe/fsfile http://ftp.debian.org/debian. En el caso de querer algún paquete más podéis usar la orden chroot para cambiar el directorio raíz y luego usar el apt-get install
Cambiamos los archivos de configuración, los de arranque,etc.
Desmontamos el sistema de ficheros. umount /home/pepe/fsfile
Aprovechando que los ordenadores de hoy en día no están realmente apagados mientras sigan teniendo alimentación, podemos arrancarlos por red.
Requisitos
Necesitamos que el ordenador que va a ser arrancado via red tenga una tarjeta de red con Wake-On-Lan (WOL) o Boot-On-Lan (BOL), una placa que soporte este modo de arranque, y activar dicha opción en la BIOS.
Despertando al durmiente
Necesitamos instalar el paquete debian etherwake tanto en el ordenador a despertar como en el ordenador "despertador". Este paquete incluye un comando para activar el WOL a la tarjeta del ordenador que vamos a arrancar.
#ethtool -s eth0 wol g
Con esto activamos el encendido en red de la tarjeta eth0 de nuestro ordenador mediante la técnica del magic packet .
Sólamente necesitamos saber la MAC de nuestra tarjeta, que la podemos obtener con el comando ifconfig y luego, desde el ordenador "despertador" ejecuta:
#etherwake 00:11:9B:20:21:F6
Recordad que la MAC debe tener las letras en mayúsculas para funcionar.
Mmmm, ¿no te atreves a destripar tu NDS para ver lo que tiene? ¿Te paraste cuando ya no quedaban más tornillos que quitar? Bueno, aprovechando la coyuntura de una NDS ajena con ganas de chapotear la hemos destripado enterita.
Los contenidos de CRySoL no son de dominio público. Se pueden copiar y adaptar, pero respetando los derechos de autoría. El administrador del sitio unidadlocal.com nos ignora a pesar de las protestas. Es turno de pasar a la acción.
Ya por estas fechas muchos de vosotros habreis visto que la Escuela Superior de Informática de la UCLM ha editado la Guía Docente en forma de un pincho USB. Por primera vez en la historia de la ESI podemos arreglar la Guía Docente para los que usamos GNU.
¿Harto de teclear la clave cuando te salta el salvapantallas? ¿Harto de que el vecino de cubículo cotillee to correo cuando se te olvida bloquear el escritorio? Tenemos una solución. El Omnikey Cardman 5321 es un lector de tarjetas RFID y de tarjetas de contactos bastante barato, pero el fabricante no proporciona información :-( . Esta recetilla explica como usarlo en Debian usando el driver binario que distribuyen ellos.
A new version of my debian packages for devkiPro was released today. They are more or less synched with devkitARM r24 (with an updated dswifi), devkitPPC r16, and a current repository snapshot of psp-sdk (with small patches).
Con propósitos docentes he generado un paquetillo Debian que contiene DevkitPro 23b para ARMEABI, PPC y PSP completo, con las herramientas de manipulación de imágenes, generación de ROMs, depuración, etc.
Esta recetilla explica como cambiar la password en un Active Directory, como el de la UCLM. De paso os pongo un scriptito para facilitar un poco lidiar con esas “políticas de seguridad” tan agresivas que les ha dado por poner a las universidades…
Os presento una pequeña utilidad para la Nintendo DS que permite bajar y subir todo tipo de archivos a cualquiera de los dos slots y hacer copias de seguridad o restaurar las memorias EEPROM de los cartuchos de juegos. En el lado del PC no necesitas nada especial, solo netcat.
Tras muchos muchos intentos de todo tipo y cuando ya pensábamos en comprar un router wifi solo para la Nintendo DS porque no había manera de que pitufara como debe…
Los usuarios de cualquier variante de GNU o de Unix buscan desde siempre el Santo Grial de la administración de sistemas: autenticación flexible y centralizada, backup flexible y sencillo, homes compartidos facilitos. En esta receta nos ocupamos del primer ingrediente, la autenticación.
Desgraciadamente no dispongo del tiempo necesario para seguir día a día los comentarios de CRySoL. Soy consciente de que esta web sobrepasa ampliamente las fronteras de su nombre y siempre está en las primeras posiciones de Google busques lo que busques relacionado con el software libre. Lo que no me esperaba es que tuviera noticias de CRySoL desde el secretario de la ESI. No pensaba que fuera a conocer este hilo a través de un escrito “formal” de queja. Y digo “formal” porque precisamente las formas no las guarda en absoluto.
Si das o pretendes dar clase en la Universidad estoy seguro de que estás hasta los güevos de reescribir el curriculum en 100 formatos diferentes. En cada formato te piden cosas diferentes, organizados de forma diferente, y lo que es peor, con herramientas diferentes.
Linux-Vserver es similar a las zonas de Solaris 9 o a las jaulas de FreeBSD. Permite ejecutar procesos de forma totalmente aislada respecto a los demás, lo que lo convierte en una especie de máquina virtual ultra-rápida.
Esta receta cuenta mis experimentos con el Active Directory de la universidad. Está en construcción porque todavía estoy experimentando, así que paciencia. Aprovecho para decir que me parece una kk el drupal éste, que no permite tener documentos en modo Draft, sin que sea visible.
El VGN-TX27TP es un laptop ultraligero con Pentium M ultra-low voltage de 1.2 Ghz y grabadora de DVD dual-layer. El TFT es de 1360×768 y está retroiluminado con LEDs. Tiene botoncillos por todas partes, un par de USBs, un firewire, ethernet, modem, bluetooth, wifi y ranura SD/memory-stick.
De serie me venía con caracteres chinos en el teclado que le dan un toque geek y, lo más importante, un layout americano, con todas las teclas raras donde deben estar…
También viene con un Windows XP en auténtico chino mandarín y un programita basado en linux para actuar como media player sin tener que encender el Windows. De esto último me enteré demasiado tarde, así que si alguien lo tiene todavía que me lo diga, que los cutres de Sony no me dieron ni un CD.
En esta receta veremos cómo realizar el exorcismo de este pobrecillo PC para darle mejor vida.
Lo más dificil
Bueno, lo más difícil con diferencia es lo aparentemente más simple. Las pegatinas. Tiene dos pegatinas que hacen que funcione deficientemente: una dice “Designed for Windows XP” y la otra dice “Microsoft Windows Original”. Ambas están muy bien pegadas en la carcasa y succionan la sustancia del pobre Vaio. Yo lo resolví con un trapo de algodón húmedo pero muy muy escurrido y mucha, mucha paciencia.
Lo peor está hecho, mete el CD de un Debian netinstall y tira millas. Si instalas una unstable no tendrás apenas problemas. La tarjeta gráfica (intel 915GM) la autodetecta, la ethernet (Intel e100) y la wifi también (tiene una intel pro wireless 2200bg).
Lo deja en un estado bastante usable salvo por la salida externa de VGA, el synaptics touchpad y los botones.
¡¡¡Y lo que es más importante: el software suspend funciona out-of-the-box!!!
Se me caían las lágrimas cuando lo vi…
La configuración de Xorg
El touchpad funciona de serie, pero para activar los taps, scroll, arrastre y tal no he encontrado nada que lo haga automáticamente. Tuve problemas con los parámetros por defecto, que lo dejaban con una sensibilidad extrema. Al final, googleando encontré este trozo que me va bien.
La resolución 1366×768 es la estándar de DVB y HDTV, pero es problemática porque la horizontal no es divisible por 8. Xorg exige que sea divisible por 8, asi que tenemos que elegir entre 1360 o 1368. Yo me quedé con 1360 porque a mi me resulta molesto el scroll automático que resulta cuando la resolución virtual es mayor que la física.
El teclado lo tengo como un estándar americano. Eso tiene el inconveniente de que no sé como escribir los caracteres chinos. Bueno, tengo que confesar que intenté escribir en chino en un Windows chino y tampoco sabía como sacar los simbolitos, parecía todo aleatorio…
De esta forma me sale el gestor de ventanas sobre las dos screens, cada una con su resolución.
Control de brillo, activación WiFi/Bluetooth
Instala spicctrl. En teoría con esto basta, pero el brillo no va, necesitamos sony-acpi-source y compilar con module-assistant:
m-a a-i sony-acpi
Y en /etc/modules añadir
sony_acpi
En Gnome va perfectamente el control de brillo con las teclitas normales.
La activación/desactivación del bluetooth, las temperaturas y el estado de las baterías se puede ver con spicctrl. Por ejemplo, para desactivar el bluetooth:
spicctrl -l 0
Las teclas multimedia se pueden mapear perfectamente con los aceleradores de Gnome. Todas menos dos, que no hay manera, las del control de volumen. ¡Tanto la teclita de subir volumen como la de bajar volumen generan el mismo scan-code!
Teclado
El teclado es super cómodo. Una vez te haces al layout americano no puedes vivir sin él y tienes que empezar a pedir teclados USB por Internet para poder usar los ordenadores que te rodean.
Escribir en lenguas extrañas como la de Cervantes tampoco es complicado. Simplemente te añades al teclado USA normal el teclado USA con alfabeto internacional. Se puede conmutar con el applet de keyboard indicator. Al usar el de alfabetización internacional el apóstrofo, las comillas, el apóstrofo inverso, el gurrumuño y el sombrerito pasan a ser dead-keys, con lo que se pueden escribir sin problemas acentos, eñes, etc. De hecho si usas el Alt derecho en combinación con n tienes una eñe, si lo combinas con la coma tienes una cedilla, si lo combinas con una vocal tienes la vocal acentuada, si lo combinas con una s tienes la ß germánica. En fin, que es más fácil y rápido escribir en alfabetización internacional con un teclado USA que con un spanish.
Y sobre todo echadle un vistacillo a cómo estan los corchetes, las llaves, los paréntesis, la barra invertida, el signo de dividir… ¡Todo está donde tiene que estar!
La ranura SD/MemoryStick
En teoría con el 2.6.17 debería funcionar, pero a mi todavía no me funciona. No es que me haya pegado mucho con el… pero así por las buenas no va.
Hay recetas por ahí para hacerlo funcionar, pero casi que me espero a que el 2.6.17 o el 2.6.18 lo soporten plenamente :-)
Imagina que de pronto se estropea tu disco duro, o tu portátil. Imagina que evolution deja de funcionar y no puedes leer tu correo. ¿Qué? ¿Te da un pasmo, como a mi? Esta receta te ayudará a configurar tu correo de manera que lo recibas todo por duplicado, tanto en la UCLM como en Gmail. El de la UCLM lo leerás como es habitual, pero si un día te encuentras sin poder acceder a tu correo, o lo borras por error (sí, también me pasó a mi :( ). O estás en casa de un amigo y quieres leer tu correo, ahí está Gmail para ayudarte.
Con este mini-HowTo aprenderemos a escribir caracteres chinos (tradicional -fántǐzì- o simplificado -jiǎntǐzì-) en nuestra distribución GNU/Linux preferida utilizando la plataforma SCIM (Smart Common Input Method). Este tutorial puede ser extensible a otros idiomas como el Japonés o el Árabe, por ejemplo.
Instalar SCIM y sus plugins de Chino
SCIM es una plataforma que nos va a permitir escoger el Chino o cualquier otro idioma como método de entrada. Además, nos ayudará después en la escritura de los caracteres (No es tarea fácil sacar ideogramas de un teclado qwerty ^_^) . Para instalarlo tecleamos lo siguiente en un terminal:
$sudo apt-get install scim
Por supuesto, también necesitamos el soporte de scim para Chino:
Se abre la ventana principal de SCIM y nos dirigimos a la sección IMEngine. Dentro de ella, pinchamos en la opción "Configuración Global", habilitamos Chino (simplificado) y/o Chino (tradicional). Los idiomas que tengamos habilitados luego los podremos seleccionar a la hora de ponernos a escribir los caracteres.
