|
11.2.2. Consejos para el paso de argumentos |

|
11.3.2. Construcción por copia |

|
Ahora que entiende lo básico de las referencias en C++, está
preparado para tratar uno de los conceptos más confusos del
lenguaje: el constructor de copia, a menudo denominado
X(X&) («X de la referencia
X»). Este constructor es esencial para controlar el paso
y retorno por valor de los tipos definidos por el usuario en las
llamadas a funciones. De hecho es tan importante que el
compilador crea automáticamente un constructor de copia en caso
de que el programador no lo proporcione.
Para entender la necesidad del constructor de copia, considere la forma en que C maneja el paso y retorno por valor de variables cuando se llama a una función. Si declara una función y la invoca,
int f(int x, char c); int g = f(a, b);
¿cómo sabe el compilador cómo pasar y retornar esas variables?
¡Simplemente lo sabe! El rango de tipos con los que debe
tratar es tan pequeño (char, int,
float, double, y sus variaciones),
que tal información ya está dentro del compilador.
Si averigua cómo hacer que su compilador genere código
ensamblador y determina qué instrucciones se usan para la
invocación de la función f(), obtendrá
algo equivalente a:
push b push a call f() add sp, 4 mov g, register a
Este código se ha simplificado para hacerlo genérico; las
expresiones b y a serán
diferentes dependiendo de si las variables son globales (en
cuyo caso serían _b y
_a) o locales (el compilador las pondría en
la pila). Esto también es cierto para g. La
sintaxis de la llamada a f() dependería
de su guía de estilo, y register a dependería de
cómo su ensamblador llama a los registros de la CPU. A pesar
de la simplificación, la lógica del código sería la misma.
Tanto en C como en C++, primero se ponen los argumentos en la
pila de derecha a izquierda, y luego se llama a la función. El
código de llamada es responsable de recoger los argumentos de
la pila (lo cual explica la sentencia add sp, 4).
Pero tenga en cuenta que cuando se pasan argumentos por valor,
el compilador simplemente pone copias en la pila (conoce los
tamaños de cada uno, por lo que los puede copiar).
El valor de retorno de f() se coloca en un
registro. Como el compilador sabe lo que se está retornando,
porque la información del tipo ya está en el lenguaje, puede
retornarlo colocándolo en un registro. En C, con tipos
primitivos, el simple hecho de copiar los bits del valor es
equivalente a copiar el objeto.
Considere ahora los tipos definidos por el usuario. Si crea una clase y desea pasar un objeto de esa clase por valor, ¿cómo sabe el compilador lo que tiene que hacer? La información de la clase no está en el compilador, pues lo ha definido el usuario.
Para investigar esto, puede empezar con una estructura simple que, claramente, es demasiado grande para ser devuelta a través de los registros:
//: C11:PassingBigStructures.cpp struct Big { char buf[100]; int i; long d; } B, B2; Big bigfun(Big b) { b.i = 100; // Do something to the argument return b; } int main() { B2 = bigfun(B); } ///:~
Listado 11.5. C11/PassingBigStructures.cpp
La conversión a código ensamblador es un poco más complicada
porque la mayoría de los compiladores utilizan funciones
«auxiliares»
(helper) en vez de inline. En
la función main(), la llamada a
bigfun() empieza como debe: se coloca
el contenido de B en la pila. (Aquí
podría ocurrir que algunos compiladores carguen registros
con la dirección y tamaño de Big y
luego una función auxiliar se encargue de colocar el
Big en la pila).
En el fragmento de código fuente anterior, lo único
necesario antes de llamar a la función es colocar los
argumentos en la pila. Sin embargo, en el código ensamblador
de PassingBigStructures.cpp se ve una
acción adicional: la dirección de B2 se
coloca en la pila antes de hacer la llamada a la función
aunque, obviamente, no sea un argumento. Para entender qué
pasa, necesita entender las restricciones del compilador
cuando llama a una función.
Cuando el compilador genera código para llamar a una
función, primero coloca en la pila todos los argumentos y
luego hace la llamada. Dentro de la función se genera código
para mover el puntero de pila hacia abajo, y así proporciona
memoria para las variables locales dentro de la función.
(«hacia abajo» es relativo, la máquina puede
incrementar o decrementar el puntero de pila al colocar un
argumento). Pero cuando se hace el CALL de
ensamblador para llamar a la función, la CPU coloca la
dirección desde la que se realiza la llamada, y en el
RETURN de ensamblador se utiliza esa dirección
para volver al punto desde donde se realizó la llamada. Esta
dirección es sagrada, porque sin ella el programa se
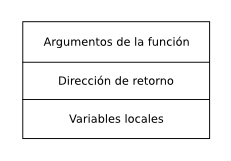
perdería por completo. He aquí es aspecto del marco de pila
después de ejecutar CALL y poner las variables
locales de la función:
El código generado por el resto de la función espera que la memoria tenga esta disposición para que pueda utilizar los argumentos y las variables locales sin tocar la dirección de retorno. Llámese a este bloque de memoria, que es todo lo que una función necesita cuando se la llama, el marco de la función (function frame).
Podría parecer razonable retornar valores mediante la utilización de la pila. El compilador simplemente los colocaría allí y la función devolvería un desplazamiento que indicara dónde empieza el valor de retorno.
Este problema ocurre porque las funciones en C y C++ pueden
sufrir interrupciones; esto es, los lenguajes han de ser (y
de hecho son) re-entrantes. También
permiten llamadas a funciones recursivas. Esto quiere decir
que en cualquier punto de ejecución de un programa puede
sufrir una interrupción sin que el programa se vea afectado
por ello. Obviamente la persona que escribe la rutina de
servicio de interrupciones (ISR) es responsable de guardar y
restaurar todos los registros que se utilicen en la
ISR. Pero si la ISR necesita utilizar la pila, ha de hacerlo
con seguridad. (Piense que una ISR es como una función
normal sin argumentos y con valor de retorno
void que guarda y restaura el estado de la
CPU. La ejecución de una ISR suele producirse por un evento
hardware, y no con una invocación dentro del programa de
forma explícita).