Para finalizar, pinchamos en "Aceptar".
Escribir los Caracteres
Abrimos un editor de texto plano (por ejemplo, gedit) y hacemos click derecho en la hoja en blanco. En el menú contextual, vamos a "Método de Entrada" y seleccionamos "SCIM Input Method".
Si todo ha ido bien, abajo aparece una nueva barra con diferentes iconos.
Puede ser que las primeras veces se resista. Esta barra sólo sale cuando el idioma Chino está correctamente habilitado en SCIM, así que si no te ha salido, probablemente el SCIM siga puesto para el español. Para comprobarlo, haz click izquierdo en el icono de SCIM de la barra de tareas al lado del reloj y comprueba que aparece el chino. Si no es así, haz click derecho y pulsa en "Actualizar Configuración".
Nosotros escribiremos con nuestro teclado qwerty las palabras chinas en pinyin (sin los tonos) y él nos mostrará las diferentes palabras chinas que existen con esas letras, probando con diferentes combinaciones de tonos. Es algo parecido al sistema de entrada T9 de los móviles.
Ahora que tenemos la barra, pinchamos en el icono a la derecha de la chincheta. Aquí elegiremos el algoritmo que nos va a ayudar a escribir. Debemos elegir la última opción que aparece en la parte de Chino (simplificado) (es la única que no tiene caracteres latinos en su descripción). También lo podemos escoger sin necesidad de la barra, en el menú desplegable que aparece al hacer click sobre el icono de SCIM al lado del reloj en la barra de tareas.
Un Ejemplo
Como no podía ser de otra forma, para probarlo escribiremos "Hola Mundo".
Off-Topic: De todas las acepciones posibles de "mundo", me ha parecido mejor por la que se traduciría por "todo el mundo".
En pinyin sería (digo yo, sólo llevo un mes aprendiendo :P) "quán qiú hào" (por si tenéis curiosidad, se pronunciaría parecido a chuanchiou jao).
Para escribirlo, como ya hemos dicho, no necesitamos escribir los tonos (las tildes; en Chino hay 5 tipos), así que escribimos "quan" y nos aparecen varios ideogramas. El que se corresponde con el que buscamos es el primero, así que pulsamos el espacio y se guarda. Seguimos escribiendo "qiu" y el caracter que buscamos es el segundo, por lo que pulsamos el 2 en el teclado. El caracter correspondiente de "hao" también es el primero, así que simplemente escribimos hao y damos un espacio. El resultado es el siguiente:
Esta receta describe cómo configurar una grabadora de CD/DVD para aprovechar todas sus posibilidades y velocidad.
Es muy posible que aunque k3b detecte perfectamente tu grabadora, luego resulte que la velocidad de grabación no llegue a la que teóricamente tiene la unidad.
Es normal que no se alcance la velocidad máxima que proporciona el fabricante y, además, la velocidad no es continua (es más lenta cuando graba en el interior del cd que en el exterior). Esto puede ser debido a que, por motivos de seguridad y, para que no se produzcan conflictos entre determinados tipos de placas base y dispositivos de almacenamiento, algunas distros (caso de mi Ubuntu Breezy) no activan el DMA por defecto.
Ver estado por defecto
Para ver la configuración de nuestro dispositivo usa hdparm <dispositivo>, por ejemplo:
Ahora actiremos el DMA, el io_support (E)IDE 32bit I/O support- y el unmaskirq (enmascarar o no otras interrupciones mientras se procesa una interrupción del disco). Siguiendo el ejemplo anterior:
$ sudo hdparm -d1 -u1 -c1 /dev/hdc
/dev/hdc:
setting 32-bit IO_support flag to 1
setting unmaskirq to 1 (on)
setting using_dma to 1 (on)
IO_support = 1 (32-bit)
unmaskirq = 1 (on)
using_dma = 1 (on)
Como consejo, si realizas muchas copias “al vuelo” (del lector a grabadora) es mejor tenerlos en diferentes canales IDE.
Comentarios
Este era un problema que tenía, pregunté en la lista y lo que he explicado es lo que me contestaron listeros como Luis Mayoral y fSancho (las mieles son pa ellos :)).
Esta receta muestra como crear una live personalizada tanto para un pendrive como para un CD en sólo una línea. Esto es posible gracias al proyecto Debian Live.
Esta receta ilustra cómo configurar el servidor RTSP Darwin Streaming Server en un sistema Debian GNU/Linux. Se ha configurado para que un dispositivo móvil pueda recibir flujo RTSP sin problemas.
Una vez descargado y descomprimido el installer del DSS podemos empezar a instalarlo, pero previamente hay que crear un usuario y un grupo qtss que utilizará el servidor para manejar los archivos de configuración.
Tras crear este usuario y grupo podemos lanzar el instalador
sudo ./Install
Durante la instalación se pregunta sobre el usuario y la contraseña para la administración del servidor, ya que será accesible desde la
red a través de una interfaz web a través de estos parámetros.
Tras finalizar la ejecución del instalador se crean los siguientes archivos:
/usr/local/sbin/DarwinStreamingServer (Servidor)
/usr/local/bin/PlaylistBroadcaster (Permite crear nuevas listas de reproducción)
/usr/local/bin/MP3Broadcaster (Permite crear nuevas listas de reproducción)
-p puerto por defecto para RTSP
-D mostrar información por la salida estándar
-c para indicar el archivo de configuración del servidor
-h help
(sudo DarwinStreamingServer -h muestra una descripción de los parámetros)
A continuación podemos lanzar la interfaz web por medio del script en Perl streamingadminserver.pl.
sudo streamingadminserver.pl
Se pedirá login con el usuario y contraseña introducidas en la instalación, y posteriormente se configurarán otros parámetros básicos. Una vez introducidos ya estamos en disposición de crear listas de reproducción a partir de archivos.
También es posible crear listas de reproducción via línea de comandos por medio del comando PlaylistBroadcaster.
Crear listas de reproducción
La interfaz web que ofrece es lo suficientemente simple como para no deternenos en ella, sin embargo no ocurre lo mismo con la codificación
de los archivos multimedia.
Los archivos multimedia deben contener información sobre cómo se debe realizar el streaming (hinting), y además deben tener una calidad
adecuada al dispositivo que lo va a reproducir, por lo que debemos coficar y 'firmar' cada archivo que queremos servir.
Cabe destacar que el DSS solo admite formatos 3gp, mov, mp4 y mp3, por lo que es posible que haya que recodificarlos (ffmpeg, mencoder).
A continuación se muestra un ejemplo adaptado a dispositivos móviles de codificación y 'firma' de un .mp3 y de un .avi. Para ello se utiliza ffmpeg y MP4Box (de la suite gpac).
Una vez codificados los archivos solo hay que ubicarlos en el directorio donde se hayan dispuesto las 'movies' y listo, ya se pueden añadir a las listas de reproducción, que serán accesibles por medio de la url 'rtsp://ip_servidor/nombreListaReproducción'.
PlaylistBroadcaster
Si queremos crear una lista de reproducción sin utilizar la interfaz web deberemos crear una serie de archivos de configuración; éstos archivos deben pertenecer al grupo qtss, de lo contrario no aceptará la lista. A continuación se muestran los pasos a seguir para poner en marcha una lista de reproducción vía línea de comandos.
1.- Crear un directorio para la lista.
sudo mkdir /var/streaming/playlists/plTest
2.- Crear un archivo con extensión.playlist que contenga la ubicación absoluta de cada 'movie' a reproducir con un peso asociado.(no olvidar la línea *PLAYLIST*)
*PLAY-LIST*
#
#Created By AVISMI.MediaServer
#
"/usr/local/movies/testMono8000Hz.3gp" 5
3.- Crear un archivo .config. Este archivo establece los parámetros de la lista de reproducción. (PlaylistBroadcaster -h, muestra una descripción del archivo de configuración)
Nótese que no se han definido los archivos .sdp ni .pid; ésto se debe a que mediante la opción -f se le dice a DSS que genere de forma automática el archivo .sdp (.pid es generado automáticamente por DSS).
4.- Lanzar el PlaylistBroadcaster
PlaylistBroadcaster -a -t -f /var/streaming/playlists/plTest/plTest.playlist
-a asocia el broadcast al servidor
-f generar el sdp automáticamente
-t envia por TCP el broadcast al servidor
Mapnik es una librería que permite generar y manipular mapas obteniendo los datos de diferentes fuentes (archivos .shp, PostGIS, .tif). En esta receta se muestra como utilizar mapnik en Python.
Ingredientes
mapnik (por ahora nos vale con el paquete debian)
libmapnik0.5
mapnik-plugins
mapnik-utils
python-mapnik
postgis
postgresql
ogr2ogr (opcional)
Map
Mapnik permite crear y manejar mapas a partir de diferentes fuentes de datos. Esta librería se basa en el objeto Map que contiene varios atributos que permiten personalizarlo. Los atributos mas relevantes son:
background - Establece el color de fondo del mapa.
height - Ancho del mapa.
width - Alto del mapa.
style - Define cómo se visualizan de los distintos componentes del mapa.
layers - Capas que contiene el mapa. Es decir cada una de las fuentes de datos que queramos que muestre el mapa.
Además esta clase permite manejar el mapa por medio de diversos métodos.
pan - centra el mapa en la posicion indicada (x,y).
pan_and_zoom - centra el mapa en la posicion indicada y hace zoom sobre ella.
zoom_all - realiza el zoom a todas las capas, es decir, visualiza el mapa entero.
zoom_to_box - realiza el zoom a todas las capas en un determinado area.
envelope - obtiene el area de las capas del mapa.
También existen algunas funciones que no pertenecen a ningún objeto en concreto.
render_to_file(Map, archivoConExtension) - Renderiza el mapa a un archivo.
render(Map, CairoContext) - Gracias a este método se puede integrar con GTK. No disponible via paquete debian, solo bajando el .tgz y compilando.
save_map(Map, archivoConExtension) - Almacena el mapa en un archivo.
frommapnikimport*#Creacion del Mapa
width=790height=590map=Map(width,height,'+proj=latlong +datum=WGS84')map.background=Color('white')
Style
Para visualizar el objeto Map se le debe asociar una serie de objetos Style que permiten definir como se debe representar cada elemento del mapa.
Un Objeto Style se compone de reglas (Rules) para elementos del mapa, siendo posible definir filtros para cada una de dichas reglas. Por ejemplo podemos crear dos Rules en las que en una los puntos que cumplen una determinada condición se vean de color rojo mientras que los demás se vean de otro color. Para ello se debe asociar a la regla un objeto Filter que realize el filtrado deseado.
Elementos del mapa:
PolygonSymbolizer - Establece el estilo de los poligonos.
LineSymbolizer - Establece el estilo de las lineas.
PointSymbolizer- Establece el estilo de los puntos.
RasterSymbolizer - Permite que se visualizen las imagenes raster.
#Creacion del Estilo del Mapa
styleShp=Style()r=Rule()r.symbols.append(PolygonSymbolizer(Color('#f2eff9')))r.symbols.append(LineSymbolizer(Color('rgb(50%,50%,50%)'),0.1))r.symbols.append(RasterSymbolizer())styleShp.rules.append(r)#Filter
# Acepta <, >, <>, not, or, and
# En teoria tambien puede filtrar por expresiones regulares
# pero tras probarlo no he obtenido resultados satisfactorios
# Ej.- [id].match('^ascensor')
style=Style()rVerde=Rule()rVerde.symbols.append(PointSymbolizer('img/puntoVerde.png','png',10,10))rVerde.filter=Filter("not [id]='escalera0_up' or not [id]='escalera1_up'")rRojo=Rule()rRojo.symbols.append(PointSymbolizer('img/puntoRojo.png','png',10,10))rRojo.filter=Filter("[id]='escalera0_up' or [id]='escalera1_up'")style.rules.append(rRojo)style.rules.append(rVerde)map.append_style('styleShp',styleShp)map.append_style('style',style)
Layers
Hasta el momento puede obtener datos de diferentes fuentes, para ello se crean
objetos Layer con la fuente de datos necesaria (datasource) a partir de varias clases.
Raster - Permite crear una layer a partir de imagenes (.tif). Puede ser util la herramienta ogr2ogr para convertir imagenes normales a imagenes con formato geográfico.
Shapefile - Crea una layer a partir de un archivo .shp de descripción de figuras geométricas.
PostGIS - Crea una layer a partir de la información de una tabla de una base de datos Postgres con campos PostGIS (geometry). Es posible realizar un pequeño filtrado de la tabla pero solo se puede trabajar con la tabla en cuestión nada de hacer joins ni comparaciones con campos de otras tablas.
Gdal - Todavia no lo he probado :-)
#Layers del Mapa
#---------------
#A cada layer hay que asociarle:
# Una fuente de datos
# Un Style para representar la informacion
# Finalmente hay que asociarla al mapa
lyrImg=Layer('raster')lyrImg.datasource=Raster(file='img/pbaja.tif',lox='0',loy='0',hix='50',hiy='50')lyrImg.styles.append('styleShp')lyrGeo=Layer('GIS')lyrGeo.datasource=PostGIS(host='localhost',user='mapnik',password='mapnik',dbname='mapnik',table='mapnik')lyrGeo.styles.append('style')lyrShp=Layer('shape')lyrShp.datasource=Shapefile(file='shp/salas')lyrShp.styles.append('styleShp')#El orden de aplicacion de las capas es relevante
map.layers.append(lyrImg)map.layers.append(lyrShp)map.layers.append(lyrGeo)#Importante ajustar el zoom para ver el mapa
map.zoom_all()render_to_file(map,"MapNik","png")
Mi conexión a internet es ONO, mediante wifi, con Zyair pero no podía meterme en internet desde Linux (Molinux –kernel 2.6.12-9-386 ) y sin embargo, si podía hacerlo mediante windows. Si tienes el mismo problema te animo a que sigas estos pasos:
Abierto el plazo de inscripción para la VI edición del Concurso Universitario de Software Libre, la fecha límite será al menos hasta el 6 de Noviembre.
Durante esta edición el Centro de Excelencia de Software Libre de Castilla-La Mancha proporcionará a los estudiantes de la región asesoramiento en los elementos decisivos para el éxito de un proyecto dentro del concurso, como son: el impacto del proyecto en la Comunidad, la calidad del desarrollo, la documentación y el grado de finalización del proyecto.
Más información sobre el concurso en: http://www.ceslcam.com/participa/concurso-software-libre/
El próximo 28 de Abril se celebra el Día del Software Libre en la Escuela Superior de Ingeniería Informática (ESII) de Albacete.
Durante el evento se organizarán charlas y talleres sobre software libre, como la Fase Final del Concurso Univ. de Software Libre de CLM, Android, Bazaar, GvSIG, etc.
Entre los asistentes a los eventos habrá un sorteo de un móvil HTC con Android y un equipo Media Center.
Esta jornada se engloba dentro de las actividades organizadas para la Semana Cultural del Campus Universitario de Albacete, que tendrá lugar del 26 al 30 de Abril.
Puede encontrarse más información sobre la agenda de la jornada e inscribirse en: http://ceslcam.com/dia-del-software-libre-albacete.html
Ampliado plazo para la presentación de proyectos hasta el 7 de Noviembre.
Podéis encontrar más información en las bases del concurso e inscribiros ahora mismo.
La Consejería de Industria de la Junta de Comunidades de Castilla-La Mancha, a través del Centro de Excelencia de Software Libre de Castilla-La Mancha crea una distribución ligera que puede ser utilizada en ordenadores antiguos. Se caracteriza principalmente por necesitar recursos mínimos para poder funcionar. Así mismo dispone de todos los aplicativos necesarios para el funcionamiento diario de cualquier persona en la Sociedad de la Información: procesador de textos, hoja de cálculo, diseño gráfico, navegación por internet, correo electrónico, chat y otros aplicativos de propósito general. Todo ello incluido en un sistema operativo actual que le permite ser usado también en equipos nuevos.
Ya está abierto el plazo para inscribirse a la Fase Final del II Concurso Universitario de Software Libre de Castilla-La Mancha. Este año se celebra en Cuenca, en su escuela politécnica, el Martes 28 de Abril. El día no es muy bueno, pero debido a una serie de problemas con la disponibilidad de las salas no ha podido encontrarse otro mejor.
La asistencia es gratuita e incluye un Crédito de Libre Configuración , transporte en autobús desde Albacete y Ciudad-Real, obsequios y sorteos entre los asistentes. Las plazas para la asistencia al evento y autobuses son limitadas. Si estás interesad@, inscríbete cuanto antes en la web del concurso http://ceslcam.com/concurso.
Ya se encuentra abierto el plazo de inscripción para asistir a la FASE FINAL del Concurso Universitario de Software Libre de Castilla-La Mancha que se celebra el próximo Martes 28 de Abril en Cuenca, en su Escuela Universitaria Politécnica.
La asistencia es totalmente gratuita e incluye un Crédito de Libre Configuración por participar en las actividades, transporte en autobús desde Albacete y Ciudad-Real, obsequios y sorteos entre todos los asistentes.
Los alumnos de la UCLM que todavía permanezcan dubitativos o que no hayan encontrado una idea hasta el momento tienen una nueva oportunidad para participar en el concurso. El periodo de inscripción finalizará el viernes 31 de Octubre de 2008, cubriendo así las sugerencias de los estudiantes castellano-manchegos.
El próximo 17 de Octubre finaliza el periodo de inscripción al II Concurso Universitario de Software Libre de Castilla-La Mancha y ¡¡Queremos Animarte a Participar en esta Nueva Edición!!
La semana pasada se abrió la II edición del Concurso Universitario de Software Libre de Castilla-La Mancha (www.ceslcam.com/concurso) que como muchos ya sabéis consiste en el desarrollo de un software realizado íntegramente con una implementación libre de cualquier lenguaje de programación y que cuenta con un presupuesto en premios de más de 9.000 euros
La Junta de Comunidades de Castilla-La Mancha, a través del Centro de Excelencia de Software Libre de Castilla-La Mancha, lanza en colaboración con la Escuela Superior de Ingenieria Informática de Albacete la III Edición del Curso de Java, el cual ha tenido gran acogida en las dos ediciones anteriores.
Con motivo de la apertura del canal en YouTube del CESLCAM y para celebrar el día de Internet el próximo 17 de mayo, el Centro ha puesto en marcha un concurso referido a la creación de videotutoriales en Molinux para premiar al mejor video formativo.
Desde la UCLM y el Centro de Excelencia de Software Libre de Castilla-La Mancha (CESLCAM) se está organizando la Fase Final del I Concurso Universitario de Software Libre de Castilla-La Mancha que tendrá lugar el próximo 17 de abril en la Escuela Superior de Informática de Ciudad Real.
El 17 de Abril, la Escuela Superior Informática de Ciudad Real, acoge la Fase Final del Primer Concurso Universitario de Software Libre de Castilla-La Mancha. El evento consiste en la realización de una jornada en la que se expondrán los proyectos finalistas y se realizarán un ciclo de charlas y talleres para los asistentes al evento.
Desde el Centro de Excelencia de Software Libre de Castilla-La Mancha ya se está trabajando en la organización de la fase final del I Concurso Universitario de Software Libre de C-LM que tendrá lugar en la Escuela Superior Informática de Ciudad-Real el día 17 de Abril.
La plataforma de teleformación alojará una serie de cursos de OpenOffice destinados a aquellos usuarios que quieran aprender de forma simple y cómoda las funciones más habituales de esta suite ofimática libre: procesador de textos Writer, hoja de cálculo Calc y creador de presentaciones Impress.
La Junta de Comunidades de Castilla-La Mancha, a través del Centro de Excelencia de Software Libre de Castilla-La Mancha (CESLCAM), continúa con su labor de enseñanza online desde su plataforma de teleformación, sitio principal de las acciones del programa Formados que se está llevando a cabo por el centro en el marco del Proyecto PASCAL (Plan de Acción en Software Libre 2007-2008 de Castilla-La Mancha), financiado por el Gobierno regional y promovido por el Parque Científico y Tecnológico de Albacete.
Tras la firma del convenio de colaboración para la promoción y uso de Molinux en la sección de empleo y formación del Ayuntamiento de Albacete, se inauguró una exposición de software libre compuesta por una serie de paneles informativos donde se ilustra la historia y características de este software para difundir y ampliar el conocimiento del mismo entre todos los ciudadanos de la Región.
Días después de la presentación de la nueva versión 3.2 Hidalgo del software libre de Castilla-La Mancha, Molinux, se ha puesto a disposición de todos los ciudadanos el curso de formación online de esta versión, una iniciativa gratuita del Gobierno regional a través del Centro de Excelencia de Software Libre de Castilla-La Mancha (CESLCAM), perteneciente al Parque Científico y Tecnológico de Albacete.
La Junta de Comunidades de Castilla-La Mancha a través del Centro de Excelencia de Software Libre de Castilla-La Mancha, perteneciente al Parque Científico y Tecnológico de Albacete, organiza, con la colaboración de la Escuela Politécnica Superior de Albacete de la UCLM, la II Edición del Curso Online de Java.
En este tiempo, el Centro de Excelencia de Software Libre de Castilla-La Mancha (CESLCAM) se ha centrado en la organización de jornadas de difusión; talleres; puesta en marcha del primer concurso universitario de software libre en Castilla-La Mancha; creación de un portal web y observatorio tecnológico en fuentes abiertas; participación activa en comunidades relacionadas con estas tecnologías como el proyecto Morfeo de telefónica I+D; acciones sociales con equipamientos hardware reutilizables; puesta en marcha de su plataforma de teleformación y en otro conjunto de actividades que han intentado acercar el software libre a todos los ciudadanos para aprovechar todas las ventajas que supone el uso de estos aplicativos.
Concluido el plazo de inscripción de proyectos, ya ha comenzado el I Concurso Universitario de Software Libre de C-LM que pretende promover entre el mundo universitario el desarrollo de Software Libre con el fin de introducir al mayor número de alumnos en el mismo y conseguir que adquieran experiencia en un modelo cada vez más demandado en el entorno laboral, así como formar a profesionales que respondan a la creciente demanda de este tipo de software que hay en la sociedad.
La bolsa de trabajo del CESLCAM es un servicio del Centro de Excelencia de Software Libre de Castilla-La Mancha, perteneciente al Parque Científico y Tecnológico de Albacete, cuyo objetivo es establecer el contacto entre las empresas oferentes de empleo y los profesionales demandantes del mismo.
La bolsa de trabajo del CESLCAM es un servicio del Centro de Excelencia de Software Libre de Castilla-La Mancha, perteneciente al Parque Científico y Tecnológico de Albacete, cuyo objetivo es establecer el contacto entre las empresas oferentes de empleo y los profesionales demandantes del mismo.
Hace unos días vi que alguien buscaba un Media Center en Linux.
Pues mirar en www.megabox.es
Han desarrollado un Media Center gratuito en GNU-LINUX y en español.
NO se necesita ningún conocimiento de informática para instalarlo, ni se puede desconfigurar.
Usa el freevo como interface.
Una muy buena idea.
Adémás es GRATIS.
Consulta Tengo Eclipse 3.1 instalado, pero no puedo hacer que me reconozca el tomcat dentro, Descomprimi el pluing com.sysdeo.eclipse.tomcat_3.1.0 dentro de la carpeta pluing en eclipse, pero no se como hacer que me aparezca dentro de eclipse.
gracias.