Ahora imagine que pasaría si una función normal intentara
retornar valores mediante la pila. No puede tocar la pila
por encima del la dirección de retorno, así que la función
tendría que colocar los valores de retorno debajo de la
dirección de retorno. Pero cuando se ejecuta el
RETURN, el puntero de pila debería estar
apuntando a la dirección de retorno (o justo debajo, depende
de la máquina), así que la función debe subir el puntero de
la pila, desechando todas las variables locales. Si intenta
retornar valores usando la pila por debajo de la dirección
de retorno, en ese momento es vulnerable a una
interrupción. La ISR escribiría encima de los valores de
retorno para colocar su dirección de retorno y sus
variables locales.
Para resolver este problema, el que llama a la función podría hacerse responsable de asignar la memoria extra en la pila para los valores de retorno antes de llamar a la función. Sin embargo, C no se diseñó de esta manera y C++ ha de ser compatible. Como verá pronto, el compilador de C++ utiliza un esquema más eficaz.
Otra idea sería retornar el valor utilizando un área de datos global, pero tampoco funcionaría. La re-entrada significa que cualquier función puede ser una rutina de interrupción para otra función, incluida la función que se está ejecutando. Por lo tanto, si coloca un valor de retorno en un área global, podría retornar a la misma función, lo cual sobreescribiría el valor de retorno. La misma lógica se aplica a la recursividad.
Los registros son el único lugar seguro para devolver
valores, así que se vuelve al problema de qué hacer cuando
los registros no son lo suficientemente grandes para
contener el valor de retorno. La respuesta es colocar la
dirección de la ubicación del valor de retorno en la pila
como uno de los argumentos de la función, y dejar que la
función copie la información que se devuelve directamente en
esa ubicación. Esto no solo soluciona todo los problemas, si
no que además es más eficaz. Ésta es la razón por la que el
compilador coloca la dirección de B2
antes de llamar a bigfun en la función
main() de
PassingBigStructures.cpp. Si viera el
código ensamblador de bigfun()
observaría que la función espera este argumento escondido y
lo copia al destino dentro de la
función.
Hasta aquí, todo bien. Tenemos un procedimiento para pasar y retornar estructuras simples grandes. Pero note que lo único que tiene es una manera de copiar bits de un lugar a otro, lo que ciertamente funciona bien para la forma (muy primitiva) en que C trata las variables. Sin embargo, en C++ los objetos pueden ser mucho más avanzados que un puñado de bits, pues tienen significado y, por lo tanto, puede que no responda bien al ser copiado.
Considere un ejemplo simple: una clase que conoce cuantos
objetos de un tipo existen en cualquier momento. En el Capítulo 10 se vio la manera de hacerlo
incluyendo un atributo estático (static):
//: C11:HowMany.cpp // A class that counts its objects #include <fstream> #include <string> using namespace std; ofstream out("HowMany.out"); class HowMany { static int objectCount; public: HowMany() { objectCount++; } static void print(const string& msg = "") { if(msg.size() != 0) out << msg << ": "; out << "objectCount = " << objectCount << endl; } ~HowMany() { objectCount--; print("~HowMany()"); } }; int HowMany::objectCount = 0; // Pass and return BY VALUE: HowMany f(HowMany x) { x.print("x argument inside f()"); return x; } int main() { HowMany h; HowMany::print("after construction of h"); HowMany h2 = f(h); HowMany::print("after call to f()"); } ///:~
Listado 11.6. C11/HowMany.cpp
La clase HowMany contiene un entero
estático llamado objectCount y un método
estático llamado print() para
representar el valor de objectCount,
junto con argumento de mensaje opcional. El constructor
incrementa objectCount cada vez que se
crea un objeto, y el destructor lo disminuye.
Sin embargo la salida no es la que cabría esperar:
after construction of h: objectCount = 1 x argument inside f(): objectCount = 1 ~HowMany(): objectCount = 0 after call to f(): objectCount = 0 ~HowMany(): objectCount = -1 ~HowMany(): objectCount = -2
Después de crear h, el contador es uno,
lo cual está bien. Pero después de la llamada a
f() se esperaría que el contador
estuviera a dos, porque h2 está ahora
también dentro de ámbito. Sin embargo, el contador es cero,
lo cual indica que algo ha ido muy mal. Esto se confirma por
el hecho de que los dos destructores, llamados al final de
main(), hacen que el contador pase a ser
negativo, algo que no debería ocurrir nunca.
Mire lo que ocurre dentro de f()
después de que el argumento se pase por valor. Esto quiere
decir que el objeto original h existe
fuera del ámbito de la función y, por otro lado, hay un
objeto de más dentro del ámbito de la
función, que es copia del objeto que se pasó por valor. El
argumento que se pasó utiliza el primitivo concepto de copia
bit a bit de C, pero la clase C++
HowMany necesita inicializarse
correctamente para mantener su integridad. Por lo tanto, se
demuestra que la copia bit a bit no logra el efecto deseado.
Cuando el objeto local sale de ámbito al acabar la función
f(), se llama a su destructor, lo cual
decrementa objectCount, y por lo tanto el
objectCount se pone a cero. La creación
de h2 se realiza también mediante la
copia bit a bit, así que tampoco se llama al constructor, y
cuando h y h2 salen de
ámbito, sus destructores causan el valor negativo en
objectCount.