Esta receta prentede mostrar al usuario cómo instalar OpenCV en Ubuntu 9.04.
Posibles problemas
Según he podido comprobar y además leer, aquí, y aquí, entre otros; existen problemas entre la última versión de la librería de OpenCV 1.1 y la librería ffmpeg, problemas que provocarán fallos a la hora de compilar OpenCV.
¿Cómo evitar estos problemas e instalar OpenCV correctamente?
Esta receta prentede ser una introducción a los hilos utilizando la librería glib.
¿Qué es un hilo?
Un hilo de ejecución es una característica que permite a una aplicación realizar varias tareas concurrentemente. Los distintos hilos de ejecución comparten una serie de recursos tales como el espacio de memoria, los archivos abiertos, situación de autenticación, etc. Esta técnica permite simplificar el diseño de una aplicación que debe llevar a cabo distintas funciones simultáneamente, por ejemplo si programamos videojuegos podemos tener un hilo para la Inteligencia Artificial, otro para la física y otro para el renderizado de los gráficos, pero todos ellos se ejecutarán de manera paralela.
¿Qué es glib?
La librería glib es una de las más importantes que existen en GNOME. Dentro de glib está implementada una serie de tipos de datos que nos hace más fácil, si cabe, el tratamiento de los datos y además tiene la propiedad de mejorar la portabilidad de nuestros programas.
Un ejemplo sencillo de programa en C++ que crea dos hilos
#include <cstdlib>
#include <iostream>
#include <glib.h>
GThreadFuncfuncion_de_prueba(char*cadena);intmain(intargc,char*argv[]){char*mensaje1="mensaje_1";char*mensaje2="mensaje_2";//inicializamos el soporte para hilos en glibif(!g_thread_supported())g_thread_init(NULL);//reservamos memoria para los hilos de manera dinámicaGThread*productor=(GThread*)malloc(sizeof(GThread));GThread*consumidor=(GThread*)malloc(sizeof(GThread));//creamos los hilosproductor=g_thread_create((GThreadFunc)funcion_de_prueba,(char*)mensaje1,TRUE,NULL);consumidor=g_thread_create((GThreadFunc)funcion_de_prueba,(char*)mensaje2,TRUE,NULL);//destruimos los hilosg_thread_join(productor);g_thread_join(consumidor);//liberamos memoriafree(productor);free(consumidor);return0;}//esta es la función que es llamada por los hilosGThreadFuncfuncion_de_prueba(char*cadena){printf("esta es la funcion de prueba\n");printf("mensaje %s\n",cadena);}
Resultados que deberás obtener
esta es la funcion de prueba
mensaje mensaje_1
esta es la funcion de prueba
mensaje mensaje_2
o bien
esta es la funcion de prueba
esta es la funcion de prueba
mensaje mensaje_1
mensaje mensaje_2
Hola a todos\as, pertenezco a la ONG ingenieros sin fronteras (ISF), los miembros de dicha ONG aquí en C. Real hemos acordado dar charlas en la semana que va desde el 21 al 27 de Abril, por distintas facultades de C.Real.
Esta receta pretende dar a conocer al lector en qué consiste la técnica de diseño de algoritmos “divide y vencerás”. Para ello se incluyen a continuación unas breves nociones teóricas y un ejemplo práctico sencillo.
¿En qué consiste la técnica “divide y vencerás”?
En el mundo de las ciencias de la computación es una técnica de diseño de algoritmos que consiste en resolver un problema a partir de la solución de subproblemas del mismo tipo, pero de menor tamaño. Si los subproblemas son todavía relativamente grandes se aplicará de nuevo esta técnica hasta alcanzar subproblemas lo suficientemente pequeños para ser solucionados directamente. Por último, habrá que combinar las soluciones obtenidas en los subproblemas para obtener la solución del problema inicial.
Estructura del algoritmo en versión recursiva
El pseudocódigo del algoritmo Divide y Vencerás en versión recursiva es el siguiente:
El pseudocódigo del algoritmo Divide y Vencerás en versión iterativa es el siguiente (yo personalmente he visto muchas más veces implementada la versión recursiva que esta iterativa):
Ejemplo sencillo de la técnica “divide y vencerás” en C
Se trata de solucionar el siguiente problema:
Diseñe un algoritmo “Divide y Vencerás” que calcule xn (x elevado a n) con un coste O(n log n).
intexponencial_n(intbase,intexponente){intresultado_parcial;intexponente_actual;switch(exponente){case0:return1;break;case1:returnbase;break;case2:return(base*base);break;default:exponente_actual=exponente/2;/*Dividimos a la mitad*/resultado_parcial=exponencial_n(base,exponente_actual);if(exponente%2==0)returnresultado_parcial*resultado_parcial;/*si el exponente es par*/elsereturnresultado_parcial*resultado_parcial*base;/*si es impar*/}}
Bibliografía
“Divide y vencerás”, Ampliación de programación. ESI. Miguel Angel Redondo.
Esta receta lo que pretende es mostrar cómo se puede configurar un adaptador inalámbrico de red USB mediante el programa ndiswrapper. Dicho programa se debe utilizar cuando el adaptador de red USB carece de drivers para GNU/Linux.
En concreto lo he probado para Molinux, que a su vez se basa en Ubuntu, que a su vez se basa en Debian, que a su vez se basa en Dios.Por lo tanto creo que para esas cuatro distribuciones debería valer.
Asegurate de que el dispositivo no tiene drivers para GNU/Linux
Para saber si tu dispositivo tiene drivers para GNU/Linux deberás conocer su chipset. Una vez conocido el chipset comprueba si posee driver para GNU/Linux.
Si no posee drivers para GNU/Linux deberás utilizar ndiswrapper
Ndiswrapper es un sistema que nos va a permitir usar los drivers para windows “envolviendolos” para que puedan funcionar en un kernel linux.
¿Cómo se instala ndiswrapper?
teclea:
$sudo apt-get install ndiswrapper-common
O si lo prefieres te puedes descargar el tar.gz desde su página web
Después decomprimes y haces un
$make install
Descargar drivers de Windows
Deberás descargar los drivers que hay disponibles para windows. Normalmente deberán estar en la página web del fabricante.
Instalar drivers
Vete al directorio donde se encuentren los archivos con los drivers de windows y haz como root.
$ndiswrapper -i nombre_del_driver.inf
La -i es de install. Lo que hará ndiswrapper es copiar el archivo .sys y crear una configuración para él. Lo podemos encontrar en /etc/ndiswrapper.
¿Cómo comprobar si el driver se ha instalado correctamente?
Teclea
$ndiswrapper -l
Esto nos lista los drivers que tenemos instalados con ndiswrapper y si su hardware está presente o no.
Cargar el módulo de ndiswrapper
El siguiente paso es cargar el modulo de ndiswrapper de la siguiente manera:
$modprobe ndiswrapper
Ultimo paso, creando el alias
Si todo ha funcionado bien, sólo nos resta hacer un
$ndiswrapper -m
para crear el alias wlan0 ndiswrapper en /etc/modprobe.d/ndiswrapper. Esto hará que cada vez que usemos la interfaz wlan0, se cargue el módulo ndiswrapper. La interfaz se puede levantar normalmente con ifconfig wlan0 up.
¿Con qué programas puedo observar a qué redes me puedo conectar?
Bien, yo al menos conozco dos:
Network-Manager. Molinux lo traía instalado por defecto.
y otro es Wifi-Radar, para instalarlo:
Intento realizar la reconstrucción 3D a partir de la visión estereo (dos imágenes o más) he llegado a un punto en el que me he quedado atascado. A ver si alguno de ustedes me puede orientar.
Aclaraciones:
La reconstrucción 3D lo que pretende es obtener las dimensiones 3D de un objeto a partir de varias imágenes tomadas del mismo desde diferentes posiciones(mínimo dos imágenes).
Para ello yo estoy utilizando dos cámaras.
Pasos que estoy siguiendo:
Calibrar la cámara izquierda (Obtenemos la matriz de cámara KL)
Calibrar la cámara derecha (Obtenemos la matriz de cámara KR)
Sacar una imagen desde el lado izquierdo
Sacar una imagen desde el lado derecho
Detectar coordenadas en píxeles del objeto deseado de la imagen izquierda(mínimo 8 )
Detectar las mismas coordenadas en píxeles del objeto deseado en la imagen derecha(mínimo 8 )
Calcular la matriz fundamental a partir de los píxeles anteriormente calculados
Para ello utilizo la función de OpenCV:
cvFindFundamentalMatrix( points1, points2,8,0, fund_matrix);
points1 corresponde a los puntos de la imagen de la izquierda, y points2 corresponde a los puntos de la imagen de la derecha, la matriz fundamental queda almacenada en fund_matrix.
calcular la matriz esencial a partir de la matriz fundamental y la matriz de cámara de ambas cámaras
De la siguiente forma:
ME=KLT x F x KR
Siendo ME la matriz esencial.
KLT la matriz transpuesta de KL(matriz de cámara izquierda).
KR matriz de cámara derecha.
F la matriz fundamental.
calcular la descomposición SVD de la matriz esencial
Para ello hay que utilzar la siguiente funcion de OpenCV.
void cvSVD( CvArr* A, CvArr* W, CvArr* U=0, CvArr* V=0, int flags=0 );
A es la matriz que queremos descomponer.
U,W,V son la matrices en las que se descompone. Como vemos en la siguiente línea de abajo.
A=U*W*VT
Calculamos la matriz de rotación(R)
de la siguiente forma:
U*P* VT
donde P es :
| 0 1 0 |
| -1 0 0|
| 0 0 1|
Calculamos la matriz de traslacion(T)
de la siguiente forma:
V*PP* VT
donde PP es :
| 0 -1 0 |
| 1 0 0|
| 0 0 1|
A partir de aquí es cuando empiezan mis primeras dudas, a partir de la T de arriba, tengo que sacar un vector de 3 X 1.
En uno de los documentos lo que hacen es formar esta matriz de 3 X 1, a partir del a02 y a21, de la siguiente forma:
|a21|
|a02|
|a02|
Con todas las matrices halladas anteriormente resolver las siguientes dos ecuaciones independientes
m1=[K1|0]M
m2=[(K2*R)|(-K2*R*T)]*M
m1 es una matriz 3X1 (coordenadas en pixeles de la primera imagen)
m2 es una matriz de 3X1 (coordenadas en pixeles de la segunda imagen)
K1 es una matriz de 3x3(matriz de cámara 1)
K2 es una matriz de 3X3(matriz de cámara 2)
R es una matriz de 3X3 (matriz de rotación)
T es una matriz de 3X1 (vector de traslacion)
M es el punto 3D que quiero obtener.
Mis dudas
Aplicando algebra lineal he conseguido hallar los puntos 3D M en ambas ecuaciones, el problema que he encontrado es que el eje Z, es decir, la tercera dimensión, la profundidad del objeto me la calcula de forma erronea.
¿Alguno de ustedes sabe si mi error radica en algún paso anterior?
¿Alguno de ustedes realiza la reconstrucción 3D de otra forma?
Agradecería cualquier tipo de orientación.
Un saludo
En esta receta se explica, qué hacer para indicar a X.Org qué tarjeta de vídeo tienes, y qué driver debe utilizar.
Acceder al archivo xorg.conf
La información que te interesa introducir, se encuentra en el archivo xorg.conf, para acceder a él, lo único que tienes que hacer es:
$cd etc/X11
Una vez aquí, te deberá aparecer el archivo xorg.conf, abrelo con algún editor de textos, por ejemplo:
$gedit xorg.conf
En este archivo, entre otra mucha información, hay una parte que hace referencia a la tarjeta de vídeo, la sección se llama Section "Device", por ejemplo a mi lo que me aparece es lo siguiente:
Esta receta ha sido posible gracias al altruismo de mi colegilla Cristobal. Blog de Cristobal.
Por supuesto, gracias también, a todos los que hacen posible CRySoL y agradecerles la oportunidad que me dan de comunicar lo poco que sé.
Sí te aburre el tradicional color en blanco y negro que aparece en tu cargador de arranque de GRUB, En esta receta verás como colocar una imagen de fondo.
Utilizar Gimp
Una imagen de arranque de GRUB puede tener una resolución máxima de 640X480 píxeles y un máximo de 14 colores.Para conseguir tal resolución ejecute el programa Gimp y realiza los siguientes pasos con el puntero del ratón:
Archvivo->Abrir->Selecciona la imagen que quieras colocar de fondo en el gestor de arranque GRUB
imagen->escalar imagen->y aquí pon la resolución 640X480
imagen->modo->indexado(y aquí pon el número máximo de colores a 14)
guarda la imagen en modo RGB
ya puedes cerrar el Gimp
ahora accede a donde hayas guardado la imagen y ponle el nombre nombre_que_tú_quieras.xpm (es fundamental que no se te olvide la terminación .xpm)
Comprimir la imagen
Aunque no es estrictamente necesario comprimir la imagen, reducirá el tiempo necesario para cargarla. Por lo que harás lo siguiente desde línea de comandos(accede al directorio en donde guardaste la imagen):
$gzip nombre_que_hayas_elegido.xpm
esta instrucción creará un archivo de la forma nombre_que_hayas_elegido.xpm.gz
Copiar en el directorio /boot/grub
Ahora copia el fichero nombre_que_hayas_elegido.xpm.gz en el directorio /boot/grub, para ello teclea en línea de comandos:
si fuera necesario, se sustituye (hd0,1) con la notación Grub para el disco duro y la partición en la que está almacenada tu distribución GNU/Linux.Esto lo podrás comprobar en el mismo archivo menu.lst, por ejemplo, en mi archivo menu.lst sale entre otras cosas:
En un servidor Fedora Core 5, que hace de Proxy, quiero darle tambien el servicio de Web, pero, me encontre con el inconveniente que tengo una regla que direcciono todo el port 80 al 8080, por lo tanto la web local del proxy no funcionaba hasta que en la misma regla incluí un -d ! proxy y todo de maravillas.
Alpine es una herramienta desarrollada por la Universidad de Washington que permite consultar noticias y el correo electrónico desde un terminal. En esta receta se describen los pasos necesarios para configurar tu cuenta Gmail.
Como bien sabéis la creación de tablas en latex es una tarea un tanto tediosa y, en algunas ocasiones, desesperante (sobre todo si la estructura de la tabla se escapa un poco de lo cotidiano); nada que ver con la construcción de tablas en aplicaciones como OpenOffice Writer donde existen herramientas que facilitan esta tarea enormemente.
Existe una forma muy sencilla de sincronizar el calendario de Gnome que aparece en la parte superior derecha del escritorio con los calendarios de Google Calendar.
El objetivo principal de este mini tutorial es describir cómo podemos cargar código HTML de forma dinámica con el objeto XMLHttpRequest; todo ello sin necesidad de que la página recargue todo su contenido. No me centraré en hablar sobre AJAX ya que hay multitud de páginas que hablan sobre ello.
Veamos un ejemplo en el que disponemos de un menú con tres enlaces y una zona central donde se muestran los contenidos (dependiendo de la pestaña o enlace que pulse el usuario se mostrará un contenido u otro). Aunque visualmente dé la sensación de que la página no se recarga, con el objeto XMLHttpRequest podemos realizar peticiones en segundo plano al servidor. En primer lugar debemos crear el objeto XMLHttpResquest; su creación varía en función del navegador en uso:
<scriptlanguage=”javascript”>varxmlhttp=false;try{//comprobamos si es IExmlhttp=newActiveXObject("Msxml2.XMLHTTP");}catch(e){try{xmlhttp=newActiveXObject("Microsoft.XMLHTTP");}catch(e){xmlhttp=false;}}if(!xmlhttp&&typeofXMLHttpRequest!='undefined'){xmlhttp=newXMLHttpRequest();}</script>
Una vez que el objeto XMLHttpResquest ha sido creado, podemos comenzar a trabajar con él para realizar peticiones al servidor. Para este ejemplo, antes de utilizarlo, necesitamos otra serie de ingredientes para completar la receta, como son el menú desplegable con los diferentes enlaces y la capa donde se cargará el contenido de forma dinámica.
Creación del menú:
Es muy importante que cuando creemos el menú le asociemos un nombre y sobre todo un identificador (id), ya que será necesario para recuperar su valor desde javascript. También asociamos al menú el evento onchange, de tal forma que, cuando cambie su estado (se seleccione una opción diferente) se produzca la llamada a una función, en este caso la hemos denominado cambiaTexto().
Creación de la capa donde se cargará el contenido de forma dinámica:
Al igual que ocurría con el menú, también es necesario asociar un identificador para la capa (creada con la etiqueta
). Una vez que tenemos los ingredientes preparados ya podemos implementar la función en código JavaScript que se encargará de variar el contenido de la capa utilizando el objeto XMLHttpRequest.
Función cambiaTexto():
Para poder manipular el menú y la capa creada con código HTML, utilizamos la función getElementById. El valor actual del menú contendrá el enlace de la página que hemos elegido menu.value. Por tanto, podemos hacer la petición del contenido de dicha página con el objeto xmlhttp y la función open. Además, podemos apreciar que en este ejemplo hemos realizado la petición con el método GET, pero es importante saber que no es la única forma, ya que existe varios métodos: GET, POST, HEAD, DELETE, TRACE, OPTIONS y CONNECT.
Finalmente, cuando la petición es satisfecha podemos cargar el contenido que ha sido solicitado en la capa (capa.innerHTML = xmlhttp.responseText)
Como hemos podido apreciar en este breve tutorial, AJAX se basa principalmente en el uso del objeto XMLHttpResquest. Además, se ha descrito cómo cargar en una capa contenido html de forma dinámica sin recargar todo el contenido de la página principal. Por otra parte, también podemos destacar que la combinación de AJAX y PHP es sencilla y de gran utilidad; en este ejemplo, hemos utilizado el objeto XMLHttpResquest para solicitar páginas html pero, de la misma forma, podríamos haber solicitado páginas PHP que accedan a una base de datos, recuperar información y construir código HTML de forma dinámica. El uso de AJAX cobra sentido cuando tenemos la intención de crear aplicaciones web similares a las aplicaciones de escritorio.
Referencias
Introducción a AJAX con PHP. Babin, Lee (Ed. Anaya Multimedia). 2005.
En esta receta intentaré explicar los pasos que he seguido para instalar ubuntu 8.04 LST y que funcione todo correctamente en un airis kira 300. Los airis kira son portátiles de bajo coste con 7 pulgadas de pantalla que salieron hace poco tiempo al mercado http://www.airiskira.com/es/index.html. Cuando pides uno de estos ordenadores, tienes la posibilidad de solicitarlo con windows xp o bien una versión de linpus preinstalada, pero esto no quiere decir que otras distribuciones puedan funcionar a las mil maravillas.
La primera piedra que encontramos en el camino es que el portátil carece de unidad de DVD o CD, por tanto, para instalar una nueva distribución necesitaremos una unidad externa o bien instalarla desde una memoria usb. Si finalmente optamos por esta última opción, en
http://www.pendrivelinux.com/2008/05/15/usb-ubuntu-804-persistent-install-from-linux/
se explica paso a paso cómo preparar una imagen de ubuntu en una memoria usb para poder instalarla en cualquier ordenador. Una vez que tengamos ubuntu (o cualquier otra distribución) instalada en nuestra memoria usb, el siguiente paso es conectarla a nuestro portátil y proceder a la instalación (es posible que necesites especificar en la bios que arranque desde el usb). La instalación de ubuntu es tan sencilla como ir siguiendo los pasos que nos indica el proceso de instalación. Después de instalar el sistema hay unas cuantas cosillas que aún no funcionan:
- Wifi.
- Lector de tarjetas.
- La tarjerta de vídeo no tiene el mejor rendimiento ni la mejor resolución.
- Tampoco funciona la salida VGA.
- No monta correctamente los dispositivos usb.
Para solucionar estos problemas vayamos por partes (como diría Jack el destripador).
1º) Para solucionar el problema de la wifi, lector de tarjetas y dispositivos usb seguí la siguiente guía:
http://foro.airiskira.com/trucos-guias-y-manuales-f11/conseguir-que-funcione-todo-en-ubuntu-t292.htm
Una vez que descargas el kernel para el airis kira: http://service.one.de/download/index.php?&direction=0&order=&directory=NOTEBOOKS/ONE_A1xx/Linux%20Drivers/Binary-driver/Kernel
1) Metemos el archivo bzImage en /boot
2) Descomprimimos el archivo modules.tgz en /lib/modules
3) Editamos el archivo /boot/grub/menu.lst y añadimos las siguientes líneas:
title Kernel para el Kira
root (hd0,0)
kernel /boot/bzImage root=/dev/hdc1 ro locale=es_ES lang=es
4) Editamos el archivo /etc/modules y añadimos la siguientes líneas:
r8187
vcrdrm
vmsc
2º) Instalar el driver de la tarjeta gráfica. Lo descargamos de la siguiente página:
http://linux.via.com.tw/support/downloadFiles.action , elegimos Ubuntu 8.04 LST y CX700M/VX700 y descargarmos la versión unichrome.83.40692 (2.8M).
Para instalarlo es muy sencillo, ejecutamos como super usuario:
$./vinstall
Finalmente, sustituimos el archivo /etc/X11/xorg.conf por este otro:
Con esto tenemos solucionado el problema de la tarjeta gráfica y la salida VGA. Me imagino que tras seguir estos pasos, la resolución por defecto será 800x480 que es, desde mi punto de vista, con la que mejor se ve la pantalla. Aún así podrás elegir de forma manual desde gnome aquella que más te guste.
El único problema que no he conseguido solucionar todavía es que la luz de la wifi luce constantemente, a pesar de que se desactive. Si consigo solucionarlo editaré la receta para compartir la solución.
Os dejo aquí un Wallpaper hecho con Blender 2.42.
La figura del Gnu fue esculpida por Ana María Leal, posteriormete fue escaneada en tres dimensiones con el escaner del Grupo ISA aquí en la escuela, para importarlo posteriormete a la escena en Blender. Enlace
Hola buenas, me acabo de registrar, porque me parecen interesantes los temas que se tratan aqui, y me gustaria que me guiaseis un poco, de hecho no se si esto lo estoy escribiendo en el lugar que deberia. Me acabo de instalar gnesis y me surgen un monton de dudas, que espero resolver, leyendo manuales y preguntas de otros usuarios, y si no lo consigo resolver, preguntare, ¿es asi como funciona no?, bueno pues lo dicho. Salu2
alguien por ahi me puede recomendar un buen convertidor de video? especificamente que convierta de AVI a MPG.
y si tiene tiempo limitado, les agradeceria que me indiquen como crackearlo. Gracias!!
que tal! tengo un problema al intentar acceder a algunas paginas webs. Me piden que debo instalar el "control ActiveX: Adobe Flash Player 9"; clickeo para proceder a instalar, pero no se me permite. una de esas paginas webs, por ejemplo, es: http://www.canalfx.tv/pe/
Gracias por la ayuda...
Tengo instalado el linux que venia con el dvd de la escula de este año y no se como darle los permisos necesarios para poder copiar y pegar en la carpetas, es decir para poder pasar el simpleScalar a usr/local. Muchas gracias por vuestra ayuda
Supongamos que tenemos 60 archivos con nombres “ficheroXXX.JPEG” y queremos cambiarles el nombre a todos para que queden “ficheroXXX.jpg” (XXX quiere decir tres dígitos cualquiera; cualquier otro significado de XXX será pura coincidencia :-) Se puede escribir un comando shell que busque todos los archivos y les cambie el nombre uno a uno. Pero más fácil aún es usar el programa mmv que viene en el paquete mmv de Debian.
Navegando por la red me he encontrado este par de vídeos que me parecen muy interesantes, considerando que por aquí hay muchos amantes de los patrones de diseño y del lenguaje de programación Python.
Esta receta explica como configurar GNU Emacs para poder enviar emails desde cuentas de Gmail.
Introducción
Si eres un Emacs-adicto, te interesa enviar un e-mail de forma rápida mientras usas tu emacs o simplemente quieres ser un poco más geek, nada mejor que Emacs.
Ingredientes
starttls – TLS encryption helper program
Configurar Emacs
Tienes que tener instalado el paquete starttls ya que Gmail utiliza TLS para el envío de emails. Después, lo único que queda es configurar tu Emacs. Para ello, abre el archivo . emacs (que se encuentra en tu home).
Simplemente pon tu dirección de correo en lugar de “direccion@gmail.com”. si quieres que al enviar un email Emacs no te pida tu password puedes cambiar el campo nil que está a continuación de “direccion@gmail.com” y poner en su lugar tu password.
Tips & Tricks Email Emacs
Entrar en el modo email de Emacs: C-x m Modo email en una nueva ventana: C-x 4 m Modo email en un nuevo frame: C-x 5 m Revisar la ortografía del e-mail: M-x ispell-message Adjuntar un archivo: C-c C-i file RET Enviar el e-mail: C-c C-s Enviar el e-mail y salir del buffer: C-c C-c
Se puede hacer mucho más, como crear alias para las direcciones de correo, saltar a un campo concreto del mail, incluir la firma… para todo ello, como siempre lo mejor es echar un vistazo a la documentación de
La siguiente receta explica con un ejemplo como construir un analizador léxico con JFlex y un analizador sintáctico y semántico con CUP (obviamente para Java). Además, muestra el uso de producciones de error.
Requisitos
jflex - analizador léxico para Java
cup - analizador sintáctico/semántico LALR para Java
Construcción
El ejemplo consiste en un conversor de unidades métricas. Admitiría textos de entradas del siguiente tipo:
Entrada.txt
Km 1 mm;
dm 3 dm;
Hm 393 m;
Dm 54 cm, mm 3429 dm;
Km 23 Dm;
dm 322 cm, Hm 0923 mm;
y devuelve en consola:
1 Km son 1000000 mm;
3 dm son 3 dm;
393 Hm son 39300 m;
...
Un archivo flex tiene la siguiente estructura (cada sección se separa mediante %%) :
Código de usuario
Opciones y declaraciones
Reglas léxicas
Conversor.lex
//* ------------Sección codigo-usuario -------- */
import java_cup.runtime.*;
%%
/*- Sección de opciones y declaraciones -*/
/*-OPCIONES --*/
/* Nombre de la clase generada para el analizador lexico */
%class conversor
/* Indicar funcionamiento autonomo*/
%standalone
%8bit
/* Acceso a la columna y fila actual de analisis CUP */
%line
%column
/* Habilitar la compatibilidad con el interfaz CUP para el generador sintactico*/
%cup
/*-- DECLARACIONES --*/
%{/*Crear un nuevo objeto java_cup.runtime.Symbol con información sobre el token actual sin valor*/
private Symbol symbol(int type){
return new Symbol(type,yyline,yycolumn);
}
/* Crear un nuevo objeto java_cup.runtime.Symbol con información sobre el token actual con valor*/
private Symbol symbol(int type,Object value){
return new Symbol(type,yyline,yycolumn,value);
}
%}
/*-- MACRO DECLARACIONES --*/
LineTerminator = \r|\n|\r\n
WhiteSpace = {LineTerminator} | [ \t\f]
//finConversion = [,;]
num_int = [0-9]+
%%
/*-------- Sección de reglas lexicas ------ */
<YYINITIAL> {
//{finConversion}{ return symbol.FCONVERSION}
"," { return symbol(sym.COMA);}
";" { return symbol(sym.PUNTOCOMA);}
"mm" { return symbol(sym.MM); }
"cm" { return symbol(sym.CM); }
"dm" { return symbol(sym.DCM); }
"m" { return symbol(sym.M); }
"Dm" { return symbol(sym.DCAM); }
"Hm" { return symbol(sym.HM); }
"Km" { return symbol(sym.KM); }
{num_int} { return symbol(sym.NUMBER, new Integer(yytext())); }
{WhiteSpace} { }
. {System.out.println("token ilegal <" + yytext()+ ">  linea: " + (yyline+1) + " columna: " + (yycolumn+1));}
}
En cuanto a un fichero CUP se pueden diferenciar cinco partes:
Especificaciones de “package” e “imports”.
Componentes de código de usuario.
Lista de símbolos de la gramática(terminalesno terminales).
Declaraciones de precedencia.
Especificación de la gramática.
Conversor.cup
/*Sección de declaraciones package e imports*/
import java_cup.runtime.*;
/* Sección componentes de código de usuario */
parser code {:
public void report_error(String message, Object info) {
StringBuffer m = new StringBuffer("Error");
System.out.println("Mensaje: "+message);
System.out.println("info: "+info.toString());
if(info instanceof java_cup.runtime.Symbol) {
java_cup.runtime.Symbol s=((java_cup.runtime.Symbol)info);
/* Comprueba si el numero de línea es mayor o igual que cero */
if(s.left >= 0) {
m.append(" en linea "+(s.left+1));
/*Comprueba si el numero de columna es mayoro igual que cero */
if (s.right >= 0)
m.append(", y columna "+(s.right+1));
}
}
m.append(" : "+message);
System.err.println(m);
}
public void report_fatal_error(String message, Object info) {
report_error(message, info);
System.exit(1);
}
public void conversion(String a, String b, int n){
int c=0,d=0;
System.out.print(n+" ");
if (a=="Km"){ c=6; System.out.print("Km"); }
else if (a=="Hm"){ c=5; System.out.print("Hm"); }
else if (a=="Dm"){ c=4; System.out.print("Dm"); }
else if (a=="m"){ c=3; System.out.print("m"); }
else if (a=="dm"){ c=2; System.out.print("dm"); }
else if (a=="cm"){ c=1; System.out.print("cm"); }
else if (a=="mm"){ c=0; System.out.print("mm"); }
if (b=="Km") d=6;
else if (b=="Hm") d=5;
else if (b=="Dm") d=4;
else if (b=="m") d=3;
else if (b=="dm") d=2;
else if (b=="cm") d=1;
else if (b=="mm") d=0;
System.out.print(" son "+n*Math.pow(10,c-d)+" ");
}
:};
/* Declaración de la lista de símbolos de la gramática */
/* Produciones de flujo normal */
terminal COMA, PUNTOCOMA, MM, DCM, CM, M, DCAM, HM, KM;
terminal Integer NUMBER;
non terminal Object programa, linea, expresiones, medida;
/* Declaración de la gramática */
programa ::= programa linea | linea;
linea ::= error NUMBER medida PUNTOCOMA {: parser.report_error("revise la sintaxis",null); :} |
medida:m1 NUMBER:n medida:m2 PUNTOCOMA {: parser.conversion(m1.toString(),m2.toString(),n.intValue());
System.out.println(m2); :} |
expresiones medida:m1 NUMBER:n medida:m2 PUNTOCOMA
{: parser.conversion(m1.toString(),m2.toString(),n.intValue());
System.out.println(m2); :} ;
expresiones ::= expresiones medida:m1 NUMBER:n medida:m2 COMA
{: parser.conversion(m1.toString(),m2.toString(),n.intValue());
System.out.println(m2); :} |
medida:m1 NUMBER:n medida:m2 COMA {: parser.conversion(m1.toString(),m2.toString(),n.intValue());
System.out.println(m2); :} |
error NUMBER medida COMA {: parser.report_error("revise las medidas en mayusculas",null); :};
medida ::= KM {: RESULT="Km"; :} | HM {: RESULT="Hm"; :} | DCAM {: RESULT="Dm"; :} |
M {: RESULT="m"; :} | DCM {: RESULT="dm"; :} |
CM {: RESULT="cm"; :} | MM {: RESULT="mm"; :};
Necesitas un fichero que cree un objeto parser y comience el análisis.
Main.java
Hace ya 5 días, que se publicó la noticia, pero yo me he enterado hoy. Debido a los problemas legales de Gaim con AOL y AIM, Gaim cambia de nombre, así como algunas de sus librerías. El nuevo nombre será Pidgin; que tiene significado, es dicho de forma llana, como una nueva lengua creada de mezclar dos, no algo del estilo de Chiquito de La Calzada, sino algo así como cuando vamos a un país extranjero y traducimos literalmente cambiando las palabras de nuestro idioma y ponemos la palabra extranjera.
Recetilla de como migrar tu home a otra partición.
Ingredientes
Espacio en disco duro.
Migración
Primeramente, tienes que tener la partición donde quieres colocar el home con el sistema de ficheros adecuado en cada caso(ext2 o ext3). Es importante que te asegures del nombre del dispositivo. Bien, para hacer esto, teclea lo siguiente en el terminal como root:
$mkfs.ext3 /dev/X
Donde en este ejemplo tu sistema de ficheros debería ser extended3 y donde X es el nombre de partición donde quieres poner tu nuevo home(válido para toda la receta).
Si lo quieres hacer en modo gráfico, puedes instalar gparted.
Ahora, crea un directorio en /mnt/ y monta la partición allí:
$mkdir /mnt/nuevo
$mount /dev/X /mnt/nuevo
El siguiente paso es entrar en modo mono usuario. Para realizar esto:
$init 1
De este modo entras en el mantenimiento del sistema, se te pedirá la contraseña de root, tecleala y ya puedes ir a tu home y copiar a la nueva partición:
$cd /home
$cp -ax * /mnt/nuevo
En mi caso, tenía el home en una partición compartida. Si también es el tuyo para guardar el antiguo home por precaución y montar el nuevo home, tienes que hacer lo siguiente:
Ya puedes salir del modo monousuario, presionando CTRL+D
Por último modificar el fstab para que la próxima vez que inicies el sistema el home se monte de forma correcta:
$gedit /etc/fstab
Introduce una línea con la información del nuevo sistema de ficheros, por ejemplo:
¿Os imagináis el logo de Orange, Epson o Panrico en la web de un evento oficial? Para mi gusto falta un mensajillo de “M$ patrocina estas elecciones”. Buena muestra de la neutralidad tecnológica (a la española).
Hola buenas... soy más o menos nuevo en CrySol aunque ya llevo un tiempo en esto del GNU. En primer lugar felicitaros por el portal... creo que es de los pocos que no son un asqueroso "grupo de usuarios de LINUX de nosequé". Como imaginaréis ODIO el LINUX... me parece un núcleo con un diseño arcaico, de los tiempos del MS-DOS. Hasta los WINDOW$ tienen núcleos con mejores diseños que éste. No hablemos ya del Linu$ Torvald$, en mi opinión ese tipo es una sanguijuela del GNU pero bueno... Ahora vienen los de GNU y sacan su GPLv3 maravillosa que intentará luchar contra el DRM. Micro$oft sacará sus windoze$ con DRM, como Linu$ ha dicho que "no adoptará la postura de los radicales de GNU y Linux no asumirá la licencia GPLv3" podremos tener sistemas basados en dicho kernel que utilicen DRM. Pues bien, teniendo un LinuxDRM y un WindozeDRM... ¿qué más dará usar GNU/Windows que GNU/Linux?. Vale que al principio, para meter aplicaciones GNU en un windowze hace falta tener un calzador... pero una vez que está todo metido y bien metido, ¿la harmonía no es la misma? además nos ahorraríamos problemas de funcionamiento de hardware nuevo (y tener que estar buscando el chipset de nuestro HW porque los cutre-fabricante$ que tenemos nos ignoran abiertamente).
hola a todos, soy nuevo en esta pagina y la encontre muy buena, mi pregunta, es que estoy tratando de desarrollar un LOAP (Linux Open Access Point), con un hardware reciclado que encontrado en algunos lados o me han regalado.
Las redes neuronales, hoy por hoy, son algo novedoso que se está implementando dentro del ordenador de consumo gracias a la biomimética. Por qué copiar a la naturaleza y tratar de emular a nuestro cerebro con neuronas de rata de laboratorio y no encaminarse en otras vías.
Suponiendo que acabáis de instalar una Debian o que, aunque ya la tenías funcionando, w8 ha hecho de las suyas, os veis en una situación en la que no tenéis grub y lo que es peor, ni siquiera podéis arrancar vuestra Debian desde el menú de arranque. En este caso, lo que hay que hacer es lo siguiente:
Si habéis adquirido un nuevo equipo que venga con Windows 8 preinstalado habréis podido comprobar que aunque la instalación de vuestra debian se realiza sin problema, incluída la instalación del grub, a la hora de arrancar el grub éste no aparece.
Un año más, con idea de introducir a los alumnos de primero en el mundo del Software Libre, os invitamos a participar en la Install Party que tendrá lugar los días 6 y 7 de marzo. Viernes tarde y sábado mañana.
Si ya podemos conectar nuestra NDS a “la Fonera” ¿por qué no utilizar esa conexión para hacer algo más? Podemos hacer llamadas por VoIP a números fijos, sin ningún coste, y lo mejor de todo, DESDENUESTRANDS! gracias a SVSIP.
Los nuevos portátiles ahtec vienen con tarjetas de sonido Intel con chipset Realtek, el problema es que aunque no te encuentras con ningún problema en la configuración de ALSA a la hora de la verdad no se reproduce ningún sonido.
A todos nos ha pasado alguna vez cuando intentamos compilar algo, encontrarnos con errores del tipo: No existe el fichero o el directorio. Algunas veces, encontrar el paquete que contiene ese .h puede ser toda una odisea, pero hoy me he encontrado con una maravillosa herramienta: apt-file.
Instalación
Con sólo tres comandos, estos problemas pasarán a mejor vida, la instalación y configuración la hacemos en dos pasos. Instalación:
#apt-get install apt-file
Y ahora actualizamos la base de datos, para poder llevar a cabo las búsquedas correctamente.
#apt-file update
Uso
Para devolver la lista con todos los paquetes que contienen este archivo:
$apt-file search nombre_del_fichero
Si queremos la lista de todos los archivos que contiene el paquete:
Supongo que vosotros ya lo sabréis, pero lo he leído hoy y lo pongo aquí por si alguien no lo sabe. Parece que la Consejería de Industria y Sociedad de la Información impartirá durante el curso 2007/2008 formación avanzada Molinux, el software libre de Castilla-La Mancha, a los alumnos de la Escuela Politécnica de Cuenca y de la Escuela Superior de Informática de Ciudad Real.
os informo de la celebración de las I Jornadas sobre Piratería de la UCLM, que se van a celebrar en la Facultad de Letras de Ciudad Real del 26 al 29 de marzo. Si sois alumnos y queréis inscribiros, la inscripción es totalmente gratuita y por la asistencia a las jornadas se os va a dar 1.5 créditos de libre configuración
Queda algún q otro detallito por cerrar perotdo lo básico ya está confirmado. Tengo que agradecer la ayuda de gente de CRySoL (David Villa, Fernando Rincón, Cleto Martín…), tanto para presentar a los ponentes como para participar ellos mismos en un encuentro con el colectivo.
Suelo usar la consola embebida, si se puede llamar así, dentro de emacs. Es muy útil porque me permite ejecutar scripts, y realizar numerosas tareas sin salir de emacs. El problema es que cuando se requieren tareas como root, al teclear la contraseña dentro de emacs, ésta se visualiza explícitamente. Para que salgan asteriscos que la oculten hay que incluir en el .emacs lo siguiente:
Hola, me gustaria que me aconsejarais una makina virtual para instalar en mi pc con ubuntu, estilo Virtualpc que me deje ejecutar programas de windows sobre esta distro. Lo que mas me interesaría es montarle varios AV para crear mi propio laboratorio de firmas, para ejecutar sobre mi pc con ubuntu los .exe de win, al igual que los AV.Alguién que me eche un cable con esto??
Gracias. Saludos.
Hola, como dije cuando me presenté, no soy un experto de gnu/linux. Llevo unos meses utilizando ubuntu, la verdad es que no me ha dado problemas, pero hace unos días recibí la última versión de molinux, y decidí partir el disco e instalar en una mitad ubuntu y la otra mitad molinux (creo que fue una estupidez y que finalmente borraré uno de ello ya que son casi iguales, para lo que también pido ayuda, ya que no se como se hace, he de reconocer que tampoco he googleado sobre esto, asi que me pondré a ello). Bueno el caso es que antes de decantarme y elegir he decidido instalar algunos programas en molinux, como el aircrack o wireshack (que conste que es cuestión de auditoria :p) o a borrar los tipicos juegos. Bien, para lo primero me dice:
Hola, no he visto nada de Molinux Adarga 4.0 por aquí, aunque supongo que la mayoría de los miembros de la comunidad ya lo conocen. Pero siempre quedará gente que no esté informada sobre éste (como era mi caso hasta hace 4 días).
Hola abro este blog para presentarme y comunicaros mis felicitaciones ya que desconocia que en Ciudad Real existiese una comunidad de este tipo. Yo la verdad es que no soy para nada un genio en GNU (hace solo un tiempo que trasteo con ubuntu) pero me gusta aprender. Mis conocimientos de informatica y programación no soy tampoco muy bastos, ya que no he estudiado nunca informatica, sólo como aficción y por mi cuenta. Lo que me a dado la posibilidad de saber sobre auditoria de redes, tener mi propio servidor web bajo un xp y aprendí también algo de vb y algo más. Mi intención al llegar aquí es aprender de los que realmente sabeis y con el tiempo aportar yo algo también.
Buenas hace poco que he instalado linux en mi portatil y realmente es la 1º vez que lo utilizo por lo que no tengo ni idea de como manejarlo. Concretamente tengo la distribucion Ubunto y la version 7.04
Mi problema reside en que emacs no me compila. Yo escribo cualquier programa en C, y desde tool le doy a compile. Y me dice que: "no hay ninguna regla para construir el objetivo ".
Saludos a Todos..
Estoy buscado procedimiento que permita de una maquina fisica que tenga instalada centos o otra distribucion de linux que me permita virtualizara, Y poderla importa a Xenserver. Ademas el procedimiento de instalar lo xentools..
Saludos
Wilson
A continuación os propongo el codigo de un pequeño WATCHDOG: Yo por ejemplo lo uso para tener mi aMule siempre funcionando, ya que suele cascar amenudo.
Soy muy nueva en esto y no se si estoy en el sitio adecuado,agradeceria mucho si alguien pudiera ayudarme.Mi pc da pantallazos y segun el sondeo que he podido hacer Atheros me da problemas.Si lo desabilito no hay error.Pero tengo una LAN en casa y quiero que funcione todo bien.Si podeis ayudarme...GRACIAS
¡Buenas a todos!
Hace una eternidad que no escribo nada (tampoco es que hubiese escrito mucho) pero bueno, simplemente quería comentar una curiosidad que me ha pasado esta misma semana aquí en la universidad de Chalmers (Gotemburgo, Suecia).
A día de hoy es común que una persona tenga a su disposición dos ordenadores: un portátil y un sobremesa en casa. Con esta receta veremos cómo sincronizar el sobremesa de casa con nuestro portátil para o bien traer ficheros que estén en el sobremesa a nuestro portátil o bien hacer copias de seguridad del portátil al sobremesa, estemos donde estemos.
Hola, soy nuevo en Crysol y me gustaría saber si se pueden hacer preguntas de tipo "mantenimiento/problemas". Soy usuario de Ubuntu y no encuentro solución a un problema que tengo, por más que busco, lo que me hace imposible seguir con él. No busco soluciones fáciles, me gustaría saber por qué pasa lo que pasa, aprender e ir explotando un poco más mi máquina. Por eso antes de hacer perder el tiempo a nadie, agradecería que se me informase de que se puede y que no se puede (debe).
Hola soy nueva en esto; estoy intentando ser usuaria de debian linux y voy despacio. Ahora he encontrado problemas para conectarme a Internet mediante red inalámbrica de ADSL de Telefónica. Tengo un modem Xavi 7968, he instalado el wicd y me reconoce la red inalámbrica pero cuando busca la IP me da Fallo de conexión: incapaz de obtener una dirección IP. En Telefónica no hay soporte para Linux (que ya les vale, claro) y estoy empezando a desesperarme. Si alguien me puede ayudar lo agradecería.
Soy nuevo en gstreamer; segui el tutorial para "crear tu propio reproductor multimedia en minutos", hice también aun archivo *.ogv con el gtk-RecordMyDesktop, pero al momento de correr el programa desde la consola, auque no me muestra ningún error, tampoco me ejecuta el video, me hará falta algún plugin?
Gracias por la ayuda
Con esta receta dejaremos la carga de decodificar el vídeo a la GPU, con lo que notaremos una gran mejoría en la fluidez de reproducción del vídeo y una descarga de trabajo en la CPU.
Buenas,he adquirido una tablet "WonderMedia wm8650" tiene 800Mhz el procesador,su propio nombre lo indica wm8650 tiene 256 MB de ram y es de 7"
Tiene Android 2.2, el caso es, que me voy a calendario,creo una nueva cita y a intentar añadir me dice "No hay calendario"
He sincronizado con Gmail calendar ese...ect y se me resiste.
¿Ideas?
Buenas,estoy buscando un filtro contenidos vía web o algo derribado para la empresa de mi tío,quiere restringir las páginas de redes sociales..ect
El caso es,que tan solo conozco el OpenDns,pero quiero alguno más eficaz y seguro o algo,claramente que sea GPL :)
Buenas,hace tiempo pensé en un proyecto;Crear un Software HelpDesk totalmente creado desde 0 con licencia GPL,pero demasiadas comunidades ese proyecto existen ya,asique reflexionando durante este tiempo,diversos cambios de s.o...etc
Buenas crysoleros,antes de empezar quiero dar la enhorabuena a todos los componentes,por su maravillosa organización el día del software libre cuando asistió R.stallman,no pude asistir anteriores por falta de transporte y estudios,pero aquí estaba la ansiosa y esperada foto http://arco.esi.uclm.es/~cleto.martin/fotos_jornadas/IMG_4103_900x677.html que muchas gracias por publicarla bueno,al grano;
¿Alguien sabe donde han publicado la foto que se realizo en el "Hall" (Gracias oscarah por corregirmelo,no sabía como se escribia) ?
un saludo crysoleros y me pongo vuestra camiseta de las jornadas con orgullo ^^
In this article a scheme with one device Cisco Catalyst 3550-12T1 that combines the functions of both a switch and an IGMP querier is described. Catalyst 3550-12T switch has 10 Gigabit Ethernet ports and two ports for GBIC modules. Peak performance is 17 billion
packets per second that allows transmitting data at a 24 Gbps rate.
Configuring IGMP snooping and IGMP querier
It is required to have an IP address configured on the Vlan 1 interface of the switch:
!
interface Vlan1
ip address 10.1.2.247 255.255.0.0
!
IGMP snooping is enabled by using the command (in global configuration mode):
ip igmp snooping
IGMP querier is enabled by using the command (in global configuration mode):
ip igmp snooping querier
Testing
A stand on basis of Cisco Catalyst 3550-12T ( C3550-IPSERVICESK9-M, Version 12.2(40)SE ) and
NetUP DVB to IP gateway 2 was prepared by NetUP specialists. A general network scheme is
given in the figure 1 below. As the client equipment it was used a PC with vlc mediaplayer and
an IP set-top box AmiNET 130.
Fig. 1. General layout of the test stand.
IGMP snooping and IGMP querier were enabled as discussed above. To check this, one can
use the following commands (the output is provided):
c3550#show ip igmp snooping querier
Vlan IP Address IGMP Version Port
----------------------------------------------------------------
1 10.1.2.247 v2 Switch
c3550#show ip igmp snooping groups
Vlan Group Version Port List
------------------------------------------------------------
As it can be seen the switch operates as an IGMP querier. In the groups list there are
no groups as no subscriber has requested a multicast stream. In this case the average
data transfer rate on the client’s port equals 0 Mbps. To check this run the following
command:
At that on the port of NetUP DVB to IP gateway we can see data transfered
at the rate of 110-120 Mbps (full decoding of 4 transponders is performed
that is around 50 TV channels):
Due to IGMP snooping multicast packets are not coming to the client port. If the client
requests a TV channel, copied to his port are only those multicast packets that belong
to this TV channel. To check this let’s request a TV program on the client’s device:
vlc udp://@226.2.0.5:1234
The requested TV channel appears on the client’s TV screen. And on the switch in the groups list we can see a new record:
c3550#show ip igmp snooping groups
Vlan Group Version Port List
------------------------------------------------------------
1 226.2.0.5 v2 Gi0/2
As we can see from this record, the switch is copying multicast packets for the group 226.2.0.5 to
the client port (Gi0/2). To check this we can check the rate of data transfer to the client port:
As it can be seen, only one TV channel is being transfered to the client port at the rate of ~3 Mbps. Because of such behavior of the switch we avoid overloading the client’s port with unwanted multicast packets.
It is worth of noting that the CPU load of the switch is almost zero. Most likely
multicast packets are processed at the hardware level.
c3550#show processes cpu history
1111111111122222111111111111111111111111111111111111111111
100
90
80
70
60
50
40
30
20
10
0....5....1....1....2....2....3....3....4....4....5....5....
0 5 0 5 0 5 0 5 0 5
CPU% per second (last 60 seconds)
Important! According to “IPv4 Multicast Unusable Group And Source Addresses” 3 it is not recommended
to use certain ranges for IPv4 multicast addresses. For example, subnet 226.0.0.0 – 226.0.0.255. Cisco
Catalyst 3550-12T switch sends multicast packets to all ports regardless of client’s requests.
GHDL ( http://ghdl.free.fr/ ) es un simulador open-source para VHDL, que permite la compilación y ejecución del código VHDL directamente en PC. Otra característica avanzada es la capacidad de utilizar funciones C desde el código VHDL.
Hola, quería compartir con ustedes, la siguiente entrada de blog que encontré... en ella detalla los pasos para acelerar el emulador que usamos junto al eclipse, netbeans ... para testear nuestros programas, de manera que "acelerase" algo mas del 400% con respecto ahora. (En estos momentos podemos decir que el emulador es excesivamente lento y no se puede trabajar a un buen ritmo con el sin tener un dispositivo android de apoyo en el que probar las aplicaciones).
El proximo kernel de android 3.3, incluirá ciertas modificaciones que fueron retiradas en otros kernel y que solo incorporaba un kernel especifico de la rama del 2.6 (2.6.33). Esta modificación nos permitirá arrancar un sistema operativo con núcleo Linux, sin necesidad de hacer ninguna modificación adicional.
Esto es una receta rápida para configurar y empezar a usar ian, una pequeña aplicación que simplifica algunos de los problemas habituales con los que se enfrenta cualquier mantenedor de paquetes Debian.































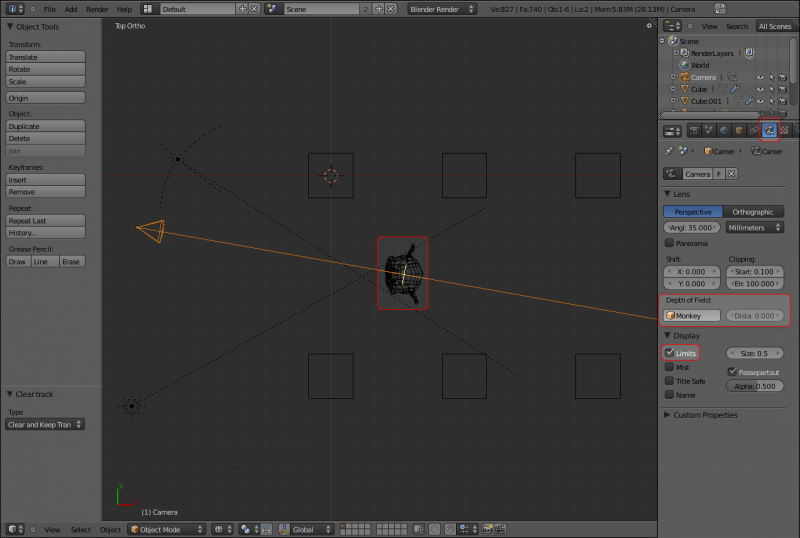
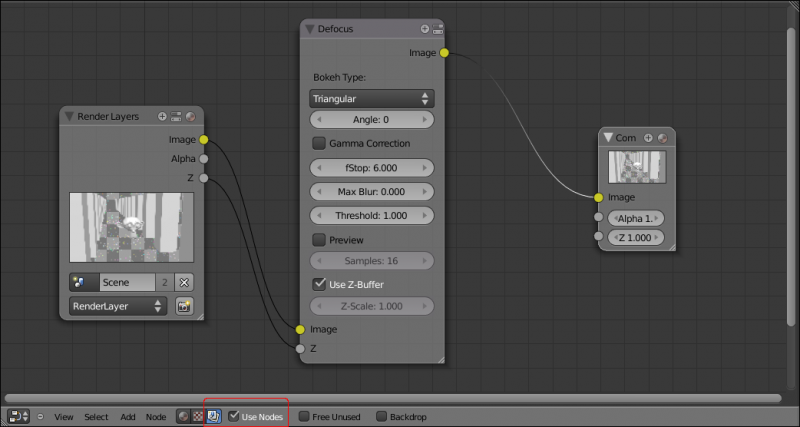



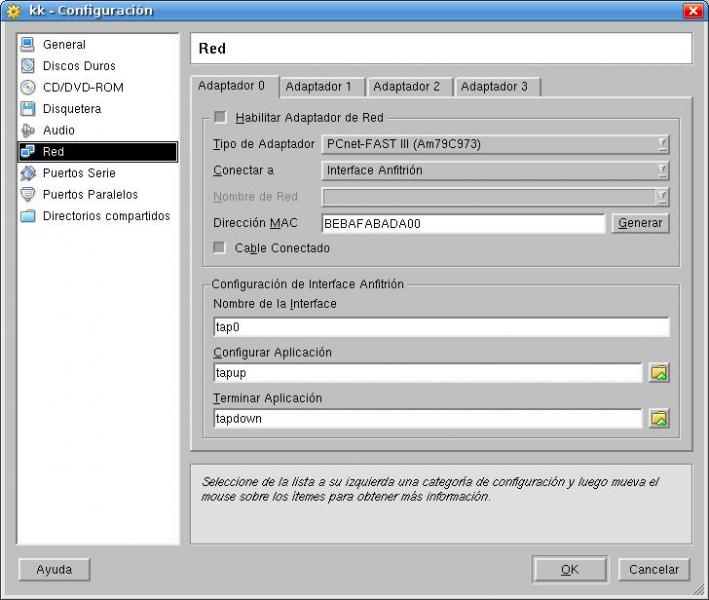
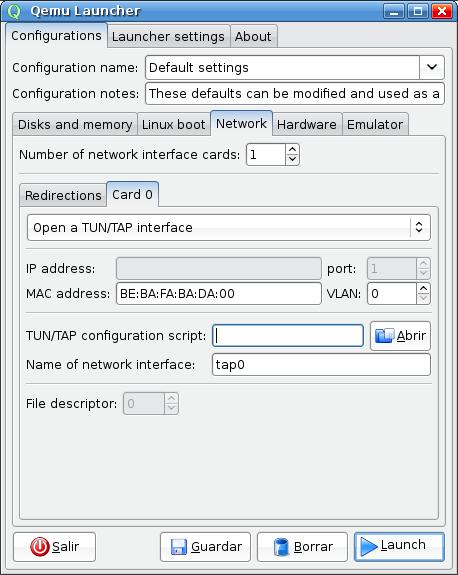
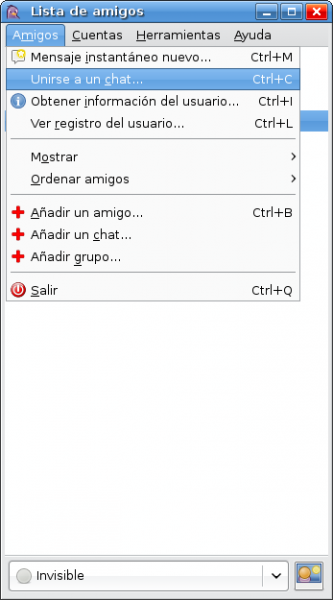
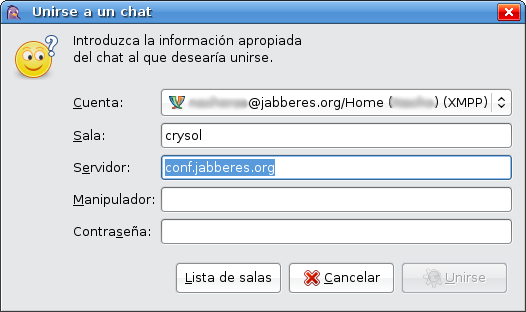
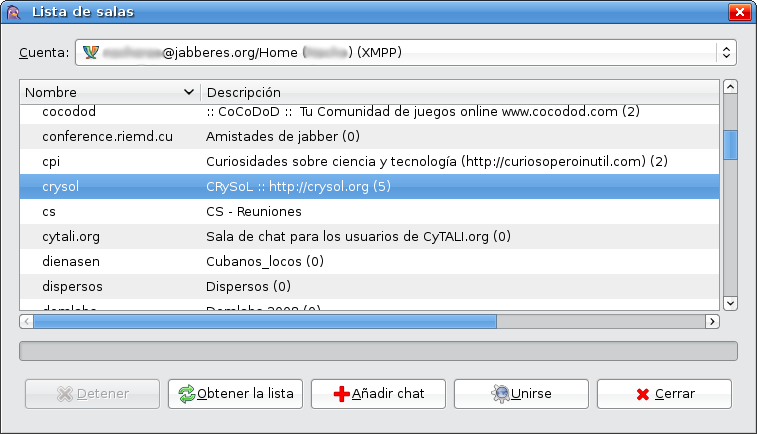
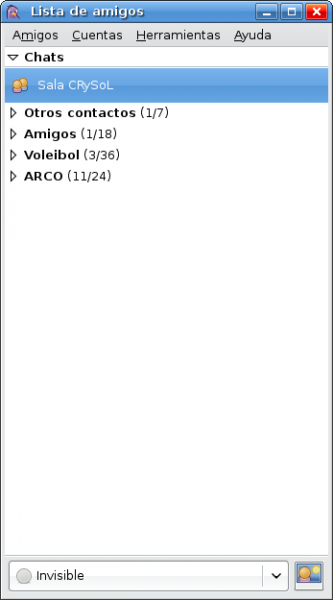













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}